
在页面开发的时候,直接通过前端组件和视图xml进行开发虽然开放性是很大的、但我们经常会忘记视图的配置属性,同时用xml配置的页面因为缺少设计数据,导致无法直接在设计器中复制,自定义页面得从头设计。今天就带大家一起来学习如何结合无代码设计器来完成页面开发,并把设计后的页面元数据装载为标准产品的一部分。
1 安装Docker
如果没有Docker的话,请自行到官网下载:https://www.docker.com/get-started/
2 下载Docker 镜像,并导入镜像
Step2.1 镜像下载
| v.4.6.28.3-allinone-full | 版本说明 | 前后端以及中间件一体 |
|---|---|---|
| 镜像地址 | docker pull harbor.oinone.top/oinone/designer:4.6.28.3-allinone-full | |
| 下载结构包 | oinone-op-ds-all-full.zip(17 KB) | |
| v.4.6.28.3-allinone-mini | 版本说明 | 前后端一体支持外部中间件 |
| 镜像地址 | docker pull harbor.oinone.top/oinone/designer:4.6.28.3-allinone-mini | |
| 下载结构包 | oinone-op-ds-all-mini.zip(14 KB) | |
| v.4.7.9-allinone-full | 版本说明 | 前后端以及中间件一体 |
| 镜像地址 | docker pull harbor.oinone.top/oinone/designer:4.7.9-allinone-full | |
| 下载结构包 | oinone-op-ds-all-full.zip(17 KB) | |
| v.4.7.9-allinone-mini | 版本说明 | 前后端一体支持外部中间件 |
| 镜像地址 | docker pull harbor.oinone.top/oinone/designer:4.7.9-allinone-mini | |
| 下载结构包 | oinone-op-ds-all-mini.zip(14 KB) |
Step2.1.2 镜像下载用户与密码
需要商业版镜像需要加入Oinone商业版本伙伴专属群,向Oinone技术支持获取用户名与密码,镜像会定时更新并通知大家。
#注意:docker镜像拉取的账号密码请联系数式技术
docker login --username=用户名 harbor.oinone.top
docker pull docker pull harbor.oinone.top/oinone/designer:4.6.28.3-allinone-fullStep2.1.3 镜像和版本选择
目前有2个版本可供选择,包含中间件以及不包含中间件2个版本,下载结构包以后注意修改startup.sh和startup.cmd中对应镜像地址的版本号。
Step2.1.4 本地结构说明
下载结构包并解压
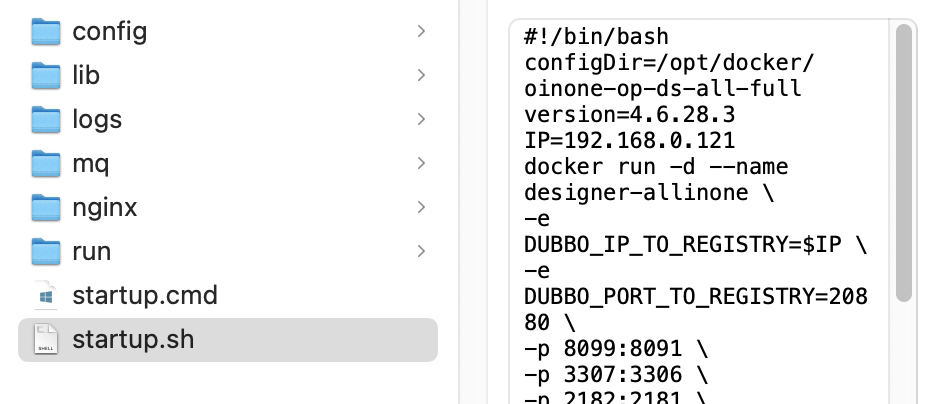

-
config是放application.yml的目录,可以在application.yml配置需要启动的自有模块同时修改对应其他中间件配置项
-
lib是放自有模块的jar包以及其对应的依赖包比如:pamirs-demo-api-1.0.0-SNAPSHOT.jar和pamirs-demo-core-1.0.0-SNAPSHOT.jar
-
nginx:前端运行的nginx站点配置文件
-
mq:消息配置,再使用低无一体时需要指定mq的broker的IP
-
run:容器运行中间件的脚本,可以对个别中间件是否启动进行设置,(注释掉运行脚本,容器启动时就不会启动该中间件)
-
logs是运行时系统日志目录
Step2.2 修改startup.sh中的路径
Step2.2.1 linux环境修改参数
在文件中找到如下 configDir=/opt/docker/oinone-op-ds-all-full version=4.6.28.3 IP=192.168.0.121
-
修改configDir的路径(下载oinone-op-ds-xx.zip解压后的路径)
-
修改对应的镜像版本号
-
修改对应的IP为docker宿主机IP
#!/bin/bash
configDir=/opt/docker/oinone-op-ds-all-full
version=4.6.28.3
IP=192.168.0.121
docker run -d --name designer-allinone \
-e DUBBO_IP_TO_REGISTRY=$IP \
-e DUBBO_PORT_TO_REGISTRY=20880 \
-p 8099:8091 \
-p 3307:3306 \
-p 2182:2181 \
-p 6378:6379 \
-p 19876:9876 \
-p 10991:10991 \
-p 15555:15555 \
-p 20880:20880 \
-p 88:80 \
-v $configDir/config/:/opt/pamirs/ext \
-v $configDir/nginx:/opt/pamirs/nginx/vhost \
-v $configDir/logs:/opt/pamirs/logs \
-v $configDir/mq/broker.conf:/opt/mq/conf/broker.conf \
-v $configDir/run/run.sh:/opt/pamirs/run/run.sh \
-v $configDir/lib:/opt/pamirs/outlib harbor.oinone.top/oinone/designer:$version-allinone-fullStep2.2.3 window环境修改参数
在文件中找到如下 set configDir=/d/shushi/docker/oinone-op-ds-all-full set version=4.6.28.3 set IP=192.168.0.121
-
修改configDir的路径((下载oinone-op-ds-xx.zip解压后的路径)
-
修改对应的镜像版本号
-
修改对应的IP为docker宿主机IP
@echo off
set configDir=/d/shushi/docker/oinone-op-ds-all-full
set version=4.6.28.3
set IP=192.168.0.121
docker run -d --name designer-allinone ^
-e DUBBO_IP_TO_REGISTRY=%IP% ^
-e DUBBO_PORT_TO_REGISTRY=20880 ^
-p 8099:8091 ^
-p 3307:3306 ^
-p 2182:2181 ^
-p 6378:6379 ^
-p 19876:9876 ^
-p 10991:10991 ^
-p 15555:15555 ^
-p 88:80 ^
-v %configDir%/config/:/opt/pamirs/ext ^
-v %configDir%/nginx:/opt/pamirs/nginx/vhost ^
-v %configDir%/logs:/opt/pamirs/logs ^
-v %configDir%/mq/broker.conf:/opt/mq/conf/broker.conf ^
-v %configDir%/run/run.sh:/opt/pamirs/run/run.sh ^
-v %configDir%/lib:/opt/pamirs/outlib harbor.oinone.top/oinone/designer:%version%-allinone-full3 不包含中间件的application.yml配置示例
修改结构包目录下config/application.yml
- 要把192.168.0.121换成非127.0.0.1的机器分配IP:通过ifconfig(mac)或ipconfig(windows)命令查询
- 数据库换成自己demo工程的数据库,demo6_v3 --> demo
dubbo:
#dubbo的配置
server:
address: 0.0.0.0
port: 8091
sessionTimeout: 3600
spring:
redis:
#redis的配置
logging:
#日志的配置
pamirs:
framework:
system:
system-ds-key: base
system-models: base.WorkerNode
data:
default-ds-key: pamirs
ds-map:
base: base
gateway:
statistics: true
show-doc: true
meta:
dynamic: false
persistence:
global:
auto-create-database: true
auto-create-table: true
datasource:
pamirs:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/demo?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
#............
asyncInit: true
#............
boot:
init: true
sync: true
modules:
- base
#-其他module
- demo_core
tenants:
- pamirs
auth:
#权限过滤配置
eip:
#eip配置我们前面中间件所绑定的IP都是127.0.0.1,因为我们这里使用了docker来访问,需要让中间件支持真正机器分配IP访问
Step3.1 检查mysql
- 确保yml文件中配置的用户可以通过机器IP来访问,例子中我们是用的是root用户,按以下步骤检查
mysql -u root -p
use mysql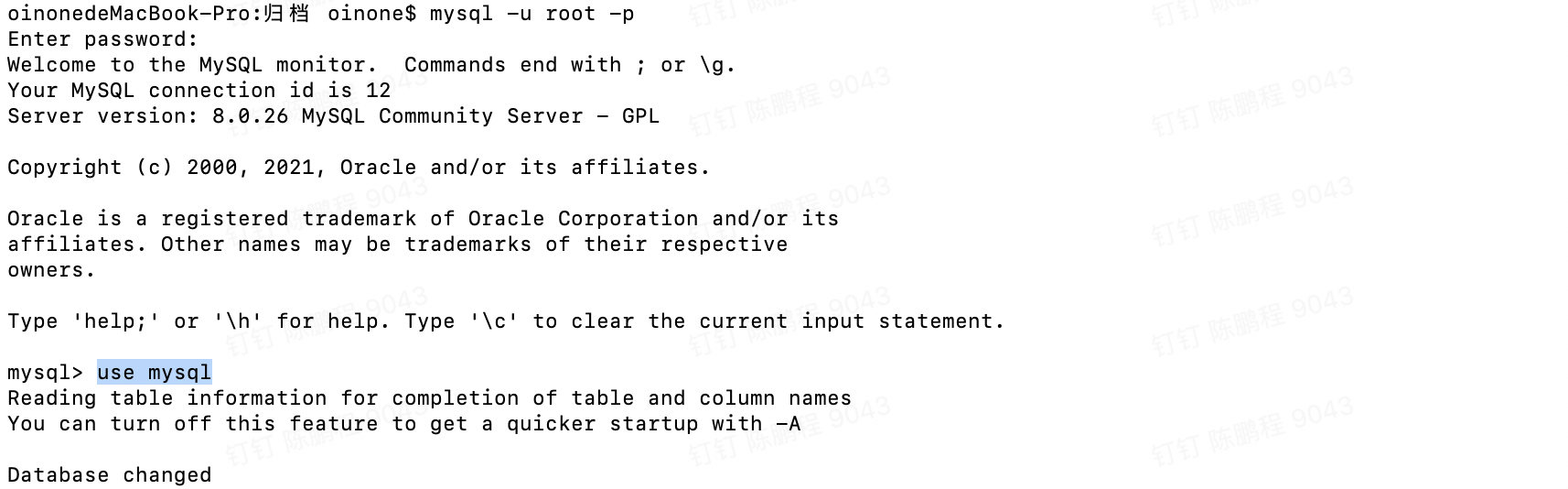
select User,authentication_string,Host from user;
update user set Host='%' where user='root';
flush privileges;Step3.2 检查redis
找到redis安装目录,编辑redis.conf,bind 从127.0.0.1改成0.0.0.0或对应本机IP,重启redis。

如果redis访问有问题,可以尝试在启动命令中增加 “--protected-mode no” 参数
nohup redis-server --protected-mode no & Step3.3 检查RocketMq
检查broker节点配置IP,如果有配置不能用127.0.0.1
Step3.4 检查Zookeeper
如果本地搭集群方式需要检查IP,如果有配置不能用127.0.0.1
4 包含中间件的application.yml以及其他配置示例
- 对应中间件的配置:指定对应IP和端口或密码,把其中192.168.0.121改为宿主机IP
- zookeeper
- mysql
- rocket-mq
- redis
- 阿里云oss配置
Step4.1 修改nginx/default.conf
如在docker和业务应用共同中间件实现低无一体时,如想在设计器中访问业务应用需要配置业务应用的nginx转发
location /pamirs/DemoCore {
# 对应额外工程部署的IP,端口为额外工程后端的端口
proxy_pass http://192.168.0.121:8190
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}修改以后可进容器重启nginx直接生效
进入docker容器
docker exec -it designer-allinone /bin/bash
docker镜像中重启nginx
/usr/local/nginx/sbin/nginx -s reloadStep4.2 修改mq/broker.conf
修改其中brokerIP1的IP从192.168.0.121改成宿主机IP
brokerClusterName = DefaultCluster
namesrvAddr=192.168.0.121:19876
brokerIP1=192.168.0.121
brokerName = broker-a
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
autoCreateTopicEnable=true
listenPort=10991
transactionCheckInterval=1000
#存储使用率阀值,当使用率超过阀值时,将拒绝发送消息请求
diskMaxUsedSpaceRatio=98
#磁盘空间警戒阈值,超过这个值则停止接受消息,默认值90
diskSpaceWarningLevelRatio=99
#强制删除文件阈值,默认85
diskSpaceCleanForciblyRatio=975. 启动Docker
Step5.1 linux环境启动
- 在终端执行 sh startup.sh
Step5.2 window环境启动
- 用PowerShell 执行 .\startup.cmd
Step5.3 查看日志,检查是否启动成功
在logs目录下可看到生成的日志文件,第一次启动时间会相对长一些,等看到日志文件中输出 启动耗时 。。。等字样,代表启动成功
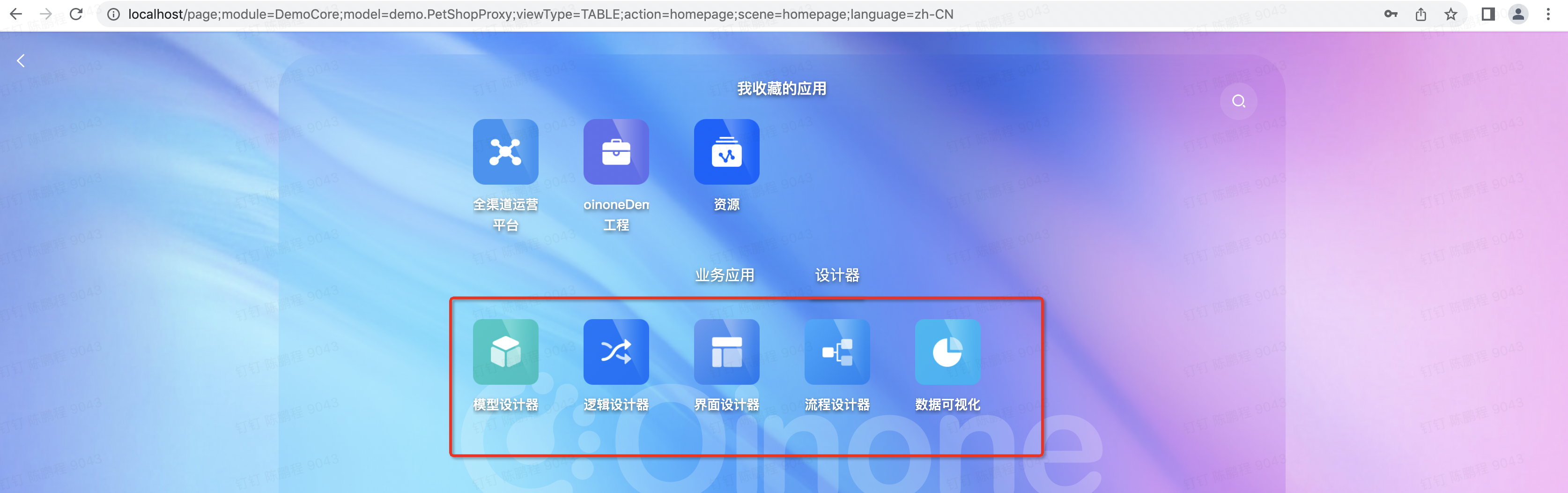
6 体验并设计页面
输入http://localhost/访问,通过App Finder 切换时多了设计器一项
7 导出数据,并固化数据到产品中
Step7.1通过接口导出数据
Step7.2 导入数据到项目中
- pom依赖:
pro.shushi.pamirs.metadata.manager
pamirs-metadata-manager
- 将第二步下载后的文件放入项目中(注意文件放置的位置)。放置工程的resources下面。例如:

3、 项目启动过程中,将文件中的数据导入(通常放在core模型的init包下面)。示例代码:
package pro.shushi.pamirs.sys.setting.enmu;
import com.google.common.collect.Lists;
import org.apache.commons.collections4.CollectionUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.boot.common.api.command.AppLifecycleCommand;
import pro.shushi.pamirs.boot.common.api.init.LifecycleCompletedAllInit;
import pro.shushi.pamirs.boot.common.extend.MetaDataEditor;
import pro.shushi.pamirs.core.common.InitializationUtil;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import pro.shushi.pamirs.meta.api.dto.meta.Meta;
import pro.shushi.pamirs.meta.domain.module.ModuleDefinition;
import pro.shushi.pamirs.metadata.manager.core.helper.DesignerInstallHelper;
import pro.shushi.pamirs.metadata.manager.core.helper.WidgetInstallHelper;
import java.util.List;
import java.util.Map;
@Slf4j
@Component
public class DemoAppMetaInstall implements MetaDataEditor, LifecycleCompletedAllInit {
@Autowired
private ApplicationContext applicationContext;
@Override
public void edit(AppLifecycleCommand command, Map metaMap) {
if (!doImport()) {
return;
}
log.info("[设计器业务元数据导入]");
InitializationUtil bizInitializationUtil = InitializationUtil.get(metaMap, DemoModule.MODULE_MODULE/***改成自己的Module*/, DemoModule.MODULE_NAME/***改成自己的Module*/);
DesignerInstallHelper.mateInitialization(bizInitializationUtil, "install/meta.json");
log.info("[自定义组件元数据导入]");
// 写法1: 将组件元数据导入到页面设计器. 只有在安装设计器的服务中执行才有效果
WidgetInstallHelper.mateInitialization(metaMap, "install/widget.json");
// 写法2: 与写法1相同效果
InitializationUtil uiInitializationUtil = InitializationUtil.get(metaMap, "ui_designer", "uiDesigner");
if (uiInitializationUtil != null) {
DesignerInstallHelper.mateInitialization(uiInitializationUtil, "install/widget.json");
}
// 写法3: 业务工程和设计器分布式部署,且希望通过业务工程导入自定义组件元数据. 业务模块需要依赖页面设计器模块,然后指定业务模块导入
DesignerInstallHelper.mateInitialization(bizInitializationUtil, "install/widget.json");
}
@Override
public void process(AppLifecycleCommand command, Map runModuleMap) {
if (!doImport()) {
return;
}
log.info("[设计器业务数据导入]");
// 支持远程调用,但是执行的生命周期必须是LifecycleCompletedAllInit或之后. 本地如果安装了设计器,则没有要求
DesignerInstallHelper.bizInitialization("install/meta.json");
log.info("[自定义组件业务数据导入]");
// 当开发环境和导入环境的文件服务不互通时, 可通过指定js和css的文件压缩包,自动上传到导入环境,并替换导入组件数据中的文件url
// WidgetInstallHelper.bizInitialization("install/widget.json", "install/widget.zip");
WidgetInstallHelper.bizInitialization("install/widget.json");
return;
}
private boolean doImport() {
// 自定义导入判断. 避免用于设计的开发环境执行导入逻辑
String[] envs = applicationContext.getEnvironment().getActiveProfiles();
List envList = Lists.newArrayList(envs);
return CollectionUtils.isNotEmpty(envList) && (envList.contains("prod"));
}
} 常见异常问题
启动失败现象
启动设计器的Docker容器,lib包中增加自定义的Jar启动报错,错误信息为:
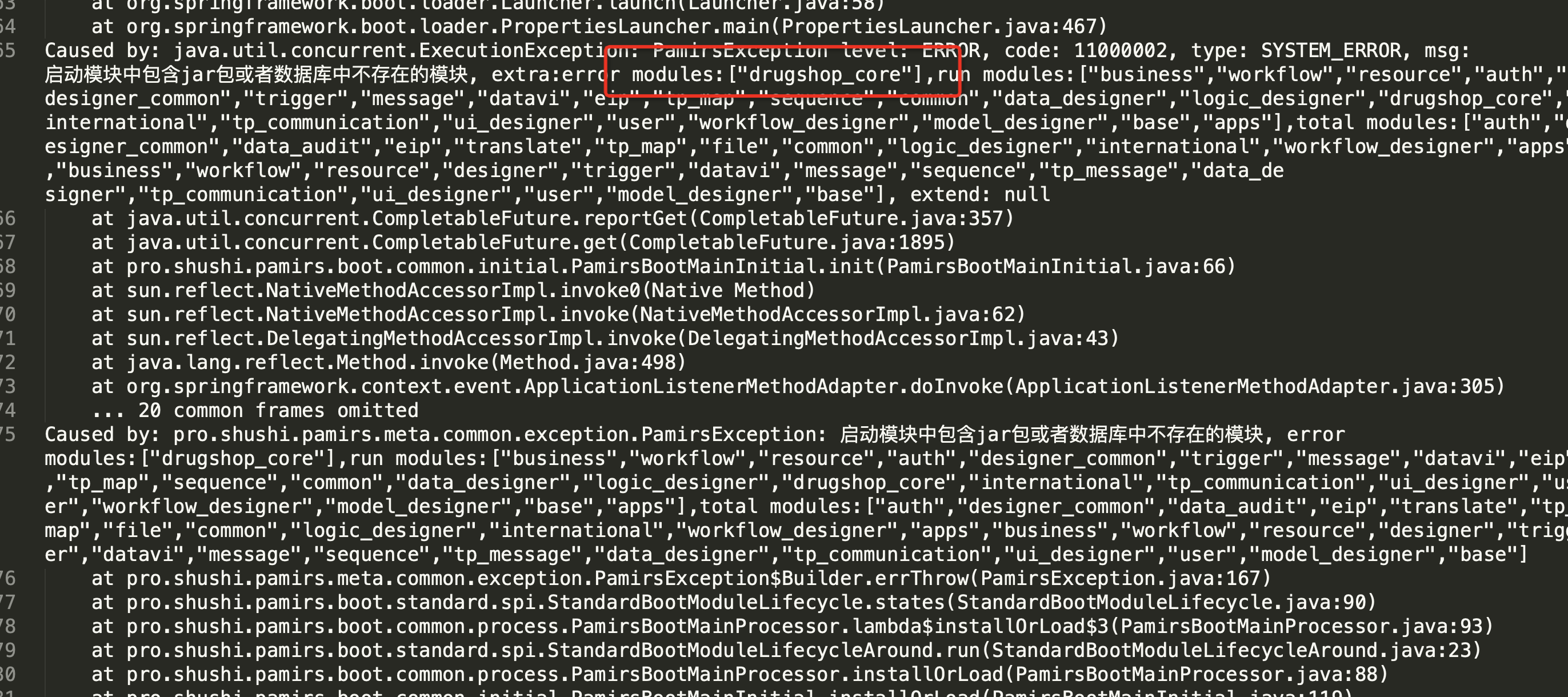
问题原因
自定义Jar的包路径不是系统默认扫描路径。 目前系统默认的包扫描路径是:pro.shushi.pamirs 和 pro.shushi.oinone。 自定义扫描路径Spring加载不到
问题解决方法
资料参考:https://itcn.blog/p/214153911.html
- 业务工程API模块 新建一个ScanConfig, resources目录下创建META-INF目录,然后创建spring.factories文件。上述两个文件目录参考如下:
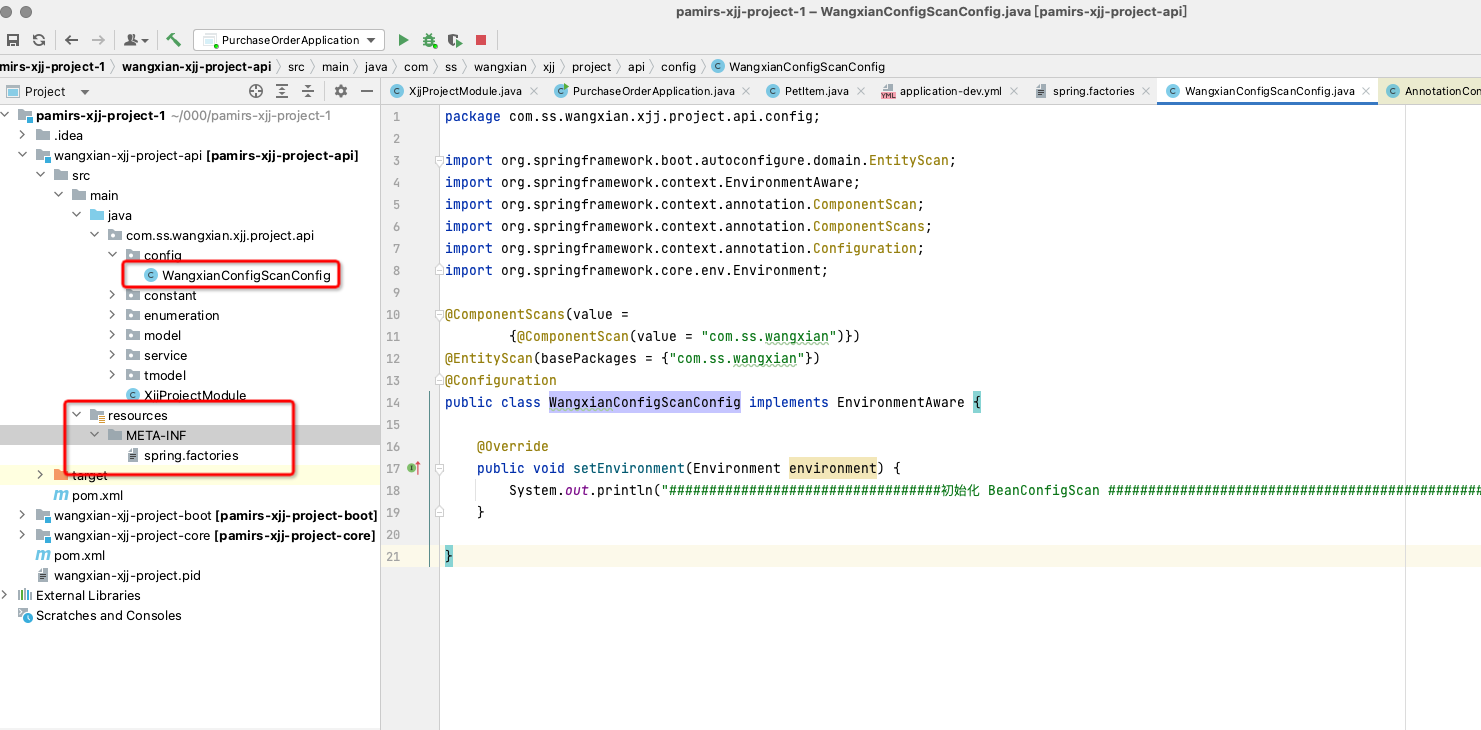
- 文件内容参考
2.1. WangxianConfigScanConfig,根据自己的实际情况修改 命名类和包扫描路径
package com.ss.wangxian.xjj.project.api.config;
import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.context.EnvironmentAware;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.ComponentScans;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
@ComponentScans(value =
{@ComponentScan(value = com.ss.wangxian)})
@EntityScan(basePackages = {com.ss.wangxian})
@Configuration
public class WangxianConfigScanConfig implements EnvironmentAware {
@Override
public void setEnvironment(Environment environment) {
System.out.println(#####初始化 BeanConfigScan #############);
}
}2.2. spring.factories,根据实际情况修改类名和路径
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.ss.wangxian.xjj.project.api.config.WangxianConfigScanConfig- API工程重新打包,然后放入到docker文档中指定的lib包下,重新启动容器。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9257.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验