
一、基础介绍
随着企业的业务不断进行数字化改造、业务越来越在线化,给企业财务工作带来几个明显的变化和挑战:
-
变化:
-
业务在线后,不同类收费、预售、授信模式的创新层出不穷,需要财务不仅只从事单一传统的会计核算工作,还需要积极地参与到业务中去。
-
从事后算账事后报账,变成财务业务一体化信息的实时处理
-
-
挑战:
-
业务系统与财务系统明显割裂,业务部门与财务部门各自采用一套软件处理其数据,不能及时沟通信息和协同更正信息。
-
财务系统往往都是单体的传统架构,凭证处理能力无法适应今天企业的不断爆棚的业务发展。
-
财务的严谨性与业务的灵活性中间有巨大的鸿沟,导致业务要做一种创新的模式,财务可能是最大阻碍。
-
不论是传统软件公司喜欢说的业财一体化还是互联网平台公司喜欢说的结算平台,都是为了解决以上变化和挑战的。业财一体化主要是从财务部门角度出发进行,在业务支撑上化被动为主动。结算中心往往是结合财务部门和业务运营部门的需求。如果拿我们下面介绍的,计费、账务、会计三个领域来说,业财一体化项目往往只包括账务和会计,结算中心往往包括:计费、账务、会计。或者说业财一体化弱化了计费,没有纳入企业统一管理,把如何计价给到了业务系统自行决定或者简单处理只要产生应收应付单据(计费详单)就好了。
结算域的是一个相对比较专业的领域,没有一定背景知识甚至连一些专业名词都很难理解,更不用说模型设计了,这里我尽快地简单去描述定位而不是描述细节。而且2.1.9版本的结算领域相对还是没有那么完善,这里介绍的是下个版本的内容,所以大家看当前版本的时候会有一些对不上。
二、子领域职责


计费
计费的价值
随着企业多业务发展以及融合计费需求,我们需要引入计费模型,对灵活计价模式进行支持,快速支撑未来可能的计费方式等
计费的核心设计理念
所有的计算器都继承自虚函数计算器y=f(x)
| 平滑兼容-默认斜率计算器y=a+bxY – 求值结果(用下标描述结果是什么)A – 偏移量(计算固定值)B – 斜率(费率值)X – 变量(数量)任何计算都是通过一组斜率组合出来的 | 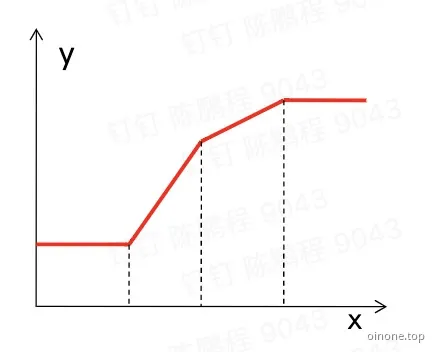 |
|---|---|
| 利用区间限定定义各种斜率组合出各种算法交易额0-100w:y=0.03x >100w:y=0.02x;时间0:00-6:00:y=0.02x 6:00-24:00:y=0.03xX- 变量,数量 | 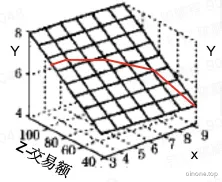 |
更灵活多维区间组合,时间维度、计数器维度、其它属性维度计数器区间斜率限定,比如交易额、空间、使用月份数…
计费的核心功能
-
通过产品定义运营方案
-
通过订购产品完成商务合同的签订来决定客户计费策略,或者通过系统产品定义通用计费策略
-
支撑各类产品的模拟计费
-
以事件驱动,根据事件、产品、订购关系完成产品路由,并实时产生计费详单
-
根据计费科目与账务科目,打通账务进行核销
账务
账务的价值
以账户账本为中心,提供记账、账户管理,以及账务的实时监控与持续对账。如果计费是对接业务,那么账务的价值是对接财务系统
账务的核心设计理念
不依赖计费,可独立对接,所有业务最终都需要反馈到帐户账本的操作上,并通过账本明细记录所有操作
账务的核心功能
-
记账:充值、转账、提现,冻结、解冻,差错处理
-
账务管理:开户、科目维护
-
账务查询:对账
会计(暂不在计划内)
会计的价值
结算平台的会计模块不是严格意义上的会计系统,它主要是衔接其他的财务系统,做凭证前置处理。在于汇总凭证,产出业务帐,对接到财务总帐系统,缓解财务系统压力。
三、模型介绍
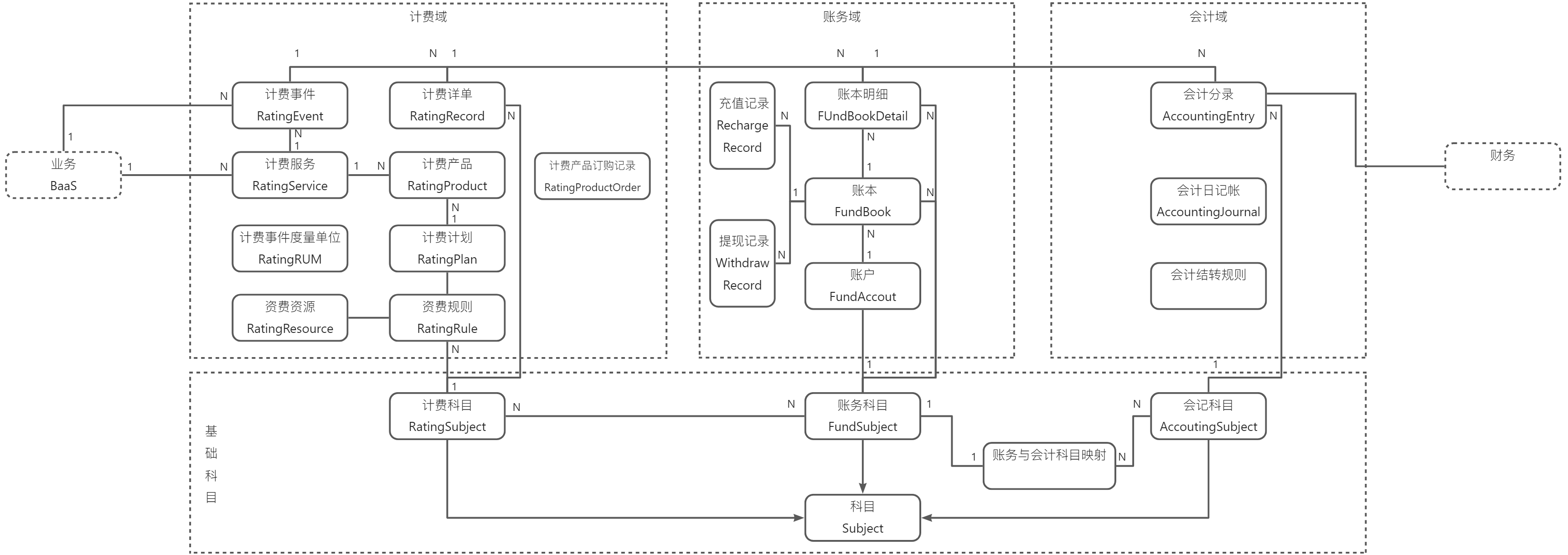
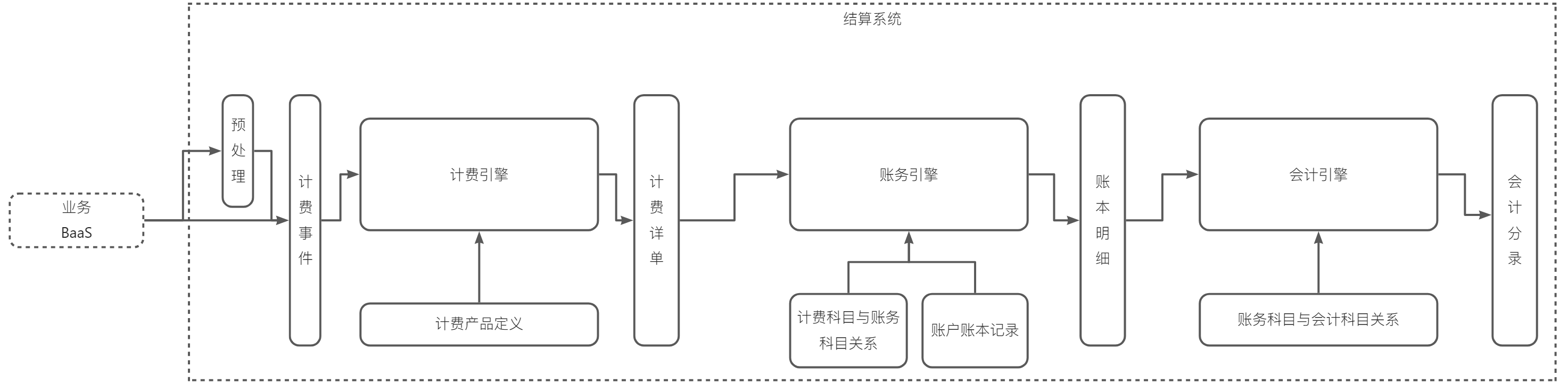
四、结算基础流程
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9320.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验