
1. 功能说明
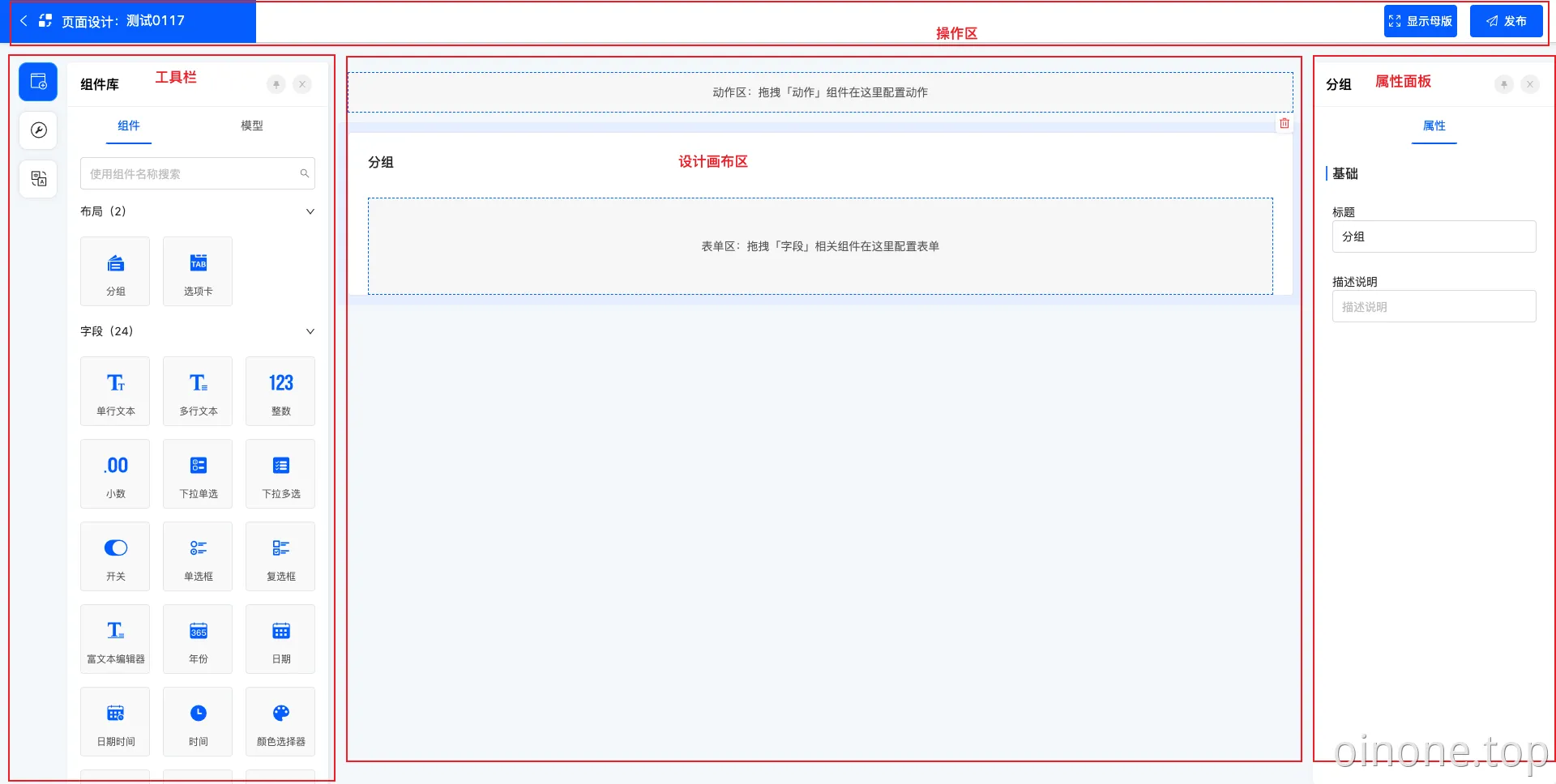
页面设计时界面设计器中「页面」模块的设计入口,在这个界面,进行页面的设置、搭建、设计、排版。
主要分为顶部操作栏、左侧工具栏、中部设计画布区、右侧属性面板。

2. 操作栏
进入页面设计,顶部显示了页面的标题,以及返回、发布等操作。
2.1 发布
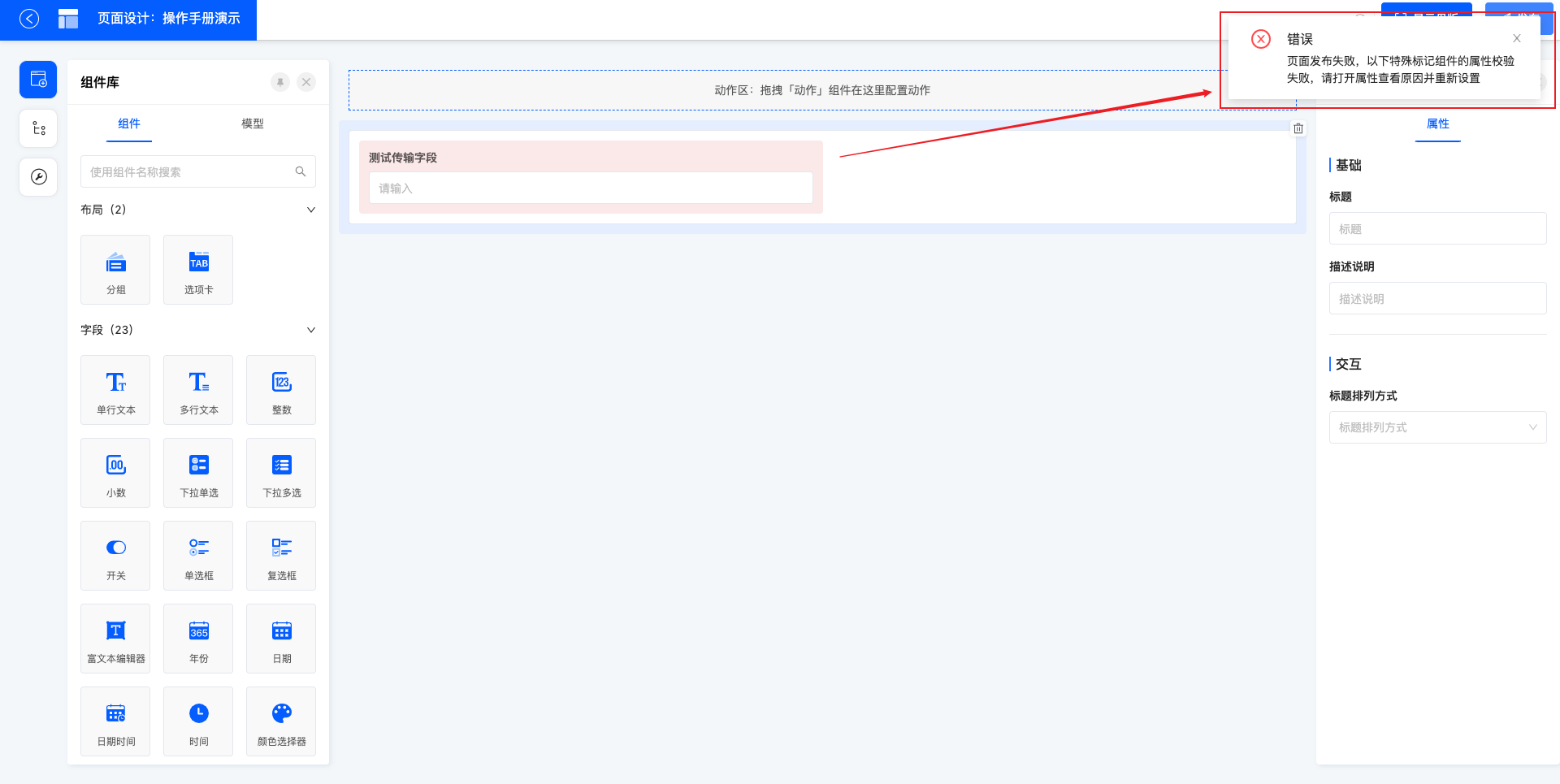
页面设计完成后,点击「发布」运行页面生效。若不点击发布,页面也有自动保存的功能,但在发布前,自动保存也等同于草稿,不会正式生效。
发布时如果有属性不符合校验规则(必填的属性未填、输入的内容校验不通过),会发布失败,相应的字段会特殊标记,需要查看并修改属性。
2.2 显示/隐藏母版
进入页面设计时默认不展示母版,可以手动操作显示母版
3. 工具栏
左侧的工具栏中包括组件库、页面设置等模块。
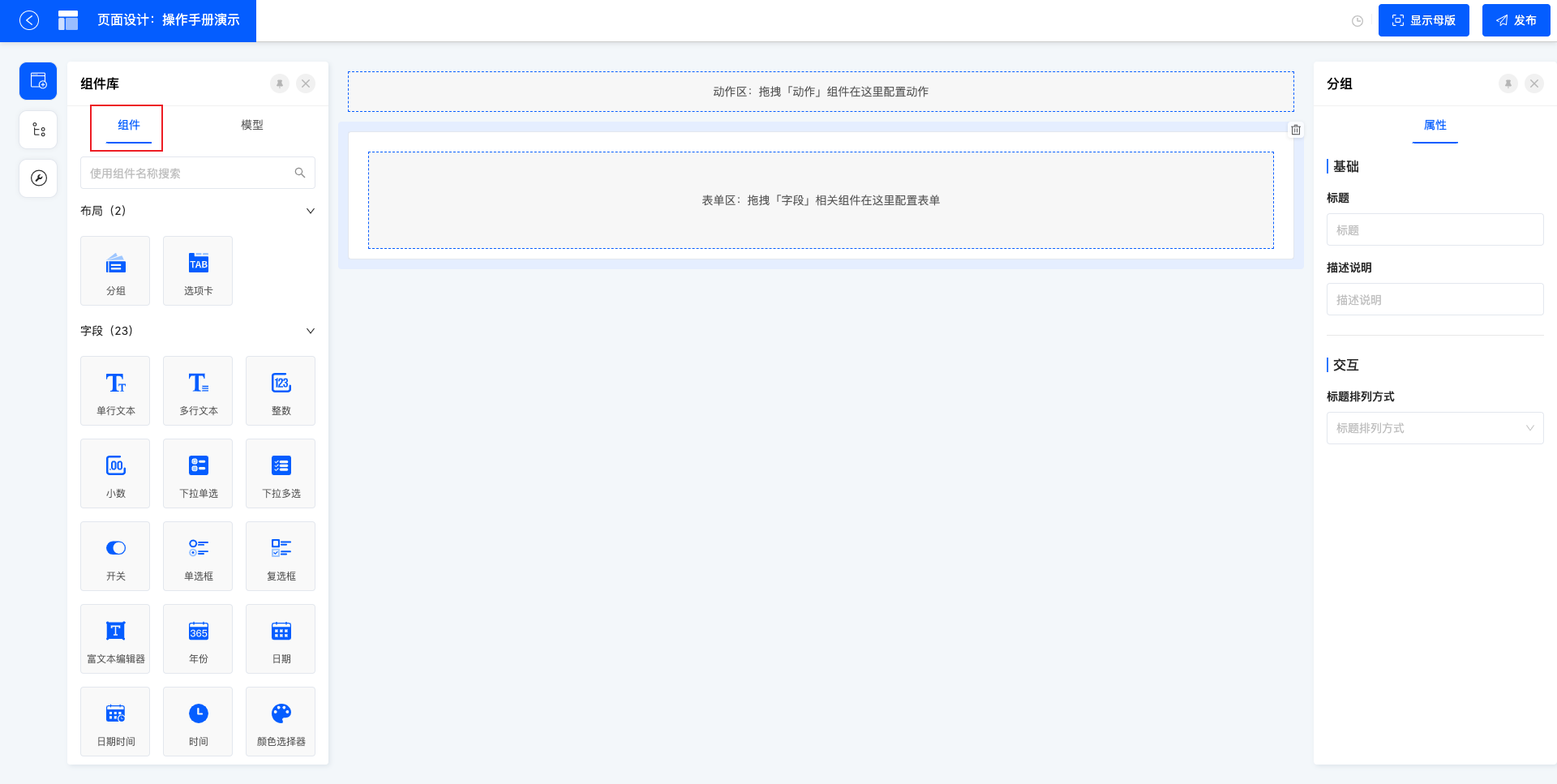
3.1 组件库
组件库中包含组件和模型,组件是当前设计器支持的所有组件,模型是页面所在模型下的所有字段和动作。
3.1.1 组件
组件中展示了系统支持的所有组件。包含
1)布局类组件,如分组、选项卡等,使用布局组件可以将页面进字段分类、分页;
2)字段类组件,如单行文本、整数、日期等等,使用字段类组件时都会在模型下对应创建一个字段;
3)动作类组件,如跳转动作、提交动作、链接动作等。
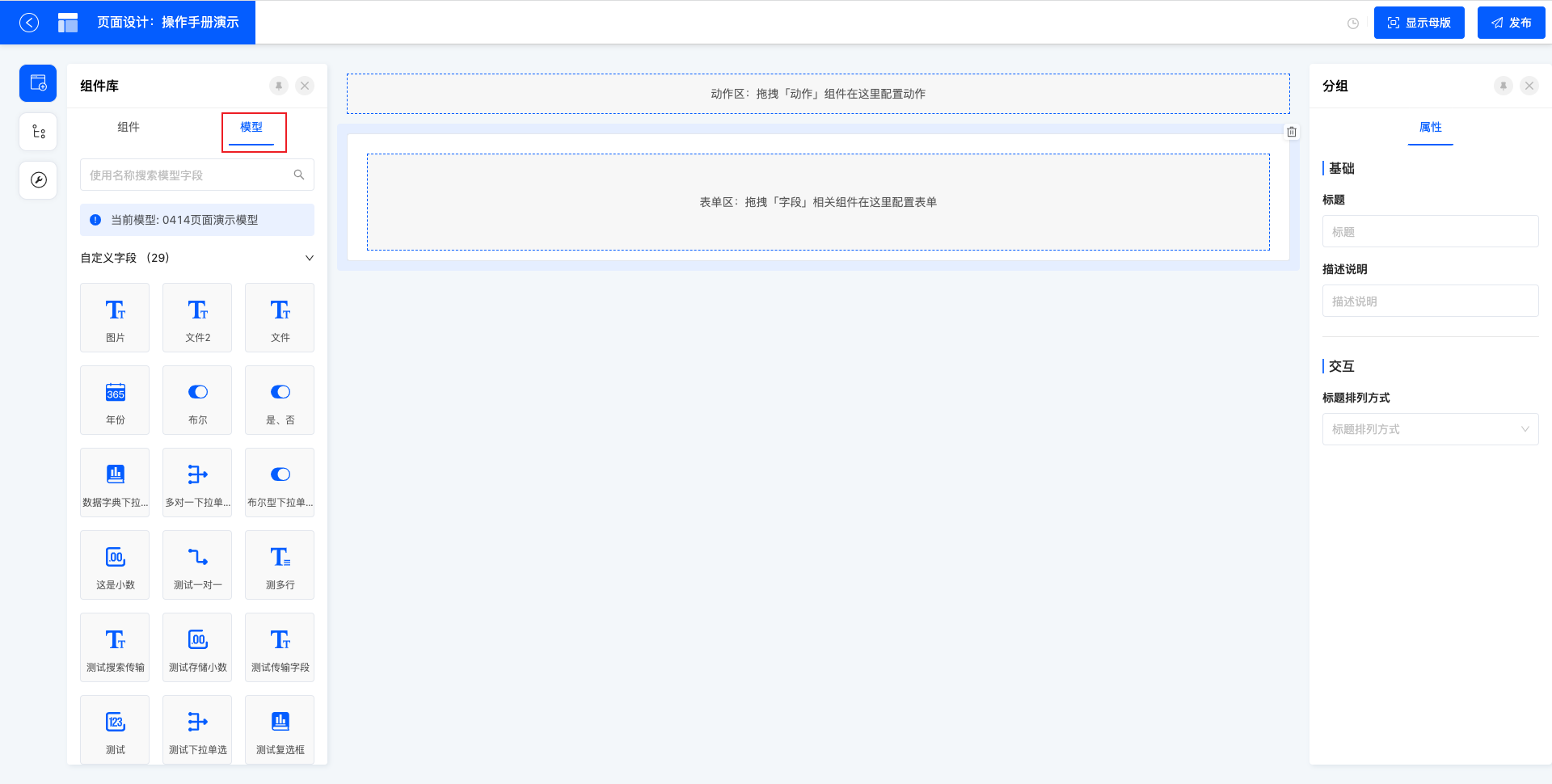
3.1.2 模型
组件库顶部,由组件可切换为模型:模型选项下,会展示当前模型的所有字段,以及系统默认动作。可以直接拖拽字段至设计画布中,会应用形成某个组件,可对组件进行多样的属性设置,优化交互。
3.1.2 组件和模型有什么区别
1展示内容维度不同
组件中展示的内容是组件信息,如分组、选项卡、单行文本、文件上传等;模型中展示的是模型下已有的所有字段。
2使用功能不同
组件中的组件使用前需要在模型中创建一个字段,当然,创建好的字段也会存在于模型中;模型中的字段可直接使用,并且使用时会在设计画布中对应生成个默认组件。
3使用场景不同
如果模型中已经存在目标字段,应直接选择从模型中拖拽字段;如果模型中没有需要的字段,可以在页面中增加一个组件,实际上也是在新增一个字段。
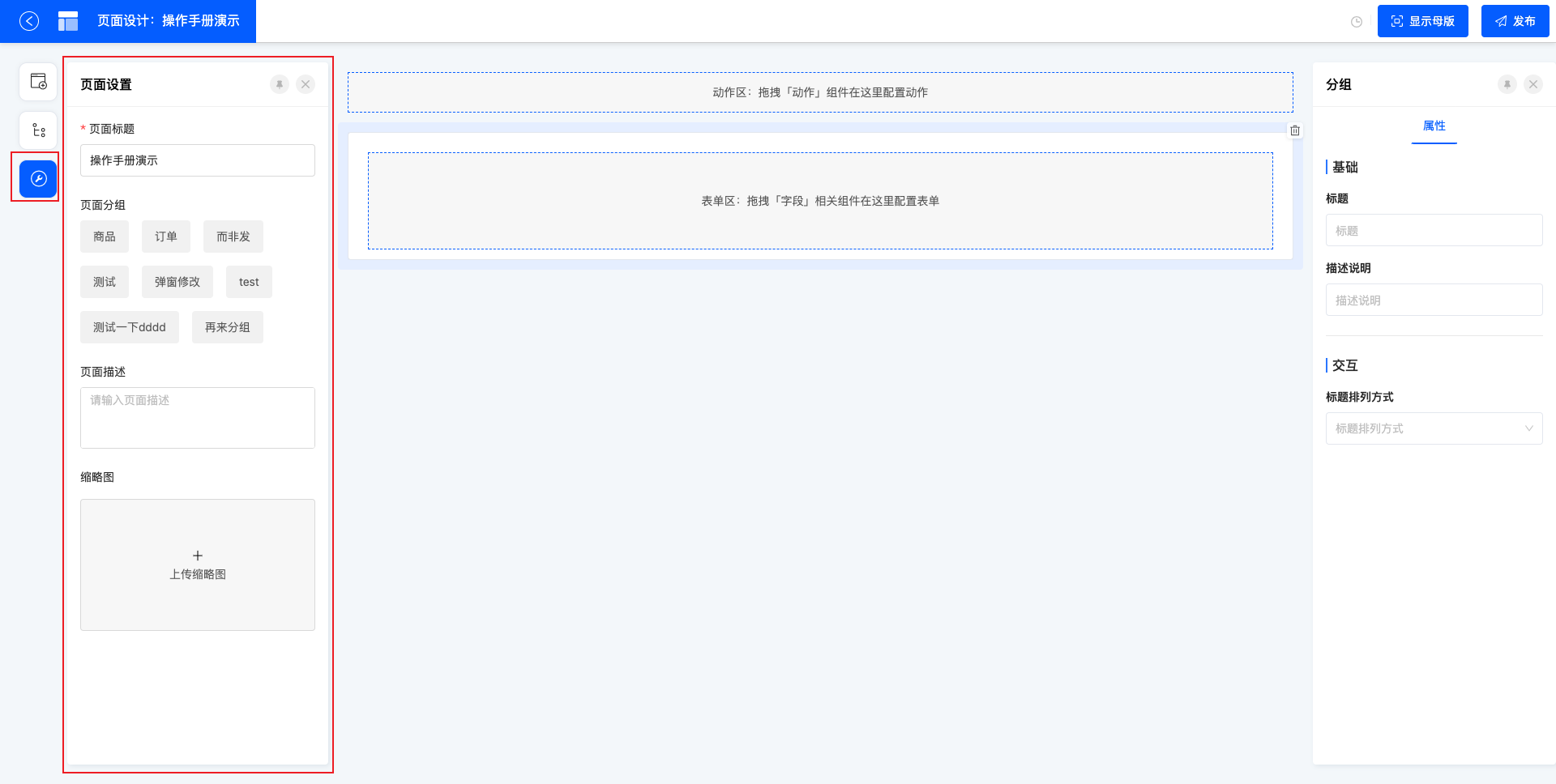
3.2 页面设置
页面设置中可以修改当前页面的标题、分组、页面描述,同时也是给页面上传缩略图的唯一入口。
4. 设计画布
将组件或字段拖拽至设计画布区,会生成样式。点击组件,右侧可对其进行设置,大部分属性可实时在画布中展示效果。
5. 属性面板
右侧属性面板抽屉中可以设置属性或查看字段信息,通过不同的属性配置化实现组件的多样化。
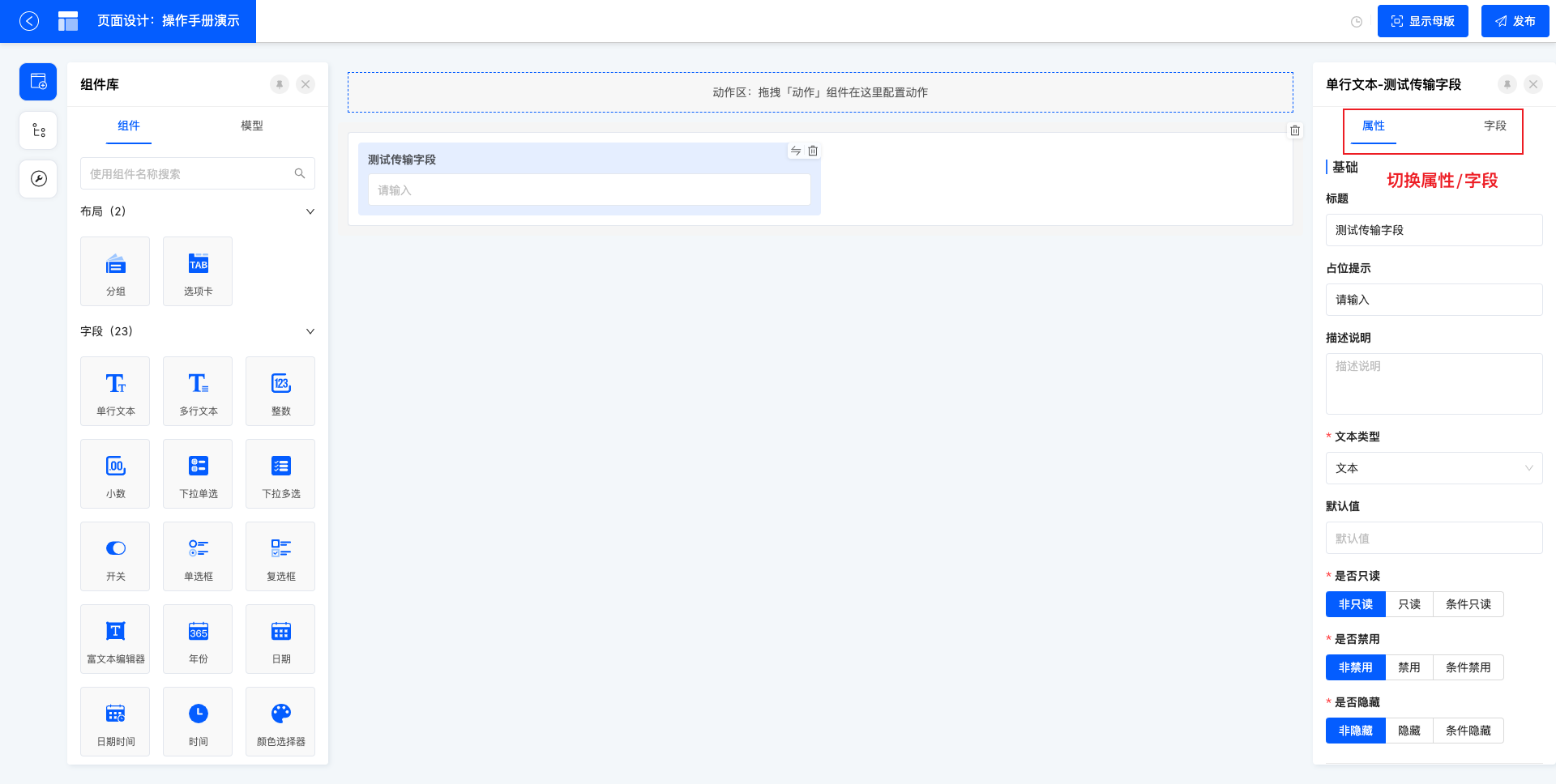
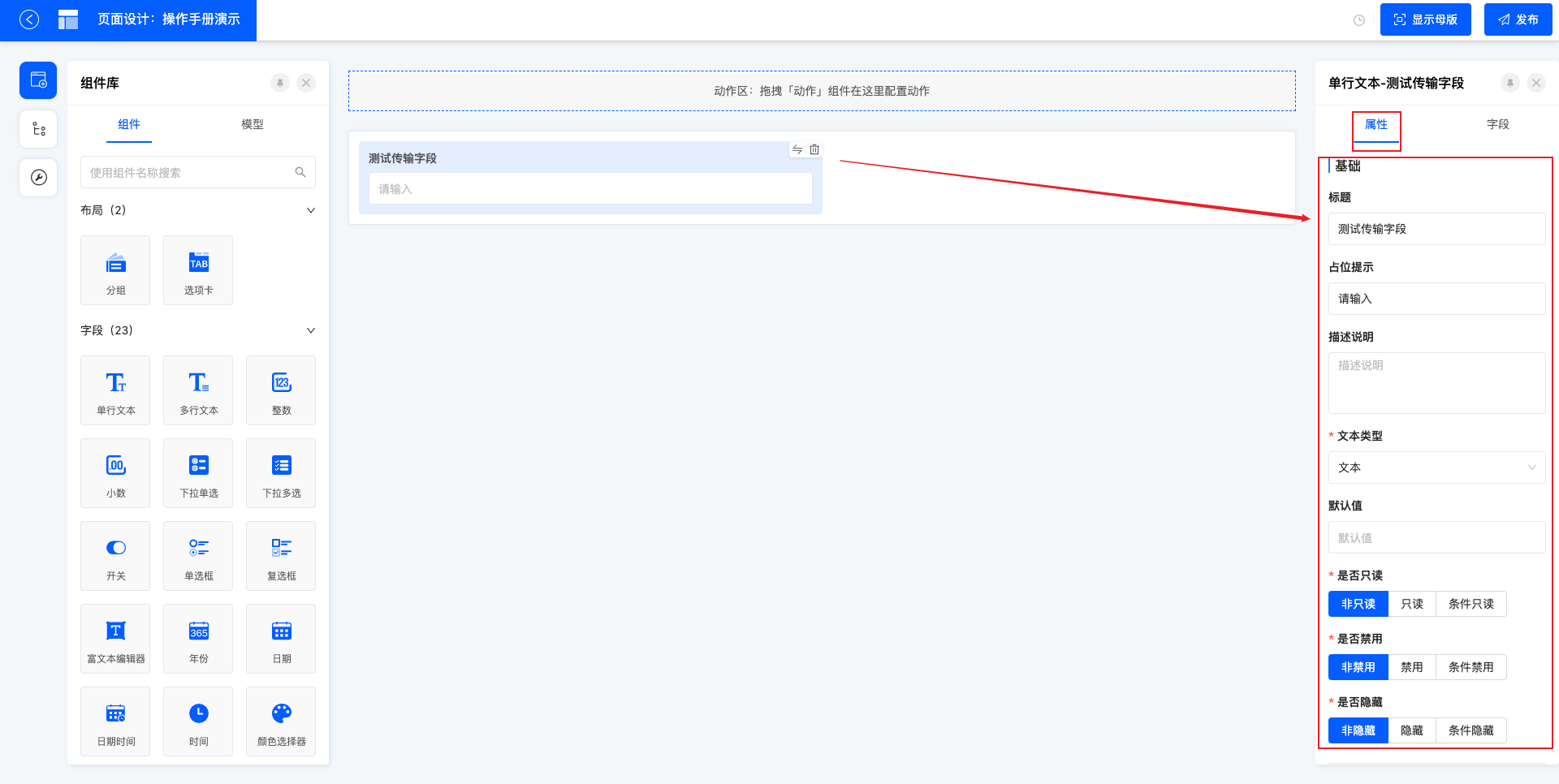
5.1 属性
属性中包括基本信息(如标题、占位提示、描述说明等)、校验信息(如是否必填、长度校验等)、交互信息(如排序方式、是否展示计数器等)
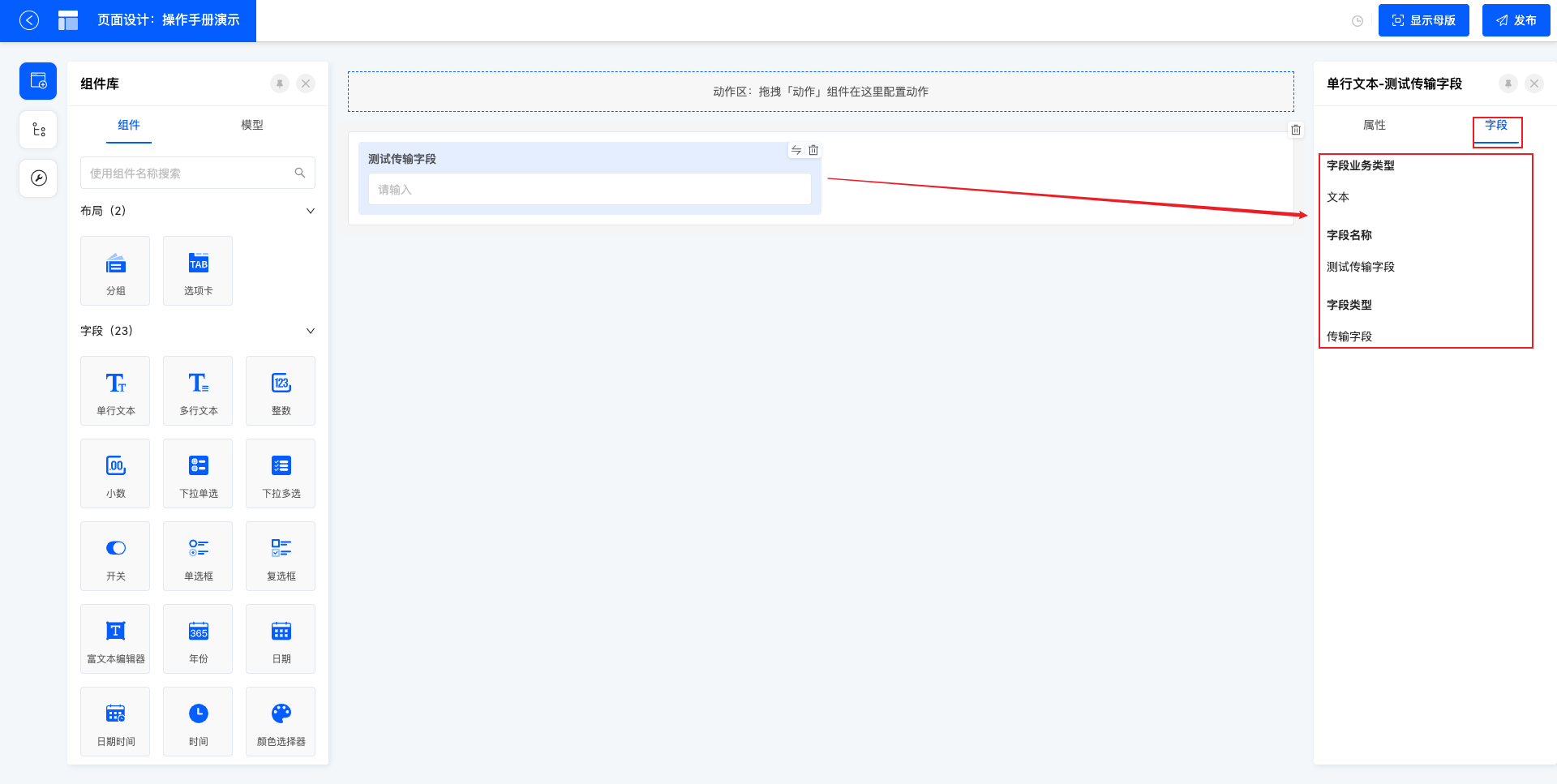
5.2 字段
首次从组件中拖拽,会先展示字段信息,并且是需要先创建一个字段,字段创建成功后,再次切换字段选项,只读展示当前组件所对应的字段基本信息。同理,如果是直接从字段中拖拽,字段选项中,只读展示当前字段基本信息。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9405.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验