
如果说低代码开发框架输出技术标准,CDM则是结合oinone技术特性和软件工程设计,让输出数据标准变成可能。
一、背景介绍
无法照搬的最佳实践
要了解引入CDM的初衷,得从互联网架构的演进开始,了解其过程,就知道为什么说Oinone的CDM是中台架构的最佳技术实践的核心!我们在2.2【互联架构做为最佳实践为何失效】一文中介绍过互联网技术发展的四个阶段,特别平台化到中台化的阶段,目的是在一套规范下让听的见炮火声音的团队自行决定业务系统发展,适用多业务线(或多场景应用)独立发展。
互联网架构在演进过程中碰到的问题跟企业数字化转型过程中碰到的问题是非常类似:
-
随着企业业务在线化后对系统性能、稳定都提出了更高的要求,而且大部分企业的内部很多系统相互割裂导致,导致很多重复建设,所以我们需要服务化、平台化。
-
同时没有一个供应商能解决企业所有商业场景问题,又需要多个供应商共同参与,所以把供应商类类比成各个业务线,在一套规范下让供应商自行决定业务系统发展
既然跟阿里当初在架构演进过程中碰到的问题非常类似,那么是不是照搬阿里中台架构方案到企业就好了?当然不是,因为历史原因阿里的中台架构是采用的平台共建模式:“让业务线研发以平台设计好的规范进来共同开发”,其本质还是平台主导模式,它是有非常大的历史包袱。我们想象各个供应商的共建一个交易平台或商品平台,那是多么荒唐的事情,平台化已经足够的复杂了,还让不同背景、不同企业的研发一起共建,最后往往导致企业架构负载过重,这时对企业来说便不再是赋能而是“内耗”。
那么如果没有历史包袱,我们重新设计,站在上帝视角去看有没有更好的方式呢?当然有
借鉴微软的CDM
这里我们借鉴微软的CDM理念,CDM这个概念最早是2016年微软宣布“以Dynamics 365的形式改造其CRM和ERP”战略时提出的。微软给它的定义是“用于存储和管理业务实体的业务数据库,而且是开箱即用的”。CDM不仅仅提供标准实体,它还允许用户建立个性化的实体,用户可以扩展标准实体也可以增加和标准实体相关的新实体。
CDM可能并不性感,但绝对是非常必要的。它成为了微软的很多产品的基础,是构建了无数业务领域的原型。同时微软也期望它能成为快速实现数据交换和迁移的标准,这个有点像菜鸟网络推出的奇门,让所有TMS、OMS、WMS都基于一套数据接口API进行互通,一套标准是为了解决一个行业问题,而不是具体某一个企业一个集团的问题。
我们发现CDM的理念跟我们想要的“企业级的数据标准”是非常吻合的。但是我们也不能照搬照抄,虽然微软的CDM很好的解决了数据割裂问题,但就模型来说就够大家喝一壶了,模型库非常庞大而且复杂,学习成本巨高。
数字化时代软件会产生新的技术流派
我们知道传统软件的设计理念:侧重在模型对业务支撑全面性上。优点体现为配置丰富,缺点模型设计过于复杂,刚开始有前瞻性,但在理解、维护都非常困难,随着业务发展系统原先的设计逐渐腐化,异常笨重。
而Oinone的CDM设计理念:侧重在简单、灵活、统一上,体现为在上层应用开发时,每一业务领域保持独立,模型简单易懂,并结合Oinone的低代码开发机制进行快速开发,灵活应对业务变化。
所以我更想说Oinone的CDM是微软CDM的在原有基础上,与互联网架构结合,利用Oinone低代码开发平台特性形成新的工程化建议。Oinone-CDM不以把模型抽象到极致,支撑“所有业务可能性”为目标,而是抽象80%通用的设计,保持模型简单可复用,来解决数据割裂问题,并保持业务线独立自主性,快速创新的能力。

二、Oinone的CDM本质是创新的工程化建议
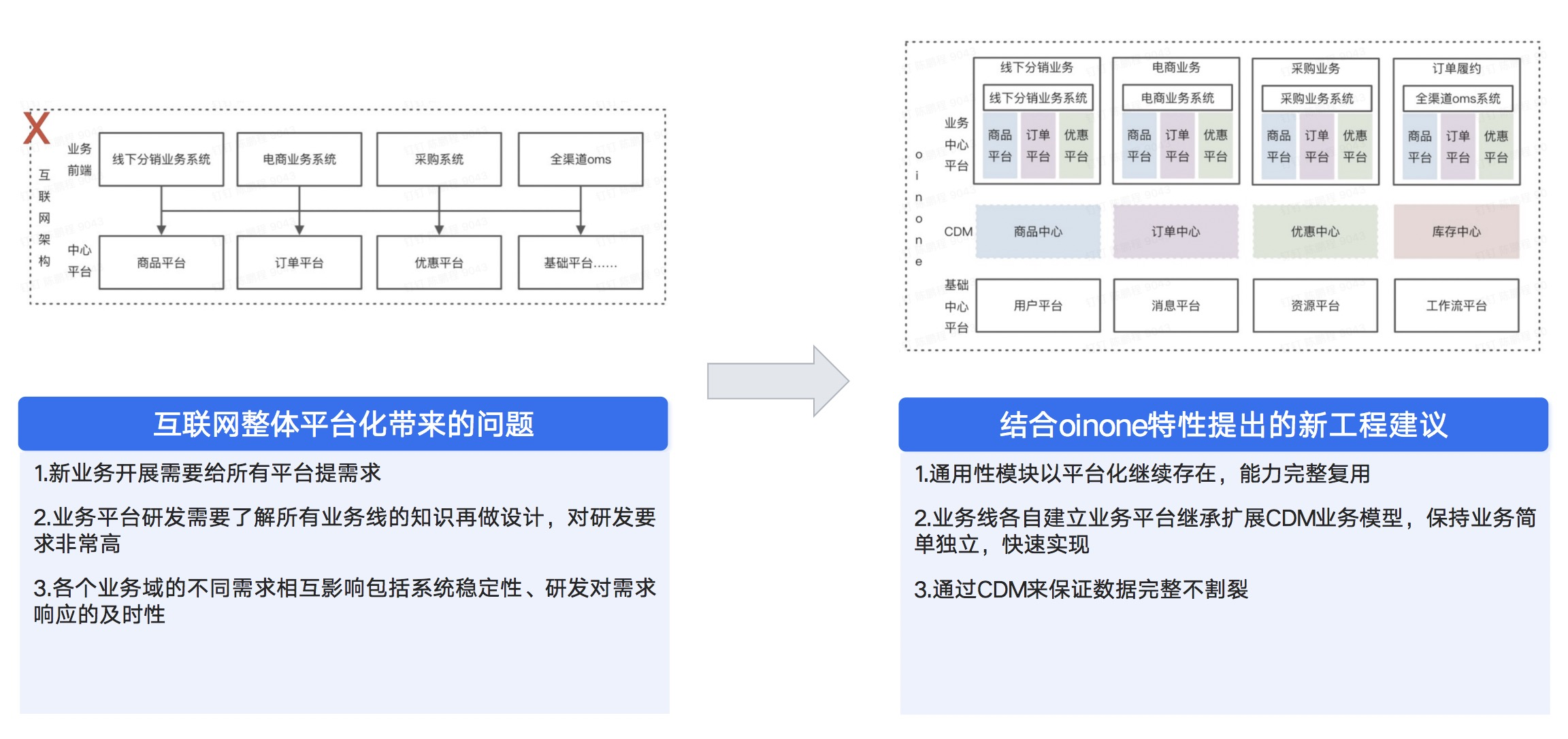
引入CDM以后系统工程结构会有什么变化,跟大家认知的互联网架构有什么区别。
原本上层的业务线系统,需要调用各个业务平台提供的功能,增加CDM以后也就是我们右的图,每个业务线就像一个独立右边。看上去复杂了,其实对业务线来说更加简单了。
互联网整体平台化带来的问题:
-
业务线每次业务调整都需要给各个平台提需求
-
业务平台研发需要了解所有业务线的知识再做设计,对研发要求非常高
-
各个业务域的不同需求相互影响包括系统稳定性、研发对需求响应的及时性
结合oinone特性提出的新工程建议:
-
一些通用性模块继续以平台化的方式存在,能力完全复用。
-
业务线自建业务平台,保持业务线的独立性和敏捷性
-
业务线以CDM为原型,保证核心数据不割裂,形成一致的数据规范
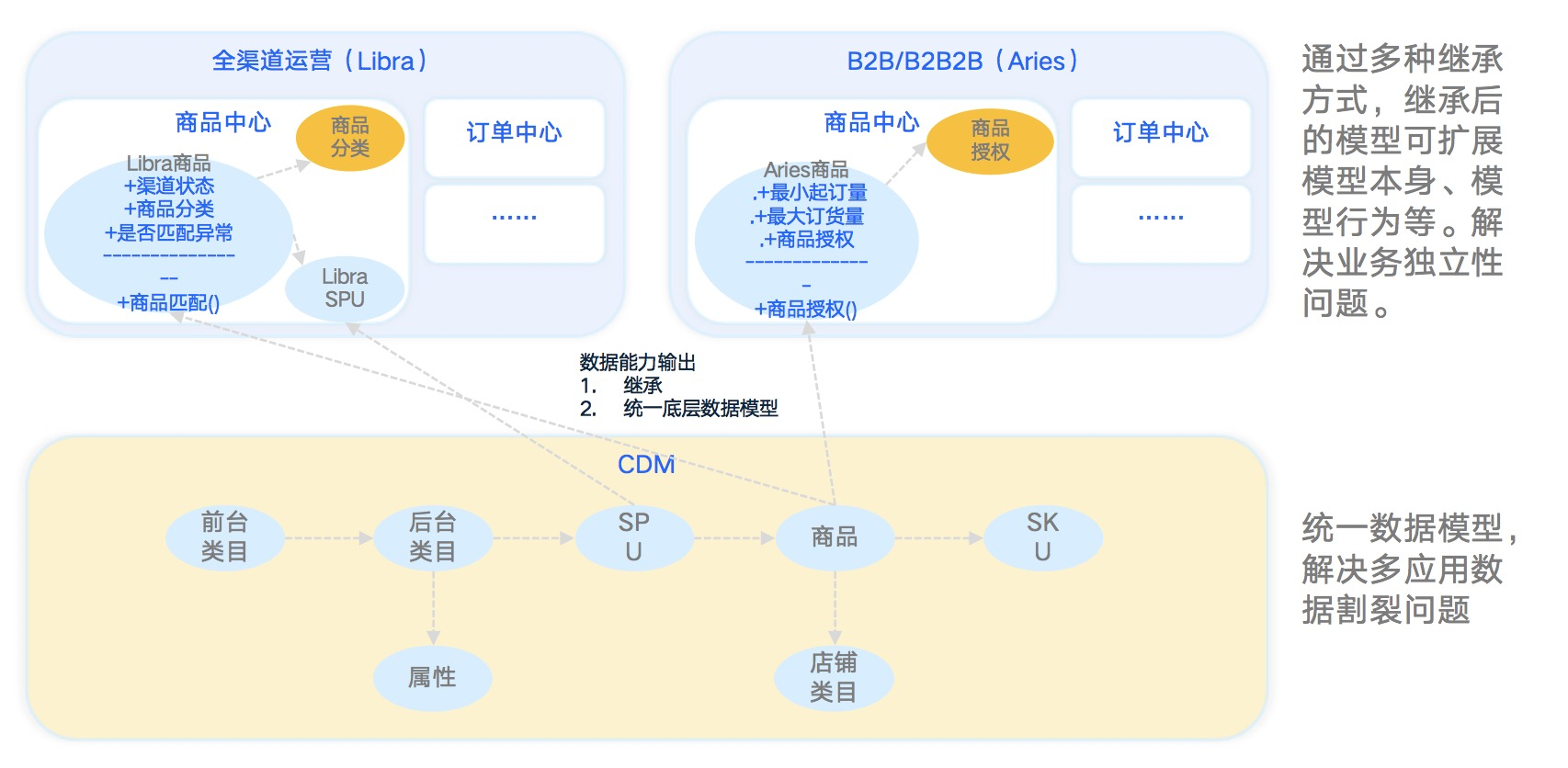
三、CDM思路示意图
该示例中OinoneCDM的商品域不仅仅提供标准实体,保证各个业务系统的对商品的通用需求、简单易懂,在我们星空系列业务产品中如全渠道运营、B2B交易等系统以此为基础建立属于自身个性化的实体,可以扩展标准实体也可以增加和标准实体相关的新实体。
带来的好处:
-
通过多种继承方式,继承后的模型可扩展模型本身、模型行为等,从而解决业务独立性问题。
-
通过CDM层统一数据模型,从而解决多应用数据割裂问题
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9316.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验