
了解oinone的启动生命周期过程,对于理解oinone或者开发高级功能都有非常大的帮助
一、生命周期大图
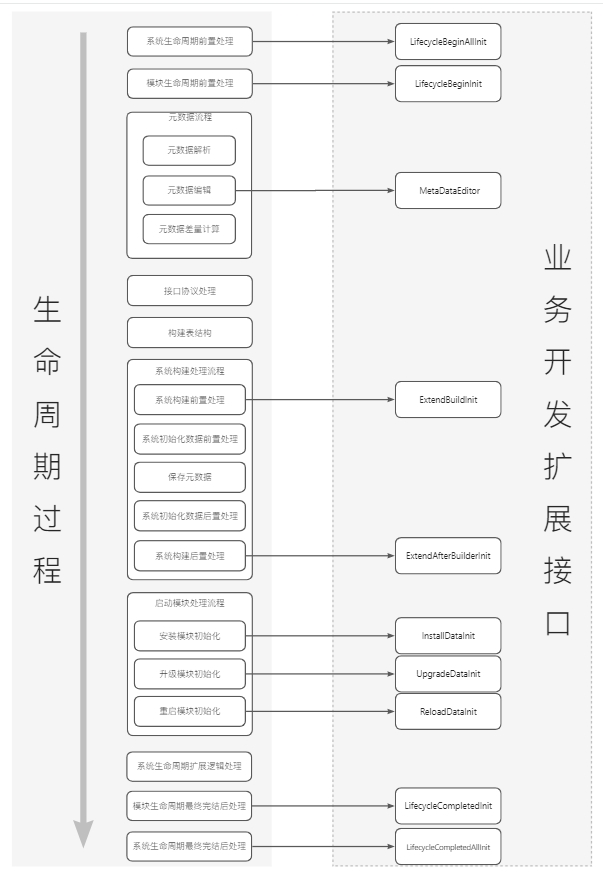

二、平台扩展说明
平台节点通过SPI机制进行扩展,本书籍暂不展开,更多详情请见可关注数式Oinone公众号中的Oinone内核揭秘系列文章。
三、业务扩展说明
| 接口 | 说明 | 使用场景 |
|---|---|---|
| LifecycleBeginAllInit | 系统进入生命周期前置逻辑注:不能有任何数据库操作 | 系统级别的信息收集上报 |
| LifecycleCompletedAllInit | 系统生命周期完结后置逻辑 | 系统级别的信息收集上报、生命周期过程中的数据或上下文清理 |
| LifecycleBeginInit | 模块进入生命周期前置逻辑注:不能有任何数据库操作 | 预留,能做的事情比较少 |
| LifecycleCompletedInit | 模块生命周期完结后置逻辑 | 本模块需等待其他模块初始化完毕以后进行初始化的逻辑。比如:1.集成模块的初始化2.权限缓存的初始化…… |
| MetaDataEditor | 元数据编辑注:不能有任何数据库操作 | 这个在第3章Oinone的基础入门中已经多次提及,核心场景是向系统主动注册如Action、Menu、View等元数据 |
| ExtendBuildInit | 系统构建前置处理逻辑 | 预留,能做的事情比较少,做一些跟模块无关的事情 |
| ExtendAfterBuilderInit | 系统构建后置处理逻辑 | 预留,能做的事情比较少,做一些跟模块无关的事情 |
| InstallDataInit | 模块在初次安装时的初始化逻辑 | 根据模块启动指令来进行选择执行逻辑,一般用于初始化业务数据。应用启动参数与指令转化逻辑详见4.1.2【模块之启动指令】一文 |
| UpgradeDataInit | 模块在升级时的初始化逻辑注:根据启动指令来执行,是否执行一次业务自己控制 | |
| ReloadDataInit | 模块在重启时的初始化逻辑注:根据启动指令来执行,是否执行一次业务自己控制 |
四、常用生命周期举例
Install\Upgrade\Reload的业务初始化(举例)
Step1 新建DemoModuleBizInit
-
DemoModuleBizInit实现InstallDataInit, UpgradeDataInit, ReloadDataInit
a. InstallDataInit 对应 init
b. UpgradeDataInit 对应 upgrade
c. ReloadDataInit 对应 reload
-
modules方法代表改初始化类与哪些模块匹配,以模块编码为准
-
priority 执行优先级
package pro.shushi.pamirs.demo.core.init;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.boot.common.api.command.AppLifecycleCommand;
import pro.shushi.pamirs.boot.common.api.init.InstallDataInit;
import pro.shushi.pamirs.boot.common.api.init.ReloadDataInit;
import pro.shushi.pamirs.boot.common.api.init.UpgradeDataInit;
import pro.shushi.pamirs.demo.api.DemoModule;
import pro.shushi.pamirs.demo.api.enumeration.DemoExpEnumerate;
import pro.shushi.pamirs.meta.common.exception.PamirsException;
import java.util.Collections;
import java.util.List;
@Component
public class DemoModuleBizInit implements InstallDataInit, UpgradeDataInit, ReloadDataInit {
@Override
public boolean init(AppLifecycleCommand command, String version) {
throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).appendMsg("DemoModuleBizInit: install").errThrow();
//安装指令执行逻辑
// return Boolean.TRUE;
}
@Override
public boolean reload(AppLifecycleCommand command, String version) {
throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).appendMsg("DemoModuleBizInit: reload").errThrow();
//重启指令执行逻辑
// return Boolean.TRUE;
}
@Override
public boolean upgrade(AppLifecycleCommand command, String version, String existVersion) {
throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).appendMsg("DemoModuleBizInit: upgrade").errThrow();
//升级指令执行逻辑
// return Boolean.TRUE;
}
@Override
public List<String> modules() {
return Collections.singletonList(DemoModule.MODULE_MODULE);
}
@Override
public int priority() {
return 0;
}
}Step2 重启看效果
启动指令为-Plifecycle=INSTALL,转化指令为 install为AUTO;upgrade为FORCE
因为DemoModule我们已经执行过好多次了,所以会进入upgrade逻辑。系统重启的效果跟我们预期的结果一致,确实执行了DemoModuleBizInit的upgrade方法
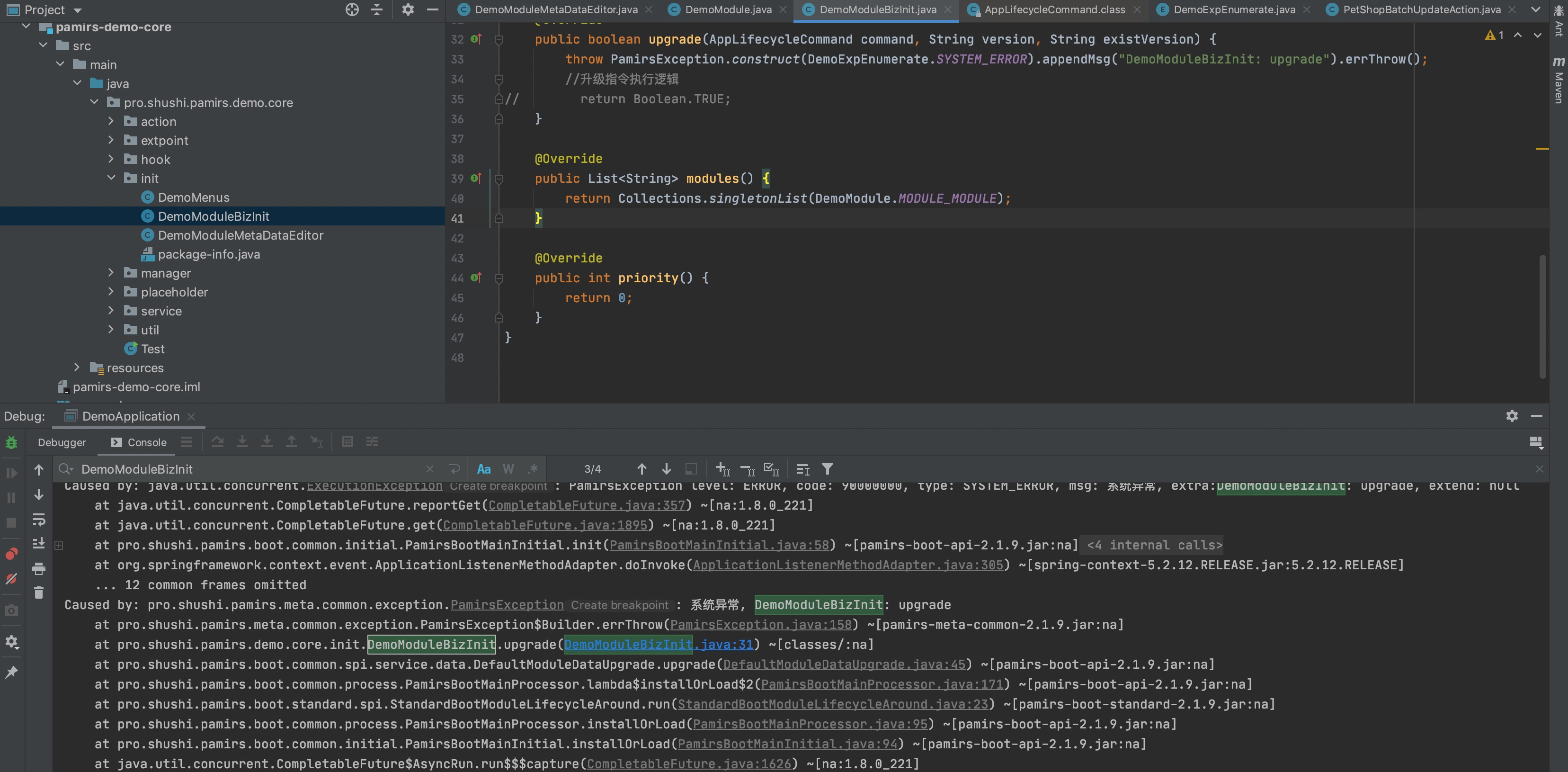
MetaDataEditor
回顾使用情况
最早在3.3.2【模型的类型】一文中介绍“传输模型”时,初始化ViewAction窗口动作时使用到,这里不过多介绍。下面主要介绍下InitializationUtil的工具类包含方法。
注:模块上报元数据只能通过注解或者实现MetaDataEditor接口并使用InitializationUtil工具来进行,更建议用注解方式
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9278.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验