
元位指令系统是通过给请求上下文的指令位字段作按位与标记来对函数处理下发对应指令的系统。
一、元位指令介绍
元位指令系统是通过给请求上下文的指令位字段作按位与标记来对函数处理下发对应指令的系统。
元位指令系统分为请求上下文指令和数据指令两种。
数据指令
数据指令基本都是系统内核指令。业务开发时用不到这里就不介绍了。前20位都是系统内核预留
请求上下文指令
请求上下文指令:使用session上下文中非持久化META_BIT属性设置指令。
| 位 | 指令 | 指令名 | 前端默认值 | 后端默认值 | 描述 |
|---|---|---|---|---|---|
| 20 | builtAction | 内建动作 | 否 | 否 | 是否是平台内置定义的服务器动作对应操作:PamirsSession.directive().disableBuiltAction(); PamirsSession.directive().enableBuiltAction(); |
| 21 | unlock | 失效乐观锁 | 否 | 否 | 系统对带有乐观锁模型默认使用乐观锁对应操作:PamirsSession.directive().enableOptimisticLocker(); PamirsSession.directive().disableOptimisticLocker(); |
| 22 | check | 数据校验 | 是 | 否 | 系统后端操作默认不进行数据校验,标记后生效数据校验对应操作:PamirsSession.directive().enableCheck(); PamirsSession.directive().disableCheck(); |
| 23 | defaultValue | 默认值计算 | 是 | 否 | 是否自动填充默认值对应操作:PamirsSession.directive().enableDefaultValue(); PamirsSession.directive().disableDefaultValue(); |
| 24 | extPoint | 执行扩展点 | 是 | 否 | 前端请求默认执行扩展点,可以标记忽略扩展点。后端编程式调用数据管理器默认不执行扩展点对应操作:PamirsSession.directive().enableExtPoint(); PamirsSession.directive().disableExtPoint(); |
| 25 | hook | 拦截 | 是 | 否 | 是否进行函数调用拦截对应操作:PamirsSession.directive().enableHook(); PamirsSession.directive().disableHook(); |
| 26 | authenticate | 鉴权 | 是 | 否 | 系统默认进行权限校验与过滤,标记后使用权限校验对应操作:PamirsSession.directive().sudo(); PamirsSession.directive().disableSudo(); |
| 27 | ormColumn | ORM字段别名 | 否 | 否 | 系统指令,请勿设置 |
| 28 | usePkStrategy | 使用PK策略 | 是 | 否 | 使用PK是否空作为采用新增还是更新的持久化策略对应操作:PamirsSession.directive().enableUsePkStrategy(); PamirsSession.directive().disableUsePkStrategy(); |
| 29 | fromClient | 是否客户端调用 | 是 | 否 | 是否客户端(前端)调用对应操作:PamirsSession.directive().enableFromClient(); PamirsSession.directive().disableFromClient(); |
| 30 | sync | 同步执行函数 | 否 | 否 | 异步执行函数强制使用同步方式执行(仅对Spring Bean有效) |
| 31 | ignoreFunManagement | 忽略函数管理 | 否 | 否 | 忽略函数管理器处理,防止Spring调用重复拦截对应操作:PamirsSession.directive().enableIgnoreFunManagement(); PamirsSession.directive().disableIgnoreFunManagement(); |
二、使用指令
普通模式
PamirsSession.directive().disableOptimisticLocker();
try{
更新逻辑
} finally {
PamirsSession.directive().enableOptimisticLocker();
}批量设置模式
Models.directive().run(() -> {此处添加逻辑}, SystemDirectiveEnum.AUTHENTICATE)三、使用举例
我们在4.1.5【模型之持久层配置】一文中提到过失效乐观锁,我们在这里就尝试下吧。
Step1 修改PetItemInventroyAction
手动失效乐观锁
package pro.shushi.pamirs.demo.core.action;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetItemInventroy;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.meta.constant.FunctionConstants;
import pro.shushi.pamirs.meta.enmu.FunctionOpenEnum;
import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum;
import java.util.ArrayList;
import java.util.List;
@Model.model(PetItemInventroy.MODEL_MODEL)
@Component
public class PetItemInventroyAction {
@Function.Advanced(type= FunctionTypeEnum.UPDATE)
@Function.fun(FunctionConstants.update)
@Function(openLevel = {FunctionOpenEnum.API})
public PetItemInventroy update(PetItemInventroy data){
List<PetItemInventroy> inventroys = new ArrayList<>();
inventroys.add(data);
PamirsSession.directive().disableOptimisticLocker();
try{
//批量更新会,自动抛错
int i = data.updateBatch(inventroys);
//单记录更新,不自动抛售需要自行判断
// int i = data.updateById();
// if(i!=1){
// throw PamirsException.construct(DemoExpEnumerate.PET_ITEM_INVENTROY_UPDATE_VERSION_ERROR).errThrow();
// }
} finally {
PamirsSession.directive().enableOptimisticLocker();
}
return data;
}
}Step2 重启看效果
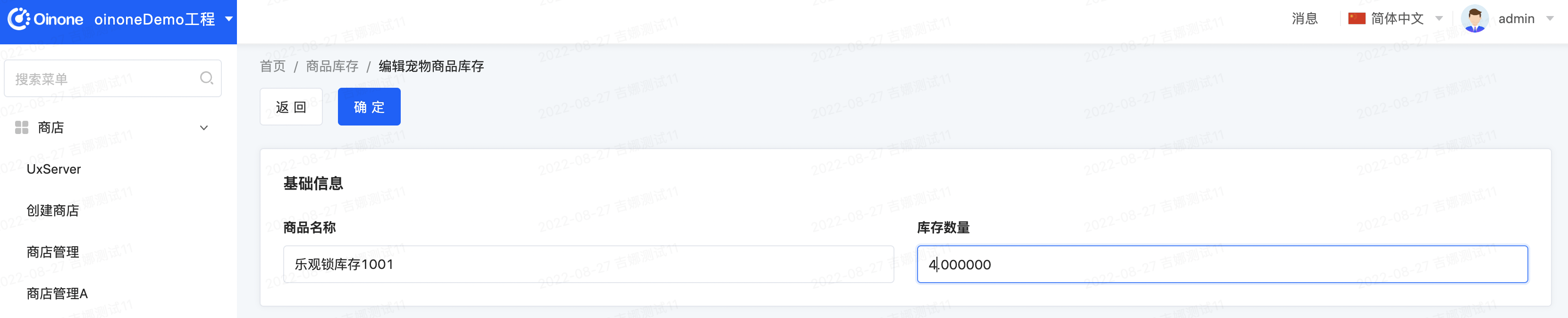
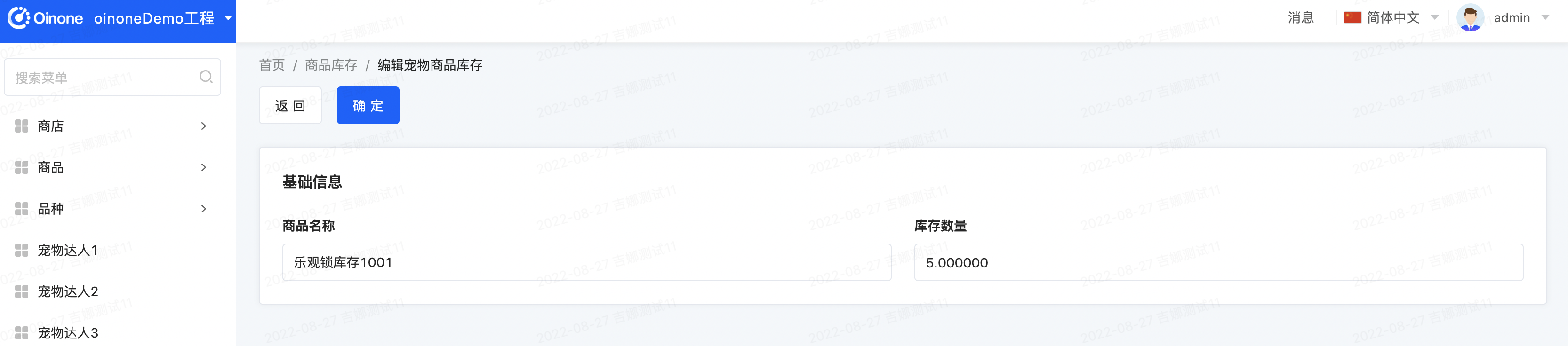
体验一:页面上修改记录,数据库字段中的opt_version不再自动加一
体验二:同时打两个页面,依次点击,您会发现两次都成功。数据库字段中的opt_version不再自动加一


Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9284.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验