
枚举是大家在系统开发中经常用的一种类型,在oinone中也对枚举类型进行了支持,同时也做了相应的加强。希望通过本文能让大家对枚举的使用,有更全面的认知
一、枚举系统与数据字典
枚举是列举出一个有穷序列集的所有成员的程序。在元数据中,我们使用数据字典进行描述。
协议约定
枚举需要实现IEnum接口和使用@Dict注解进行配置,通过配置@Dict注解的dictionary属性来设置数据字典的唯一编码。前端使用枚举的displayName来展示,枚举的name来进行交互;后端使用枚举的value来进行交互(包括默认值设置也使用枚举的value)。
枚举会存储在元数据的数据字典表中。枚举分为两类:1.异常类;2.业务类。异常类枚举用于定义程序中的错误提示,业务类枚举用于定义业务中某个字段值的有穷有序集。
编程式用法
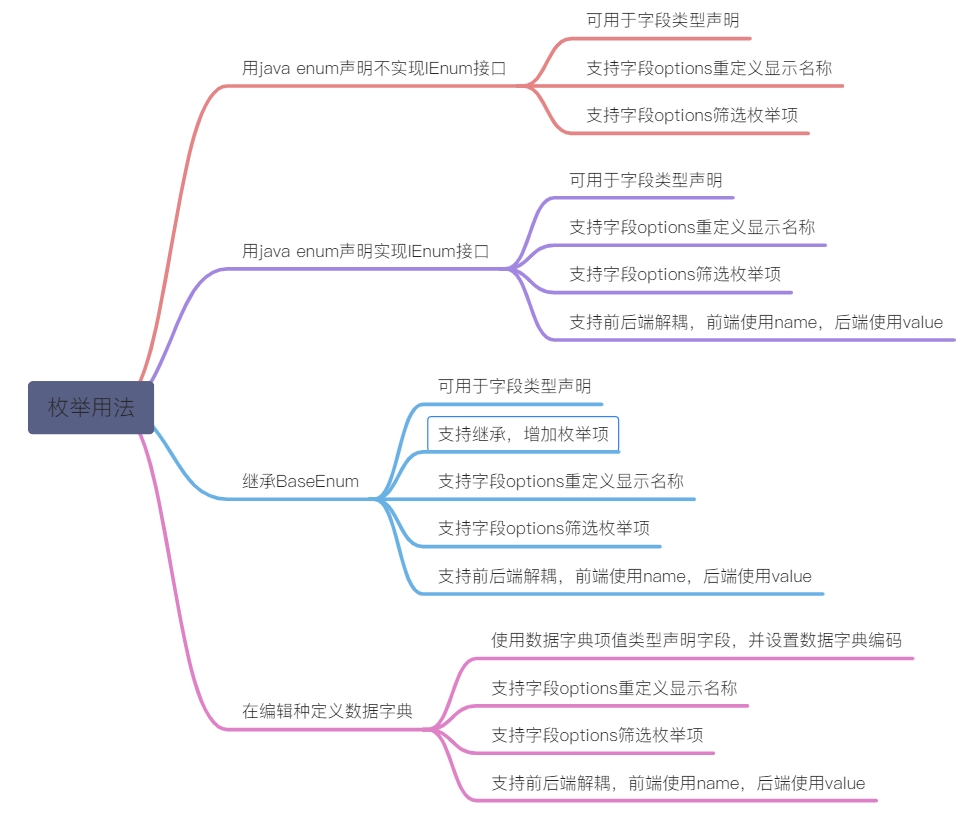

如果一个字段的类型被定义为枚举,则该字段就可以使用该枚举来进行可选项约束(options)。该字段的可选项为枚举所对应数据字典的子集。
可继承枚举
继承BaseEnum可以实现java不支持的继承枚举。同时可继承枚举也可以用编程式动态创建枚举项。
可继承枚举也可以兼容无代码枚举。

二进制枚举
可以通过@Dict注解设置数据字典的bit属性或者实现BitEnum接口来标识该枚举值为2的次幂。
二、enum不可继承枚举(举例)
我们在介绍抽象基类中AbstractDemoCodeModel和AbstractDemoIdModel就引入了数据状态(DataStatusEnum)字段,并设置了必填和默认值为DISABLED。DataStatusEnum实现了IEnum接口,并用@Dict(dictionary = DataStatusEnum.dictionary, displayName = "数据状态")进行了注解。为什么不能继承呢?因为JAVA语言的限制导致enum是不可继承的
package pro.shushi.pamirs.core.common.enmu;
import pro.shushi.pamirs.meta.annotation.Dict;
import pro.shushi.pamirs.meta.common.enmu.IEnum;
@Dict(dictionary = DataStatusEnum.dictionary, displayName = "数据状态")
public enum DataStatusEnum implements IEnum<String> {
DRAFT("DRAFT", "草稿", "草稿"),
NOT_ENABLED("NOT_ENABLED", "未启用", "未启用"),
ENABLED("ENABLED", "已启用", "已启用"),
DISABLED("DISABLED", "已禁用", "已禁用");
public static final String dictionary = "partner.DataStatusEnum";
private String value;
private String displayName;
private String help;
DataStatusEnum(String value, String displayName, String help) {
this.value = value;
this.displayName = displayName;
this.help = help;
}
public String getValue() {
return value;
}
public String getDisplayName() {
return displayName;
}
public String getHelp() {
return help;
}
}三、BaseEnum可继承枚举(举例)
Step1 新增CatShapeExEnum继承CatShapeEnum枚举
package pro.shushi.pamirs.demo.api.enumeration;
import pro.shushi.pamirs.meta.annotation.Dict;
@Dict(dictionary = CatShapeExEnum.DICTIONARY,displayName = "萌猫体型Ex")
public class CatShapeExEnum extends CatShapeEnum {
public static final String DICTIONARY ="demo.CatShapeExEnum";
public final static CatShapeExEnum MID =create("MID",3,"中","中");
}Step2 修改PetCatType的shape字段类型为CatShapeExEnum
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.demo.api.enumeration.CatShapeExEnum;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
@Model.MultiTableInherited(type = PetCatType.KIND_CAT)
@Model.model(PetCatType.MODEL_MODEL)
@Model(displayName="萌猫品种",labelFields = {"name"})
public class PetCatType extends PetType {
public static final String MODEL_MODEL="demo.PetCatType";
public static final String KIND_CAT="CAT";
@Field(displayName = "宠物分类",defaultValue = PetCatType.KIND_CAT,invisible = true)
private String kind;
@Field.Enum
@Field(displayName = "宠物体型")
private CatShapeExEnum shape;
}Step3 重启系统,查看效果
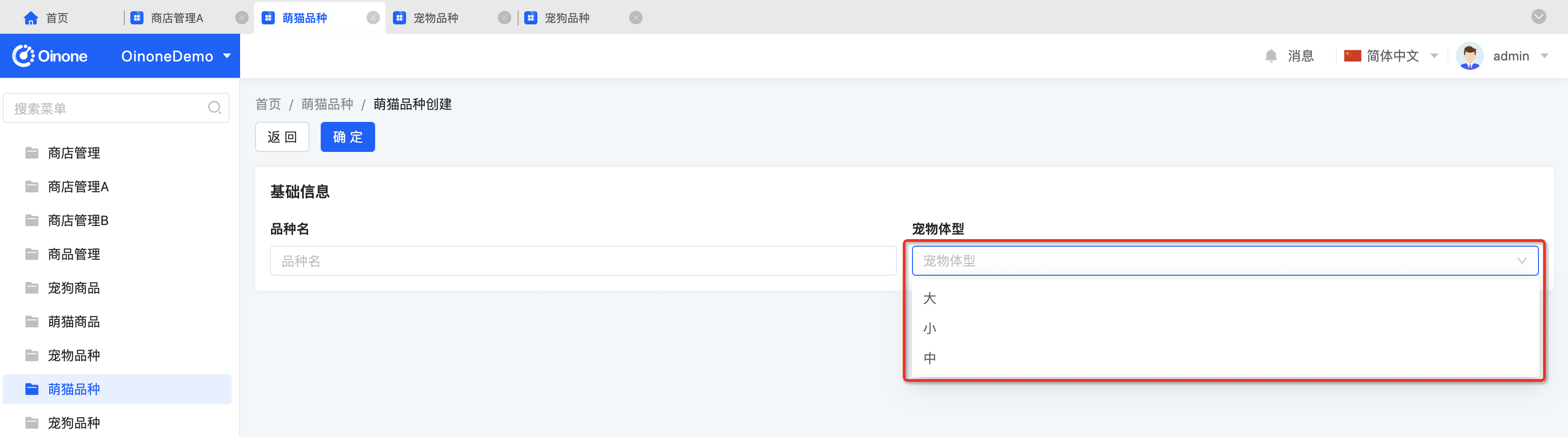
另:可继承枚举的Switch API
继承BaseEnum可以实现Java不支持的可变枚举,可变枚举可以在运行时增加非Java代码定义的枚举项,同时可变枚举支持枚举继承。由于可变枚举不是Java规范中的枚举,所以无法使用switch...case...语句,但是K2提供稍作变化的switches(无需返回值)与switchGet(需要返回值)方式实现相同功能与逻辑。
BaseEnum.switches(比较变量, 比较方式/*系统默认提供两种方式:caseName()和caseValue()*/,
cases(枚举列表1).to(() -> {/*逻辑处理*/}),
cases(枚举列表2).to(() -> {/*逻辑处理*/}),
...
cases(枚举列表N).to(() -> {/*逻辑处理*/}),
defaults(() -> {/*默认逻辑处理*/})
);BaseEnum.<比较变量类型, 返回值类型>switchGet(比较变量,
比较方式/*系统默认提供两种方式:caseName()和caseValue()*/,
cases(枚举列表1).to(() -> {/*return 逻辑处理的结果*/}),
cases(枚举列表2).to(() -> {/*return 逻辑处理的结果*/}),
...
cases(枚举列表N).to(() -> {/*return 逻辑处理的结果*/}),
defaults(() -> {/*return 逻辑处理的结果*/})
);caseName()使用枚举项的name与比较变量进行匹配比较;caseValue()使用枚举项的value值与比较变量进行匹配比较。
例如以下逻辑表示当ttype的值为O2O、O2M、M2O或M2M枚举值时返回true,否则返回false。
return BaseEnum.<String, Boolean>switchGet(ttype, caseValue(),
cases(O2O, O2M, M2O, M2M).to(() -> true),
defaults(() -> false)
);四、二进制枚举(举例)
可以通过@Dict注解设置数据字典的bit属性或者实现BitEnum接口来标识该枚举值为2的次幂。二进制枚举最大的区别在于值的序列化和反序列化方式是不一样的。更多有关序列化知识详见3.3.5【模型编码生成器】一文。
Step1 新建店铺选项枚举、并添加为PetShop的一个字段
- PetShopOptionEnum继承BaseEnum<PetShopOptionEnum,Long>并实现BitEnum接口,增加三个枚举,值分别是2的0次幂,2的1次幂,2的2次幂。多选枚举3位枚举都选中,字段值为7;
package pro.shushi.pamirs.demo.api.enumeration;
import pro.shushi.pamirs.meta.annotation.Dict;
import pro.shushi.pamirs.meta.common.enmu.BaseEnum;
import pro.shushi.pamirs.meta.common.enmu.BitEnum;
@Dict(dictionary = PetShopOptionEnum.DICTIONARY,displayName = "店铺选项枚举")
public class PetShopOptionEnum extends BaseEnum<PetShopOptionEnum,Long> implements BitEnum {
public static final String DICTIONARY ="demo.PetShopOptionEnum";
public static final PetShopOptionEnum ANCIENT = create("ANCIENT",1L<<0,"十年老店","十年老店");
public static final PetShopOptionEnum SEVEN = create("SEVEN",1L<<1,"七天无理由退货","七天无理由退货");
public static final PetShopOptionEnum CERTIFIED_PRODUCTS = create("CERTIFIED_PRODUCTS",1L<<2,"正品认证","正品认证");
}- 修改PetShop,增加一个多选枚举字段options,枚举类型为PetShopOptionEnum
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.demo.api.enumeration.PetShopOptionEnum;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import java.sql.Time;
import java.util.List;
@Model.model(PetShop.MODEL_MODEL)
@Model(displayName = 宠物店铺,summary=宠物店铺,labelFields = {shopName})
@Model.Code(sequence = DATE_ORDERLY_SEQ,prefix = P,size=6,step=1,initial = 10000,format = yyyyMMdd)
public class PetShop extends AbstractDemoIdModel {
public static final String MODEL_MODEL=demo.PetShop;
@Field(displayName = 店铺编码)
private String code;
@Field(displayName = 店铺编码2)
@Field.Sequence(sequence = DATE_ORDERLY_SEQ,prefix = C,size=6,step=1,initial = 10000,format = yyyyMMdd)
private String codeTwo;
@Field(displayName = 店铺名称,required = true)
private String shopName;
@Field(displayName = 开店时间,required = true)
private Time openTime;
@Field(displayName = 闭店时间,required = true)
private Time closeTime;
@Field(displayName = 店铺标志)
private List options;
}
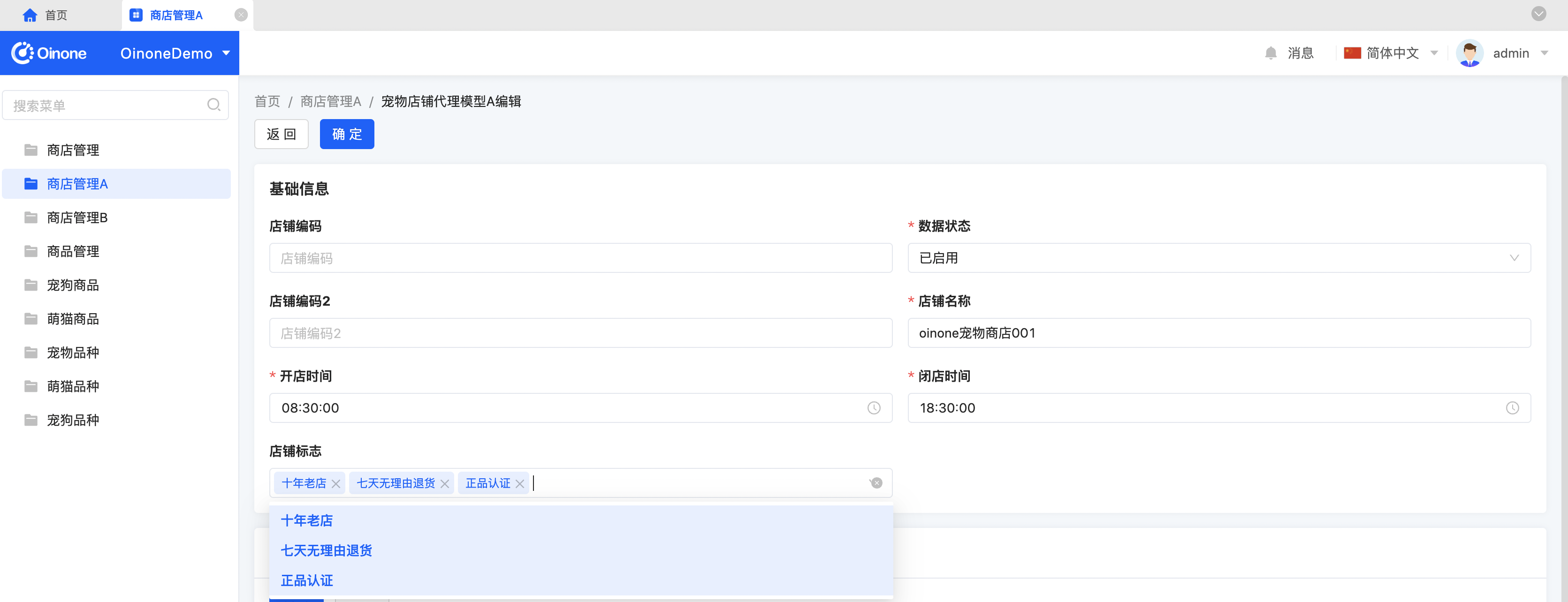
Step2 重启查看效果
- 商店管理A的编辑页面可以看到店铺标志字段可多选十年老店、七天无理由退货、正品认证
- 商店管理A的列表页面可以看到【店铺标志】字段为【十年老店】、【七天无理由退货】、【正品认证】
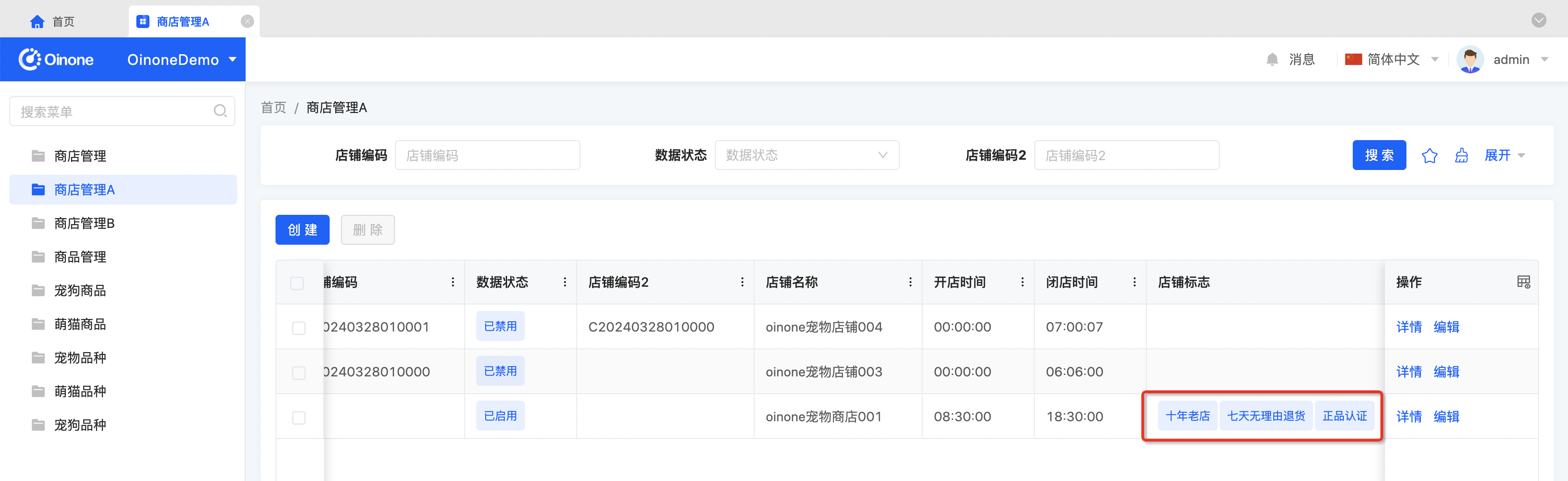
- 查看数据库对应的options字段值为7

五、异常枚举(举例)
作为oinone管理异常的规范,一般枚举都是用@Dict申明为数据字典,但是异常枚举会用@Error来注解,因为异常跟业务枚举有很大区别,异常往往数量非常多,如果用@Dict数据字典方式来管理,那么数据字典的量会非常大。
Step1 新建一个异常枚举类DemoExpEnumerate,实现ExpBaseEnum接口并加上@Errors(displayName = demo模块错误枚举)注解,增加对应错误枚举
package pro.shushi.pamirs.demo.api.enumeration;
import pro.shushi.pamirs.meta.annotation.Errors;
import pro.shushi.pamirs.meta.common.enmu.ExpBaseEnum;
@Errors(displayName = demo模块错误枚举)
public enum DemoExpEnumerate implements ExpBaseEnum {
SYSTEM_ERROR(ERROR_TYPE.SYSTEM_ERROR,90000000,系统异常),
PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL(ERROR_TYPE.BIZ_ERROR,90000001,店铺列表不能为空);
private ERROR_TYPE type;
private int code;
private String msg;
DemoExpEnumerate(ERROR_TYPE type, int code, String msg) {
this.type= type;
this.code=code;
this.msg=msg;
}
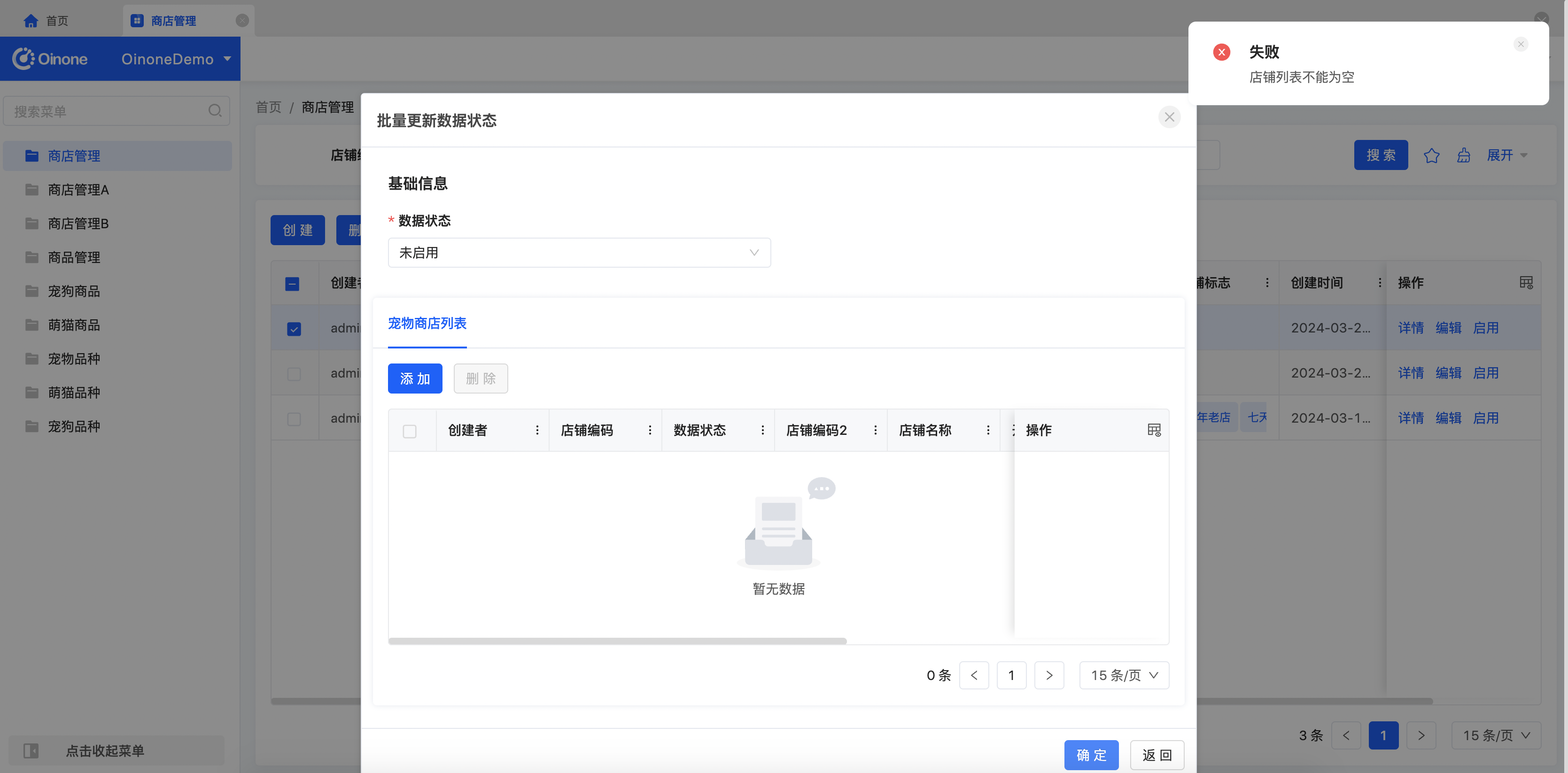
}Step2 修改宠物商店批量更新数据状态逻辑
增加一个PetShopList必选判断,如果没选则抛出异常并制定异常枚举为PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL
package pro.shushi.pamirs.demo.core.action;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.enumeration.DemoExpEnumerate;
import pro.shushi.pamirs.demo.api.proxy.PetShopProxy;
import pro.shushi.pamirs.demo.api.tmodel.PetShopBatchUpdate;
import pro.shushi.pamirs.meta.annotation.Action;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.common.enmu.ExpBaseEnum;
import pro.shushi.pamirs.meta.common.exception.PamirsException;
import pro.shushi.pamirs.meta.enmu.ActionContextTypeEnum;
import pro.shushi.pamirs.meta.enmu.FunctionOpenEnum;
import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum;
import pro.shushi.pamirs.meta.enmu.ViewTypeEnum;
import java.util.List;
@Model.model(PetShopBatchUpdate.MODEL_MODEL)
@Component
public class PetShopBatchUpdateAction {
@Function(openLevel = FunctionOpenEnum.API)
@Function.Advanced(type= FunctionTypeEnum.QUERY)
public PetShopBatchUpdate construct(PetShopBatchUpdate petShopBatchUpdate, List petShopList){
PetShopBatchUpdate result = new PetShopBatchUpdate();
result.setPetShopList(petShopList);
return result;
}
@Action(displayName = 确定,bindingType = ViewTypeEnum.FORM,contextType = ActionContextTypeEnum.SINGLE)
public PetShopBatchUpdate conform(PetShopBatchUpdate data){
if(data.getPetShopList() == null || data.getPetShopList().size()==0){
throw PamirsException.construct(DemoExpEnumerate.PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL).errThrow();
}
List proxyList = data.getPetShopList();
for(PetShopProxy petShopProxy:proxyList){
petShopProxy.setDataStatus(data.getDataStatus());
}
new PetShopProxy().updateBatch(proxyList);
return data;
}
}Step3 重启系统看效果
平台的异常枚举如下:
pamirs-framework异常枚举
每一个模块都可以包含一个或多个异常枚举类,枚举项定义了应用中异常的错误编码与描述。在应用需要抛出异常的位置,可在抛出异常的时候附带对应的错误枚举。我们使用@Errors注解来定义错误枚举类。
| 工程名 | 定义位置 | 编码起始值 |
|---|---|---|
| pamirs-meta-model | MetaExpEnumerate | 10010000 |
| pamirs-meta-dsl | DslExpEnumerate | 10020000 |
| pamirs-framework-common | FwExpEnumerate | 10050000 |
| pamirs-framework-configure-annotation | AnnotationExpEnumerate | 10060000 |
| pamirs-framework-configure-db | MetadExpEnumerate | 10070000 |
| pamirs-framework-compute | ComputeExpEnumerate | 10080000 |
| pamirs-framework-compare | CompareExpEnumerate | 10090000 |
| pamirs-framework-faas | FaasExpEnumerate | 10100000 |
| pamirs-framework-orm | OrmExpEnumerate | 10110000 |
| pamirs-connectors-data | DataExpEnumerate | 10150000 |
| pamirs-connectors-data-dialect | DialectExpEnumerate | 10160000 |
| pamirs-connectors-data-sql | SqlExpEnumerate | 10170000 |
| pamirs-connectors-data-ddl | DdlExpEnumerate | 10180000 |
| pamirs-connectors-data-infrastructure | InfExpEnumerate | 10190000 |
| pamirs-connectors-data-tx | TxExpEnumerate | 10200000 |
| pamirs-gateways-rsql | RsqlExpEnumerate | 10500000 |
| pamirs-gateways-graph-java | GqlExpEnumerate | 10510000 |
| pamirs-boot-api | BootExpEnumerate | 11000000 |
| pamirs-boot-uxd | BootUxdExpEnumerate | 11040000 |
| pamirs-boot-standard | BootStandardExpEnumerate | 11050000 |
| pamirs-base-api | BaseExpEnumerate | 11500000 |
| pamirs-sid | SidExpEnumerate | 11510000 |
通用异常码
| 错误 | 错误描述 | 定义位置 | 编码 |
|---|---|---|---|
| BASE_USER_NOT_LOGIN_ERROR | 用户未登录 | BaseExpEnumerate | 11500001 |
| BASE_CHECK_DATA_ERROR | 校验失败,数据错误 | FwExpEnumerate | 10050009 |
pamirs-core异常枚举(20010000-20290000)
| 工程名 | 编码起始值 | 数据字典名 |
|---|---|---|
| pamirs-core-common | 20010000 | error.core.common.exceptions |
| pamirs-sequence(原pamirs-bid) | 20020000 | error.core.sequence.exceptions |
| pamirs-data-audit | 20030000 | error.core.data.audit.exceptions |
| pamirs-channel | 20040000 | error.core.channel.exceptions |
| pamirs-resource | 20050000 | error.core.resource.exceptions |
| pamirs-user | 20060000 | error.core.user.exceptions |
| pamirs-auth | 20070000 | error.core.auth.exceptions |
| pamirs-message | 20080000 | error.core.message.exceptions |
| pamirs-international | 20090000 | error.core.international.exceptions(未正确定义) |
| pamirs-translate | 20100000 | error.core.translate.exceptions(未正确定义) |
| pamirs-scheduler(已作废)pamirs-data-audit | 20110000 | error.core.schedule.exceptions(已作废)error.core.data.audit.exceptions |
| pamirs-trigger | 20120000 | error.core.trigger.exceptions(未正确定义) |
| pamirs-file2(原pamirs-file) | 20130000 | error.core.file.exceptions(未正确定义) |
| pamirs-eip2(原pamirs-eip2) | 20140000 | error.core.eip.exceptions(未正确定义) |
| pamirs-third-party-communication | 20150000 | error.core.third-party-communication.exceptions(未定义) |
| pamirs-third-party-map | 20160000 | error.core.third-party-map.exceptions(未定义) |
| pamirs-business | 20170000 | error.core.business.exceptions(未定义) |
| pamirs-web | 20180000 | error.core.web.exceptions |
| pamirs-studio(已作废) | 20190000 | error.core.studio.exceptions(未正确定义) |
| pamirs-workflow | 20200000 | error.core.workflow.exceptions |
| pamirs-apps | 20210000 | AppsExpEnumerate |
| pamirs-paas | 20220000 | PaasExpEnumerate |
pamirs-model-designer异常枚举(20300000)
| pamirs-model-designer | 20300000 | ModelDesignerExp |
pamirs-workflow异常枚举(20310000-20320000)
| pamirs-workflow | 20310000 | WorkflowExpEnumerate |
|---|---|---|
| pamirs-workflow-designer | 20320000 | WorkflowDesignerExpEnumerate |
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9237.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验