
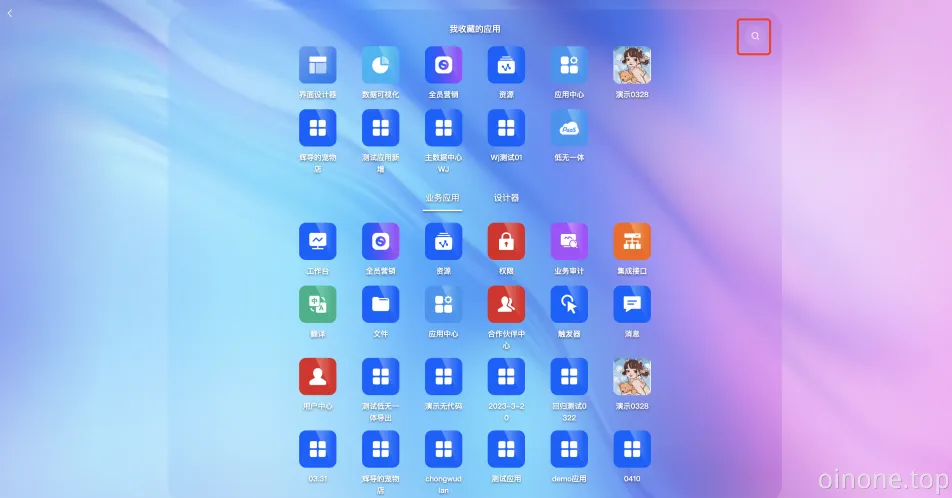
在App Finder 中点击应用中心可以进入Oinone的应用中心,可以看到Oinone平台所有应用列表、应用大屏、以及技术可视化。
1. App Finder
平台提供App Finder搜索查找已安装的应用、点击进入应用;
我收藏的应用:在应用中心收藏后会呈现在“我收藏的应用”;
业务应用:与业务相关、用户可操作的应用;
设计器:平台提供五大设计器设计应用,即平台的无代码能力,包括:模型设计器、界面设计器、流程设计器、数据可视化、集成设计器。

2. 应用列表
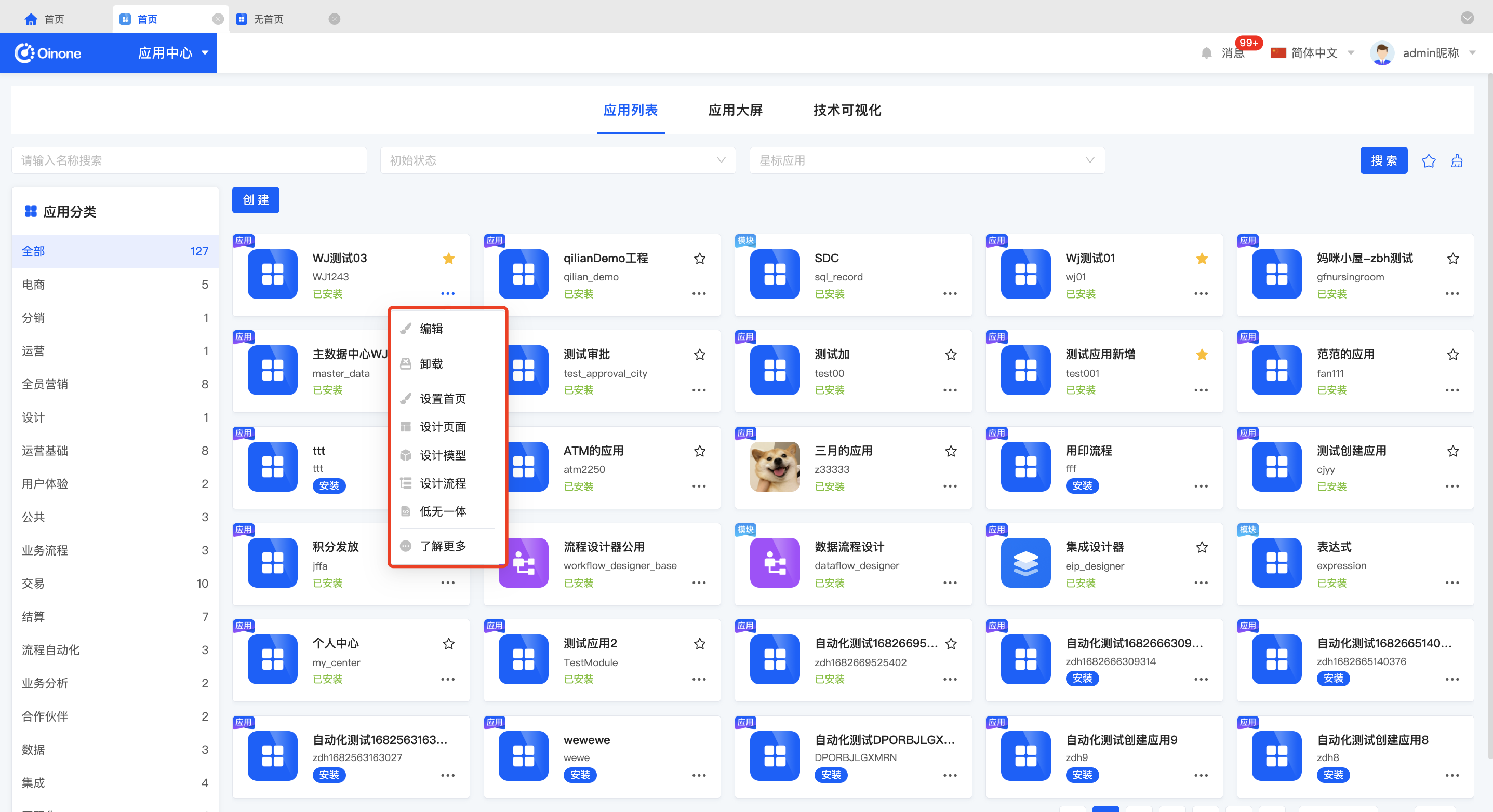
应用列表管理平台中所有应用,管理应用的生命周期,如安装、升级、卸载,提供搜索、创建、编辑、卸载、收藏、设置首页等功能。
在介绍应用具体操作前,我们先来了解以下概念:
应用类型:分为应用与模块两种类型,两者区别在于在于应用有前台页面,可以在前台页面操作数据,模块没有前台页面、服务于其他应用或模块,大家在创建应用时可根据业务需求创建应用或模块。
依赖:创建新应用时,可依赖已有应用或模块,依赖后使用依赖应用/模块的能力,比如依赖文件应用可使用导入、导出能力,依赖资源应用可使用地址、语言等能力。
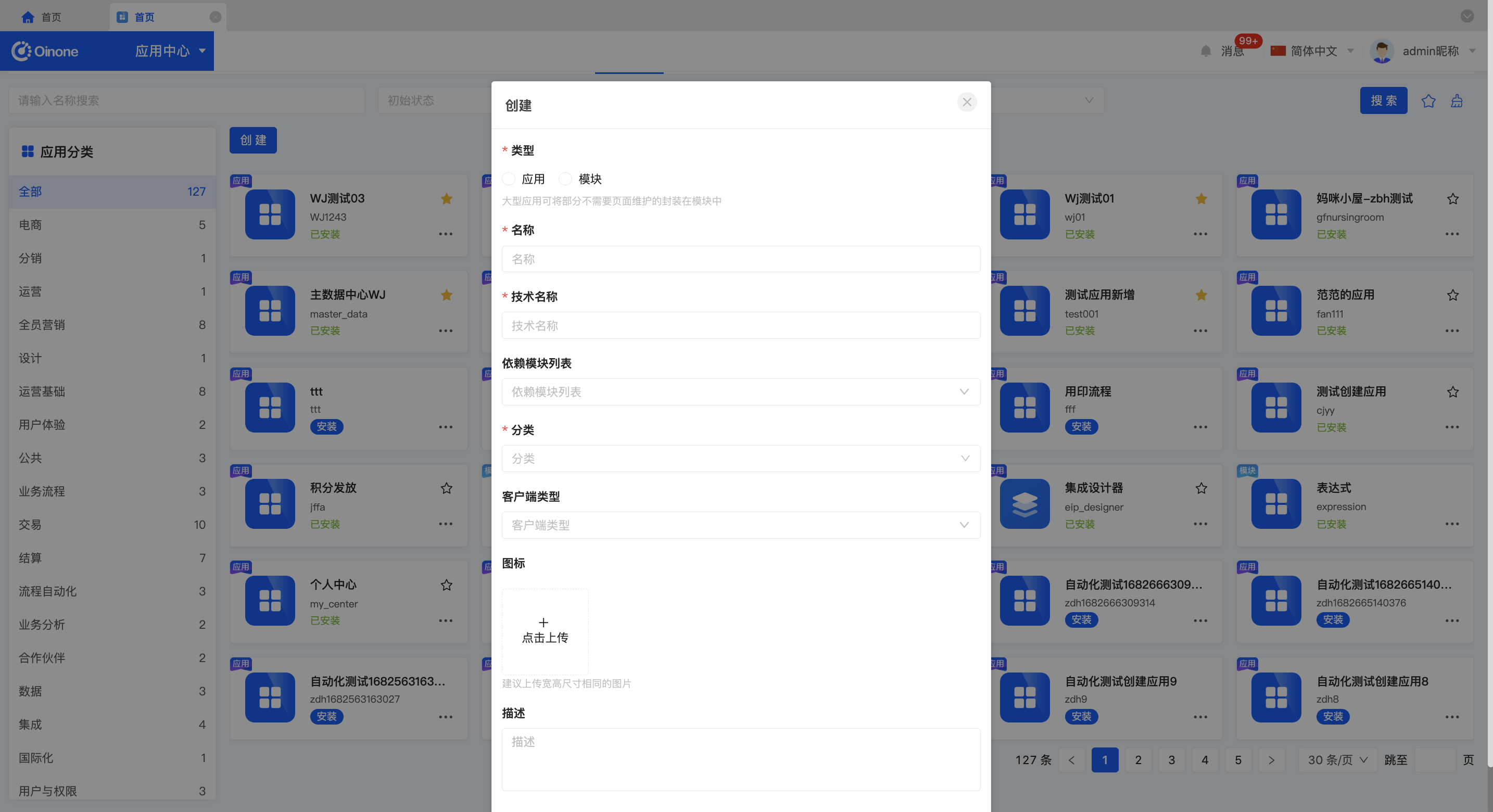
2.1 创建
- 创建应用时,需要选择类型、定义应用名称、技术名称,选择依赖模块、所属分类、客户端类型。
- 每个应用大多数都需要依赖一些基础模块:文件、资源、
- 应用分类是按照应用所属业务域进行的分类管理,目前是平台提供的分类,后续会开放给用户自行管理。
- 客户端类型是指应用适用于PC端、移动端,如果只选择PC端,则应用不可在移动端使用。
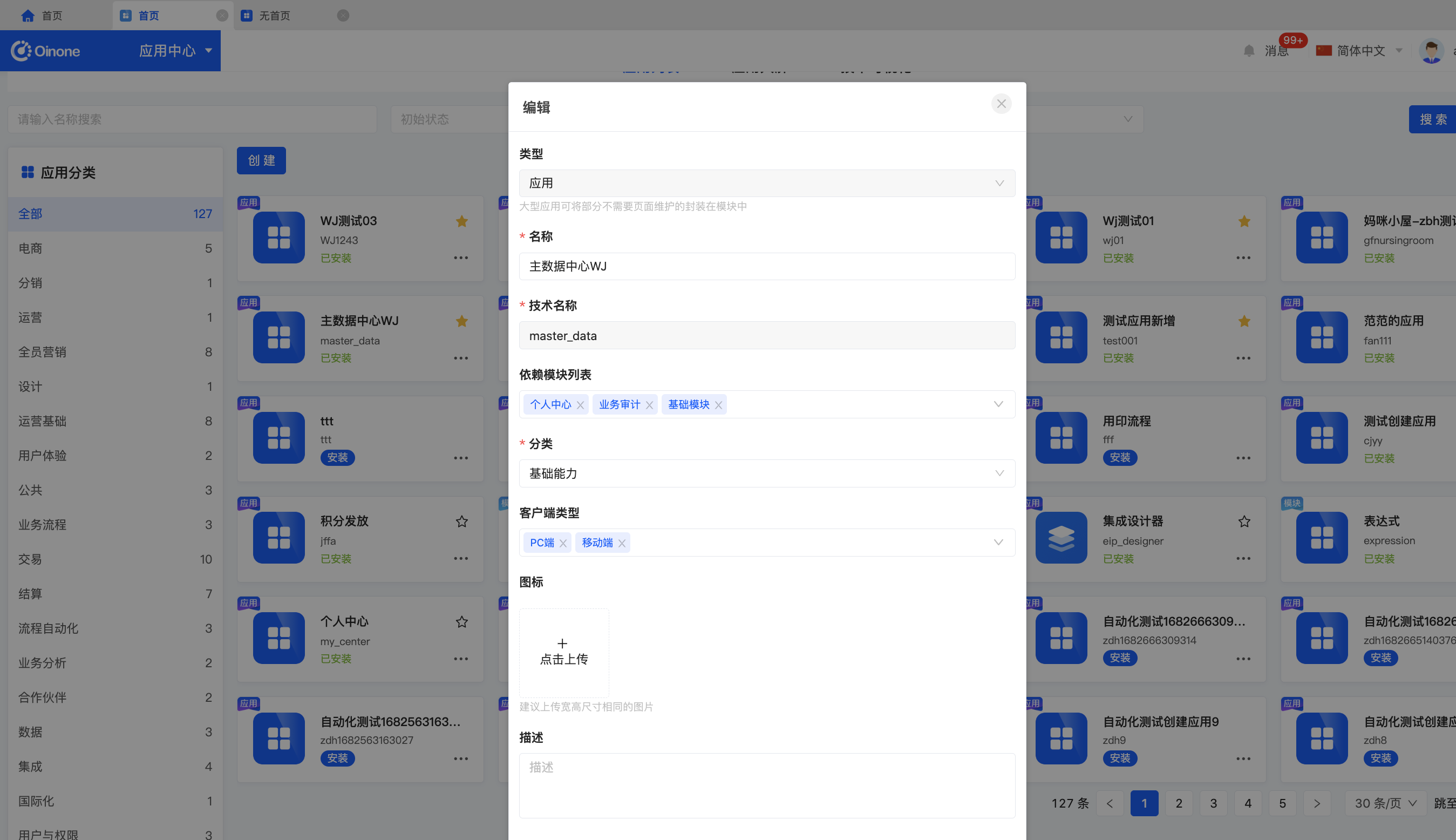
2.2 编辑
编辑时,不允许编辑类型,技术名称,需要在创建时定义正确。
2.3 安装与卸载
卸载后,应用就不会呈现在App Finder中,不可进入应用、使用应用,可重新安装,安装后继续使用。
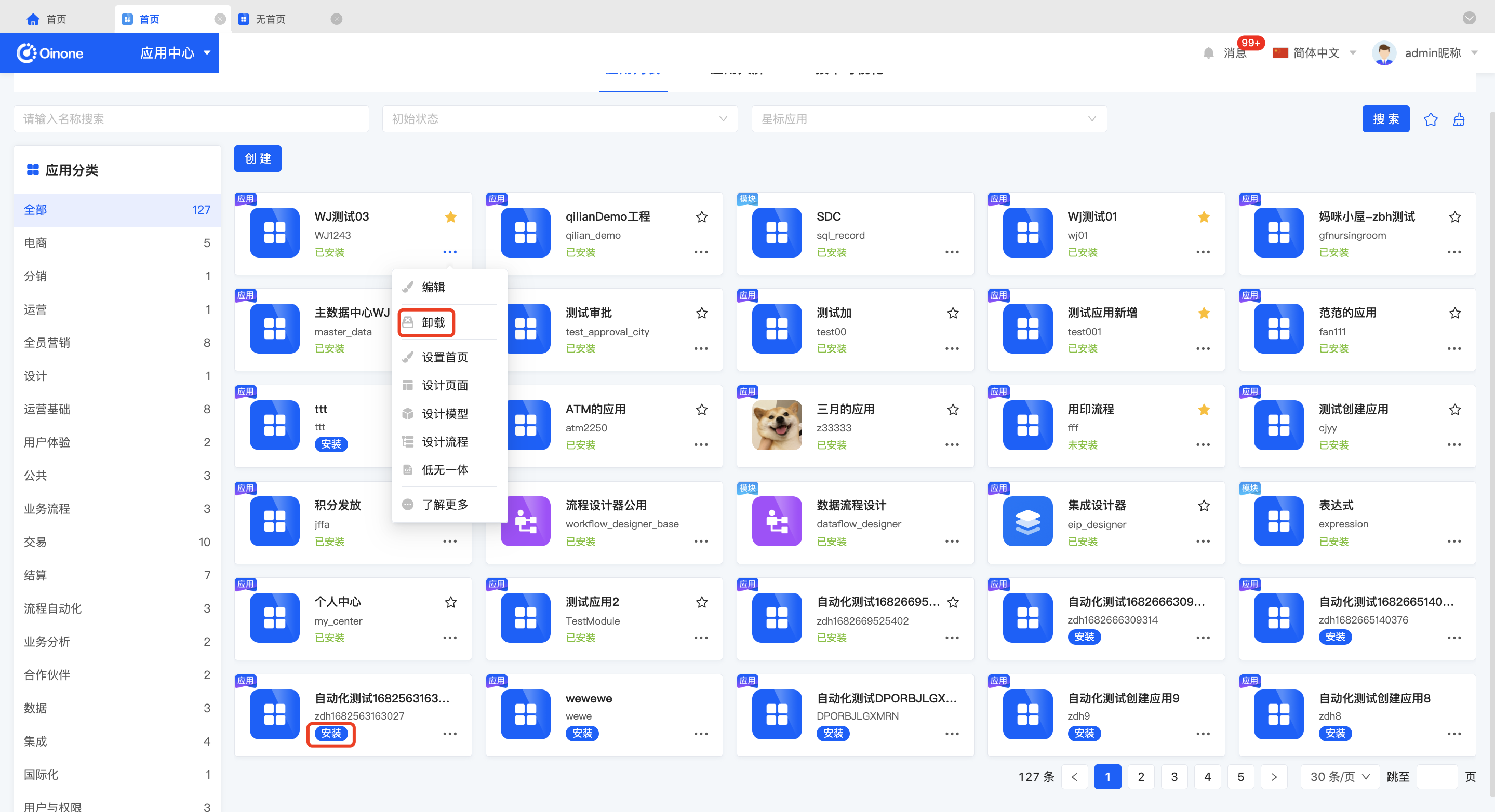
2.4 收藏应用
点击应用卡片右上角的星标可收藏、取消收藏应用,收藏的应用在App Finder和工作台中展示在收藏位置,可快捷进入。
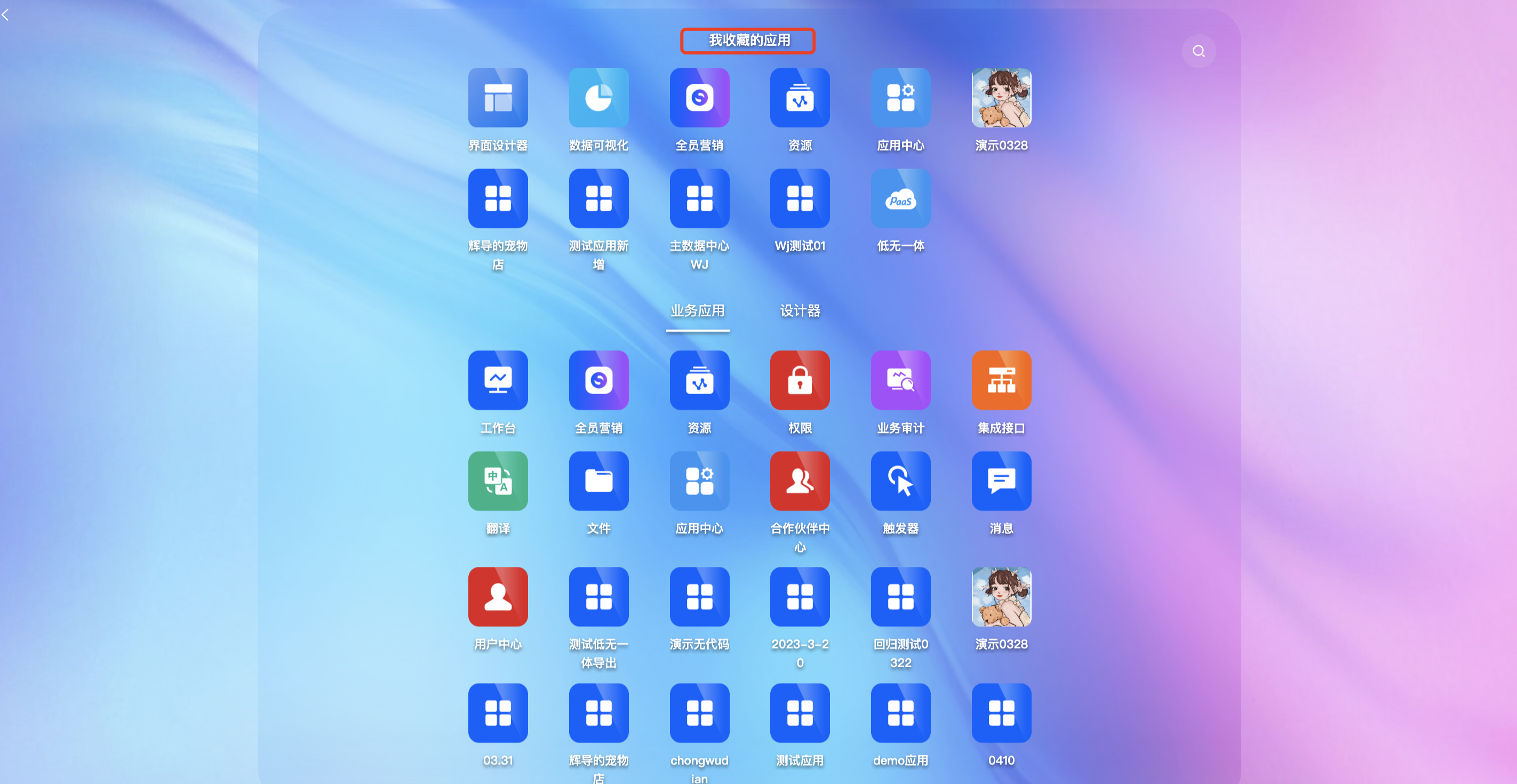
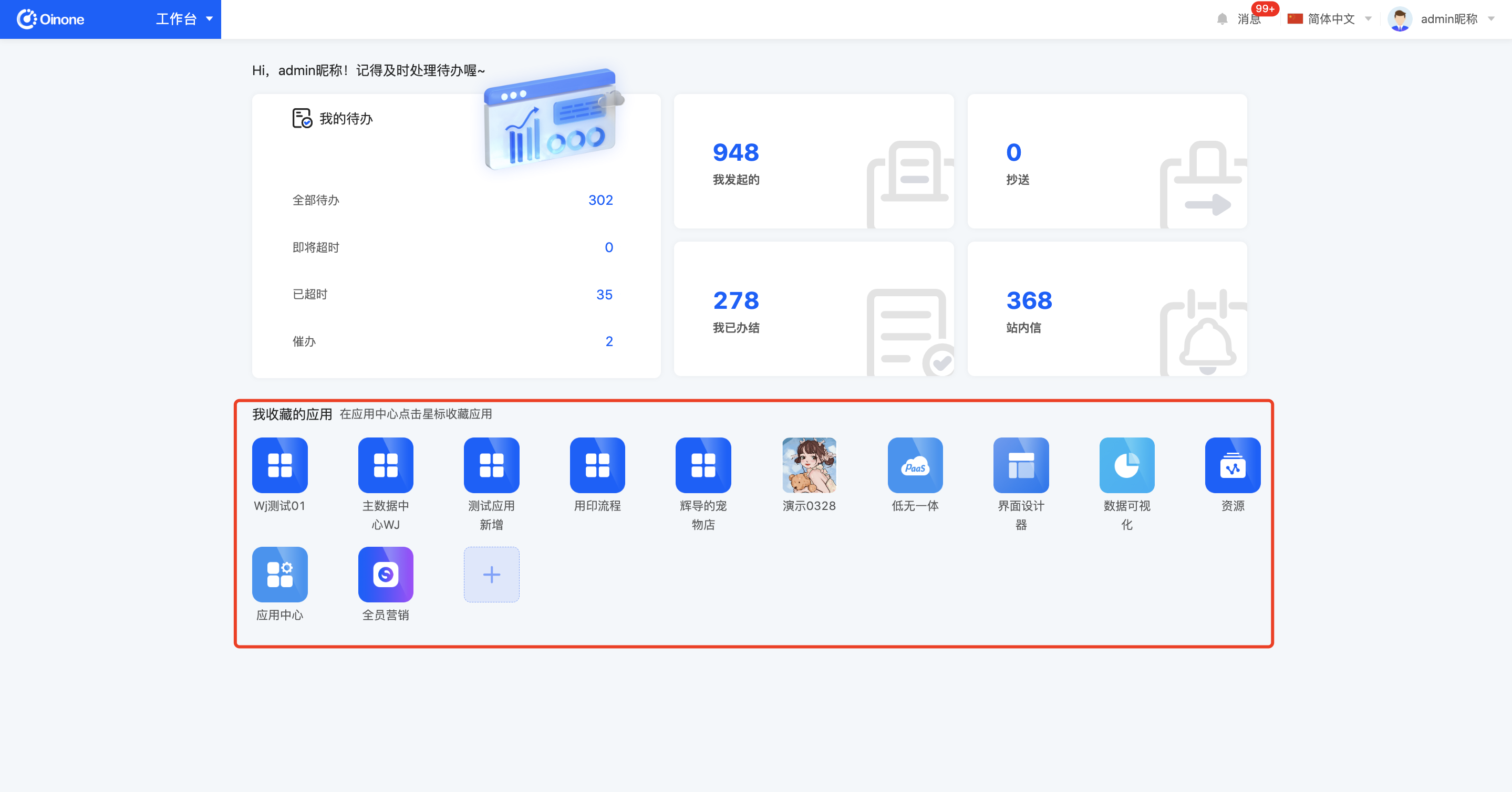
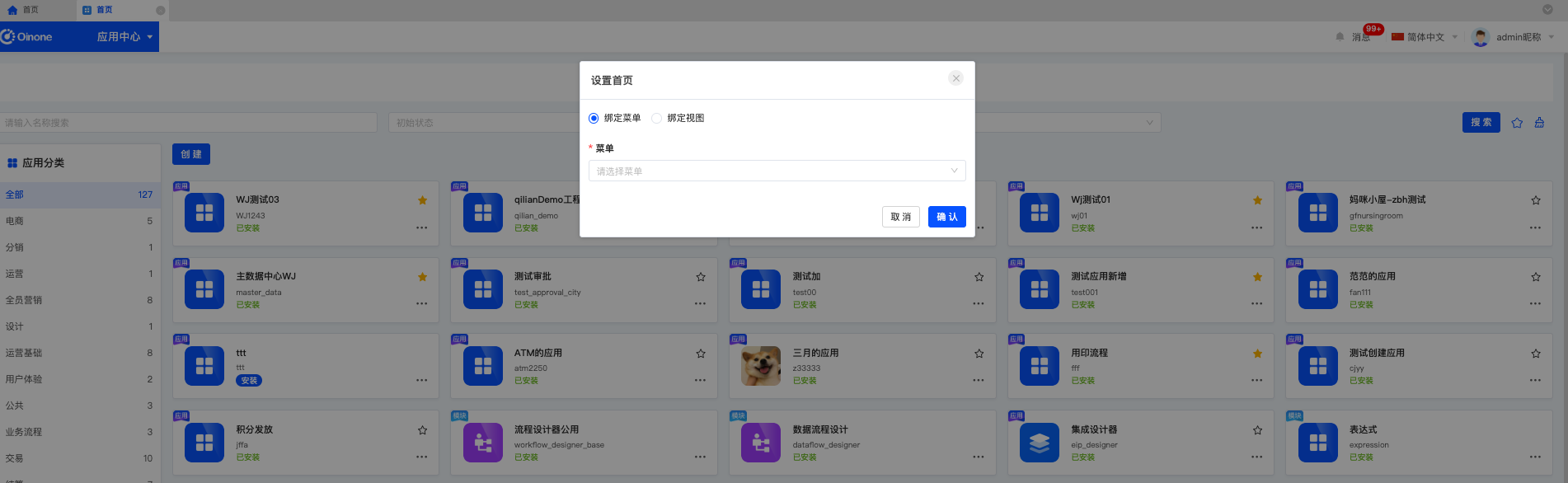
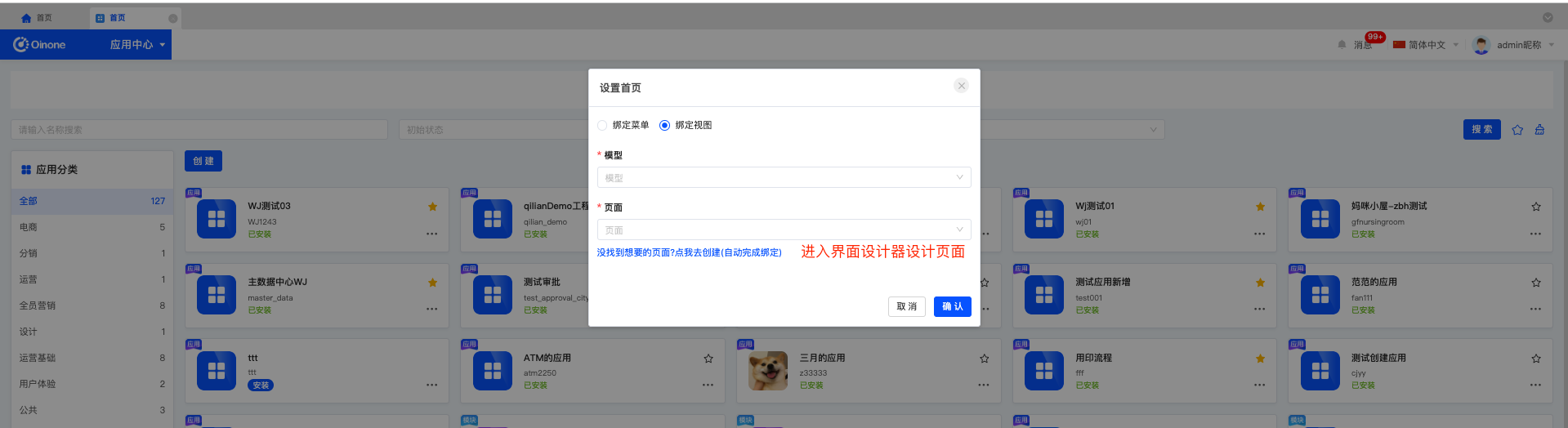
2.5 设置首页
定义每个应用的首页,有两种方式:
a. 通过绑定菜单,进入绑定菜单的页面;
b. 直接绑定视图,选择模型、找到模型下的视图,如果可作为首页的视图不存在,也可以进入设计器创建。
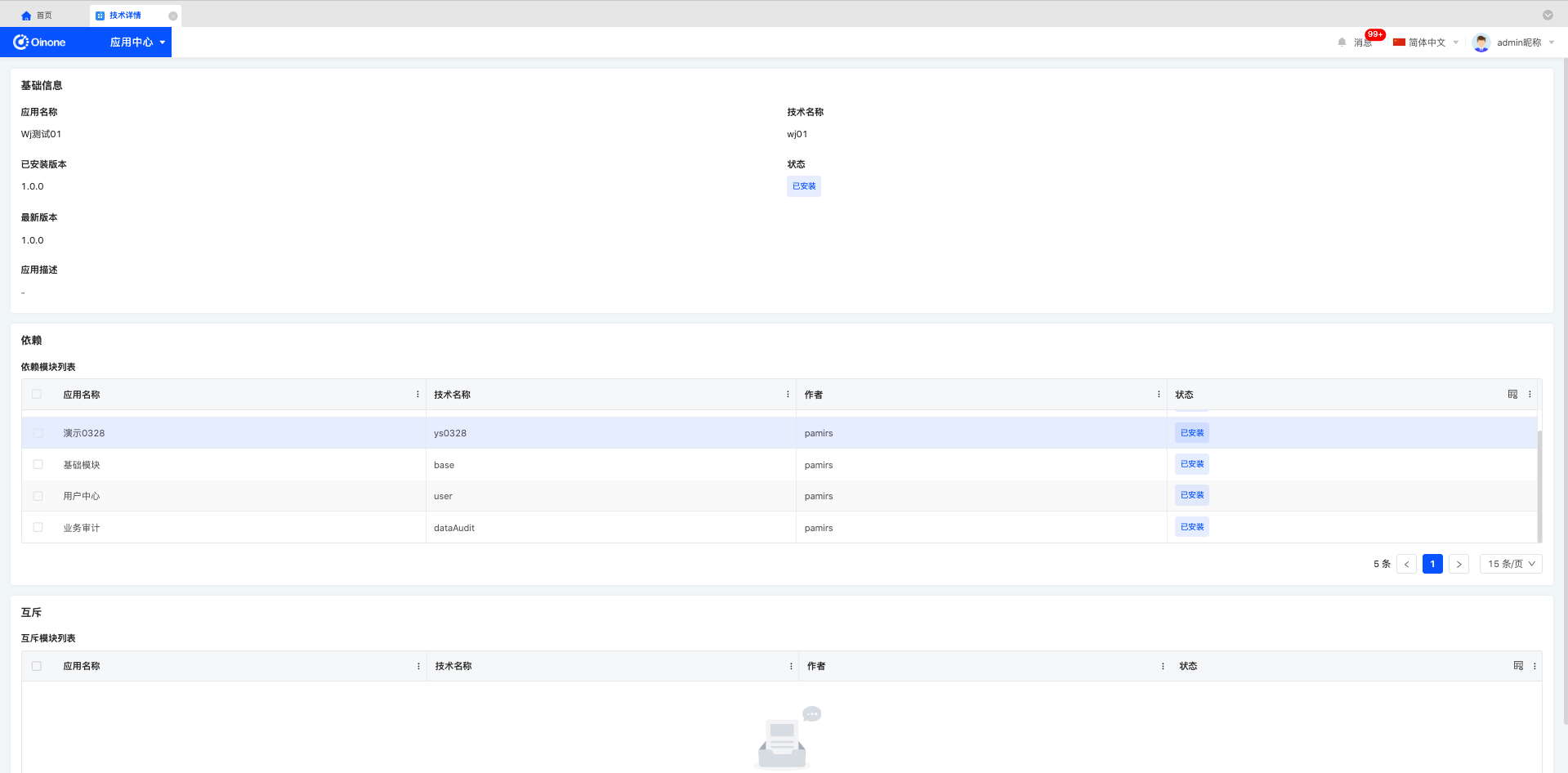
2.6 应用详情
点击了解更多,可进入应用详情,查看应用基础信息。
2.7 设计器快捷入口
设计页面:进入界面设计器;
设计模型:进入模型设计器;
设计流程:进入流程设计器;
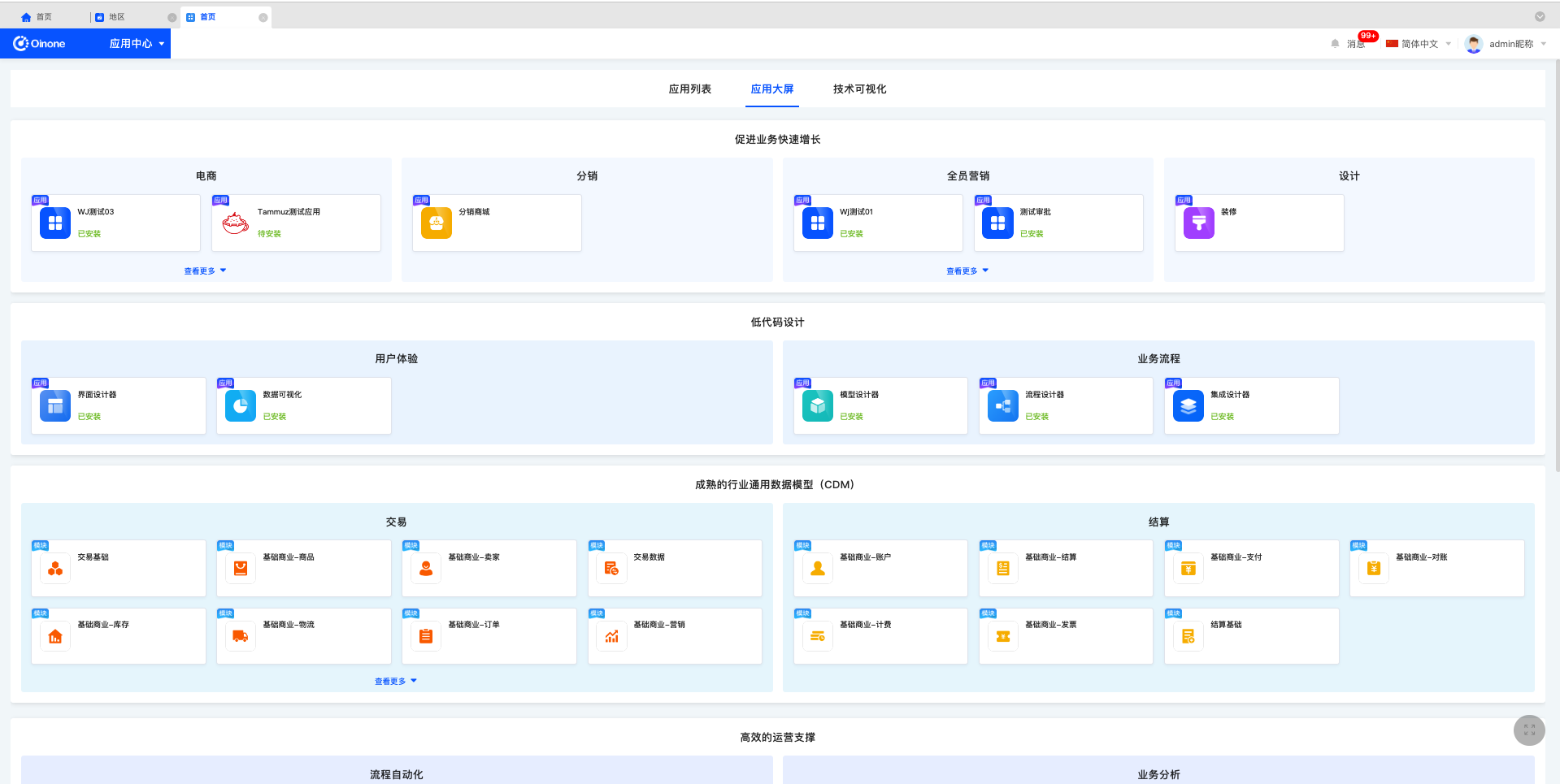
3. 应用大屏
应用大屏按照分类展示应用,未设置应用分类的应用,无法在应用大屏中呈现。
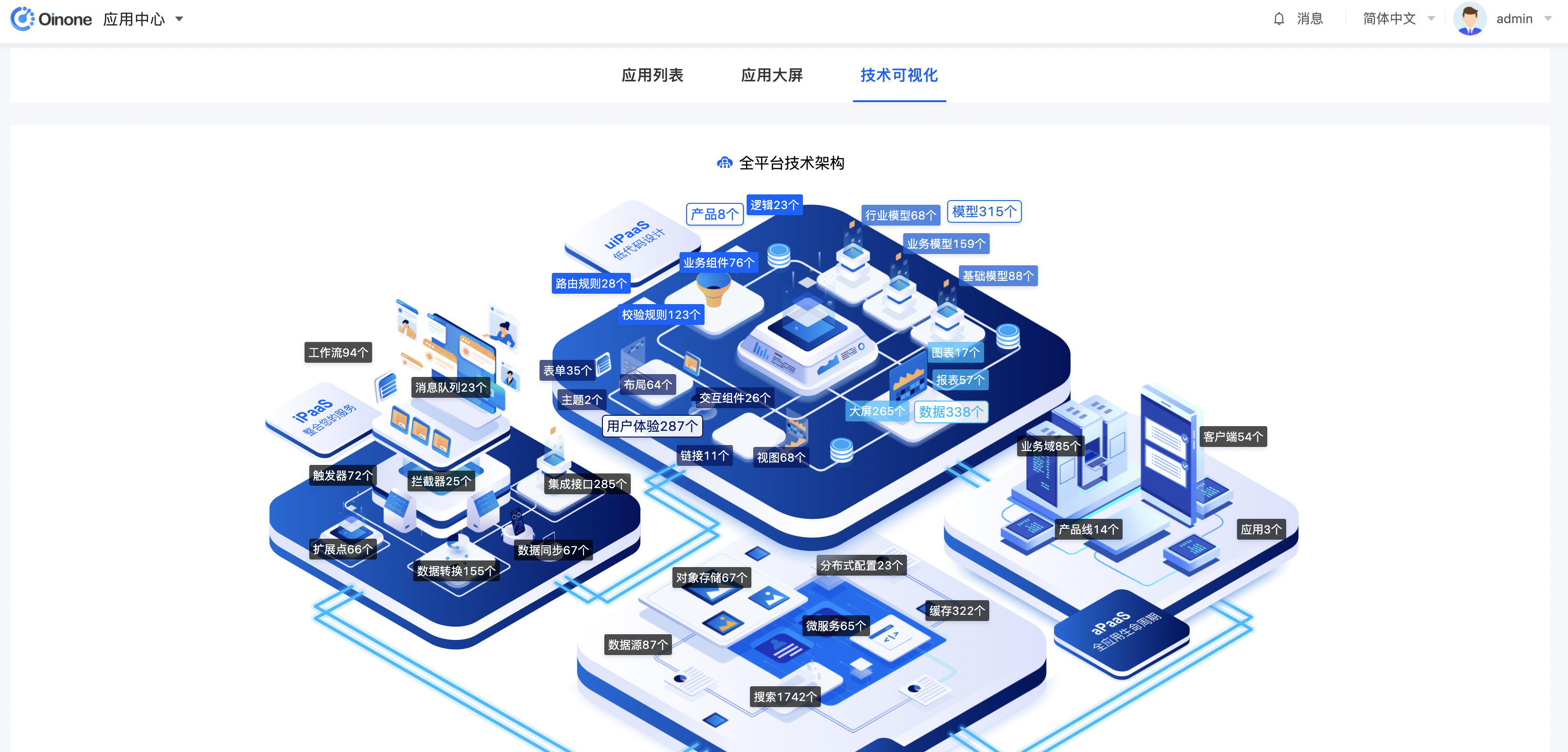
4. 技术可视化
在技术可视化页面,出展示已经安装模块的元数据,并进行分类呈现。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9386.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验