
一、三户概念
三户由来
介绍下经典的三户模型,它是电信运营支持系统的基础。三户模型即客户、用户和帐户,来源于etom的模型。这三者之间的关系应该是一个相互关联但又是独立的三个实体,这种关联只是一个归属和映射的关系,而三个实体本身是相互独立的,分别是体现完全不同的几个域的信息,客户是体现了社会域的信息,用户体现了业务域的信息,帐户体现的是资金域的信息。
-
客户:它是个社会化的概念,一个自然人或一个法人
-
用户:它是客户使用运营商开发的一个产品以及基于该产品之上的增值业务时,产生的一个实体。如果说一个客户使用了多个产品,那么一个客户就会对应好几个用户(即产品)
-
账户:它的概念起源于金融业,只是一个客户在运营商存放资金的实体,目的是为选择的产品付费
Oinone的三户
在原三户模型中【用户】是购买关系产生的产品与客户关系的服务实例,在互联网发展中用户的概念发生了非常大的变化,【用户】概念变成了:使用者,是指使用电脑或网络服务的人,通常拥有一个用户账号,并以用户名识别。而且新概念在互联网强调用户数的大背景下已经被普遍介绍,再去强调电信行业的用户概念就会吃力不讨好。而且不管是企业应用领域和互联网领域,原用户概念都显得过于复杂和没有必要。也就有了特色的oinone的三户模型:
-
客户:它是个社会化的概念,一个自然人或一个法人
-
用户:使用者,是指使用电脑或网络服务的人,通常拥有一个用户账号,并以用户名识别
-
账户:它的概念起源于金融业,只是一个客户在运营商存放资金的实体,目的是为选择的产品付费
二、Oinone的客户与用户
三户模型是构建上层应用的基础支撑能力,任何业务行为都跟这里两个实体脱不了干系。以客户为中心建立商业关系与商业行为主体,以用户为中心构建一致体验与操作行为主体。在底层设计上二者相互独立并无关联,由上层应用自行作关联绑定,往往在登陆时在Session的处理逻辑中会根据【用户】去找到对应一个或多个【商业(主体)客户】,Session的实现可以参考4.1.20【框架之Session】一文。
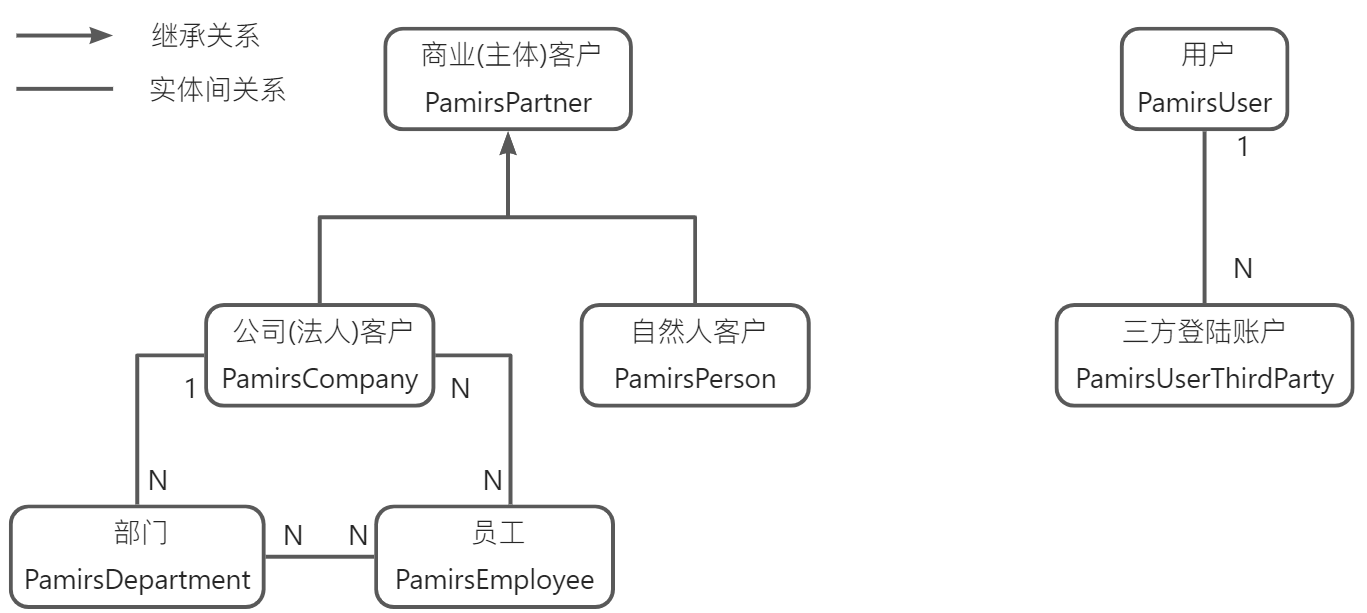

客户设计说明
-
PamirsPartner作为商业关系与商业行为的主体,派生了两个子类PamirsCompany与PamirsPerson分别对应:公司(法人)客户、自然人客户
-
公司(法人)客户PamirsCompany对应多个组织部门PamirsDepartment,公司(法人)客户PamirsCompany对应多个员工PamirsEmployee
-
部门PamirsDepartment对应一个公司(法人)客户PamirsCompany,对应多个员工PamirsEmployee
-
员工PamirsEmployee对应多个部门PamirsDepartment,对应一个或多个公司(法人)客户PamirsCompany,其中有一个主的
用户设计说明
- PamirsUser作为一致体验与操作行为主体,本身绑定登陆账号,并且可以关联多个三方登陆账户PamirsUserThirdParty
客户与用户如何关联(举例)
例子设计:
-
新建demo系统的PetComany和PetEmployee,用PetEmployee去关联用户。
-
当用户登陆时,根据用户Id找到PetEmployee,在根据PetEmployee找到PetComany,把PetComany放到Session中去
-
修改PetShop模型关联一个PamirsPartner,PamirsPartner的信息从Session取。
Step1 pamirs-demo-api工程增加依赖,并且DemoModule增加对BusinessModule的依赖
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-business-api</artifactId>
</dependency>在DemoModule类中通过@Module.dependencies中增加BusinessModule.MODULE_MODULE
@Module(
dependencies = { BusinessModule.MODULE_MODULE}
)Step2 新建PetComany和PetEmployee,以及对应的服务
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.business.api.model.PamirsEmployee;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.user.api.model.PamirsUser;
@Model.model(PetEmployee.MODEL_MODEL)
@Model(displayName = "宠物公司员工",labelFields = "name")
public class PetEmployee extends PamirsEmployee {
public static final String MODEL_MODEL="demo.PetEmployee";
@Field(displayName = "用户")
private PamirsUser user;
}
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.business.api.entity.PamirsCompany;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
@Model.model(PetCompany.MODEL_MODEL)
@Model(displayName = "宠物公司",labelFields = "name")
public class PetCompany extends PamirsCompany {
public static final String MODEL_MODEL="demo.PetCompany";
@Field.Text
@Field(displayName = "简介")
private String introductoin;
}package pro.shushi.pamirs.demo.api.service;
import pro.shushi.pamirs.demo.api.model.PetEmployee;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
@Fun(PetEmployeeQueryService.FUN_NAMESPACE)
public interface PetEmployeeQueryService {
String FUN_NAMESPACE ="demo.PetEmployeeQueryService";
@Function
PetEmployee queryByUserId(Long userId);
}package pro.shushi.pamirs.demo.core.service;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetEmployee;
import pro.shushi.pamirs.demo.api.service.PetEmployeeQueryService;
import pro.shushi.pamirs.framework.connectors.data.sql.query.QueryWrapper;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
@Fun(PetEmployeeQueryService.FUN_NAMESPACE)
@Component
public class PetEmployeeQueryServiceImpl implements PetEmployeeQueryService {
@Override
@Function
public PetEmployee queryByUserId(Long userId) {
if(userId==null){
return null;
}
QueryWrapper<PetEmployee> queryWrapper = new QueryWrapper<PetEmployee>().from(PetEmployee.MODEL_MODEL).eq("user_id", userId);
return new PetEmployee().queryOneByWrapper(queryWrapper);
}
}package pro.shushi.pamirs.demo.api.service;
import pro.shushi.pamirs.demo.api.model.PetCompany;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
@Fun(PetCompanyQueryService.FUN_NAMESPACE)
public interface PetCompanyQueryService {
String FUN_NAMESPACE ="demo.PetCompanyQueryService";
@Function
PetCompany queryByCode(String code);
}package pro.shushi.pamirs.demo.core.service;
import org.apache.dubbo.common.utils.StringUtils;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetCompany;
import pro.shushi.pamirs.demo.api.service.PetCompanyQueryService;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
@Fun(PetCompanyQueryService.FUN_NAMESPACE)
@Component
public class PetCompanyQueryServiceImpl implements PetCompanyQueryService {
@Override
@Function
public PetCompany queryByCode(String code) {
if(StringUtils.isBlank(code)){
return null;
}
return new PetCompany().queryByCode(code);
}
}
Step3 Session中增加PamirsPartner
对DemoSession\DemoSessionApi\DemoSessionData\DemoSessionHolder进行修改,增加PetCompany getCompany()相关方法。可以参考4.1.20【框架之Session】一文。
对DemoSessionCache修改如下,增加根据userId获取employee,以及根据employee获取PetCompany
package pro.shushi.pamirs.demo.core.session;
import pro.shushi.pamirs.demo.api.model.PetCompany;
import pro.shushi.pamirs.demo.api.model.PetEmployee;
import pro.shushi.pamirs.demo.api.service.PetCompanyQueryService;
import pro.shushi.pamirs.demo.api.service.PetEmployeeQueryService;
import pro.shushi.pamirs.meta.api.CommonApiFactory;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.user.api.model.PamirsUser;
import pro.shushi.pamirs.user.api.service.UserService;
public class DemoSessionCache {
private static final ThreadLocal<DemoSessionData> BIZ_DATA_THREAD_LOCAL = new ThreadLocal<>();
public static PamirsUser getUser(){
return BIZ_DATA_THREAD_LOCAL.get()==null?null:BIZ_DATA_THREAD_LOCAL.get().getUser();
}
public static PetCompany getCompany(){
return BIZ_DATA_THREAD_LOCAL.get()==null?null:BIZ_DATA_THREAD_LOCAL.get().getCompany();
}
public static void init(){
if(getUser()!=null){
return ;
}
Long uid = PamirsSession.getUserId();
if(uid == null){
return;
}
PamirsUser user = CommonApiFactory.getApi(UserService.class).queryById(uid);
if(user!=null){
DemoSessionData demoSessionData = new DemoSessionData();
demoSessionData.setUser(user);
PetEmployee employee = CommonApiFactory.getApi(PetEmployeeQueryService.class).queryByUserId(uid);
if(employee!=null){
PetCompany company = CommonApiFactory.getApi(PetCompanyQueryService.class).queryByCode(employee.getCompanyCode());
demoSessionData.setCompany(company);
}
BIZ_DATA_THREAD_LOCAL.set(demoSessionData);
}
}
public static void clear(){
BIZ_DATA_THREAD_LOCAL.remove();
}
}Step4 修改PetShop模型,以及重写PetShop的默认create方法
PetShop模型增加partner字段,修改openTime为readonly=true的配置,变成带条件readonly。scene == \'redirectUpdatePage\'表示只有再修改的时候为只读
@Field(displayName = "所属主体" )
@UxForm.FieldWidget(@UxWidget(readonly = "scene == 'redirectUpdatePage'"/* 在编辑页面只读 **/ ))
private PamirsPartner partner;
创建PetShopAction类重写PetShop模型的create方法
package pro.shushi.pamirs.demo.core.action;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetCompany;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.demo.core.session.DemoSession;
import pro.shushi.pamirs.meta.annotation.Action;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.constant.FunctionConstants;
import pro.shushi.pamirs.meta.enmu.ViewTypeEnum;
@Component
@Model.model(PetShop.MODEL_MODEL)
public class PetShopAction {
@Action.Advanced(name= FunctionConstants.create,managed = true)
@Action(displayName = "确定",summary = "确定",bindingType = ViewTypeEnum.FORM)
@Function(name=FunctionConstants.create)
@Function.fun(FunctionConstants.create)
public PetShop create(PetShop data){
//从session中获取登陆主体信息
PetCompany company = DemoSession.getCompany();
if(company!=null){
data.setPartner(company);
}
data.create();
return data;
}
}
Step5 增加PetEmployee和PetCompany的管理入口
DemoMenus增加@UxMenu注解申明
@UxMenu("公司管理")@UxRoute(PetCompany.MODEL_MODEL) class PetCompanyMenu{}
@UxMenu("员工管理")@UxRoute(PetEmployee.MODEL_MODEL) class PetEmployeeMenu{}Step6 重启应用看效果
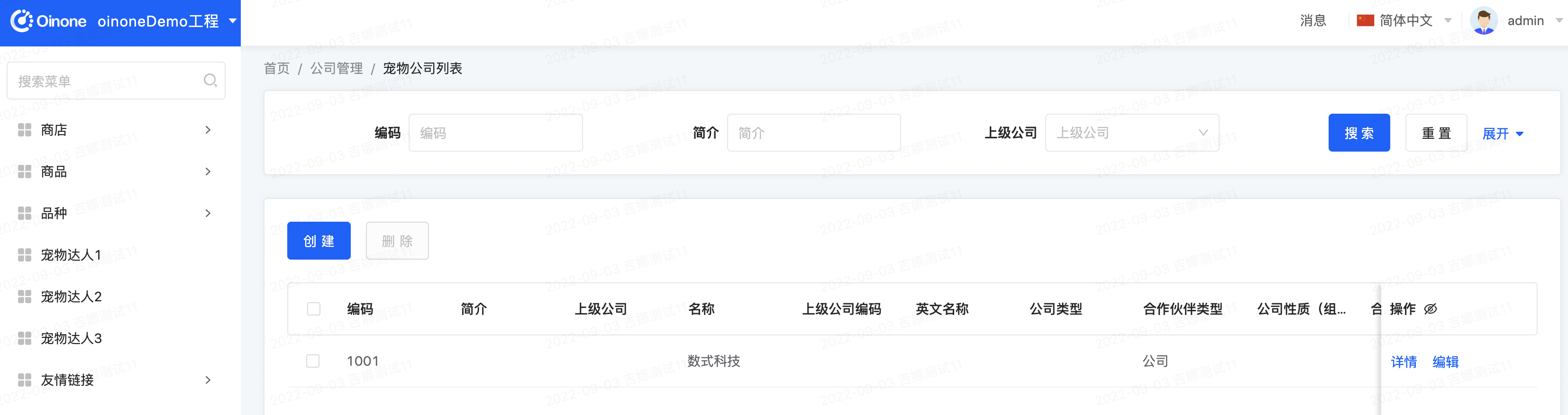
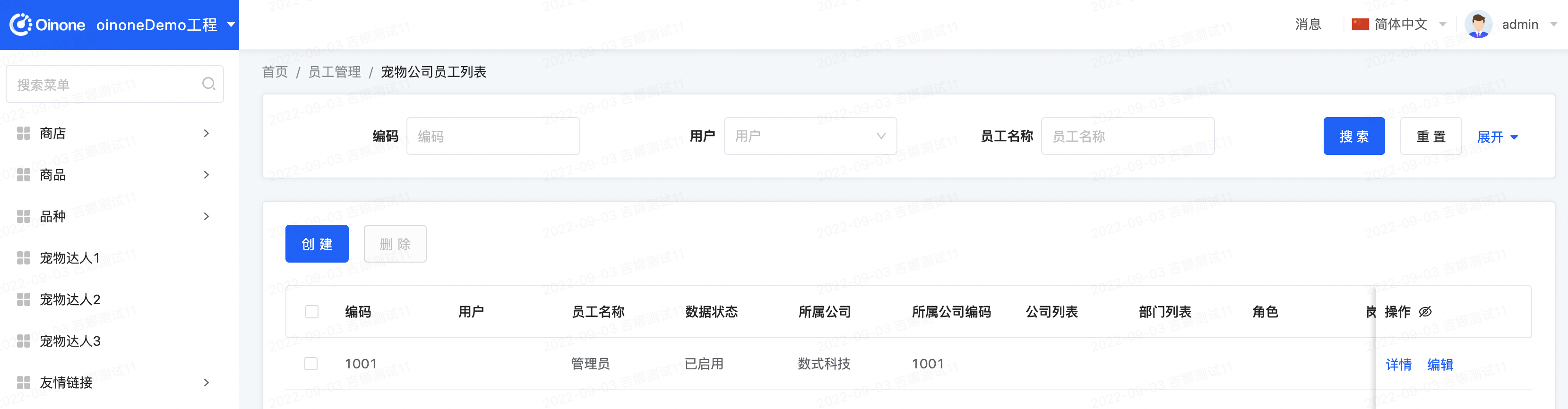
- 创建公司与员工,在创建的同时建立公司与员工,员工与用户关联
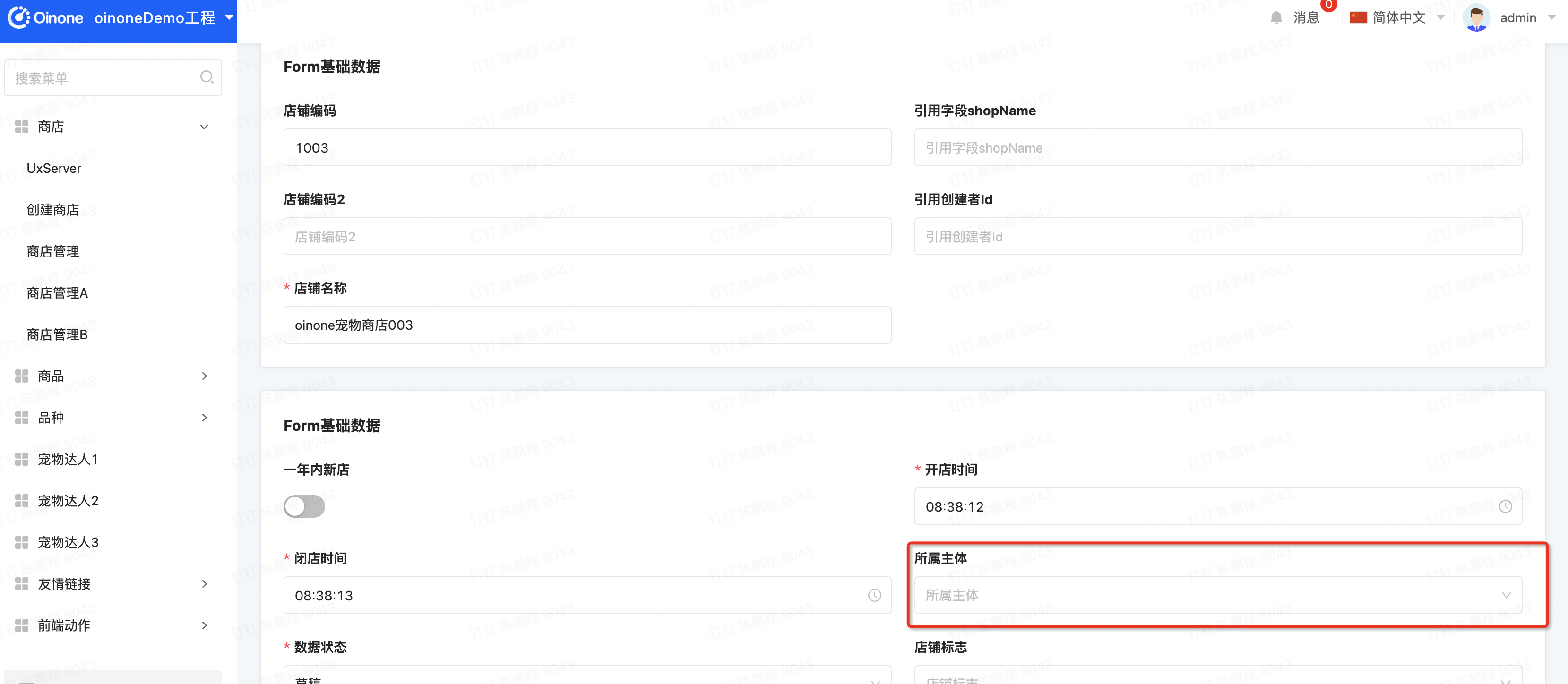
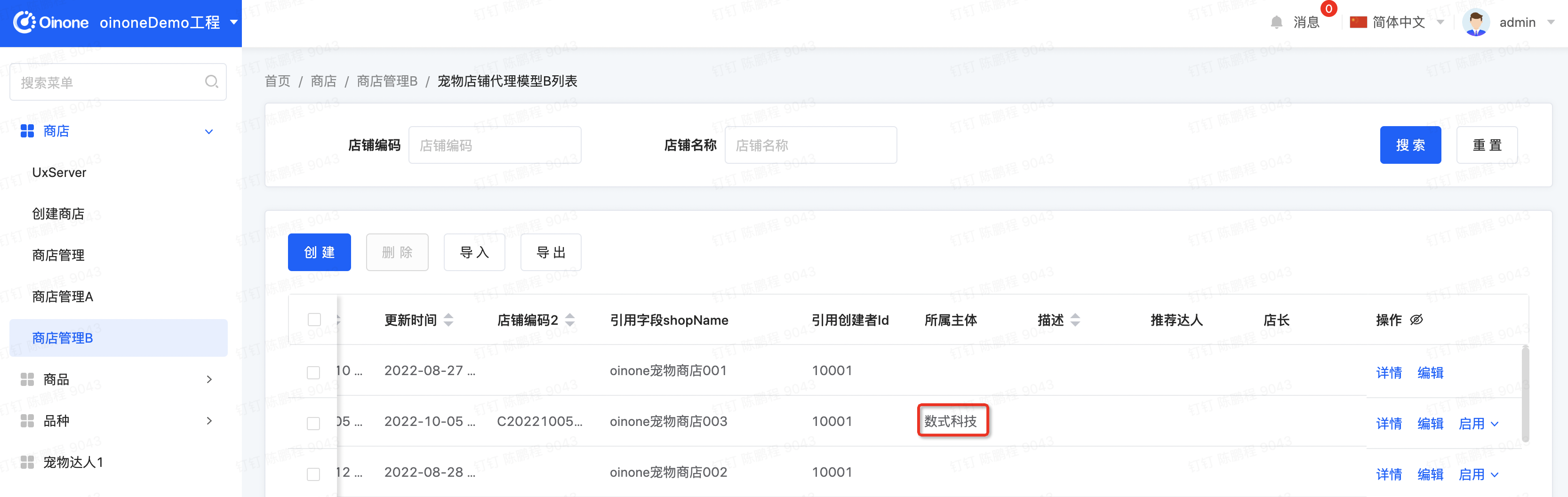
- 创建一个宠物店铺
新增oinone的宠物店铺003,但不要选择所属主体。点击确定按钮后期望效果是:会从session中自动获取admin关联的PetCompany,并填充到宠物店铺的所属主体字段中
Step7 注意事项
-
PetEmployee 的create方法应该重写,再调用PamirsEmployeeService 的create方法
-
PetEmployeeQueryServiceImpl的queryByUserId方法实现上也没有考虑一个用户绑定多个员工的模式。
-
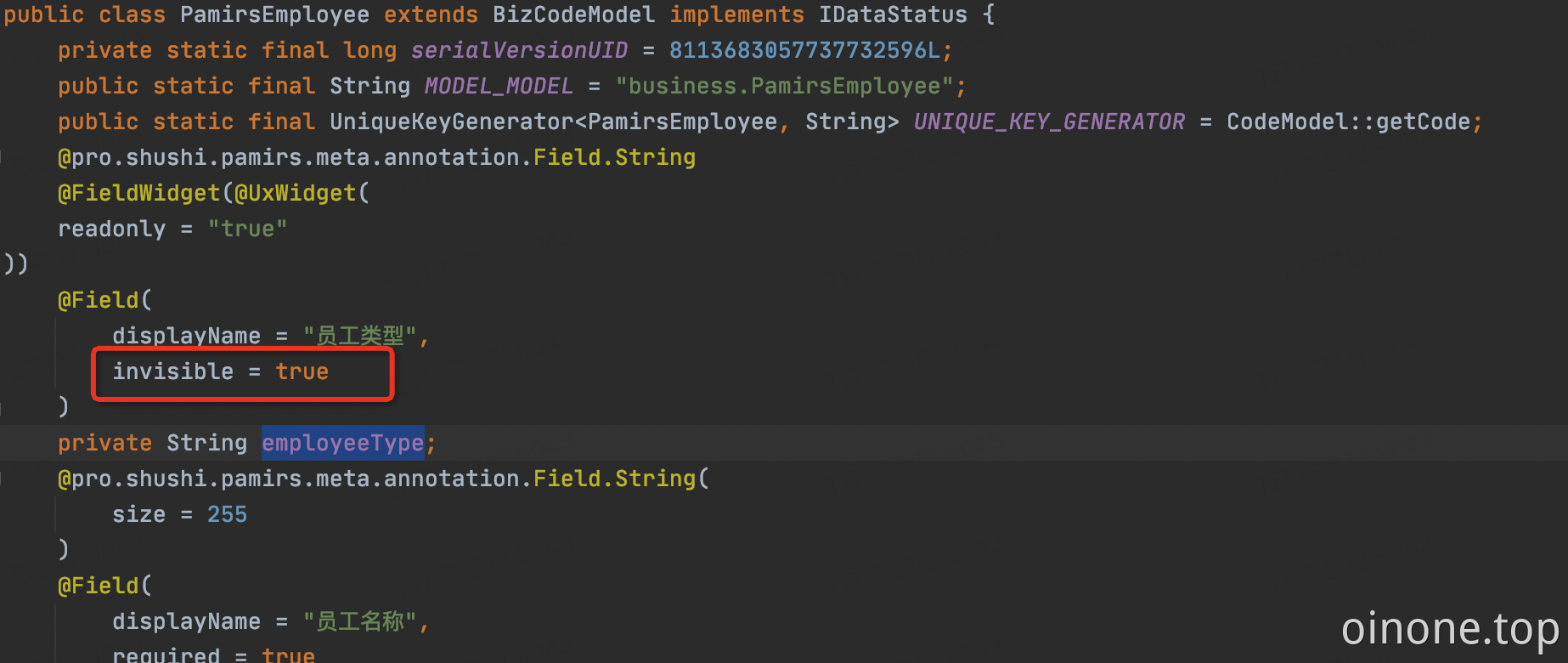
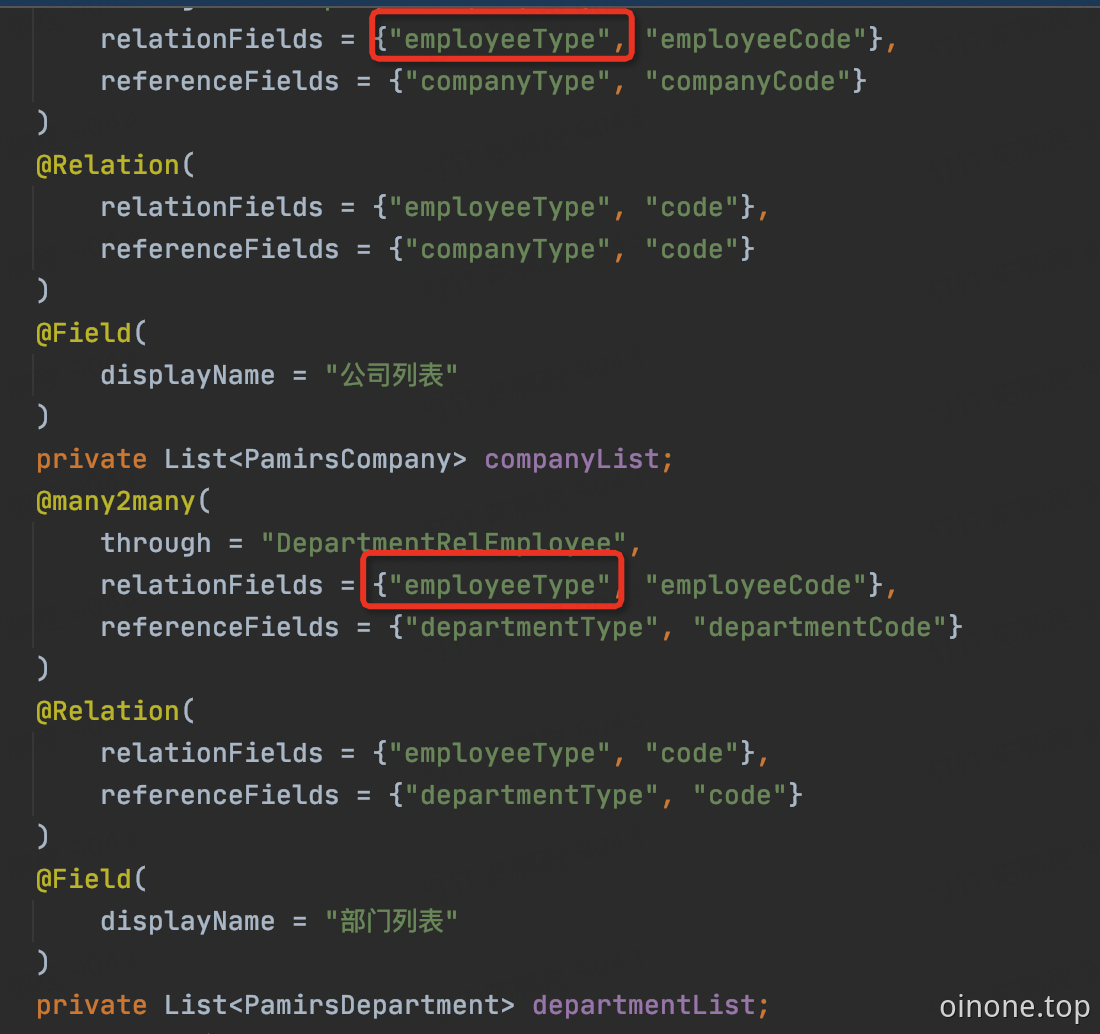
employeeType 字段默认是不展示的,但是例子中又没有重写PetEmployee 的create方法,所以这个值是空的。但这个字段为空,会导致报错。解决办法有两个
-
重写create,手动给employeeType赋值
-
自定义员工创建页面,拿到公司列表和部门列表两个字段。
-
 |
 |
三、客户扩展申明
按CDM的设计理念,我们不以把模型抽象到极致支撑所有业务可能性为目标,而是抽象80%通用的设计,保持模型简单可理解。我们只提供了基础模型统一数据存储,以用面向对象特性来解决多应用模型复用和数据割裂问题。
Oinone CDM是商业领域的通用模型,更是结合oinone特性提出的新工程建议
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9318.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验