
多语言是国际化中大家最常面对的问题,我们需要对应用的页面结构元素进行翻译,也需要对系统内容进行翻译比如:菜单、数据字典等,甚至还会业务数据进行翻译。但不管什么翻译需求,我们在实现上基本可以归类为前端翻译和后端翻译。前端翻译顾名思义是在前端根据用户选择语言对内容进行翻译,反之就是后端翻译。本文会带着大家了解oinone的前端翻译与后端翻译
准备工作
pamirs-demo-boot的pom文件中引入pamirs-translate包依赖
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-translate</artifactId>
</dependency>pamirs-demo-boot的application-dev.yml文件中增加配置pamirs.boot.modules增加translate,即在启动模块中增加translate模块
pamirs:
boot:
modules:
- translate后端翻译(使用)
这里通过对菜单的翻译来带大家了解翻译模块
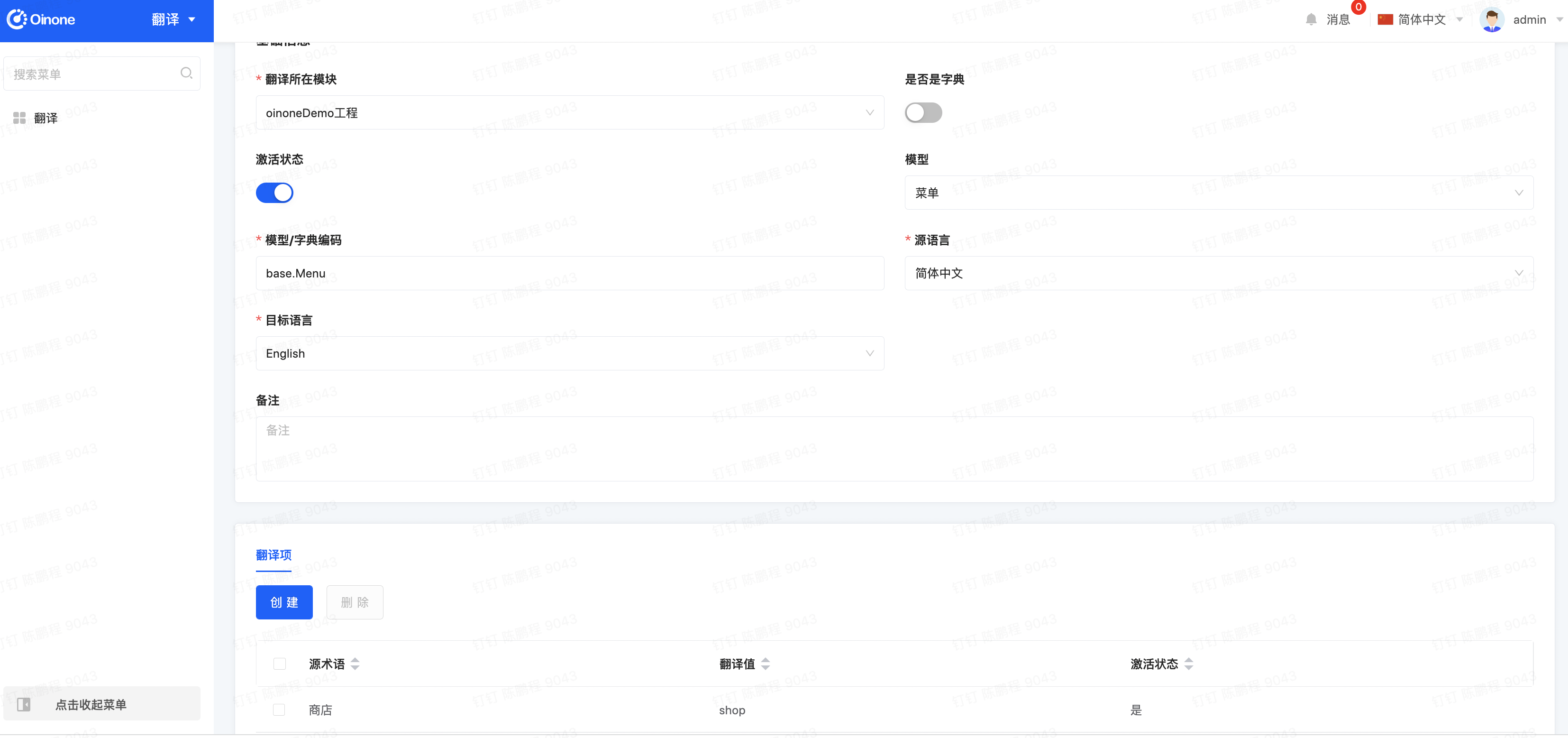
Step1 新增翻译记录
切换应用到translate模块,点击新增翻译。
-
选择新增翻译生效模块
-
选择翻译的模型为:菜单模型
-
源语言选择中文,目标选择English
-
添加翻译项目:
-
源术语为:商店
-
翻译值为:shop
-
状态为:激活
-

Step2 查看效果
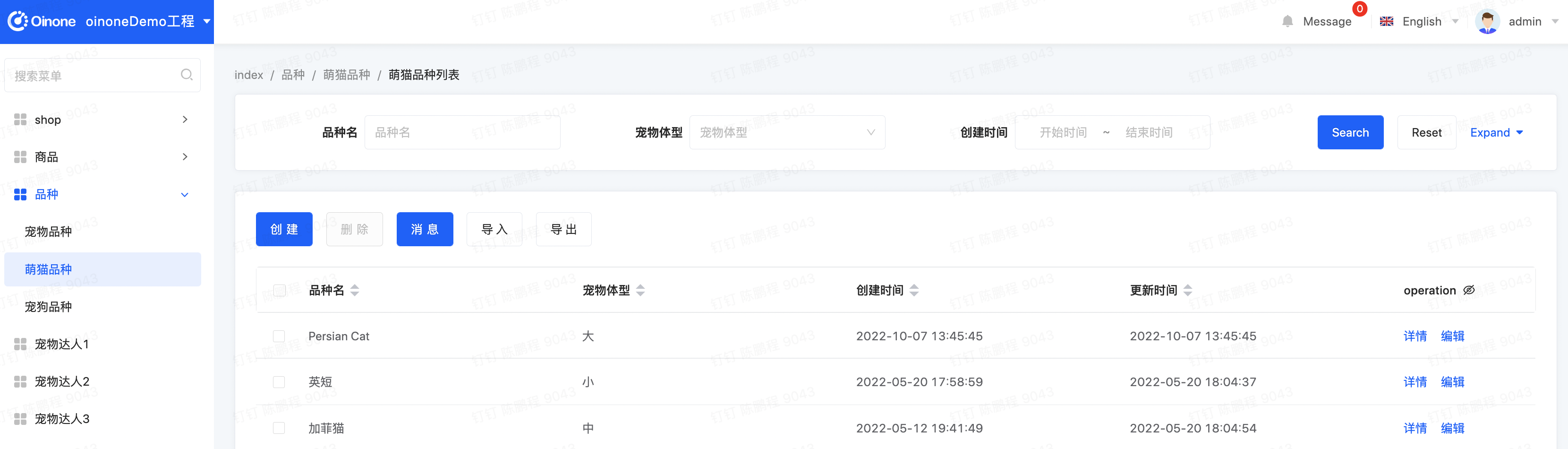
应用切换到Demo模块,在右上角切换语言至英语

后端翻译(自定义模型的翻译)
在前面菜单的翻译中,似乎我们什么都没做就可以正常通过翻译模块完成多语言的切换了。是不是真如我们想象的一样,当然不是。是因为Menu模型的displayName字段加上@Field(translate = true)注解。
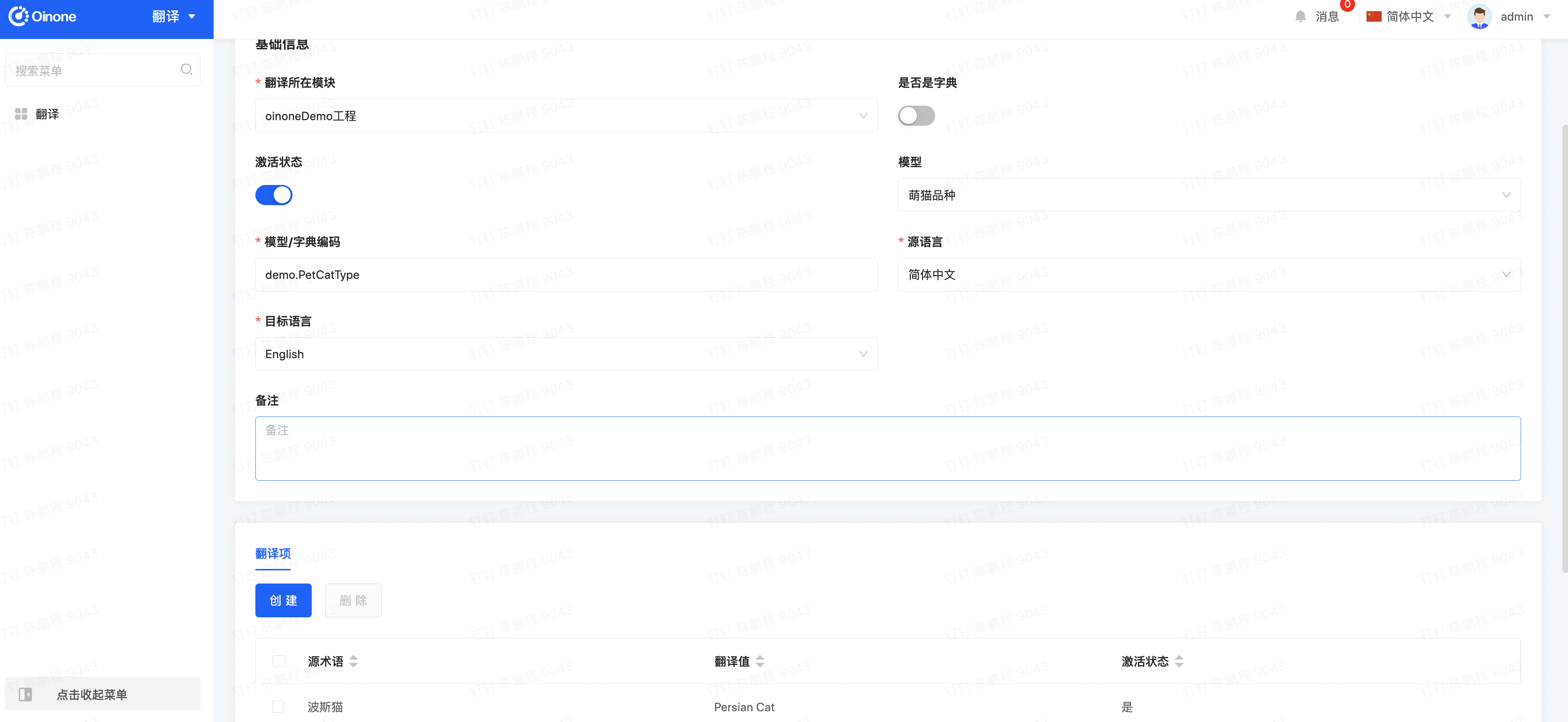
Step1 为PetType模型的name字段增加翻译注解
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.base.IdModel;
@Model.MultiTable(typeField = "kind")
@Model.model(PetType.MODEL_MODEL)
@Model(displayName="品种",labelFields = {"name"})
public class PetType extends IdModel {
public static final String MODEL_MODEL="demo.PetType";
@Field(displayName = "品种名" , translate = true)
private String name;
@Field(displayName = "宠物分类")
private String kind;
}Step2 重启应用查看效果
- 切换应用到translate模块,点击新增翻译
- 切换应用到Demo模块,切换中英文,查看效果
前端翻译
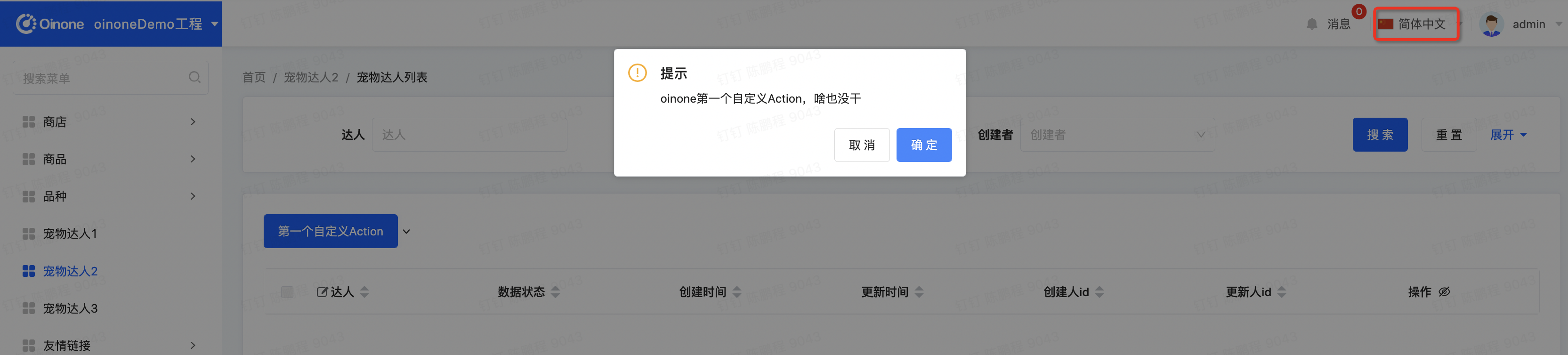
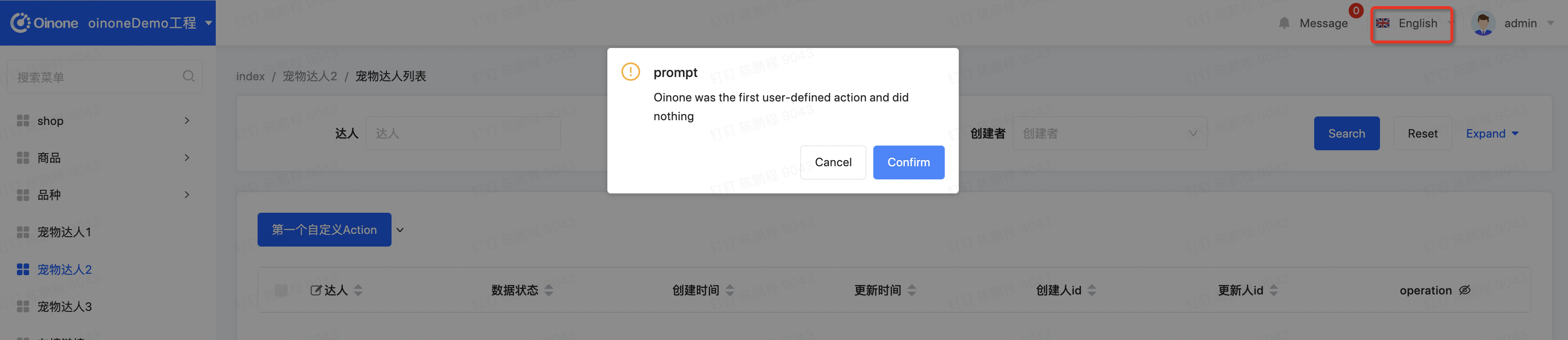
还记得我们前端第一个自定义动作吗?会弹出“oinone第一个自定义Action,啥也没干”,我们要对它进行翻译。
Step1 修改前端DoNothingActionWidget.ts
-
import translateValueByKey
-
提示语用translateValueByKey加上翻译 const confirmRs = executeConfirm(translateValueByKey(\'oinone第一个自定义Action,啥也没干\')||\'oinone第一个自定义Action,啥也没干\');
前端更多翻译工具请见前端高级特性-框架之翻译工具
import {
Action,
ActionContextType,
ActionWidget,
executeConfirm,
IClientAction,
SPI,
ViewType,
Widget,
translateValueByKey
} from '@kunlun/dependencies';
@SPI.ClassFactory(ActionWidget.Token({ name: 'demo.doNothing' }))
export class DoNothingActionWidget extends ActionWidget {
@Widget.Method()
public async clickAction() {
const confirmRs = executeConfirm(translateValueByKey('oinone第一个自定义Action,啥也没干')||'oinone第一个自定义Action,啥也没干');
}
}
//定义动作元数据
Action.registerAction('*', {
displayName: '啥也没干',
name: 'demo.doNothing',
id: 'demo.doNothing',
contextType: ActionContextType.ContextFree,
bindingType: [ViewType.Table]
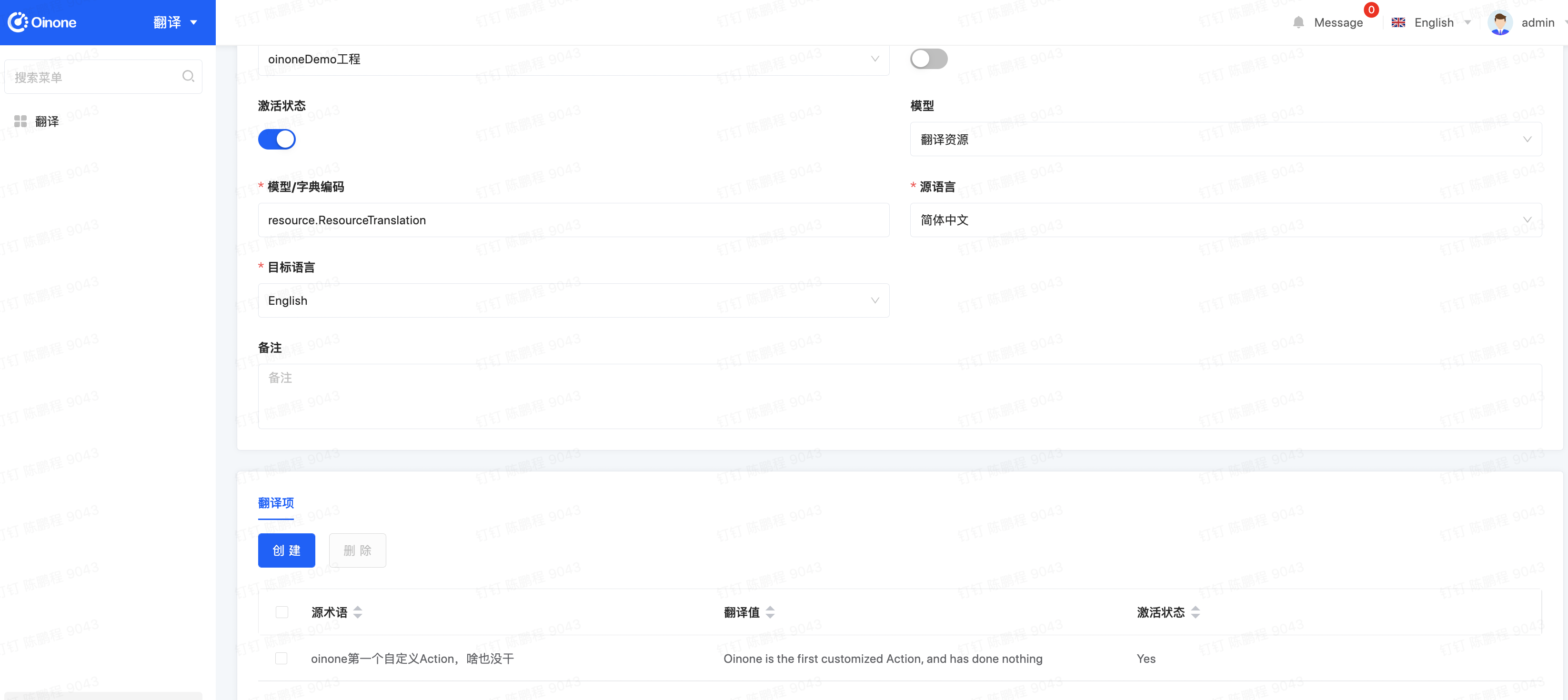
} as IClientAction);Step2 新增翻译记录
前端翻译的翻译记录对应的模型可以随意找一个放。但要注意几点:
-
不要找有字读配置translate = true的模型,因为会影响后端翻译性能。
-
最好统一到一个模型中,便于后续管理。这里大家可以自定义一个无有业务访问且本身无需要翻译的模型来挂载,避免性能损失
Step3 刷新远程资源生成前端语言文件
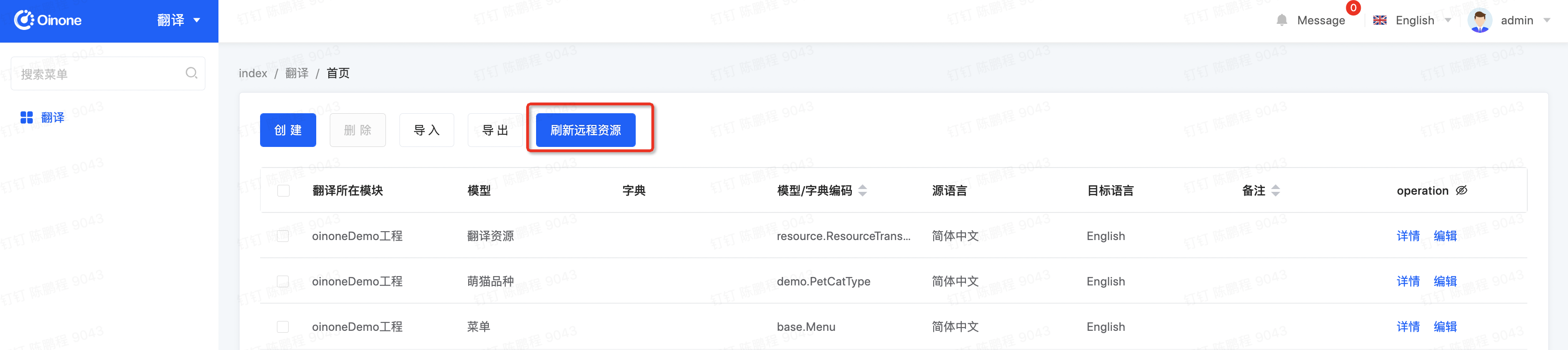
Step4 新增或修改.env
前端在项目根目录下新增或修改.env,可以参考.env.example文件。通过.env文件为前端配置oss文件路径,针对I18N_OSS_URL配置项。真实前端访问翻译语言文件的路径规则为:http://bucket.downloadUrl/mainDir/租户/translate/模块/语言文件。
-
yaml文件中oss配置的文件路径:http://pamirs.oss-cn-hangzhou.aliyuncs.com/upload/demo/
-
租户/translate/模块/语言文件 前端会自动根据上下文组织
# 后端api配置
# API_BASE_URL=http://127.0.0.1:8090
# 下面是国际化语言的cdn配置,默认用当前请求链接下的路径: /pamirs/translate/${module}/i18n_${lang}.js
I18N_OSS_URL=http://pamirs.oss-cn-hangzhou.aliyuncs.com/upload/demoStep5 重启前端应用看效果
对语言进行中英文切换,进入宠狗达人页面,点击【第一个自定义Action】,查看前端翻译效果
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9328.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验
Comments(2)
只支持英语吗?如何添加其他语种?
@xiao3:支持其他的国家的语言,需要在资源里面创建,如果有其他的疑问,也可以群内联系我们哈