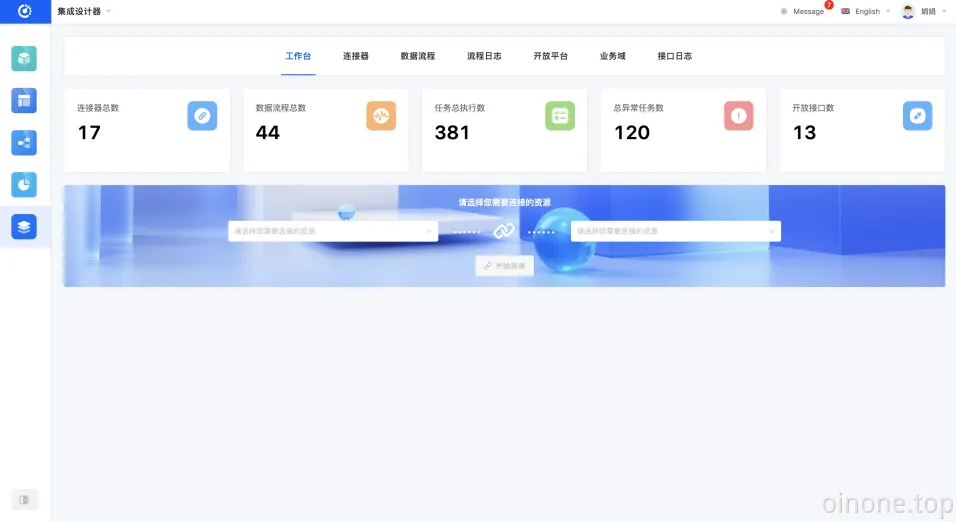
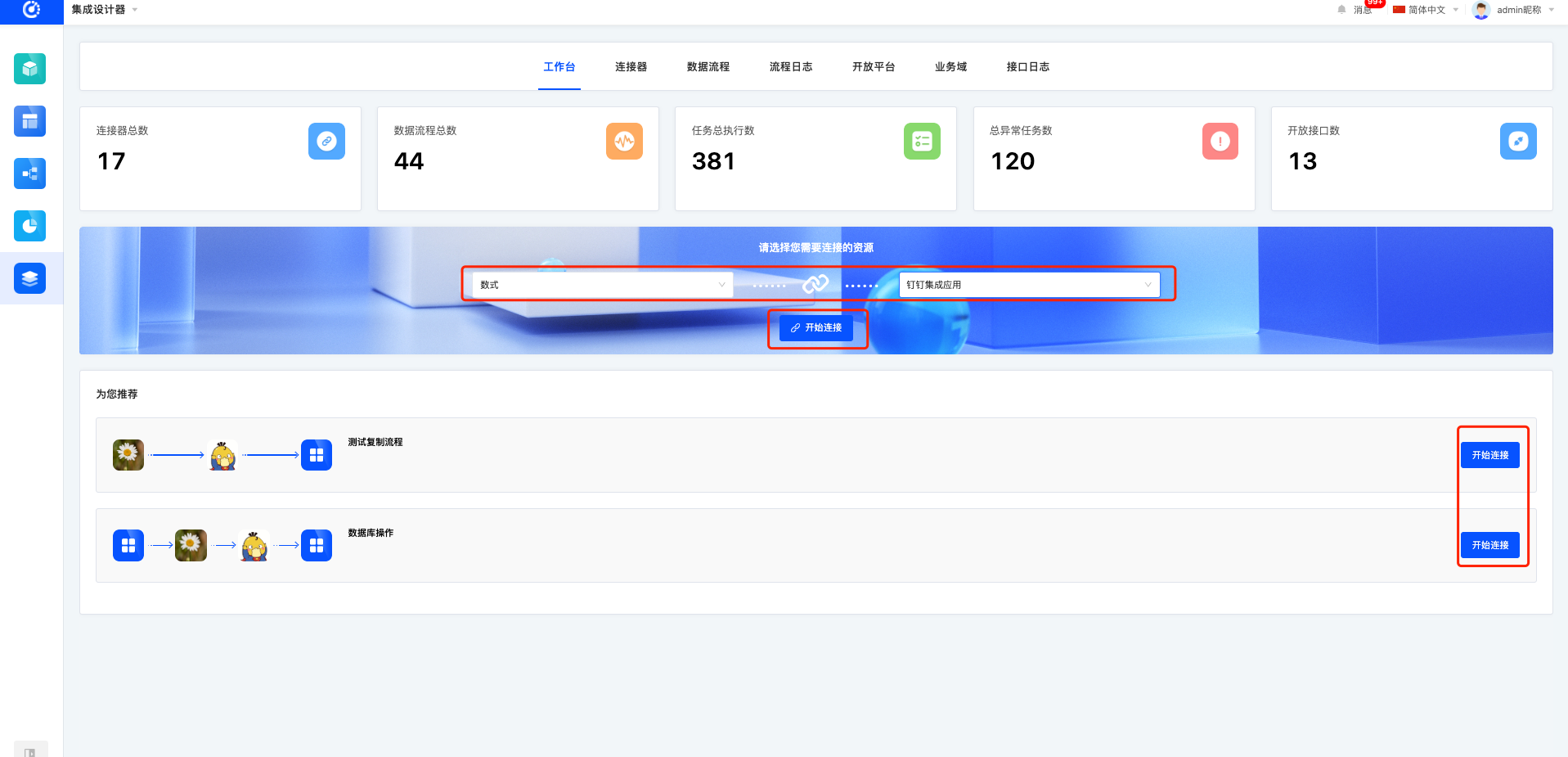
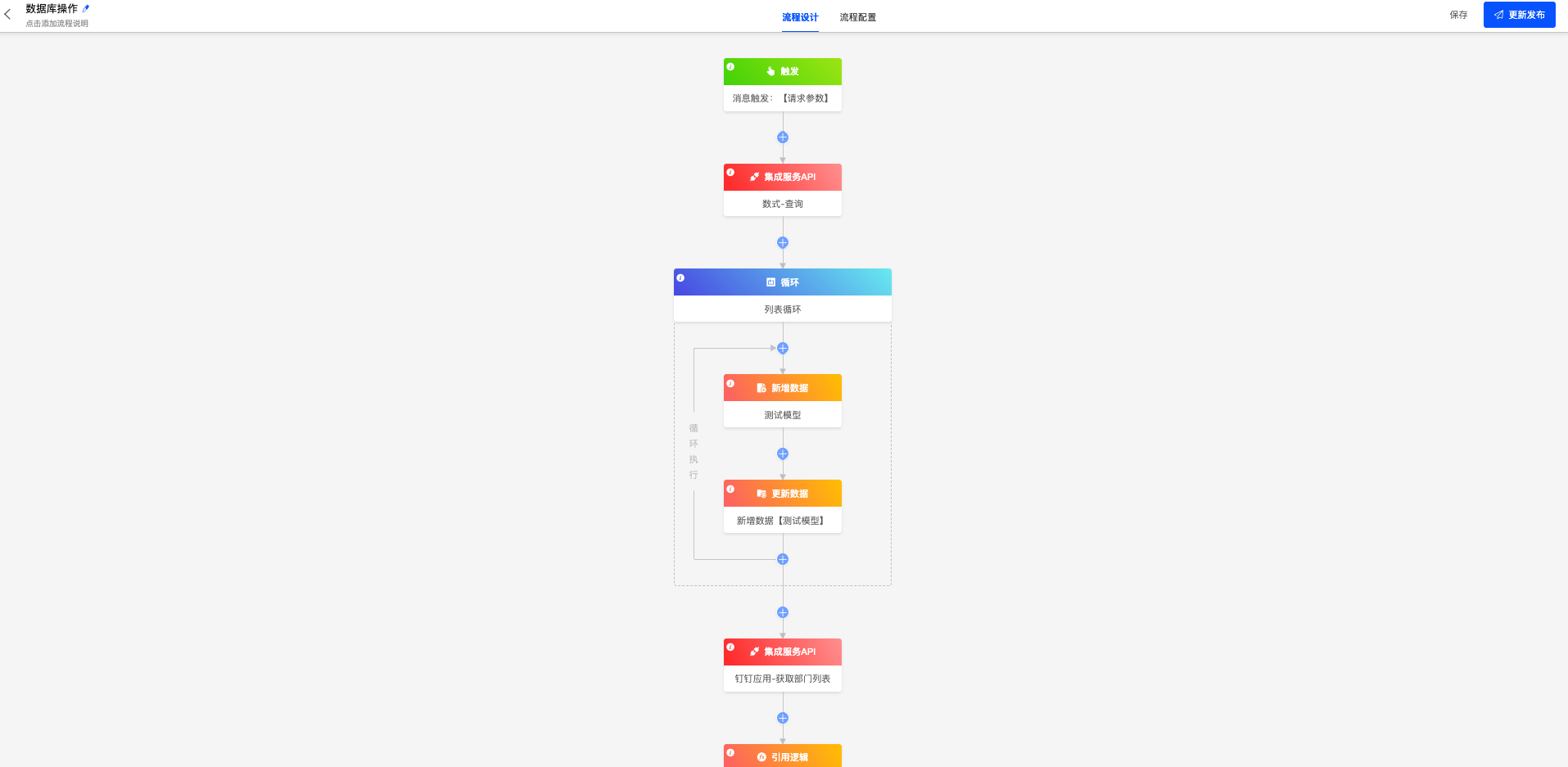
一、RSQL / FIQL parser RSQL是一种查询语言,用于对RESTful API中的条目进行参数化过滤。它基于FIQL(Feed Item Query Language)——一种URI友好的语法,用于跨Atom Feed中的条目表达过滤器。FIQL非常适合在URI中使用,没有不安全的字符,因此不需要URL编码。另一方面,FIQL的语法不太直观,URL编码也不总是那么重要,因此RSQL还为逻辑运算符和一些比较运算符提供了更友好的语法。 例如,您可以像这样查询资源:/movies?query=name=="Kill Bill";year=gt=2003 or /movies?query=director.lastName==Nolan and year>=2000。详见以下示例: 这是一个用JavaCC和Java编写的完整且经过彻底测试的RSQL解析器。因为RSQL是FIQL的超集,所以它也可以用于解析FIQL。 语法和语义 以下语法规范采用EBNF表示法(ISO 14977)编写。 RSQL表达式由一个或多个比较组成,通过逻辑运算符相互关联: Logical AND : ; or and Logical OR : , or or 默认情况下,AND运算符优先(即,在任何OR运算符之前对其求值)。但是,可以使用带括号的表达式来更改优先级,从而产生所包含表达式产生的任何结果。 input = or, EOF; or = and, { "," , and }; and = constraint, { ";" , constraint }; constraint= ( group | comparison ); group = "(", or, ")"; 比较由选择器、运算符和参数组成。 comparison=选择器、比较运算、参数; 选择器标识要筛选的资源表示形式的字段(或属性、元素…)。它可以是任何不包含保留字符的非空Unicode字符串(见下文)或空格。选择器的特定语法不由此解析器强制执行。 selector=未保留str; 比较运算符采用FIQL表示法,其中一些运算符还具有另一种语法: · Equal to : == · Not equal to : != · Less than : =lt= or < · Less than or equal to : =le= or <= · Greater than operator : =gt= or > · Greater than or equal to : =ge= or >= · In : =in= · Not in : =out= 您还可以使用自己的运算符简单地扩展此解析器(请参阅下一节)。 comparison-op = comp-fiql | comp-alt; comp-fiql = ( ( "=", { ALPHA } ) | "!" ), "="; comp-alt = ( ">" | "<" ), [ "=" ]; 参数可以是单个值,也可以是用逗号分隔的括号中的多个值。不包含任何保留字符或空格的值可以不加引号,其他参数必须用单引号或双引号括起来。 arguments = ( "(", value, { "," , value }, ")" ) | value; value = unreserved-str | double-quoted | single-quoted; unreserved-str = unreserved, {…