
在我们日常开发中会有碰到一些特殊场景,需要由前端来传一些如“当前用户Id”、“当前用户code”诸如此类只有后端才知道值的参数,那么后端占位符就是来解决类似问题的。如前端传${currentUserId},后端会自动替换为当前用户Id。
Step1 后端定义占位符
我们新建一个UserPlaceHolder继承AbstractPlaceHolderParser,用namespace来定义一个“currentUserId”的占位符,其对应值由value()决定为“PamirsSession.getUserId().toString()”,active要为真才有效,priority为优先级
package pro.shushi.pamirs.demo.core.placeholder;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.user.api.AbstractPlaceHolderParser;
@Component
public class UserPlaceHolder extends AbstractPlaceHolderParser {
@Override
protected String value() {
return PamirsSession.getUserId().toString();
}
@Override
public Integer priority() {
return 10;
}
@Override
public Boolean active() {
return Boolean.TRUE;
}
@Override
public String namespace() {
return "currentUserId";
}
}Step2 前端使用后端占位符
我们经常在o2m和m2m中会设置domain来过滤数据,这里案例就是在field中设置来过滤条件,domain="createUid == $#{currentUserId}",注意这里用的是$#{currentUserId} 而不是${currentUserId},这是前端为了区分真正变量和后端占位符,提交的时候会把#过滤掉提交。修改宠物达人表格视图的Template中search部分
<template slot="search" cols="4">
<field data="name" label="达人"/>
<field data="petTalentSex" multi="true" label="达人性别"/>
<field data="creater" />
<!-- <field data="petShops" label="宠物商店" domain="createUid == ${activeRecord.creater.id}"/>-->
<field data="petShops" label="宠物商店" domain="createUid == $#{currentUserId}"/>
<field data="dataStatus" label="数据状态" multi="true">
<options>
<option name="DRAFT" displayName="草稿" value="DRAFT" state="ACTIVE"/>
<option name="NOT_ENABLED" displayName="未启用" value="NOT_ENABLED" state="ACTIVE"/>
<option name="ENABLED" displayName="已启用" value="ENABLED" state="ACTIVE"/>
<option name="DISABLED" displayName="已禁用" value="DISABLED" state="ACTIVE"/>
</options>
</field>
<field data="createDate" label="创建时间"/>
<field data="unStore" />
</template>Step3 重启看效果
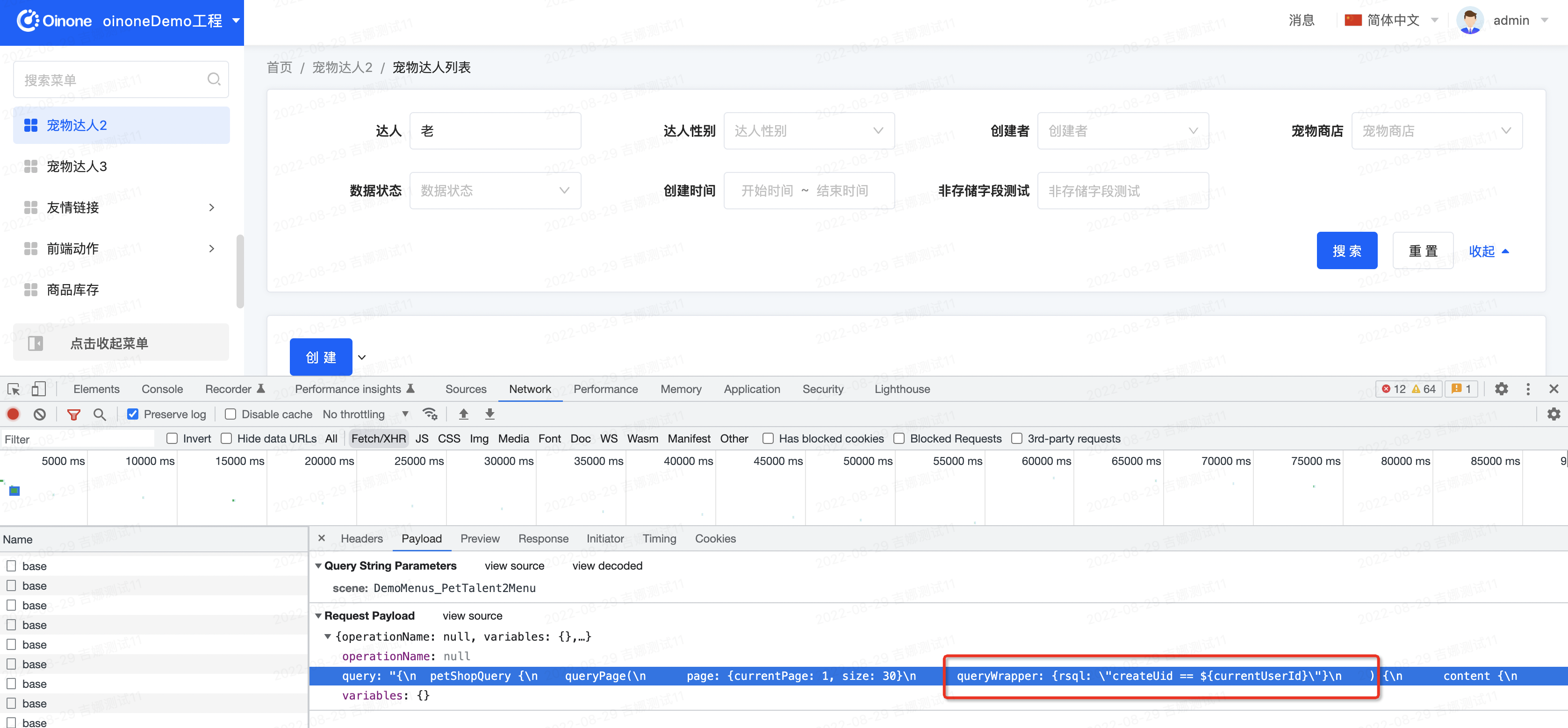
请求上都带上了createUid==${currentUserId}

Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9294.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验