
概述
调试工具分为两部分内容
- 页面调试
- 接口调试
PS:可视化调试工具仅能用于测试当前环境,无法跨环境测试。
页面调试概述
对当前页面的前端运行时上下文做了简单的解析,主要用于解决元数据、权限、视图等常见问题。
接口调试概述
对任何Oinone平台发起的标准请求,都可以使用该调试工具进行检查。主要用于解决异常堆栈、权限、SQL执行等相关问题的排查。
表述解释
为了方便表述,以下内容包含的后端模型字段/方法或GQL请求相关信息,其表述规则为:
{ClassSimpleName/GQLNamespace}#{field/method}例如后端模型字段/方法:(该示例并不在平台代码中,仅作为展示)
public class ModuleDefinition {
private String module;
public void queryOne() {
...
}
}ClassSimpleName为Java类的类名,在上述例子中,ClassSimpleName为ModuleDefinition。
该Java类下的module字段可以表述为ModuleDefinition#module。
该Java类下的queryOne方法可以表述为ModuleDefinition#queryOne。
例如:
{
viewActionQuery {
load(
...
) {
...
}
}
}GQLNamespace为GQL的首个字段在移除Query或Mutation后缀后的结果,在上述例子中,GQLNamespace为viewAction。
该GQL请求调用了load方法,可以将该请求简单表述为viewAction#load。
PS:通常情况下,Java类名采用大驼峰表述,而GQL采用小驼峰表述。因此可以根据首字母为大写或小写区分其表述的具体内容。
以下所有内容表述均建立在此基础之上。
调试工具使用说明
进入调试工具页面
在需要调试的页面,通过修改浏览器URL的方式进入调试工具页面。如下图所示:
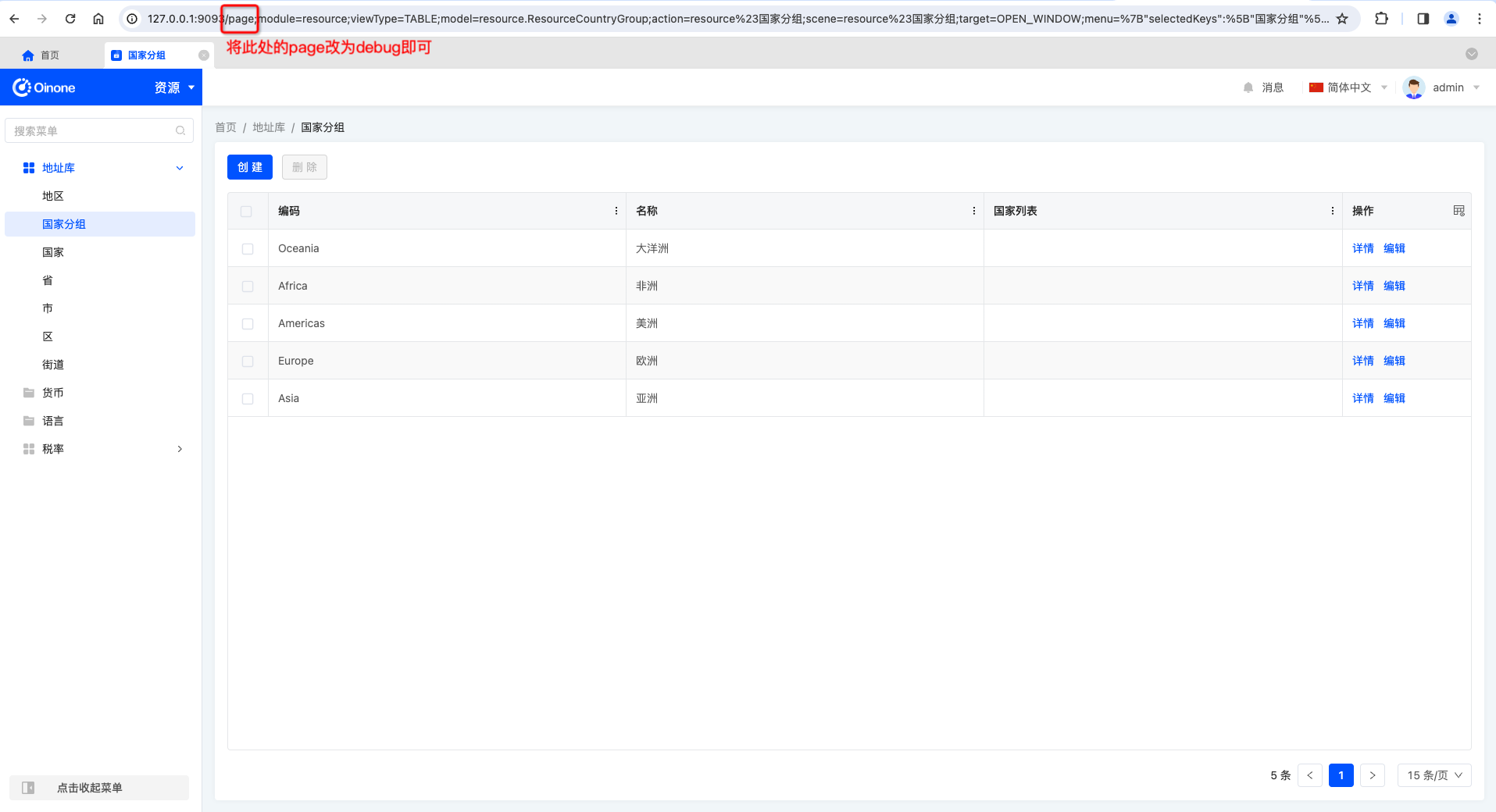

如需要调试的页面的URL如下所示:
http://127.0.0.1:9093/page;module=resource;viewType=TABLE;model=resource.ResourceCountryGroup;action=resource%23%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84;scene=resource%23%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84;target=OPEN_WINDOW;menu=%7B%22selectedKeys%22:%5B%22%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84%22%5D,%22openKeys%22:%5B%22%E5%9C%B0%E5%9D%80%E5%BA%93%22,%22%E5%9C%B0%E5%8C%BA%22%5D%7D将page改为debug后即可进入该页面的调试页面,如下所示:
http://127.0.0.1:9093/debug;module=resource;viewType=TABLE;model=resource.ResourceCountryGroup;action=resource%23%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84;scene=resource%23%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84;target=OPEN_WINDOW;menu=%7B%22selectedKeys%22:%5B%22%E5%9B%BD%E5%AE%B6%E5%88%86%E7%BB%84%22%5D,%22openKeys%22:%5B%22%E5%9C%B0%E5%9D%80%E5%BA%93%22,%22%E5%9C%B0%E5%8C%BA%22%5D%7DPS:通常我们会将新的URL改好后粘贴到新的浏览器标签页,以保留原页面可以继续查看相关信息。
调试工具页面
进入调试工具页面后,我们可以看到如下图所示的页面:
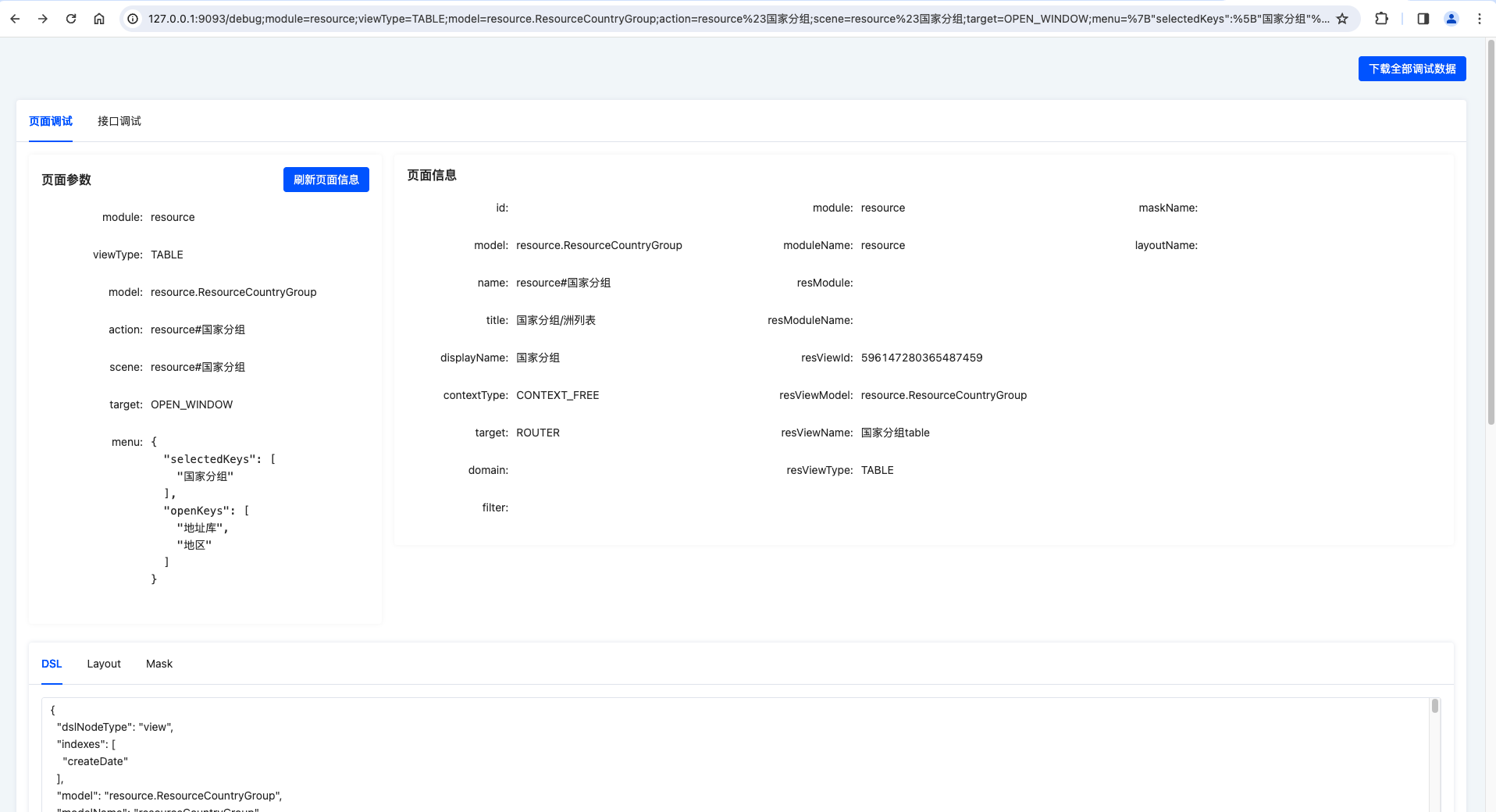
调试页面信息概述
- 下载全部调试数据:包括
页面调试和接口调试的全部数据。- 页面调试数据包含
页面参数、viewAction#load等页面数据。 - 接口调试数据仅包含最近一次接口调试相关数据,未发起过请求将没有相关数据。
- 页面调试数据包含
页面调试信息概述
- 页面参数:当前URL中所有参数。
- module:模块名称。
ModuleDefinition#name - viewType:视图类型。
ViewAction#resView#viewType - model:当前跳转动作模型编码。
ViewAction#model - action:当前跳转动作名称。
ViewAction#name
- module:模块名称。
- 页面信息:
ViewAction#load接口返回的基础信息。- id:当前跳转动作ID。
- model:同URL参数
model。 - name:同URL参数
action。 - title:用于浏览器标题以及面包屑显示名称备选项。
- displayName:用于浏览器标题以及面包屑显示名称备选项。
- contextType:数据交互上下文类型。
- target:后端配置路由类型。不同于URL参数中的target。
- domain:用户可视过滤条件,会根据规则回填至
搜索区域。 - filter:用户不可视过滤条件,通过后端
DataFilterHook追加至查询条件中。 - module:跳转动作加载模块编码。
- moduleName:跳转动作加载模块名称。
- resModule:目标视图模块编码。
- resModuleName:目标视图模块名称,用于模块跳转。
- resViewId:目标视图ID。即当前页面视图ID。
- resViewModel:目标视图模型编码。即当前页面视图模型编码。
- resViewName:目标视图名称。即当前页面视图名称。
- resViewType:目标视图类型。即当前页面视图类型。
- maskName:后端配置母版名称。
- layoutName:后端配置布局名称。
- DSL:当前页面返回的未经处理的全部元数据信息。
- Layout:当前页面使用的布局数据,当
layoutName属性不存在时,该数据来自于前端注册的Layout。 - Mask:当前页面使用的母版数据。
- 页面字段:当前页面的全部字段元数据信息。(不包含引用视图)
- 页面动作:当前页面的全部动作元数据信息。(不包含引用视图)
- 运行时视图:当前页面的视图元数据信息。
- 运行时DSL:经过解析的DSL元数据信息。
- 运行时Layout:经过解析的布局信息。
- 运行时渲染模板:主视图区域渲染的完整模板,即合并Layout和DSL后的最终结果。
- 完整上下文:运行时上下文中的全部内容。
接口调试信息概述
- 接口调试:用于发起一个
fetch格式的浏览器请求。- 日志级别:根据不同的日志级别返回或多或少的调试信息。(暂未支持)
- 发起请求:在下方输入框中粘贴
fetch格式请求后可以发起真实的接口调用。(生产环境使用时可能产生数据,请确保接口幂等性以及在允许产生测试数据的环境中使用) - 重置:还原接口调试页面所有内容。
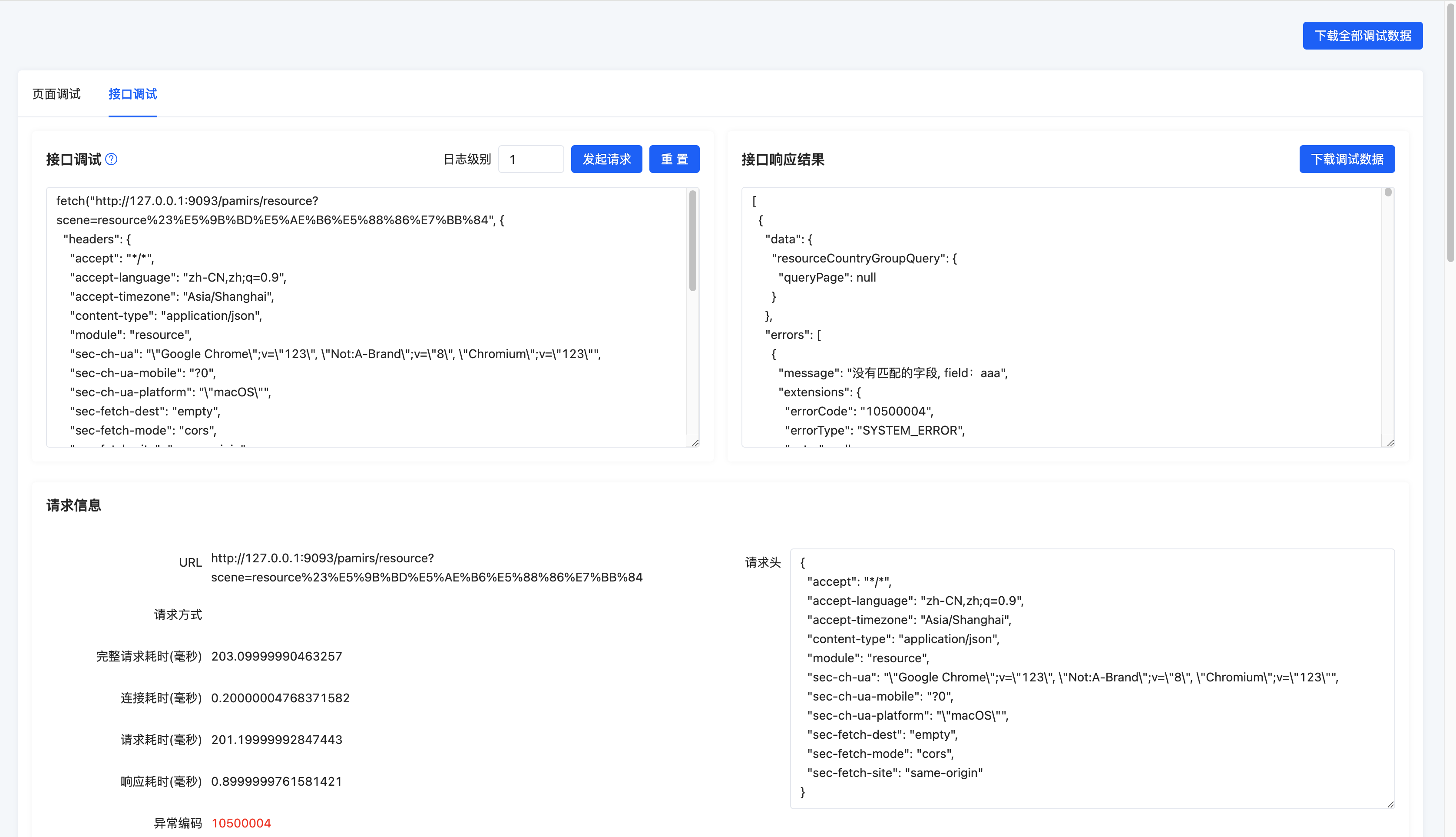
- 接口响应结果:完整的接口返回结果。
- 请求信息:当前请求的基本信息以及性能信息。
- URL:调试请求的URL。
- 请求方式:调试请求的Http请求方式。
GET/POST。 - 完整请求耗时:从调试请求发起到前端响应并解析完成的时间。
- 连接耗时:Http请求连接建立的时间。
- 请求耗时:从调试请求发起到浏览器响应的时间。
- 响应耗时:从浏览器响应到解析完成的时间。
- 异常编码:调试请求响应结果中的首个异常信息的错误编码。
- 异常信息:调试请求响应结果中的首个异常信息的错误信息。
- 请求头:调试请求的Http请求头信息。
- GQL#{index}:一个请求中可能包含多个GQL同时发起并调用多个对应的后端函数,
index表示其对应的序号。- GQL:GQL内容
- Variables:GQL参数
- 异常抛出栈:请求出现异常的首个栈,即异常发生地。(无异常不返回)
- 业务堆栈:不包含Oinone堆栈的调用堆栈信息。
- 业务与Oinone堆栈:包含Oinone堆栈的调用堆栈信息。
- 全部堆栈:未经处理的全部堆栈信息。
- SQL调试:在当前请求链路中用到的所有执行SQL。
- 函数调用链追踪:在当前请求链路中执行的全部Oinone函数基本信息及耗时。
- GQL上下文:当前GQL上下文摘要。
- 会话上下文:当前请求链路到结束的全部
PamirsSession上下文信息。 - 函数信息:当前GQL调用函数信息。
- 模型信息:当前GQL调用函数对应模型的摘要信息。
- 环境配置信息:服务端环境配置信息。
- {GQLNamespace}#{GQLName}:当前执行函数的响应结果。
发起一次接口调试
以下示例均在Chrome浏览器中进行演示,不同浏览器可能存在差异。
使用浏览器查看接口及查看接口异常
如下图所示,通过检查或F12打开浏览器控制台,并查看所有接口请求:
无异常接口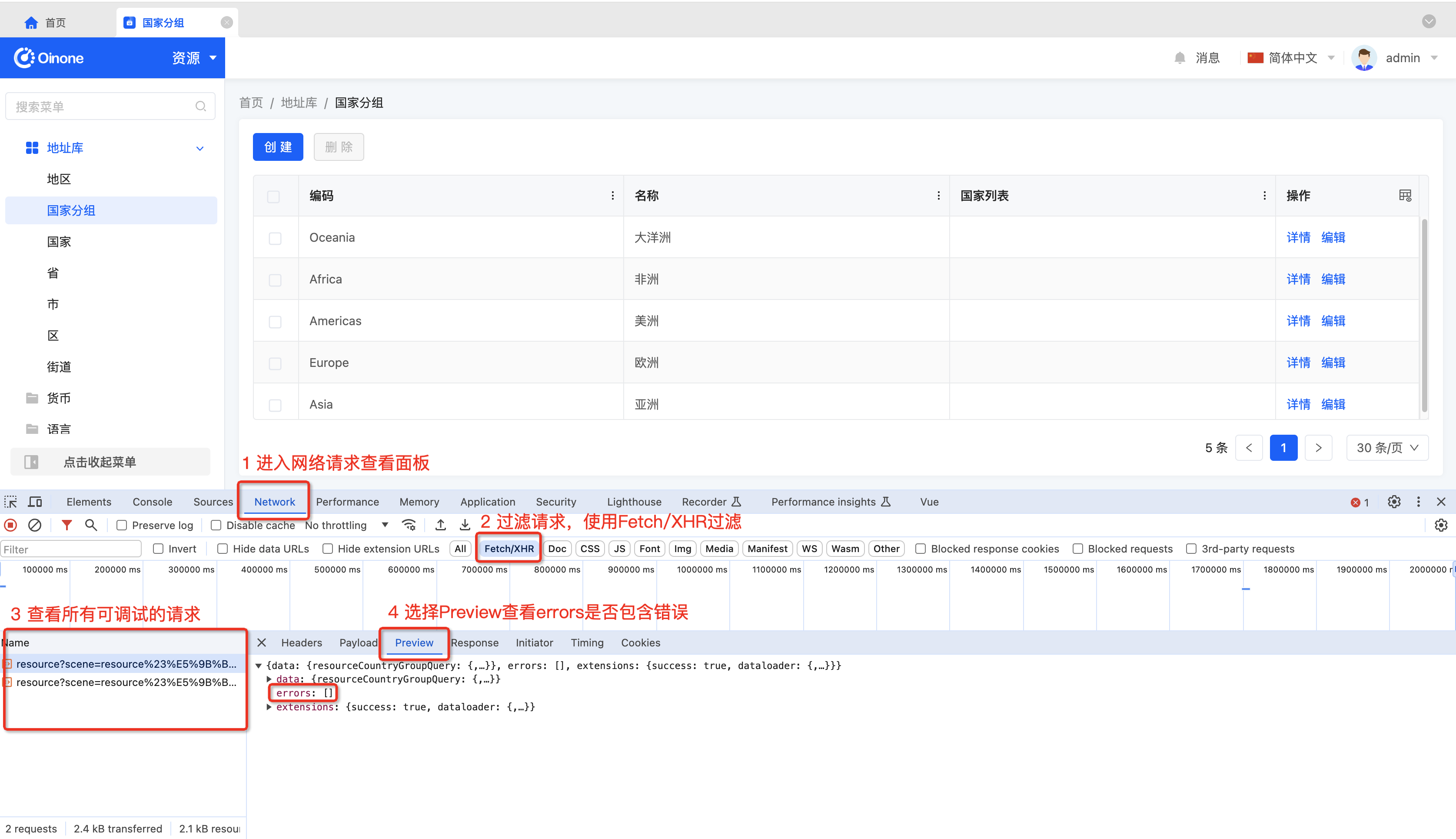
有异常接口
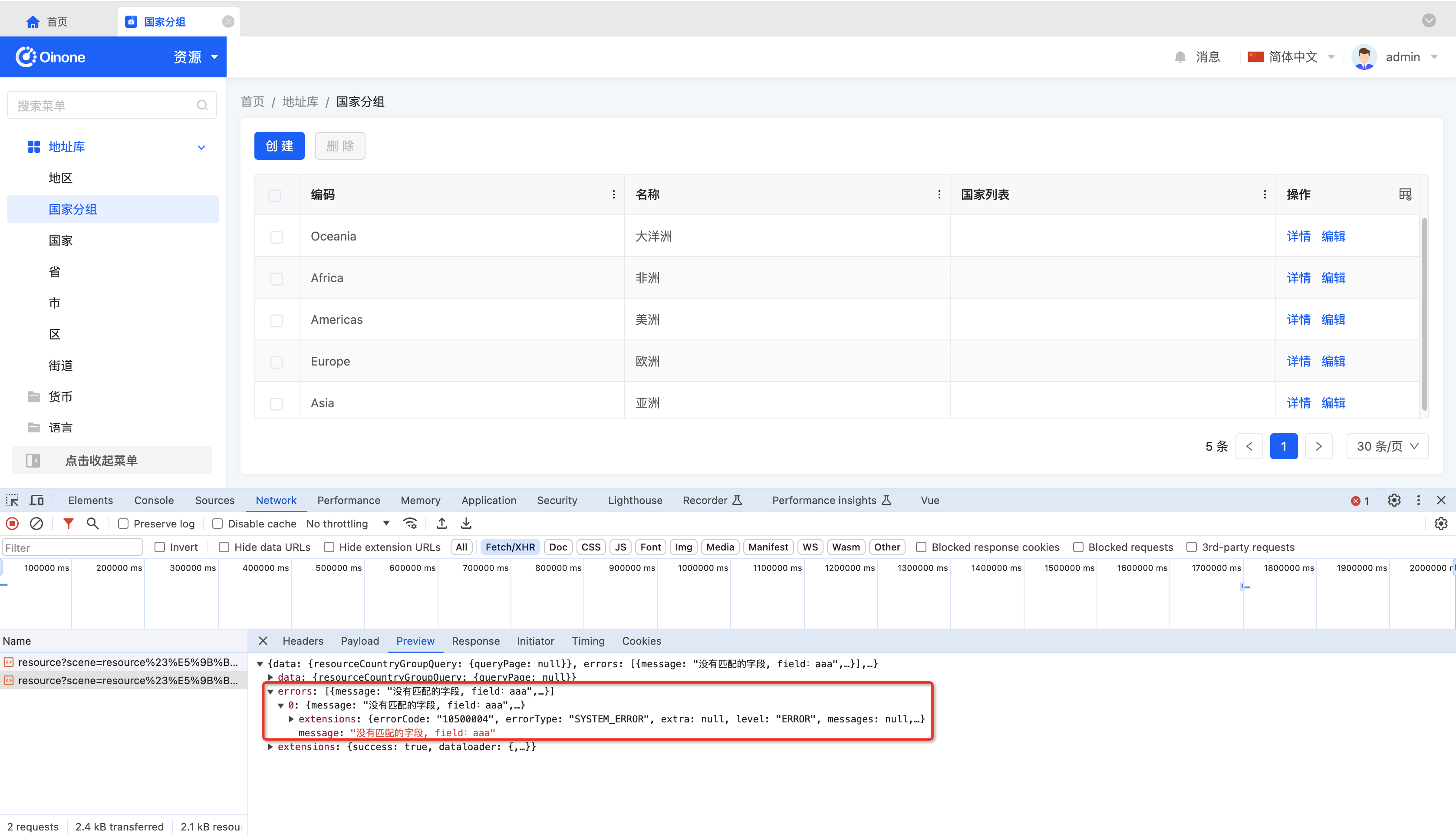
PS:一般情况下,所有Oinone请求的Http状态都为200,错误信息在errors数组中进行返回。
在浏览器控制台复制fetch格式请求
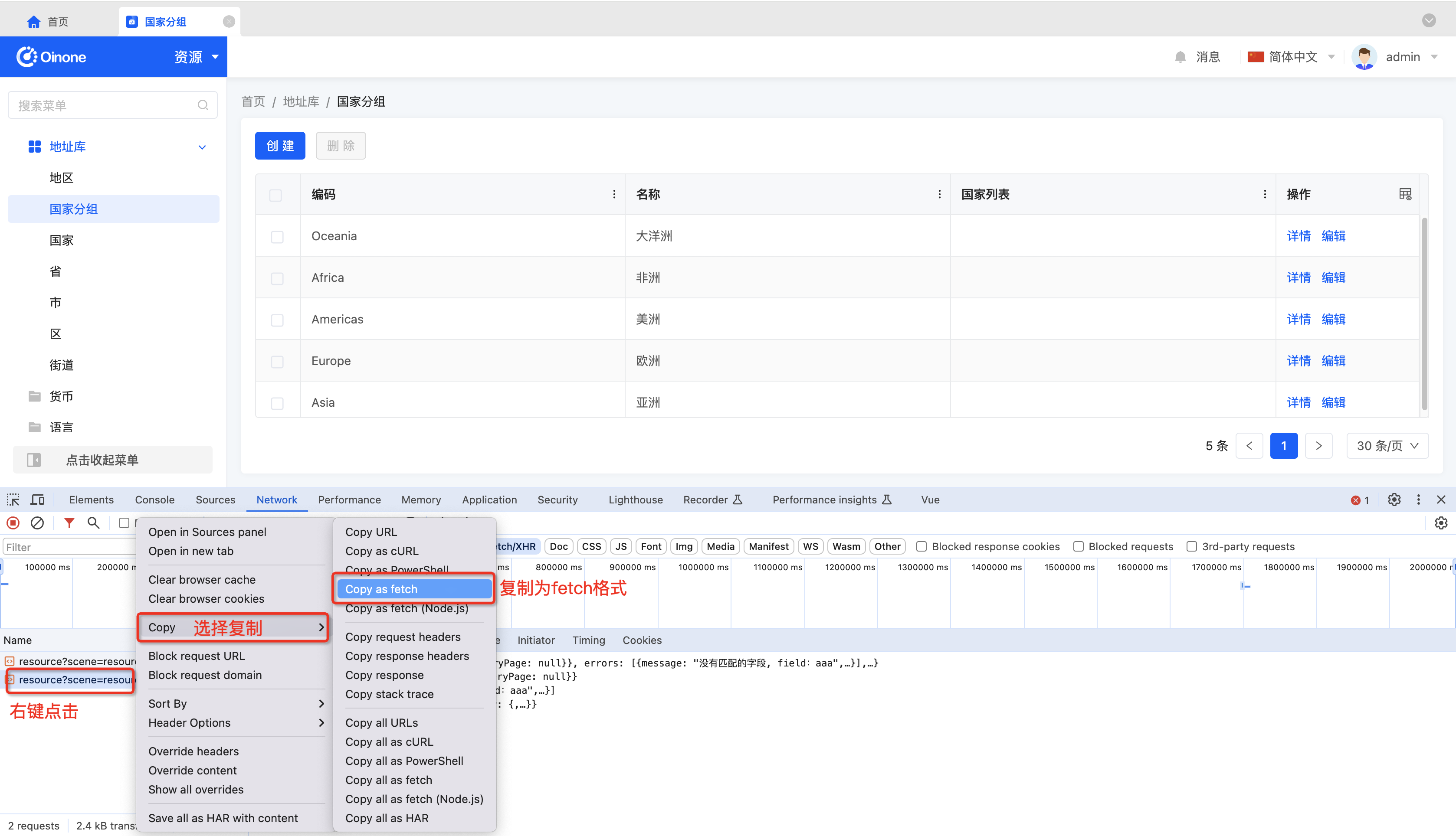
粘贴至接口调试输入框
点击发起请求即可看到该接口的响应信息
至此,我们已经完全介绍了现有调试工具的使用及页面展示内容的基本解释。未来我们还会根据需要调试的内容对该调试工具进行补充和完善,尽可能帮助开发者可以高效定位开发过程中遇到的常见问题。
下面,我们将提供几种查看调试信息的简单场景及步骤,帮助开发者可以快速上手并使用调试工具。
调试场景及检查步骤
通常情况下,Oinone平台遇到的问题都可以通过以下调试场景列举的检查步骤轻松定位问题。
当遇到无法通过调试工具定位问题时,可通过下载全部调试数据或下载调试数据按钮,将下载的文件发送给Oinone售后服务工程师,并清楚描述遇到的问题,Oinone售后服务工程师会针对该问题提出解决方案或修复方案。
以下调试场景不区分使用页面调试和接口调试,需要开发者根据遇到的问题自行判断该使用什么调试工具解决遇到的问题。
SQL示例解释
SQL示例中的表名可能与开发者调试的环境中的表名存在差异,需要开发者根据SQL示例找到对应的数据库及数据表并执行SQL。SQL示例中的参数需要根据开发者所遇到的问题进行调整。
SQL示例中并不包含租户隔离相关字段,请开发者根据运行环境自行补充查询条件。
{URL#model}表示使用URL参数中的model属性值进行替换,其他情况开发者可自行调整。
当页面中的字段/动作未正确显示时
检查当前用户是否具有该字段/动作的权限(超级管理员可跳过此步骤)
使用页面进行检查
步骤1:进入用户模块,查看该用户配置的角色列表,检查是否包含预期角色。
步骤2:进入权限模块,查看该用户所有角色的权限配置,检查是否包含字段的可见权限或动作的访问权限。
使用SQL进行检查
步骤1:根据当前登录用户获取用户ID(请开发者通过当前登录用户信息在user_pamirs_user表中自行查看)
步骤2:查看该用户配置的角色列表,检查是否包含预期角色。
-- 检查当前用户配置的角色列表
select id,name from auth_auth_role where id in (select role_id from auth_user_role_rel where user_id = {userId} and is_deleted = 0) and is_deleted = 0;步骤3:根据角色列表分别查看字段和动作权限配置相关信息
检查当前跳转动作对应的视图是否为所需视图
步骤1:在页面调试的DSL中搜索字段/动作相关信息,看看有没有正确返回。
如正确返回,可根据以下步骤进行检查:
- 检查
元数据是否补充完整。 - 检查
invisible属性是否按预期执行。
如未正确返回,可根据以下SQL示例在数据库中检查相关内容。
-- 检查ViewAction对应的视图是否为预期视图
select id,res_model,res_view_name from base_view_action where model = '{URL#model}' and name = '{URL#action}' and is_deleted = 0;
-- 检查视图的template是否存在字段/动作
select b.id,b.type,b.template from (select res_model,res_view_name from base_view_action where model = ''{URL#model}' and name = ''{URL#action}' and is_deleted = 0) a left join base_view b on a.res_model = b.model and a.res_view_name = b.name;本文来自投稿,不代表Oinone社区立场,如若转载,请注明出处:https://doc.oinone.top/frontend/6669.html