
一、说明
Oinone目前的默认文案是中文,如果需要使用其他语言,Oinone也提供一系列的翻译能力。
二、定义语言文件
在src/local下新增一个名为zh_cn.ts文件:

编辑zh_cn.ts文件,增加以下内容:
const zhCN = {
demo: {
test: '这是测试'
}
}
export default zhCN在mian.ts注册语言资源:
import { LanguageType, registryLanguage} from '@kunlun/dependencies';
import Zh_cn from './local/zh_cn'
registryLanguage(LanguageType['zh-CN'], Zh_cn);三、Vue模板使用
<template>
<div class="petFormWrapper">
<form :model="formState" @finish="onFinish">
<a-form-item :label="translate('demo.test')" id="name" name="kind" :rules="[{ required: true, message: '请输入品种种类!', trigger: 'focus' }]">
<a-input v-model:value="formState.kind" @input="(e) => onNameChange(e, 'kind')" />
<span style="color: red">{{ getServiceError('kind') }}</span>
</a-form-item>
<a-form-item label="品种名" id="name" name="name" :rules="[{ required: true, message: '请输入品种名!', trigger: 'focus' }]">
<a-input v-model:value="formState.name" @input="(e) => onNameChange(e, 'name')" />
<span style="color: red">{{ getServiceError('name') }}</span>
</a-form-item>
</form>
</div>
</template>
<script lang="ts">
import { defineComponent, reactive } from 'vue';
import { Form } from 'ant-design-vue';
export default defineComponent({
// 引入translate
props: ['onChange', 'reloadData', 'serviceErrors', 'translate'],
components: { Form },
setup(props) {
const formState = reactive({
kind: '',
name: '',
});
const onFinish = () => {
console.log(formState);
};
const onNameChange = (event, name) => {
props.onChange(name, event.target.value);
};
const reloadData = async () => {
await props.reloadData();
};
const getServiceError = (name: string) => {
const error = props.serviceErrors.find(error => error.name === name);
return error ? error.error : '';
}
return {
formState,
reloadData,
onNameChange,
onFinish,
getServiceError
};
}
});
</script>效果

四、JS使用-translate
<template>
<div class="petFormWrapper">
<form :model="formState" @finish="onFinish">
<a-form-item :label="translate('demo.test')" id="name" name="kind" :rules="[{ required: true, message: '请输入品种种类!', trigger: 'focus' }]">
<a-input v-model:value="formState.kind" @input="(e) => onNameChange(e, 'kind')" />
<span style="color: red">{{ getServiceError('kind') }}</span>
</a-form-item>
<a-form-item label="品种名" id="name" name="name" :rules="[{ required: true, message: '请输入品种名!', trigger: 'focus' }]">
<a-input v-model:value="formState.name" @input="(e) => onNameChange(e, 'name')" />
<span style="color: red">{{ getServiceError('name') }}</span>
</a-form-item>
</form>
</div>
</template>
<script lang="ts">
import { defineComponent, reactive, onMounted } from 'vue';
// 引入
import { translate } from '@kunlun/dependencies';
import { Form } from 'ant-design-vue';
export default defineComponent({
props: ['onChange', 'reloadData', 'serviceErrors', 'translate'],
components: { Form },
setup(props) {
const formState = reactive({
kind: '',
name: '',
});
const onFinish = () => {
console.log(formState);
};
const onNameChange = (event, name) => {
props.onChange(name, event.target.value);
};
const reloadData = async () => {
await props.reloadData();
};
const getServiceError = (name: string) => {
const error = props.serviceErrors.find(error => error.name === name);
return error ? error.error : '';
}
onMounted(() => {
// 使用
const test = translate('demo.test');
console.log(test);
});
return {
formState,
reloadData,
onNameChange,
onFinish,
getServiceError
};
}
});
</script>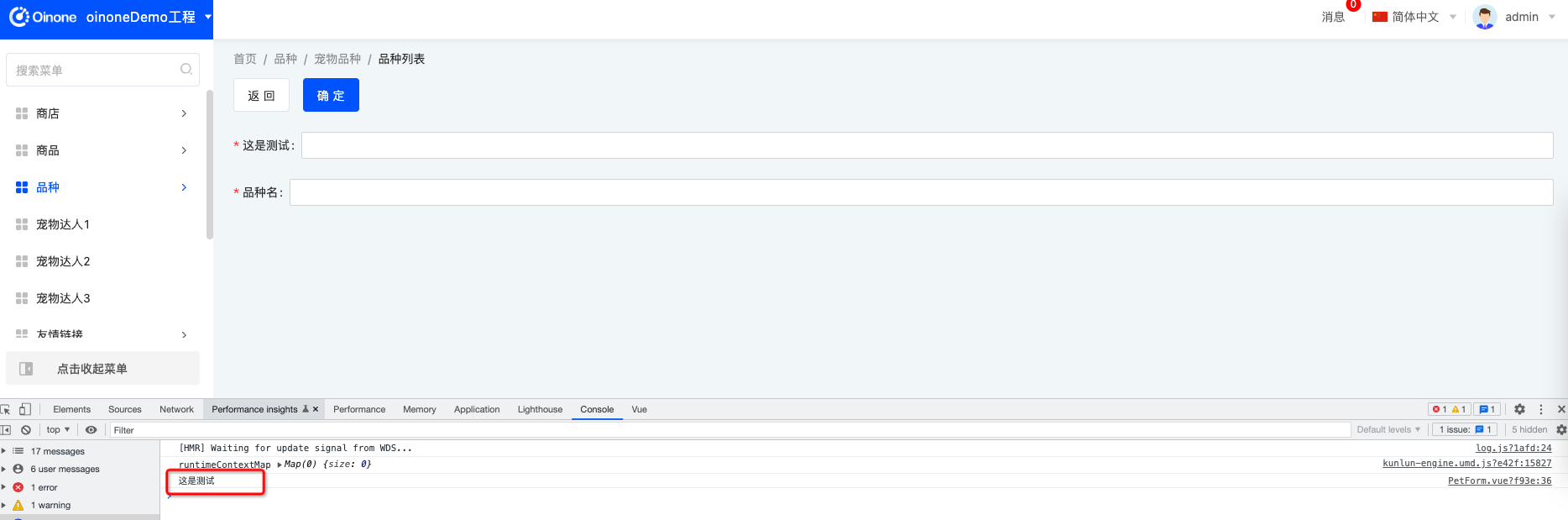
五、JS使用-translateValueByKey
translateValueByKey和translate的区别是,获取资源的路径不同,translate从前端定义中获取对应的翻译,translateValueByKey是从平台翻译功能中配置得来。建议使用
import { translateValueByKey } from '@kunlun/dependencies';
translateValueByKey("中文名称") || "默认值"六、翻译dslNode
处理xml的国际化
import { translateNode } from '@kunlun/translateValueByKey';
translateNode(dslNode);Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9308.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验