
介绍Model相关元数据,以及对应代码注解方式。大家还是可以通读并练习每种不同的使用方式,这个是oinone的设计精华所在。当您不知道如何配置模型、字段、模型间的关系、以及枚举都可以到这里找到。
一、模型元数据
安装与更新
使用@Model.model来配置模型的不可变更编码。模型一旦安装,无法在对该模型编码值进行修改,之后的模型配置更新会依据该编码进行查找并更新;如果仍然修改该注解的配置值,则系统会将该模型识别为新模型,存储模型会创建新的数据库表,而原表将会rename为废弃表。
如果模型配置了@Base注解,表明在studio中该模型配置不可变更;如果字段配置了@Base注解,表明在studio中该字段配置不可变更。
注解配置
模型类必需使用@Model注解来标识当前类为模型类。
可以使用@Model.model、@Fun注解模型的模型编码(也表示命名空间),先取@Model.model注解值,若为空则取@Fun注解值,若皆为空则取全限定类名。
模型元信息
模型的priority,当展示模型定义列表时,使用priority配置来对模型进行排序。
模型的ordering,使用ordering属性来配置该模型的数据列表的默认排序。
模型元信息继承形式:
- 不继承(N)
- 同编码以子模型为准(C)
- 同编码以父模型为准(P)
- 父子需保持一致,子模型可缺省(P=C)
注意:模型上配置的索引和唯一索引不会继承,所以需要在子模型重新定义。数据表的表名、表备注和表编码最终以父模型配置为准;扩展继承父子模型字段编码一致时,数据表字段定义以父模型配置为准。
| 名称 | 描述 | 抽象继承 | 同表继承 | 代理继承 | 多表继承 |
|---|---|---|---|---|---|
| 基本信息 | |||||
| displayName | 显示名称 | N | N | N | N |
| summary | 描述摘要 | N | N | N | N |
| label | 数据标题 | N | N | N | N |
| check | 模型校验方法 | N | N | N | N |
| rule | 模型校验表达式 | N | N | N | N |
| 模型编码 | |||||
| model | 模型编码 | N | N | N | N |
| 高级特性 | |||||
| name | 技术名称 | N | N | N | N |
| table | 逻辑数据表名 | N | P=C | P=C | N |
| type | 模型类型 | N | N | N | N |
| chain | 是否是链式模型 | N | N | N | N |
| index | 索引 | N | N | N | N |
| unique | 唯一索引 | N | N | N | N |
| managed | 需要数据管理器 | N | N | N | N |
| priority | 优先级,默认100 | N | N | N | N |
| ordering | 模型查询数据排序 | N | N | N | N |
| relationship | 是否是多对多关系模型 | N | N | N | N |
| inherited | 多重继承 | N | N | N | N |
| unInheritedFields | 不从父类继承的字段 | N | N | N | N |
| unInheritedFunctions | 不从父类继承的函数 | N | N | N | N |
| 高级特性-数据源 | |||||
| dsKey | 数据源 | N | P=C | P=C | N |
| 高级特性-持久化 | |||||
| logicDelete | 是否逻辑删除 | P | P | P | N |
| logicDeleteColumn | 逻辑删除字段 | P | P | P | N |
| logicDeleteValue | 逻辑删除状态值 | P | P | P | N |
| logicNotDeleteValue | 非逻辑删除状态值 | P | P | P | N |
| underCamel | 字段是否驼峰下划线映射 | P | P | P | N |
| capitalMode | 字段是否大小写映射 | P | P | P | N |
| 高级特性-序列生成配置 | |||||
| sequence | 配置编码 | C | C | C | N |
| prefix | 前缀 | C | C | C | N |
| suffix | 后缀 | C | C | C | N |
| separator | 分隔符 | C | C | C | N |
| size | 序列长度 | C | C | C | N |
| step | 序列步长 | C | C | C | N |
| initial | 初始值 | C | C | C | N |
| format | 序列格式化 | C | C | C | N |
| 高级特性-关联关系(或逻辑外键) | |||||
| unique | 外键值是否唯一 | C | C | C | N |
| foreignKey | 外键名称 | C | C | C | N |
| relationFields | 关系字段列表 | C | C | C | N |
| references | 关联模型 | C | C | C | N |
| referenceFields | 关联字段列表 | C | C | C | N |
| limit | 关系数量限制 | C | C | C | N |
| pageSize | 查询每页个数 | C | C | C | N |
| domainSize | 模型筛选可选项每页个数 | C | C | C | N |
| domain | 模型筛选,前端可选项 | C | C | C | N |
| onUpdate | 更新关联操作 | C | C | C | N |
| onDelete | 删除关联操作 | C | C | C | N |
| 静态配置 | |||||
| Static | 静态元数据模型 | N | N | N | N |
字段定义继承形式
| 名称 | 描述 | 抽象继承 | 同表继承 | 代理继承 | 多表继承 |
|---|---|---|---|---|---|
| 字段定义 | 字段定义 | C | C | C | C |
模型约束
主键约束
每个模型都可以配置自身的主键列表,也可以不配置主键。主键值不可缺省,可以索引到模型所对应数据表中唯一的一条记录。
外键约束
模型与模型之间的关联关系可以配置外键约束来约束关联关系之间数据的变更行为。
校验约束
模型可以配置校验函数对该模型的数据进行校验,存储数据时,校验数据是否合法合规。
二、字段元数据
模型字段描述的是实体的特征属性。模型与字段之间的关联关系由Model的model与Field的model进行关联。ModelField继承关系抽象类Relation。
使用@Field注解来描述模型的字段。如果未配置字段类型,系统会根据Java代码的字段声明类型来自动获取业务类型。建议配置displayName属性来描述字段在前端的显示名称。可以使用defaultValue配置字段的默认值。
元数据注解说明
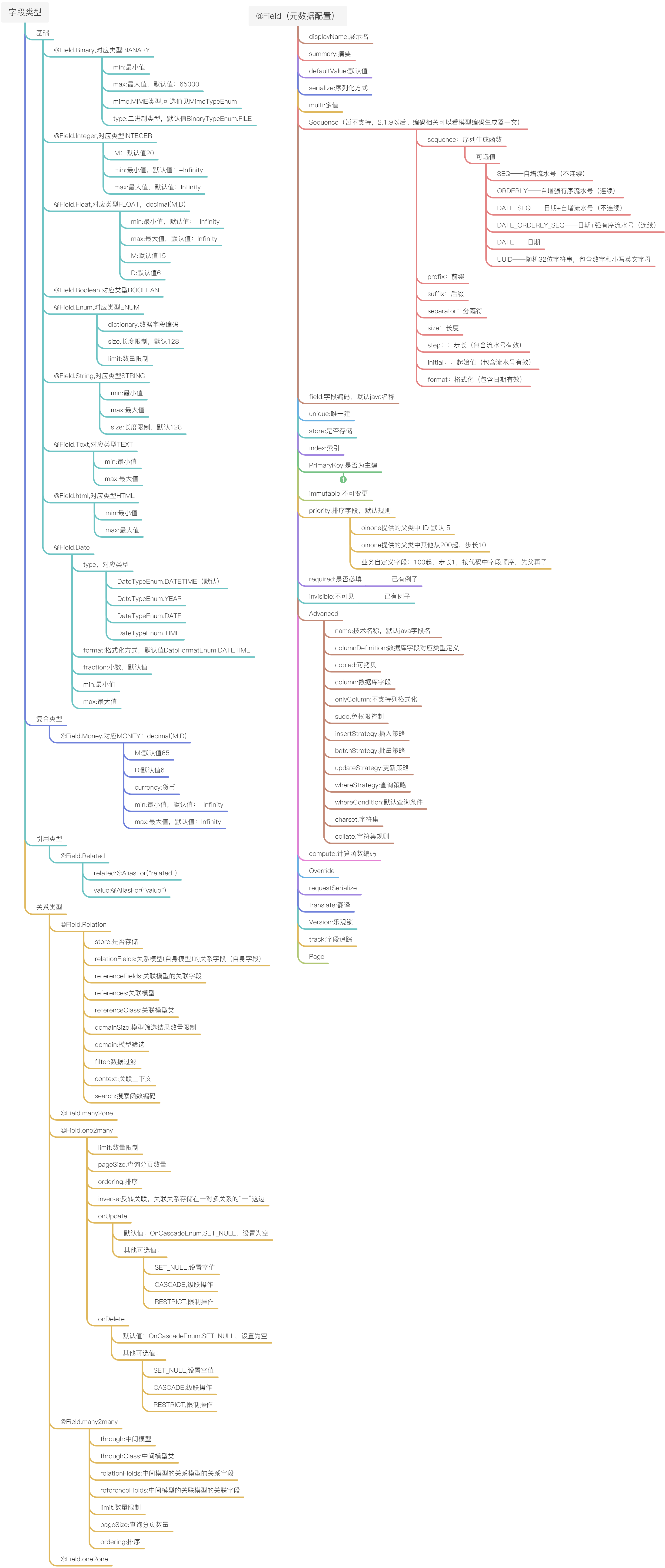

安装与更新
使用@Field.field来配置字段的不可变更编码。字段一旦安装,无法在对该字段编码值进行修改,之后的字段配置更新会依据该编码进行查找并更新;如果仍然修改该注解的配置值,则系统会将该字段识别为新字段,存储模型会创建新的数据库表字段,而原字段将会rename为废弃字段。
基础配置
不可变更字段
使用immutable属性来描述该字段前后端都无法进行更新操作,系统会忽略不可变更字段的更新操作。
自动生成编码的字段
可以使用@Field.Sequence注解在字段上配置编码生成规则,为编码为空的字段自动生成编码。
详见3.3.5【模型编码生成器】
字段的序列化与反序列化
使用@Field注解的serialize属性来配置非字符串类型属性的序列化与反序列化方式,最终会以序列化后的字符串持久化到存储中。
详见3.3.7【字段之序列化方式】
前端默认配置
可以使用@Field注解中的以下属性来配置前端的默认视觉与交互规则,也可以在前端设置覆盖以下配置。
- required,是否必填
- invisible,是否不可见
- priority,字段优先级,列表的列使用该属性进行排序
字段类型
类型系统由基本类型、复合(组件)类型、引用类型和关系类型四种类型系统构成。通过类型系统来决定应用程序、数据库和前端视觉视图是如何进行交互,数据及数据间关系如何处理的。
基本类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 | |||
|---|---|---|---|---|---|---|
| BINARY | Byte Byte[] | TINYINT BLOB | 二进制类型,不推荐使用 | |||
| INTEGER | INTEGER Short Integer Long BigInteger |
smallint int bigint decimal(size,0) |
整数, 包括整数(10-11位有效数字)、长整数(19-20位有效数字)和大整数(超过19位)。 【数据库规则】:默认使用int;如果size小于6则使用smallint;如果size超过6则使用int;如果size超过10位数字,即大于11(包含符号位),则使用长整数bigint;如果size超过19位数字,即大于20(包含符号位),则使用大数decimal。若未配置size,则按Java类型推测。 【前端交互规则】:整数使用Number类型,长整数和大整数前后端协议使用字符串类型。 |
二进制类型,不推荐使用 | ||
| FLOAT | Float Double BigDecimal |
float(M,D) double(M,D) decimal(M,D) |
浮点数, 包括单精度浮点数(7-8位有效数字)、双精度浮点数(15-16位有效数字)和大数(超过15位)。 【数据库规则】:默认使用单精度浮点数float; 如果size超过7位数字,即大于等于8,则使用双精度浮点数double;如果size超过15位数字,即大于等于16,则使用大数decimal。若未配置size,则按Java类型推测。 【前端交互规则】:单精度浮点数float和双精度浮点数double使用Number类型(因为都使用IEEE754协议64位进行存储),大数前后端协议使用字符串类型。 |
|||
| BOOLEAN | Boolean | tinyint(1) | 布尔类型,值为1,true(真)或0,false(假) | |||
| ENUM | Enum | varchar(size) | 【前端交互规则】:可选项从ModelField的options字段获取,options字段值为字段指定数据字典子集的JSON序列化字符串。前后端传递的是可选项的name,数据库存储使用可选项的value。multi属性为true,则使用多选控件;multi属性为false,则使用单元控件 | |||
| STRING | String | varchar(size) | 字符串,size为长度限制默认值参考,前端可以view中覆盖该配置 | |||
| TEXT | String | text | 多行文本,编辑态组件为多行文本框,长度限制为配置项size值 | |||
| HTML | String | text | 富文本编辑器 | |||
| DATETIME | java.util.Date java.sql.Timestamp |
datetime(fraction) timestamp(fraction) |
日期时间类型 【数据库规则】:日期和时间的组合, 时间格式为 YYYY-MM-DD HH:MM:SS[.fraction],默认精确到秒,在默认的秒精确度上,可以带小数,最多带6位小数,即可以精确到 microseconds (6 digits) precision。可以通过设置fraction来设置精确小数位数,最终存储在字段的decimal属性上。 【前端交互规则】:前端默认使用日期时间控件,根据日期时间类型格式化格式format格式化日期时间 |
|||
| YEAR | java.util.Date | year | 日期时间类型 年份类型 日期类型 【数据库规则】:默认“YYYY”格式表示的日期值 【前端交互规则】:前端默认使用年份控件,根据日期类型格式化格式format格式化日期 |
|||
| DATE | java.util.Date java.sql.Date |
date date |
date date 日期类型 【数据库规则】:默认“YYYY-MM-DD”格式表示的日期值 【前端交互规则】:前端默认使用日期控件,根据日期类型格式化格式format格式化日期 |
|||
| TIME | java.util.Date java.sql.Time |
time(fraction) time(fraction) |
time(fraction) time(fraction) 时间类型 【数据库规则】:默认“HH:MM:SS”格式表示的时间值 【前端交互规则】:前端默认使用时间控件,根据日期类型格式化格式format格式化日期 |
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| BINARY | ByteByte[] | TINYINTBLOB | 二进制类型,不推荐使用 |
| INTEGER | ShortIntegerLongBigInteger | smallintintbigintdecimal(size,0) | 整数, 包括整数(10-11位有效数字)、长整数(19-20位有效数字)和大整数(超过19位)。【数据库规则】:默认使用int;如果size小于6则使用smallint;如果size超过6则使用int;如果size超过10位数字,即大于11(包含符号位),则使用长整数bigint;如果size超过19位数字,即大于20(包含符号位),则使用大数decimal。若未配置size,则按Java类型推测。【前端交互规则】:整数使用Number类型,长整数和大整数前后端协议使用字符串类型。 |
| FLOAT | FloatDoubleBigDecimal | float(M,D)double(M,D)decimal(M,D) | 浮点数,?包括单精度浮点数(7-8位有效数字)、双精度浮点数(15-16位有效数字)和大数(超过15位)。【数据库规则】:默认使用单精度浮点数float;如果size超过7位数字,即大于等于8,则使用双精度浮点数double;如果size超过15位数字,即大于等于16,则使用大数decimal。若未配置size,则按Java类型推测。【前端交互规则】:单精度浮点数float和双精度浮点数double使用Number类型(因为都使用IEEE754协议64位进行存储),大数前后端协议使用字符串类型。 |
| BOOLEAN | Boolean | tinyint(1) | 布尔类型,值为1,true(真)或0,false(假) |
| ENUM | Enum | 与数据字典指定基本类型一致 | 【前端交互规则】:可选项从ModelField的options字段获取,options字段值为字段指定数据字典子集的JSON序列化字符串。前后端传递的是可选项的name,数据库存储使用可选项的value。multi属性为true,则使用多选控件;multi属性为false,则使用单元控件 |
| STRING | String | varchar(size) | 字符串,size为长度限制默认值参考,前端可以view中覆盖该配置 |
| TEXT | String | text | 多行文本,编辑态组件为多行文本框,长度限制为配置项size值 |
| HTML | String | text | 富文本编辑器 |
| DATETIME | java.util.Datejava.sql.Timestamp | datetime(fraction)timestamp(fraction) | 日期时间类型【数据库规则】:日期和时间的组合,时间格式为?YYYY-MM-DD HH:MM:SS[.fraction],默认精确到秒,在默认的秒精确度上,可以带小数,最多带6位小数,即可以精确到?microseconds (6 digits) precision。可以通过设置fraction来设置精确小数位数,最终存储在字段的decimal属性上。【前端交互规则】:前端默认使用日期时间控件,根据日期时间类型格式化格式format格式化日期时间 |
| YEAR | java.util.Date | year | 年份类型日期类型【数据库规则】:默认“YYYY”格式表示的日期值【前端交互规则】:前端默认使用年份控件,根据日期类型格式化格式format格式化日期 |
| DATE | java.util.Datejava.sql.Date | datedate | 日期类型【数据库规则】:默认“YYYY-MM-DD”格式表示的日期值【前端交互规则】:前端默认使用日期控件,根据日期类型格式化格式format格式化日期 |
| TIME | java.util.Datejava.sql.Time | time(fraction)time(fraction) | 时间类型【数据库规则】:默认“HH:MM:SS”格式表示的时间值【前端交互规则】:前端默认使用时间控件,根据日期类型格式化格式format格式化日期 |
表4-1-6-3 基本类型
复合类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| MONEY | BigDecimal | decimal(M,D) | 金额,前端使用金额控件,可以使用currency设置币种字段 |
#### 引用类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| RELATED | 基本类型或关系类型 | 不存储或varchar、text | 引用字段【数据库规则】:点表达式最后一级对应的字段类型;数据库字段值默认为Java字段的序列化值,默认使用JSON序列化【前端交互规则】:点表达式最后一级对应的字段控件类型 |
#### 关系类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| O2O | 模型/DataMap | 不存储或varchar、text | 一对一关系 |
| M2O | 模型/DataMap | 不存储或varchar、text | 多对一关系 |
| O2M | List<模型/DataMap> | 不存储或varchar、text | 一对多关系 |
| M2M | List<模型/DataMap> | 不存储或varchar、text | 多对多关系 |
多值字段或者关系字段需要存储,默认使用JSON格式序列化。多值字段数据库字段类型默认为varchar(1024);关系字段数据库字段类型默认为text。
#### 类型默认推断
M代表精度,即有效长度(总位数), D代表标度,即小数点后的位数,fraction为时间秒以下精度。multi表示该字段为多值字段。
| Java类型 | Field注解 | 推断ttype | 推断配置 | 推断数据库配置 |
|---|---|---|---|---|
| Byte | @Field | BINARY | 无 | blob |
| String | @Field | STRING | size=128 | varchar(128) |
| List |
@Field | STRING | size=1024,multi=true | varchar(1024) |
| Map | @Field | STRING | size=1024 | varchar(1024) |
| Short | @Field | INTEGER | M=5 | smallint(6) |
| Integer | @Field | INTEGER | M=10 | integer(11) |
| Long | @Field | INTEGER | M=19 | bigint(20) |
| BigInteger | @Field | INTEGER | M=64 | decimal(64,0) |
| Float | @Field | FLOAT | M=7,D=2 | float(7,2) |
| Double | @Field | FLOAT | M=15,D=4 | double(15, 4) |
| BigDecimal | @Field | FLOAT | M=64,D=6 | decimal(64,6) |
| Boolean | @Field | BOOLEAN | 无 | tinyint(1) |
| java.util.Date | @Field | DATETIME | fraction=0 | datetime |
| java.util.Date | @Field.Date(type=DateTypeEnum.YEAR) | YEAR | 无 | year |
| java.util.Date | @Field.Date(type=DateTypeEnum.DATE) | DATE | 无 | date |
| java.util.Date | @Field.Date(type=DateTypeEnum.TIME) | TIME | fraction=0 | time |
| java.sql.Timestamp | @Field | DATETIME | fraction=0 | timestamp |
| java.sql.Date | @Field | DATE | 无 | date |
| java.sql.Time | @Field | TIME | fraction=0 | time |
| Long | @Field.Date | DATETIME | fraction=0 | datetime |
| enum implementsIEnum | @Field | ENUM | 无 | 根据枚举value类型 |
| primitive type | @Field.Enum(dictionary=数据字典编码) | ENUM | 无 | 根据枚举value类型 |
| List |
@Field.Enum(dictionary=数据字典编码) | ENUM | multi=true | varchar(512) |
| 模型类 | @Field.Relation | M2O | 无 | text |
| DataMap | @Field.Relation | M2O | 无 | text |
| List<模型类> | @Field.Relation | O2M | multi=true | text |
| List |
@Field.Relation | O2M | multi=true | text |
### 字段约束
#### 主键
可以使用Yaml或者@Model.Advanced的keyGenerator属性来配置模型主键的自动生成规则,AUTO_INCREMENT或者分布式ID。如果不配置,将不会自动生成主键值。
#### 逻辑外键约束
在创建关联关系字段的时候,可以使用@Field.Relation注解的onUpdate和onDelete属性指定在删除模型或更新模型关系字段值时,对关联模型进行的相应操作。操作包括RESTRICT、NO ACTION、SET NULL和CASCADE,默认值为RESTRICT。
- RESTRICT是指模型与关联模型有关联记录的情况下,引擎会阻止模型关系字段的更新或删除模型记录;
- NO ACTION是指不作约束(这里与数据库约束的定义不相同);
- CASCADE表示在更新模型关系字段或者删除模型时,级联更新关联模型对应记录的关联字段值或者级联删除关联模型对应记录;
- SET NULL则是表示在更新模型关系字段或者删除模型的时候,关联模型的对应关联字段将被SET NULL(该字段值允许为null的情况下,若不允许为null,则引擎阻止对模型的操作)。
#### 通用校验约束
| 字段业务类型 | size | limit | decimal | mime | min | max |
|---|---|---|---|---|---|---|
| BINARY | 文件类型 | 最小比特位 | 最大比特位 | |||
| INTEGER | 有效数字 | 最小值 | 最大值 | |||
| FLOAT | 有效数字 | 小数位数 | 最小值 | 最大值 | ||
| BOOLEAN | ||||||
| ENUM | 存储字符数 | 多选最多数量 | ||||
| STRING | 存储字符数 | 字符数 | 字符数 | |||
| TEXT | 字符数 | 字符数 | ||||
| HTML | 字符数 | 字符数 | ||||
| MONEY | 有效数字 | 小数位数 | 最小值 | 最大值 | ||
| RELATED |
| 字段业务类型 | fraction | format | min | max |
|---|---|---|---|---|
| DATETIME | 时间精度 | 时间格式 | 最早日期时间 | 最晚日期时间 |
| YEAR | 时间格式 | 最早年份 | 最晚年份 | |
| DATE | 时间格式 | 最早日期 | 最晚日期 | |
| TIME | 时间精度 | 时间格式 | 最早时间 | 最晚时间 |
| 字段业务类型 | size | domainSize | limit | pageSize |
|---|---|---|---|---|
| RELATED | 存储字符数(若序列化存储) | |||
| O2O | 存储字符数(若序列化存储) | 可选项每页个数 | ||
| M2O | 存储字符数(若序列化存储) | 可选项每页个数 | ||
| O2M | 存储字符数(若序列化存储) | 可选项每页个数 | 关系数量限制 | 查询每页个数 |
| M2M | 存储字符数(若序列化存储) | 可选项每页个数 | 关系数量限制 | 查询每页个数 |
在模型或字段上配置check函数,则处理前端请求时会进行校验约束。也可以调用模型上的check函数进行编程式校验。
#### 默认值约束
字段默认值defaultValue可以是基本类型或者关系类型的序列化值。时间类型可以使用format来格式化时间表达式或者使用长整数来设置默认值。枚举类型使用枚举项值value来设置默认值。如果需要进行复杂的计算请使用模型的construct构造函数来配置解决。
#### 唯一约束
将字段或者模型上配置unique唯一索引,可以为模型或字段添加唯一约束。
#### 可选项约束
使用枚举定义字段的可选项值,可以为字段提供可选项约束功能。
### 关系字段
关联关系用于描述模型间的关联方式:
- 多对一关系,主要用于明确从属关系
- 一对多关系,主要用于明确从属关系
- 多对多关系,主要用于弱依赖关系的处理,提供中间模型进行关联关系的操作
- 一对一关系,主要用于多表继承和行内合并数据

#### 名词解释
关联关系比较重要的名词解释如下:
- 关联关系:使用relation表示,模型间的关联方式的一种描述,包括关联关系类型、关联关系双边的模型和关联关系的读写
- 关联关系字段:业务类型ttype为O2O、O2M、M2O或M2M的字段
- 关联模型:使用references表示,自身模型关联的模型
- 关联字段:使用referenceFields表示,关联模型的字段,表示关联模型的哪些字段与自身模型的哪些字段建立关系
- 关系模型:自身模型
- 关系字段:使用relationFields表示,自身模型的字段,表示自身模型的哪些字段与关联模型的哪些字段建立关系
- 中间模型,使用through表示,只有多对多存在中间模型,模型的relationship=true
#### 关联关系的默认视图
- 一对多默认视图,编辑态在行内是下拉多选,在详情是选项卡表格;展示态在行内是折叠面板表格,在详情是选项卡表格
- 多对一默认视图,编辑态在行内是下拉单选,在详情是下拉单选;展示态在行内是文字,在详情是文字
- 多对多默认视图,编辑态在行内是下拉多选,在详情是选项卡表格;展示态在行内是折叠面板表格,在详情是选项卡表格
- 一对一默认视图,编辑态在行内是平铺,在详情是分组;展示态在行内是平铺,在详情是分组
在后端研发的使用上所有关联关系和引用的处理都限制在本模型,即平台至多处理到当前模型的字段,不再继续依据关联关系和引用处理关联模型。但是可以手动调用模型上的链式方法fieldQuery、fieldCreate和fieldUpdate来完成关联关系的查询与更新操作。
使用O2M或者M2M关联关系关联的临时模型没有分页查询操作。
#### 关联关系的配置
可以使用@Field.Relation注解的relationFields、referenceFields、references和through来配置关联关系。
relationFields与referenceFields为存储关联关系的一一映射字段列表。
如果relationFields缺省,一对多或者多对多关系的relationFields默认为模型主键;一对一或者多对一关系的relationFields默认为关联关系字段名加上首字母大写的主键名拼接而成的字符串。如果有多个主键,则relationFields和referenceFields也对应有多个字段。
如果配置了relationFields,但referenceFields缺省,则referenceFields与relationFields字段名一致。
一对多关系的referenceFields必填。如果referenceFields缺省,多对多,多对一或者一对一关系的referenceFields默认为主键。
| 关系类型 | 缺省关系字段默认值 | 缺省关联字段默认值 |
|---|---|---|
| 一对多 | 默认为关系模型的pk | 默认为关系模型名+关系模型的pk;如果关系另一端的多对一字段名不是关系模型名,则需明确指定,使两端关系字段与关联字段对应 |
| 一对一 | 默认为关联关系字段名+关系模型的pk | 默认为关联模型的pk |
| 多对一 | 默认为关联关系字段名+关系模型的pk | 默认为关联模型的pk |
| 多对多 | 默认为关系模型的pk | 默认为关联模型的pk |
多对多使用through来指定中间模型的模型编码,如果指定模型编码的中间模型不存在,系统会根据through自动生成中间模型,中间模型的默认字段为与两端模型关联的关系字段。与关系模型关联的关系字段名称为关系模型名称加上关系模型的主键拼接而成的字符串;与关联模型关联的多对一字段名称为关联模型名称加上关联模型主键拼接而成的字段串。如果与关系模型关联的关系字段名称和与关联模型关联的多对一字段名称冲突,需要使用throughRelationFields和throughReferenceFields明确配置指定字段名称解决冲突。
系统根据模块的依赖关系,自动生成的中间模型将生成在先加载的建立多对多关系的关系模型所在模块。
#### 读写关联关系字段
默认关联关系字段的store属性为false,relationStore为true。若设置关联关系字段relationStore属性为true,则会为关联关系字段生成关系字段用于存储关联关系。若设置关联关系字段store属性为true,则存储时序列化字段值存储到数据库中,查询时从数据库中反序列化得到字段值。字段类型为varchar且长度为128,如果需要改变字段长度,可以使用@Field.Advanced的columnDefinition设置。当store属性为false时,则字段值为关联关系查询得到的结果。如果store为false且relationStore为false,则只能对字段进行赋值来设置字段值。
#### 关联操作
调用数据管理器的API不会触发关联操作,需要调用fieldQuery和fieldSave方法进行关联模型的关联操作。
前端的查询接口会根据GraphQL协议进行关联查询。
前端的新增和更新接口默认会存储当前模型的关联关系字段和递归新增和更新一对多关系的关联关系字段。更新接口会检查当前模型的逻辑外键约束。可以调用模型的ignore方法或设置模型数据的ignore属性来改变递归深度,避免循环操作。
前端的删除接口会默认删除当前模型数据和根据级联配置进行当前模型的关联关系字段的关联操作。删除接口会检查当前模型的逻辑外键约束。可以调用模型的ignore方法或设置模型数据的ignore属性来改变递归深度,避免循环操作。
#### 关联数据分页
可以使用关系字段配置中分页数量pageSize来限定关联查询的返回结果数量。可选项可以使用domainSize来限定可选项返回结果数量,由前端从字段元数据中获取并设置为可选项查询分页数量限制。
#### 反转关系
一对多关联关系可以设置inverse为true反转关系,反转关系后关联关系存储在一对多关系中“一”这一端。
#### 引用字段
引用字段可以通过与其他字段建立引用关系来获取数据。
当引用字段的store属性为true时,则字段值为存储的字段值,数据存储时将被引用字段值存储到数据存储中(unset掉被引用字段,则直接存储引用字段值);当store属性为false时,则数据为被引用字段的字段值且不会存储。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9281.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验
相关推荐
-
庄卓然
从2009年加入阿里至今,经历了“三淘”时期、天猫时期、双十一,到最后的all in无线手淘时期,几乎是赶上了淘系发展的所有历史性事件。在这个过程中,每一次业务的变革都催生着技术的变迁,倒逼着我们用技术的方式去解决业务问题:在存储、IO、网络等环节满足不了淘系的业务规模时,开始去IOE,最后演化成了阿里云;当业务的规模大到不能通过简单加机器的方式去做调整、当开发的规模大到所有人在一起开发会互相影响的的时候,我们开始做SOA改造,最后演化成了业务中台;在经历了几届双十一后的巨大挑战后,我们开创了里程碑式的全链路压测;在手淘时代,为了解决动态发版问题,我们植入容器概念,搭建了可动态插拔的三层架构,一年实现了500多次的发版;为了同时满足写一套代码就解决多端开发和高并发的性能问题,我们做了weex,最后还捐给了开源社区…… 每一次的业务需求推动技术进步,而技术的进步永远会超出我们的想象! 同为技术宅,我在Oinone身上能清晰地感受到技术演进的脉络,企业在数字化时代,需要一个能快速上手、全面设计、灵活适应且低成本的技术工具,时代的变迁推动了Oinone的诞生。Oinone是一种全新的开发方式,在数字化时代,Oinone在提升研发效率上做出的创新性“低无一体”的设计对传统软件代码开发或者无代码开发一定会有巨大冲击,这种冲击会对软件市场格局造成什么样的变化,我拭目以待。 最后,愿我们这些追光人,在时代的洪流中,都能留下一抹印迹,不辜负时代,不辜负自己。 现任阿里巴巴副总裁,飞猪总裁,曾任阿里大文娱CTO兼优酷COO、淘宝CTO 庄卓然(南天)
-
报表
1. 业务场景 报表不局限于表格的样式,还能以各式各样的图表形式展现各项汇总数据 这有利于管理者更为直观地了解公司的经营情况,便于后续进行分析,提高对公司的管理水平。 2. 操作流程 1)进入数据可视化,进入报表tab,维护分组信息; 2)在二级分组名称后点击“+”【添加报表】,对报表进行编辑设计; 3)创建完成后可以【编辑】报表标题、备注; 4)需要通过【选择图表、创建图表】完善报表内容; 5)完善后可以点击【发布】报表,则报表此时可以被引用; 6)如果报表有更新,则可以点击【更新发布】,使业务系统引用对报表变为最新的报表信息; 7)如果报表数据不再可以公开使用,则需要通过【隐藏】功能将报表的引用权限收起,此时数据大屏、前端业务系统均不可再引用该报表,但不影响已被引用的报表; 8)隐藏后可以【取消隐藏】,报表恢复隐藏前的状态和功能,可以被引用。 3. 操作流程图解 3.1 创建分组 1)操作流程:创建分组 2)操作路径:数据可视化-报表-创建分组 3)点击搜索框后的「+」创建一级分组,输入一级分组名称后,点击一级分组后的「+」创建二级分组,输入二级分组名称后,此时分组创建完成,可以在二级分组下创建报表 3.2 编辑分组名称 1)操作流程:选择分组-编辑分组名称 2)操作路径:数据可视化-报表-编辑分组名称 3)鼠标移动至需要修改的分组上,点击出现的「编辑图标」,可以修改分组名称,修改后分组名称实时更新 3.3 删除分组 1)操作流程:选择分组-删除分组 2)操作路径:数据可视化-报表-删除分组 3)鼠标移动至需要删除的分组上,当分组下无报表时出现「删除图标」,可以点击图标后删除分组,删除一级分组时对应所有的二级分组也会被删除,删除后消失,只要分组下没有报表的分组才能直接删除成功 3.4 创建报表 1)操作流程:选择二级分组-创建报表 2)操作路径:数据可视化-报表-二级分组-创建报表 3)鼠标移动至需要创建报表的二级分组上,出现「+」,点击图标后=需要填写报表标题; a. 报表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复; 4)创建后可以选择报表需要展示的图表 3.5 删除报表 1)操作流程:选择报表-删除报表 2)操作路径:数据可视化-报表-二级分组-报表名称-删除图表 3)未发布或者已发布但没有被隐藏的报表,并且没被前端或者数据大屏引用,才展示报表菜单名称后的删除图标 4)删除报表后报表消失 3.6 选择图表 1)操作流程:选择报表-为报表选择图表 2)操作路径:数据可视化-报表-二级分组-报表名称-选择图表 3)选择单个未发布或者已发布但没有被隐藏的报表,点击【选择图表】,弹出“选择图表”弹窗,对该报表需要展示的图表进行选择 a. 需要选择图表的一级分组后才能选择图表; b. 可以多选图表,选择的图表只能是已选一级分组下的未隐藏的未被选择的图表;选择一个二级分组时,默认该二级分组下的图表会全部被选中,图表会按照选中的顺序展示在报表列表; 4)选择图表后,报表信息保持展示图表的最新效果;如果图表更新了,但是报表没有发布最新,则报表在前端展示的仍为最近发布的版本; 5)如果图表中存在超过一行的图内筛选项,则在报表处原始的图表尺寸只能查看一行图内筛选项,需要根据图表在报表处的等比拖动效果展示更多的图内筛选项 3.7 创建图表 1)操作流程:选择报表-创建图表 2)操作路径:数据可视化-报表-二级分组-创建图表 3)选择单个未发布或者已发布但没有被隐藏的报表,点击【创建图表】,弹出“创建图表”弹窗,需要填写图表标题、模型、方法; a. 图表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复; b. 模型:需要选择来源数据对应的模型; c. 方法:选择模型后需要选择方法,方法是用来提取模型数据的逻辑; 4)选择成功后进入图表设计页面,创建图表保存后返回,返回到当前报表页面,新创建的图表展示在报表的第一个位置 3.8 拖拽图表 1)操作流程:选择报表-拖拽图表 2) 操作路径:数据可视化-报表-二级分组-报表名称-拖拽图表 3)所有的报表均可拖拽图表,拖拽时需要选择图表,可以上下左右等比拖动,图表的内容也会根据拖动的比例进行缩放,展示全部的被遮挡图表内容 4)拖拽后实时生效,报表信息保持展示最新效果 3.9 移除图表 1)操作流程:选择报表-移除图表 2)操作路径:数据可视化-报表-二级分组-报表名称-移除图表 3)未发布或者已发布但没有被隐藏的报表,并且没被前端或者数据大屏引用,此时可以针对不需要的图表进行移除 4)选择移除后不展示在报表中,不影响原图表 5)报表移除图表后实时更新,更新发布后,前端可以展示最新的报表信息,如果未发布,则仅数据大屏可展示最新的报表信息,前端仍为最近发布的报表 3.10 设置报表筛选项 1)操作流程:选择报表-设置报表筛选项 2)操作路径:数据可视化-报表-二级分组-报表名称-更多-报表筛选项-添加 3)添加时选择筛选项字段的类型,关联每个图表对应的字段,一个图表只能关联一个 4)关联后可以按关联字段查询图表数据 3.11 发布 1)操作流程:选择报表-发布报表 2)操作路径:数据可视化-图表-二级分组-报表-发布 3)选择单个未发布且没有被隐藏的报表,点击【发布】按钮,报表发布后可以被前端引用,报表状态变为已发布,展示最近发布时间; 4)如果报表发布后有更新内容,会展示的更新类型:更新报表信息/更新图表内容/选择图表/移除图表 3.12 查看最近一次发布的版本 1)操作流程:选择报表-查看最近一次发布的版本 2)操作路径:数据可视化-报表-二级分组-报表名称-查看最近一次发布的版本 3)当报表发布后有更新,在最近发布时间左侧展示【查看】,在最近发布时间下展示更新的类型,点击查看可以查看最近发布的版 3.13 更新发布 1)操作流程:选择报表-更新发布报表 2)操作路径:数据可视化-报表-二级分组-报表名称-更新发布报表 3)选择单个已发布且没有被隐藏的报表,并且该报表在上次发布后有所更新,可以点击【更新发布】按钮,将最新的报表内容发布至业务系统,业务系统引用的报表为最新内容; 4)如果更新了内容,但未点击更新发布,则前端业务系统查看的报表仍为最近发布的报表 3.14 隐藏 1)操作流程:选择报表-隐藏报表 2)操作路径:数据可视化-报表-二级分组-报表名称-隐藏报表 3)报表默认不隐藏,可以切换是否隐藏=是 a. 未发布的报表,较隐藏前,不可以操作【发布】,可以【取消隐藏】; b. 已发布的图表,较隐藏前,只能操作【导出图片、导出excel、取消隐藏】; c. 隐藏后的报表不可以被引用,但不影响已经被引用的数据 3.15 取消隐藏 1) 操作流程:选择报表-取消隐藏报表 2) 操作路径:数据可视化-报表-二级分组-报表名称-取消隐藏报表 3) 隐藏后的报表可以取消隐藏,切换是否隐藏=否,取消隐藏后,报表恢复隐藏前的状态和功能,可以被引用 3.16 查看引用 1)流程:选择报表-查看被哪些页面引用 2)操作路径:数据可视化-报表-二级分组-报表-更多-查看引用 3)选择具体的报表,查看当前报表被引用的所有信息 3.17 不允许别人编辑 1)流程:选择报表-不允许别人编辑 2)操作路径:数据可视化-报表-二级分组-报表-更多-不允许别人编辑 3)选择自己创建的报表,对报表是否允许其他人编辑进行设置;如果设置为不允许,则其他人无法编辑报表 3.18 不允许别人引用 1)流程:选择图表-更多-不允许别人引用 2)操作路径:数据可视化-报表-二级分组-报表-更多-不允许别人引用 3)选择自己创建的报表,对报表是否允许他人引用进行设置;如果设置为不允许,则其他人无法引用到该报表 3.19 导出图片 1) 操作流程:选择报表-导出图片 2) 操作路径:数据可视化-报表-二级分组-报表名称-导出图片 3) 选择报表后,点击【导出图片】按钮可以将当前报表导出为图片 3.20 导出EXCEL 1)操作流程:选择报表-导出EXCEL 2)操作路径:数据可视化-报表-二级分组-报表名称-报表导出EXCEL 3)选择报表后,点击【导出EXCEL】按钮可以将当前报表导出为EXCEL
-
3.4.1 构建第一个Function
Function做为oinone的可管理的执行逻辑单元,是无处不在的 在3.3.3【模型的数据管理器】和3.3.2【模型类型】一文中的代理模型部分,涉及到包括在Action中自定义函数(action背后都对应一个Function)、重写queryPage的函数、以及独立抽取的公共逻辑函数,Function做为oinone的可管理的执行逻辑单元,是无处不在的。这也是为什么说oinone以函数为内在的原因。 一、构建第一个Function 因为数据管理器和数据构造器是oinone为模型自动赋予的Function,是内在数据管理能力。模型其他Function都需要用以下四种方式主动定义 伴随模型新增函数(举例) 它是跟模型的java类定义在一起,复用模型的命名空间。 Step1 为PetShop增加一个名为sayHello的Function package pro.shushi.pamirs.demo.api.model; …… //import @Model.model(PetShop.MODEL_MODEL) @Model(displayName = "宠物店铺",summary="宠物店铺",labelFields ={"shopName"} ) @Model.Code(sequence = "DATE_ORDERLY_SEQ",prefix = "P",size=6,step=1,initial = 10000,format = "yyyyMMdd") public class PetShop extends AbstractDemoIdModel { public static final String MODEL_MODEL="demo.PetShop"; …… //省略其他代码 @Function(openLevel = FunctionOpenEnum.API) @Function.Advanced(type=FunctionTypeEnum.QUERY) public PetShop sayHello(PetShop shop){ PamirsSession.getMessageHub().info("Hello:"+shop.getShopName()); return shop; } } 图3-4-1-1 代码示例 Step2 重启看效果 用graphQL工具Insomnia查看效果 用Insomnia模拟登陆 a. 创建一个login请求,用于保存login请求,为后续模拟登陆保留快捷方式 图3-4-1-2 创建一个login请求 b. 下面为登陆请求的GraphQL,请在post输入框中输入。如果请求输入框提示错误可以,可以点击schema 的Refresh Schema来刷新文档 mutation { pamirsUserTransientMutation { login(user: {login: "admin", password: "admin"}) { broken errorMsg errorCode errorField } } } 图3-4-1-3 登陆请求的GraphQL c. 点击Send按钮,我们可以看到登陆成功的反馈信息 图3-4-1-4 登陆成功的反馈信息 用Insomnia模拟访问PetShop的sayHello方法,gql的返回中,我们可以看到两个核心返回 a. 一是方法正常返回的shopName b. 二是“PamirsSession.getMessageHub().info("Hello:"+shop.getShopName())”代码执行的结果,在messages中有一个消息返回,更多消息机制详见4.1.23【框架之信息传递】 query{ petShopQuery{ sayHello(shop:{shopName:"cpc"}){ shopName } } } 图3-4-1-5 用Insomnia模拟访问PetShop的sayHello 图3-4-1-6 代码执行结果 用Insomnia模拟访问PetShopProxy的sayHello方法 效果同用Insomnia模拟访问PetShop的sayHello方法,体现Function的继承特性。 独立新增函数绑定到模型(举例) 独立方法定义类,并采用Model.model或Fun注解,但是value都必须是模型的编码,如@Model.model(PetShop.MODEL_MODEL)或@Fun(PetShop.MODEL_MODEL) Step1 提取PetShop的sayHello方法独立到PetShopService中 注释掉PetShop的sayHello方法 package pro.shushi.pamirs.demo.api.model; …… //import @Model.model(PetShop.MODEL_MODEL) @Model(displayName = "宠物店铺",summary="宠物店铺",labelFields ={"shopName"} ) @Model.Code(sequence = "DATE_ORDERLY_SEQ",prefix = "P",size=6,step=1,initial = 10000,format = "yyyyMMdd") public class PetShop extends AbstractDemoIdModel { public static final String MODEL_MODEL="demo.PetShop"; …… //省略其他代码 // @Function(openLevel = FunctionOpenEnum.API) // @Function.Advanced(type=FunctionTypeEnum.QUERY) // public PetShop sayHello(PetShop shop){ // PamirsSession.getMessageHub().info("Hello:"+shop.getShopName()); // return shop; // } } 图3-4-1-7 注释掉PetShop的sayHello 新增PetShopService接口类 接口的方法上要加上@Function注解,这样另模块依赖api包的时候,会自动注册远程服务的消费者 package pro.shushi.pamirs.demo.api.service; import pro.shushi.pamirs.demo.api.model.PetShop; import pro.shushi.pamirs.meta.annotation.Fun; import pro.shushi.pamirs.meta.annotation.Function; @Fun(PetShop.MODEL_MODEL) //@Model.model(PetShop.MODEL_MODEL) public interface…
-
报表发布主流程
1. 主业务流程图 2. 主业务流程操作图解 创建图表—创建报表/数据大屏—发布图表/报表—前端业务系统可引用 2.1 创建图表分组 1)操作流程:创建图表分组 2)操作路径:数据可视化-图表-创建图表分组 3)点击搜索框后的「+」创建一级分组,输入一级分组名称后,点击一级分组后的「+」创建二级分组,输入二级分组名称后,此时分组创建完成,可以在二级分组下创建图表 2.2 创建图表 1)操作流程:选择图表二级分组-创建图表 2)操作路径:数据可视化-图表-二级分组-创建图表 3)鼠标移动至需要创建图表的二级分组上,出现「+」,点击图标后弹出“创建图表”弹窗,需要填写图表标题、模型、方法; a. 图表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复; b. 模型:需要选择来源数据对应的模型; c. 方法:选择模型后需要选择方法,方法是用来提取模型数据的逻辑; 4)选择成功后进图表设计页面(详见图表-图表设计页面),设计完成后点击保存,图表创建成功 2.3 创建报表分组 1)操作流程:创建报表分组 2)操作路径:数据可视化-报表-创建报表分组 3)点击搜索框后的「+」创建一级分组,输入一级分组名称后,点击一级分组后的「+」创建二级分组,输入二级分组名称后,此时分组创建完成,可以在二级分组下创建报表 2.4 创建数据大屏分组 1)操作流程:创建报表分组 2)操作路径:数据可视化-报表-创建报表分组 3)点击搜索框后的「+」创建一级分组,输入一级分组名称后,点击一级分组后的「+」创建二级分组,输入二级分组名称后,此时分组创建完成,可以在二级分组下创建报表 2.5 创建报表 1)操作流程:选择报表二级分组-创建报表 2)操作路径:数据可视化-报表-二级分组-创建报表 3)鼠标移动至需要创建报表的二级分组上,出现「+」,点击图标后=需要填写报表标题; a报表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复; 4)创建后可以选择报表需要展示的图表 2.6 为报表选择图表 1)操作流程:选择报表-为报表选择图表 2)操作路径:数据可视化-图表-二级分组-报表-选择图表 3)选择单个未发布或者已发布但没有被隐藏的报表,点击【选择图表】,弹出“选择图表”弹窗,对该报表需要展示的图表进行选择 a需要选择图表的一级分组后才能选择图表; b可以多选图表,选择的图表只能是已选一级分组下的未隐藏的未被选择的图表;选择一个二级分组时,默认该二级分组下的图表会全部被选中,图表会按照选中的顺序展示在报表列表; 4)选择图表后,报表信息保持展示图表的最新效果;如果图表更新了,但是报表没有发布最新,则报表在前端展示的仍为最近发布的版本; 5)如果图表中存在超过一行的图内筛选项,则在报表处原始的图表尺寸只能查看一行图内筛选项,需要根据图表在报表处的等比拖动效果展示更多的图内筛选项 2.7 创建数据大屏 1)操作流程:选择数据大屏二级分组-创建数据大屏 2)操作路径:数据可视化-数据大屏-二级分组-创建 3)鼠标移动至需要创建数据大屏的二级分组上,出现「+」,点击图标后进入数据大屏设计页面; a. 选择图表组件组合成数据大屏,还有其他诸如时间、图片等组件可供选择; b. 数据大屏标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复; 4)选择完成后可以保存,则创建数据大屏成功 2.8 发布图表/报表/数据大屏 1)操作流程:选择图表/报表-发布图表/报表 2)操作路径:数据可视化-图表/报表/数据大屏-二级分组-图表名称/报表名称/数据大屏名称-发布 3)选择单个未发布且没有被隐藏的图表/报表/数据大屏,点击【发布】按钮,图表/报表发布后可以被前端引用,数据大屏可被屏幕演示,图表/报表/数据大屏状态变为已发布,展示最近发布时间; a. 如果图表发布后有更新内容,会展示的更新类型:更新图表信息/更新图表内容; b. 如果报表发布后有更新内容,会展示的更新类型:更新报表信息/更新图表内容/选择图表/移除图表; c. 如果数据大屏发布后有更新内容,会展示的更新类型:更新数据大屏信息/更新数据大屏内容; 4)发布后可以修改 2.9更新发布图表/报表/数据大屏 1)操作流程:选择图表/报表-更新发布图表/报表 2)操作路径:数据可视化-图表/报表/数据大屏-二级分组-图表名称/报表名称/数据大屏名称-更新发布图表/报表/数据大屏 3)选择单个已发布且没有被隐藏的图表/报表/数据大屏,并且该图表/报表/数据大屏在上次发布后有所更新,可以点击【更新发布】按钮,将最新的图表/报表内容发布至业务系统,业务系统引用的图表/报表为最新内容,屏幕展示的数据大屏是最新的大屏内容; 4)如果更新了内容,但未点击更新发布,则前端业务系统查看的图表/报表仍为最近发布的内容,屏幕展示的数据大屏仍是最近发布的内容