
1. 模型介绍
Oinone低代码设计器是采用模型驱动的方式来设计应用,数据、数据都在模型,在模型设计器的模型管理模块,通过可视化配置的方式为用户提供快速设计模型的功能。
模型是对应用中所需要描述的实体进行必要的简化,并用适当的变现形式或规则把它的主要特征描述出来所得到的系统模仿品。模型由元信息、字段、数据管理器和自定义函数构成。
2. 操作模式
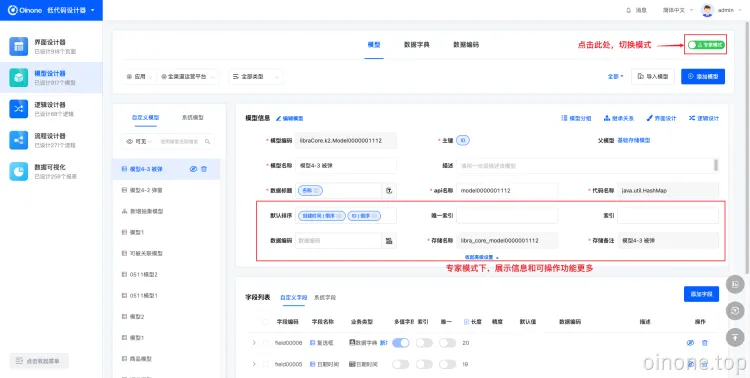
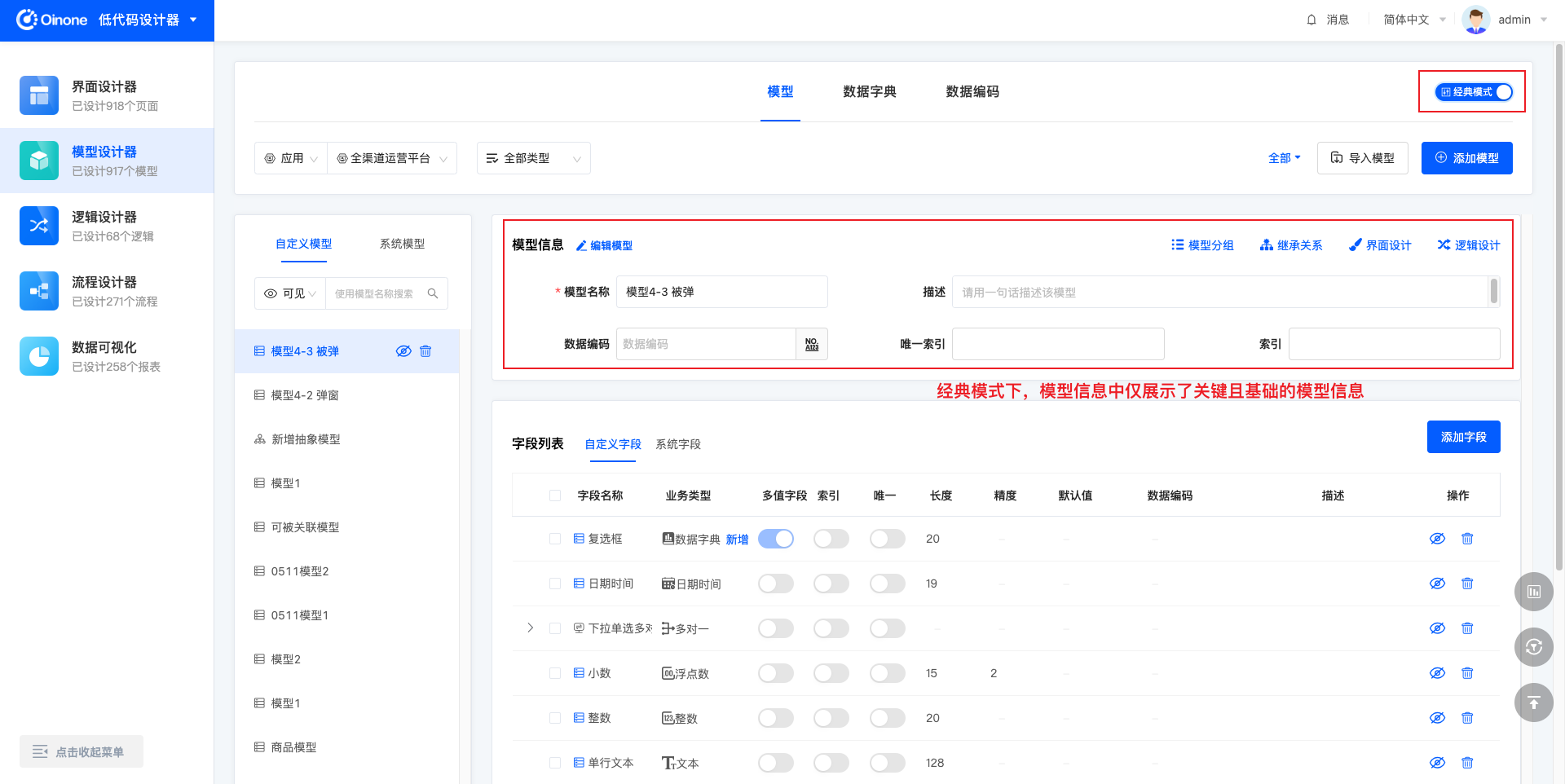
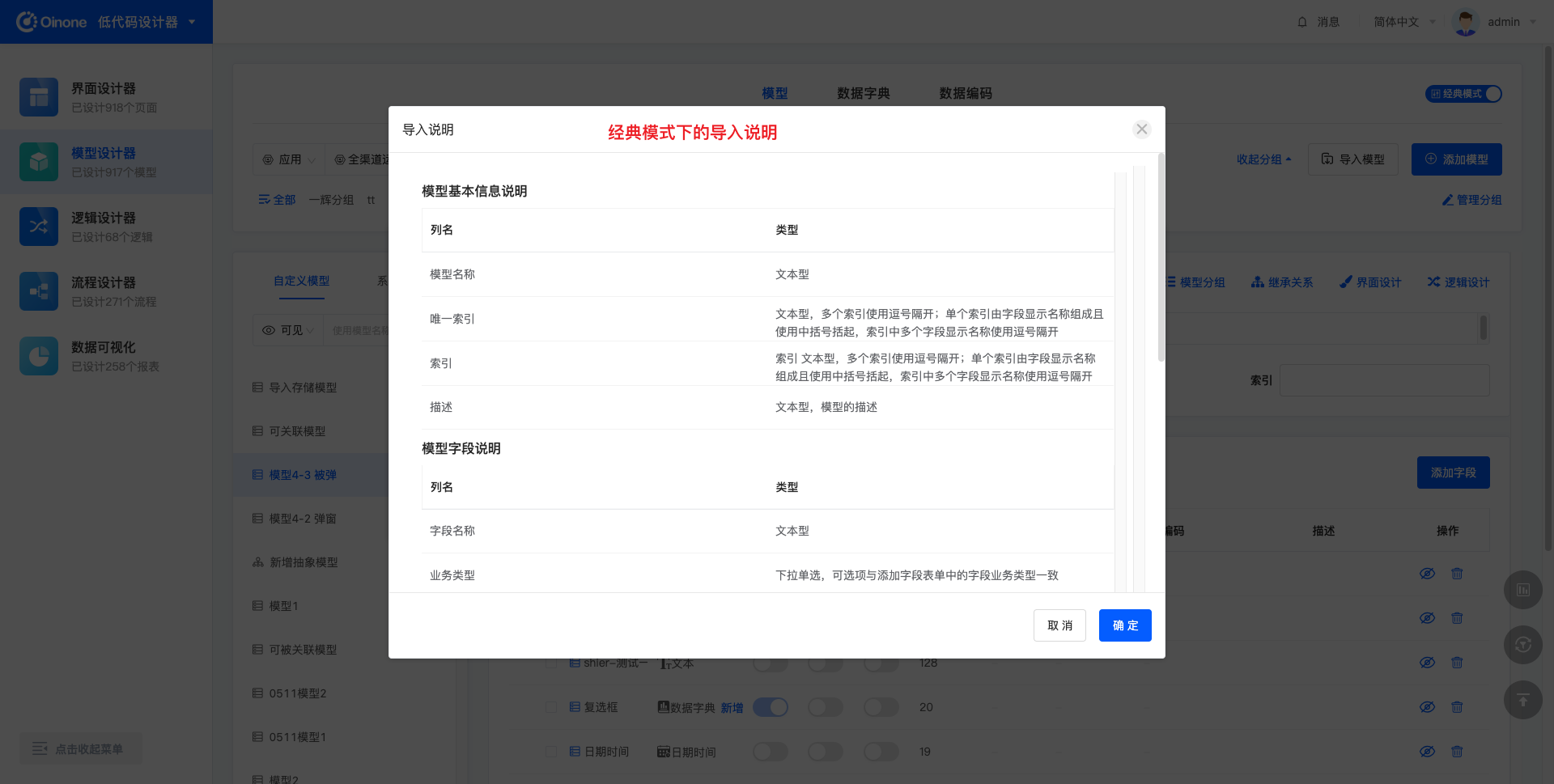
为了满足有无研发背景知识的不同用户使用需求,在模型设计器中,支持切换操作模式,包含专家模式和经典模式。经典模式功能基础且完善,操作交互简单易理解,适用于非研发用户;专家模式下模型的设计能力更高,有经典模式下的所有功能,相比于经典模式,功能更多,适用于一般有研发知识基础的用户。
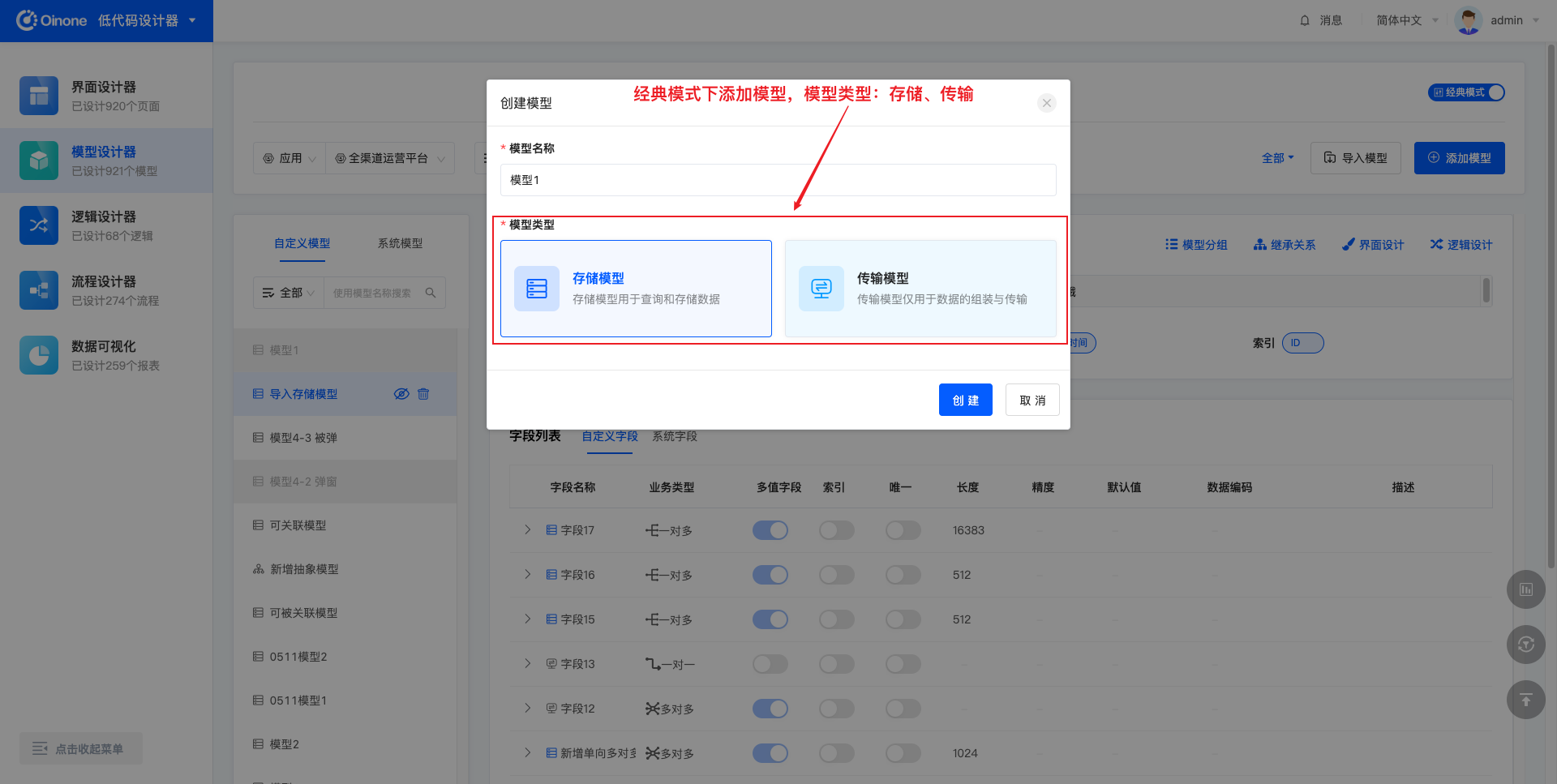
比如在添加模型时,经典模式下可以创建的模型类型有:存储模型、传输模型,专家模式下,在此基础上还可以创建抽象模型和代理模型。

3. 分组管理
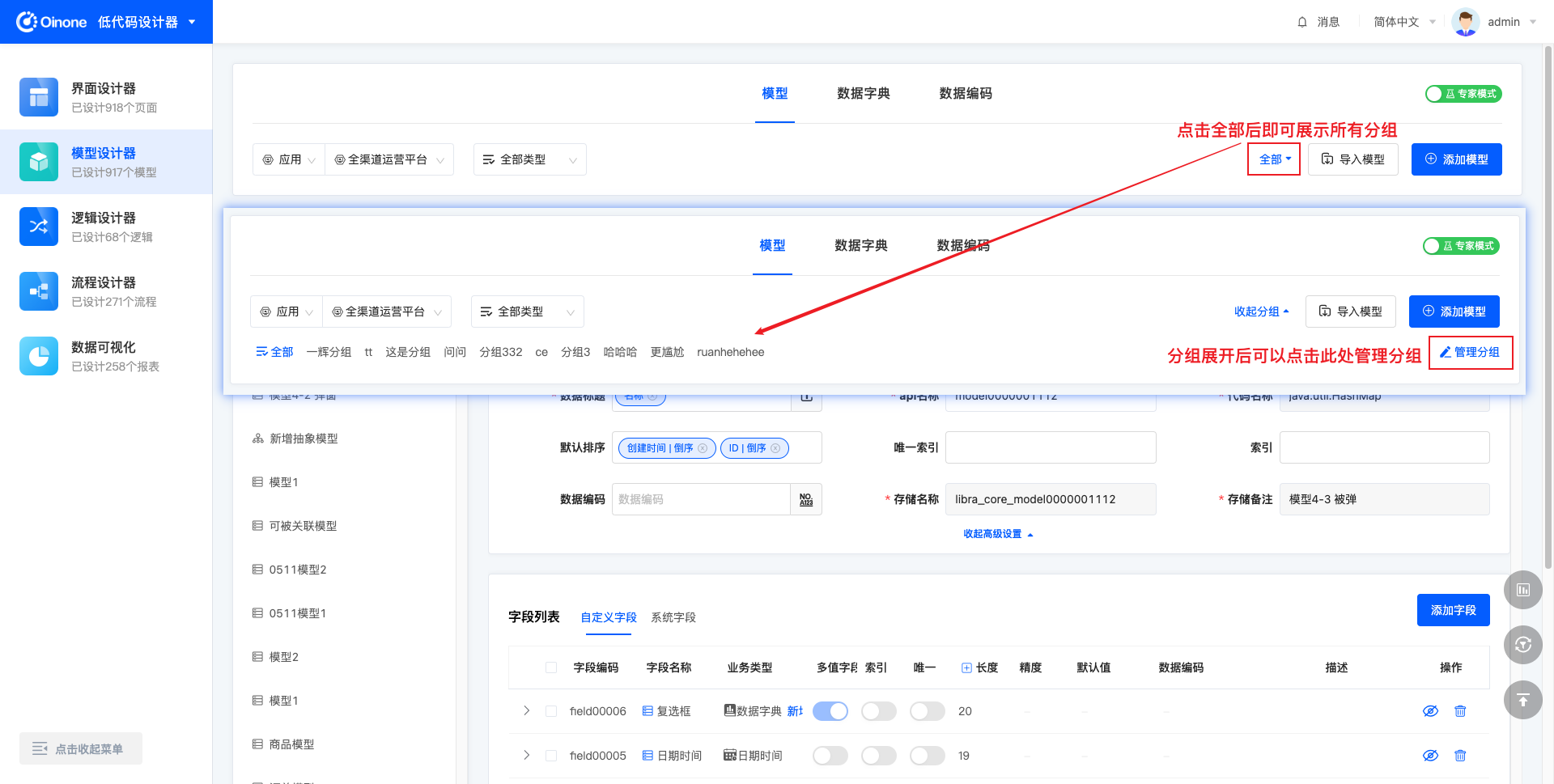
当模型过多时,可以自定义添加15个分组,将模型进行归类管理。点击「全部」展开所有分组,展开后,分组右侧可以管理分组。
3.1 管理分组
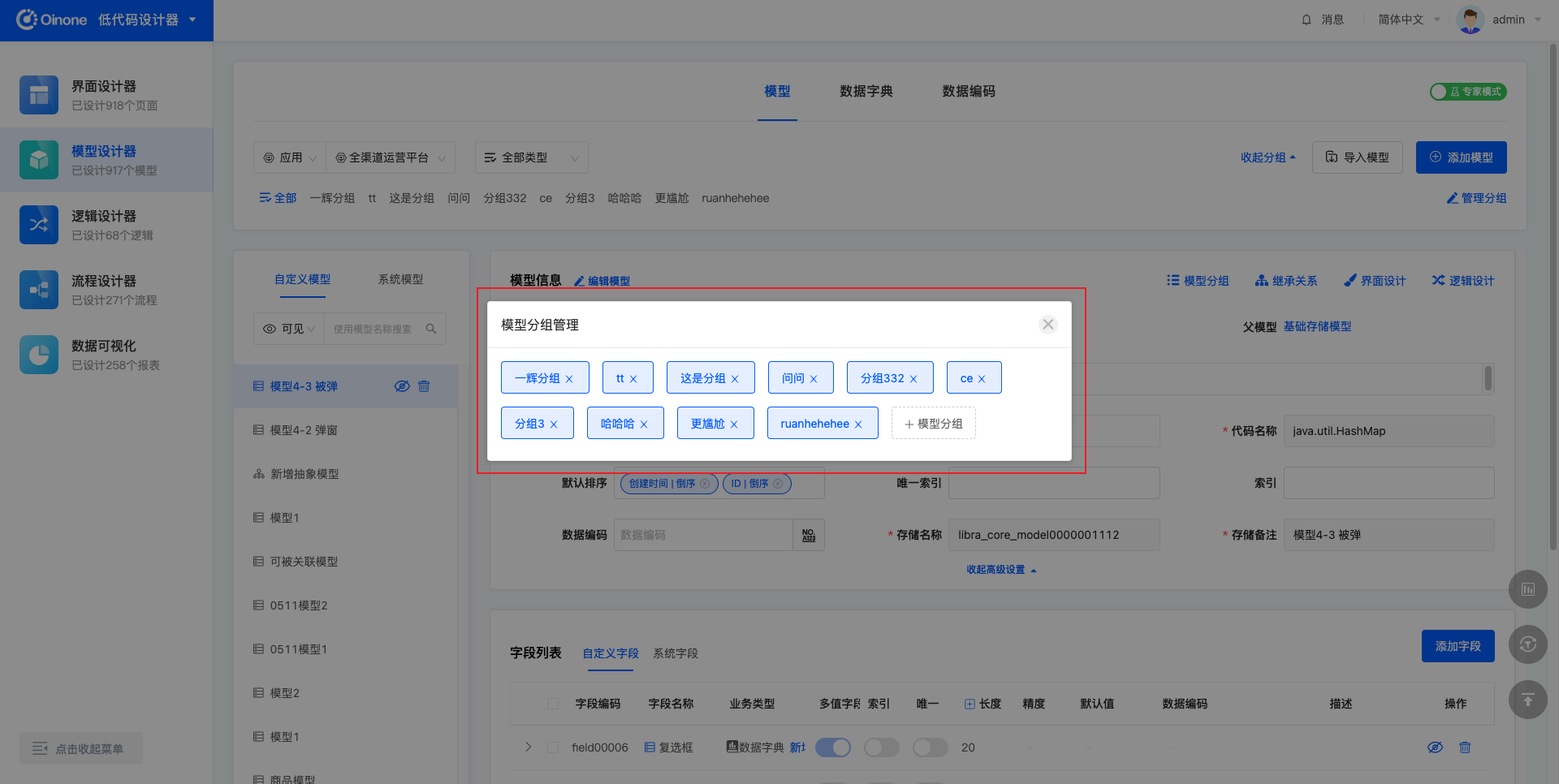
展开分组后,点击「管理分组」,出现弹窗,在弹窗中可以修改分组名称、添加分组、删除分组。
3.2 添加分组
操作「+模型分组」,可以直接输入分组名称后回车以添加一个新分组,或快捷选择其他应用使用的分组。最多添加15个分组。
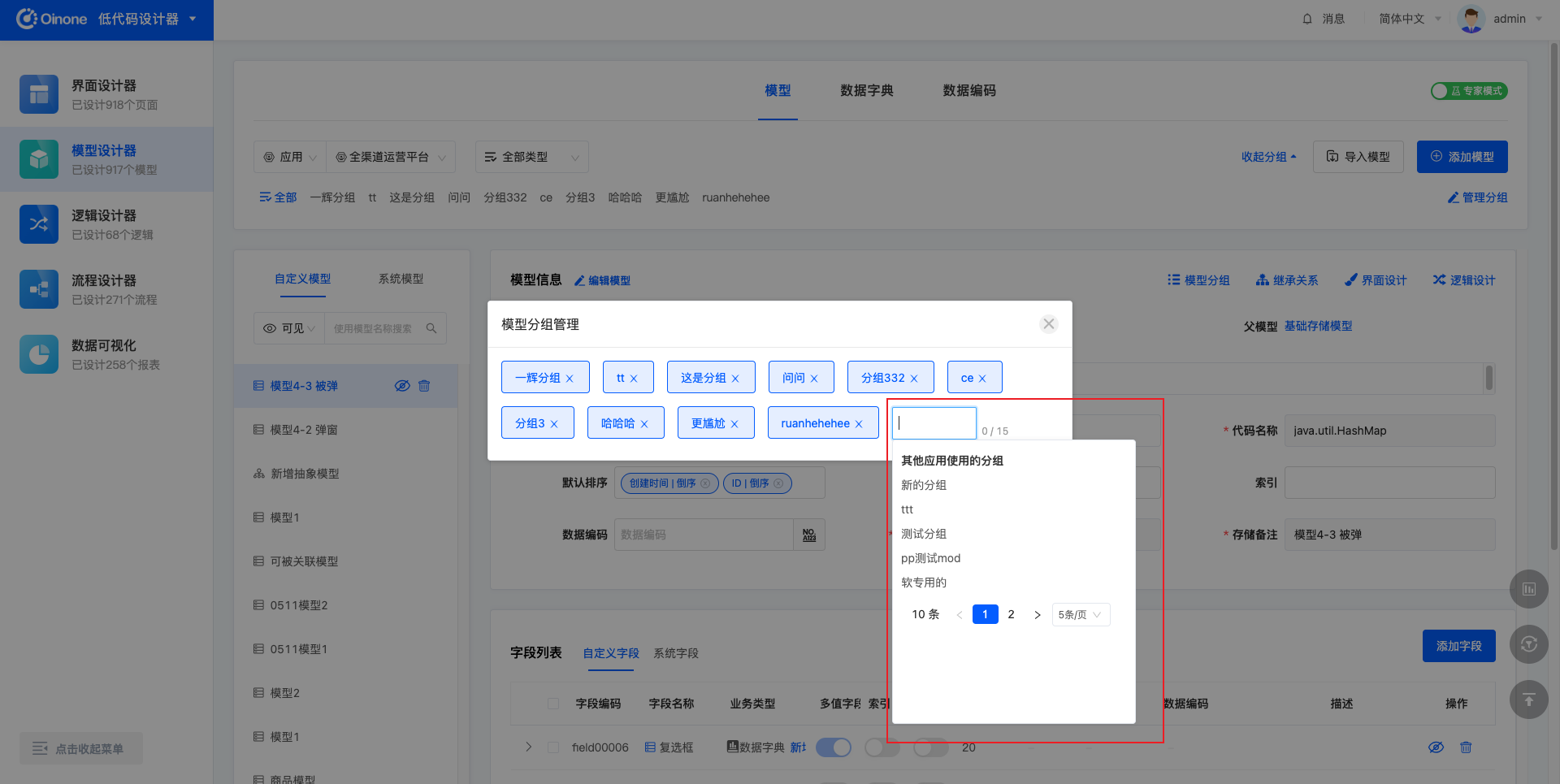
3.3 修改分组
双击分组标签,即可对已有分组进行名称的修改。若分组在其他应用也使用,则在其他应用内,该分组名称也同步变化。
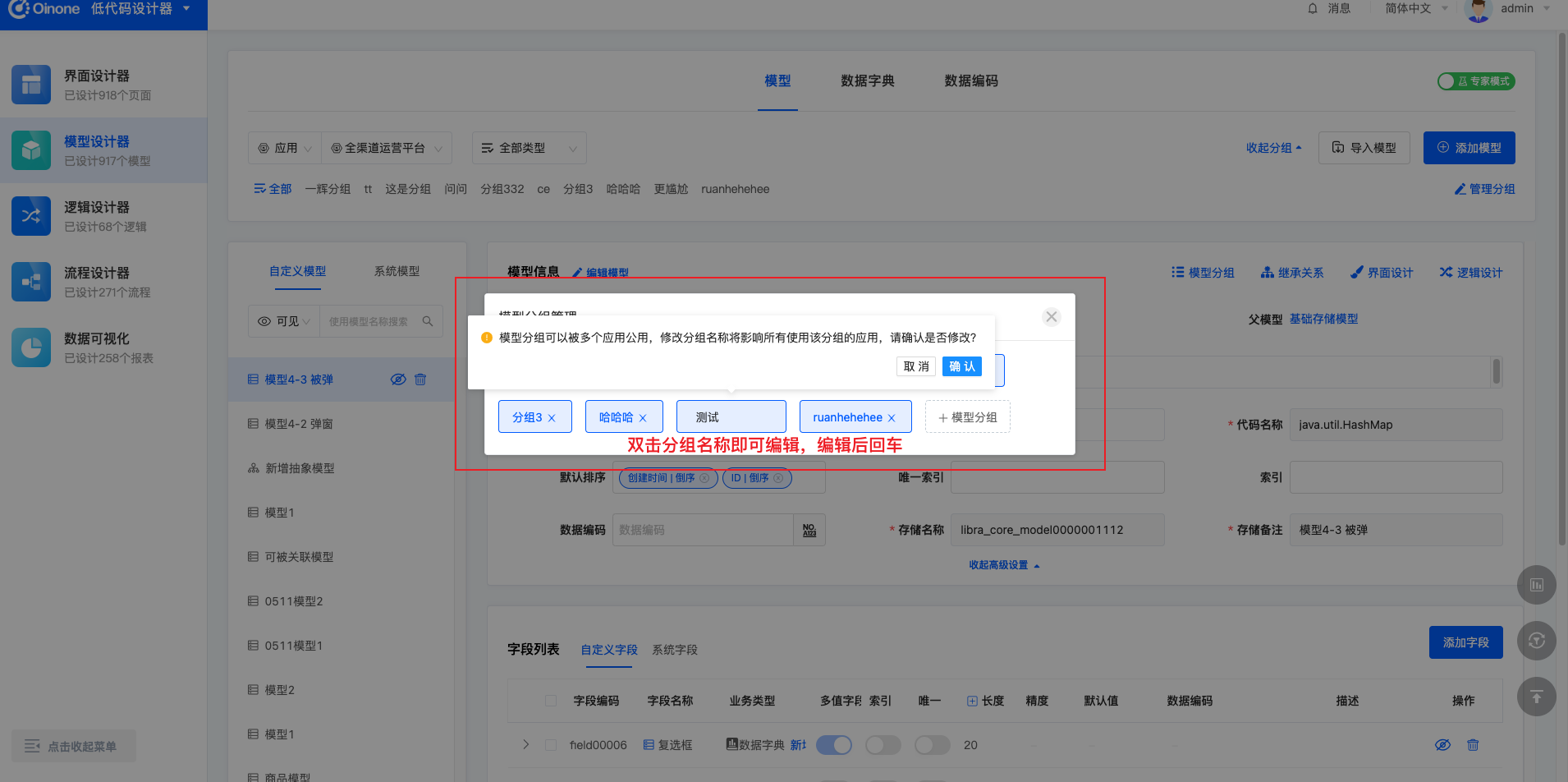
3.4 删除分组
点击分组标签右侧的“X”按钮,即为删除分组,但分组下如果有模型或者分组有被其他应用使用,则分组无法删除。
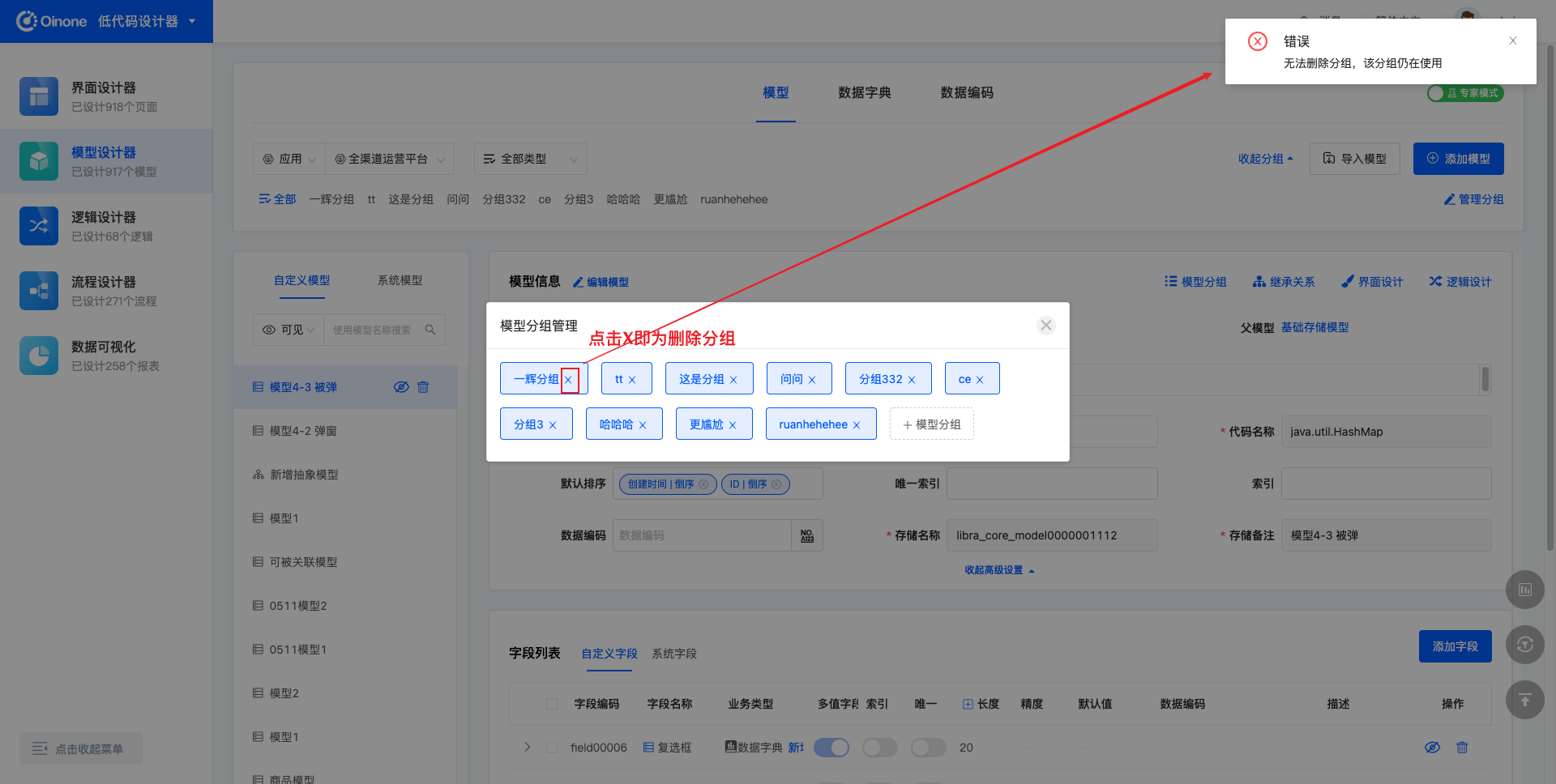
4. 模型管理
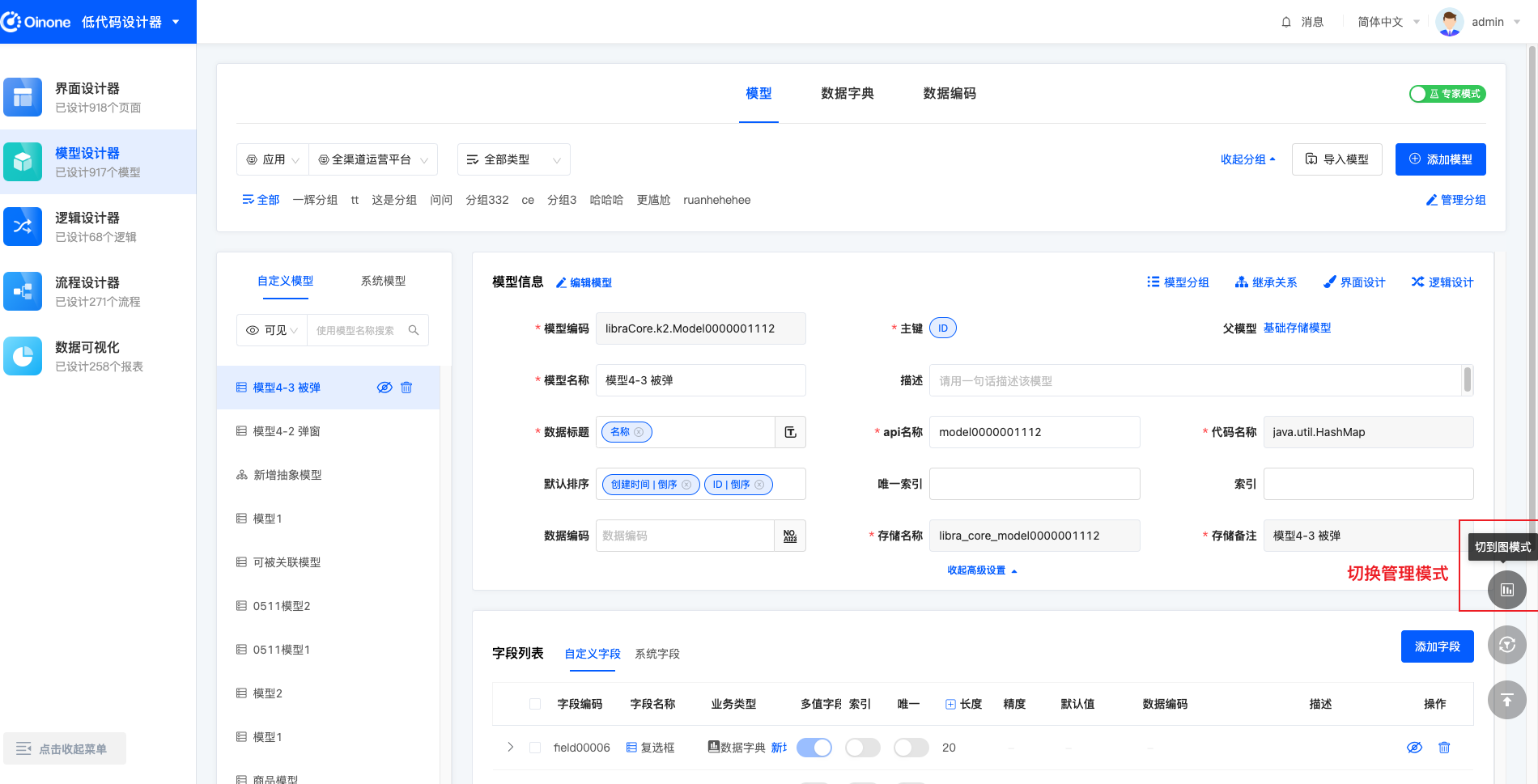
4.1 管理模式
在模型管理中,有两种管理模式,分别是图管理模式和列表管理模式。(下文简称图模式、表模式)
可以根据不同的使用场景,切换管理模式:
- 图管理模式下,模型操作区展示当前模型和与当前模型有直接关联关系的模型关系图,可以在关注模型关联关系时使用;
- 列表管理模式下,展示更多更详细的模型信息、字段信息,且左侧可快速切换不同模型,可以在关注模型基础信息时使用;
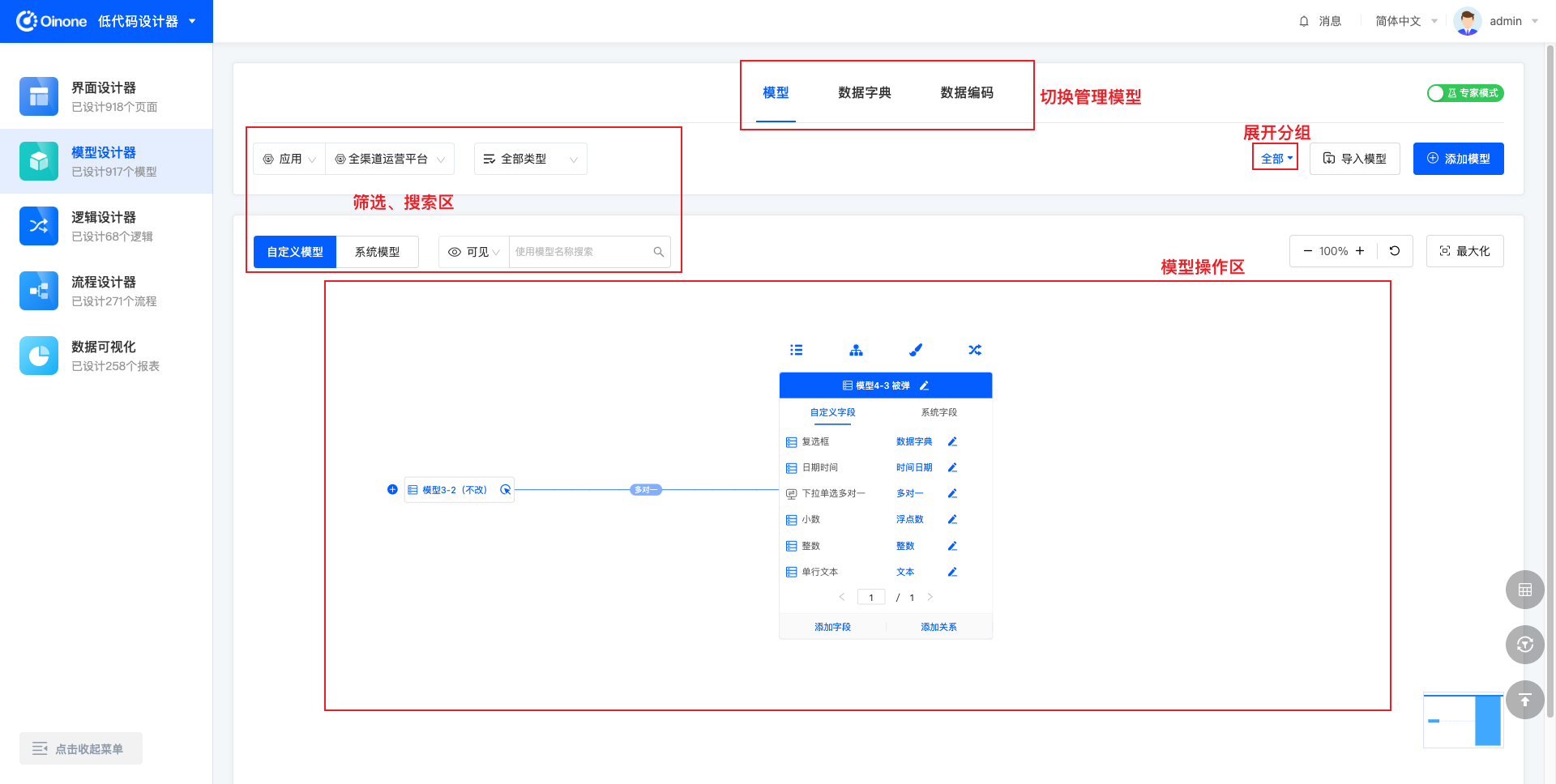
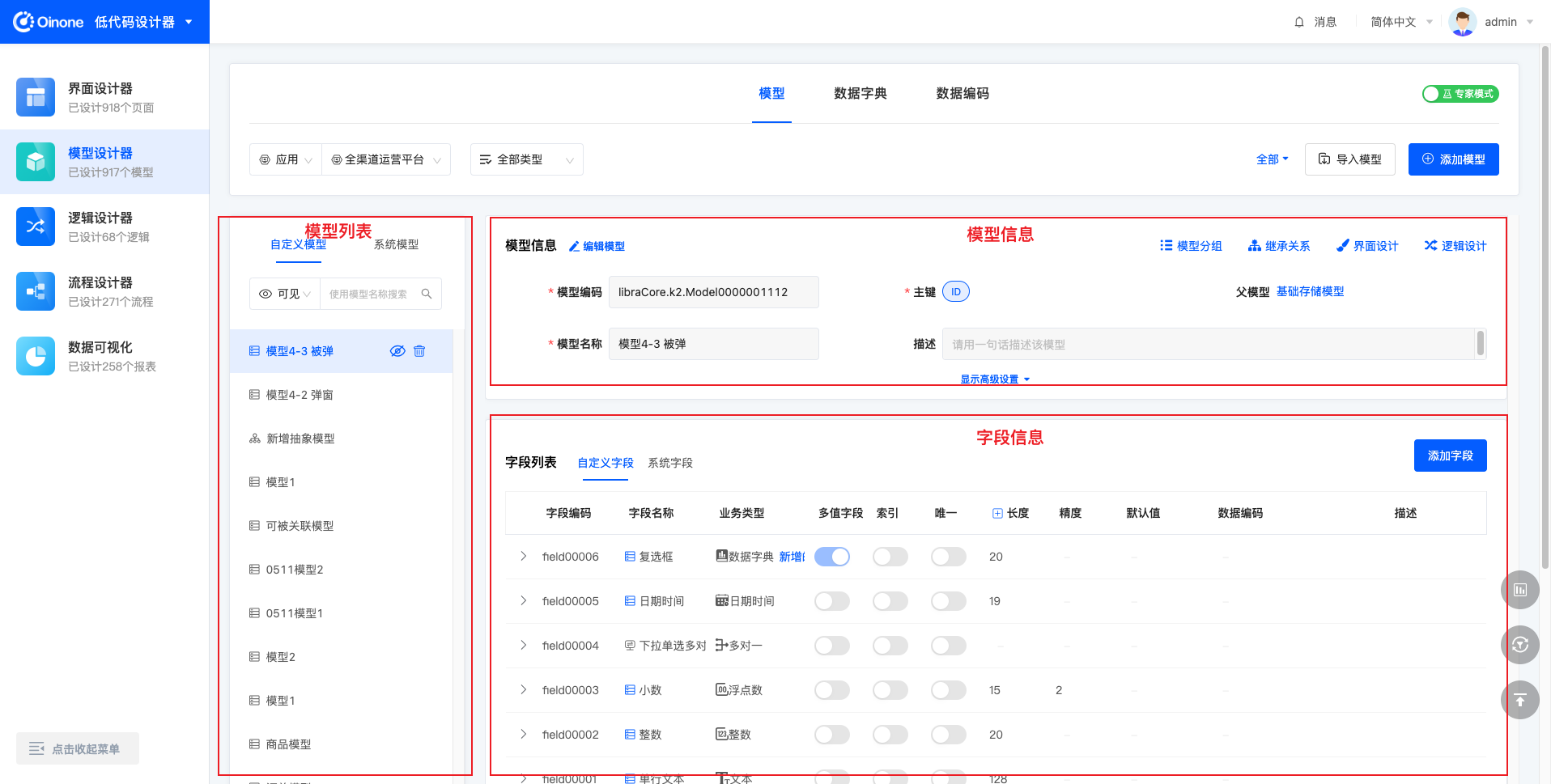
4.2 筛选
4.2.1 图模式筛选
在图模式下,顶部进行应用/模块、模型类型、分组的筛选,依此向下可以搜索或展开当前筛选条件下的模型列表,切换模型后在模型操作区将展示另一模型的信息。为了更大程度保留图模式下的模型展示区域,模型列表默认不会展示,点击搜索行的任意筛选项,即可展开模型列表。
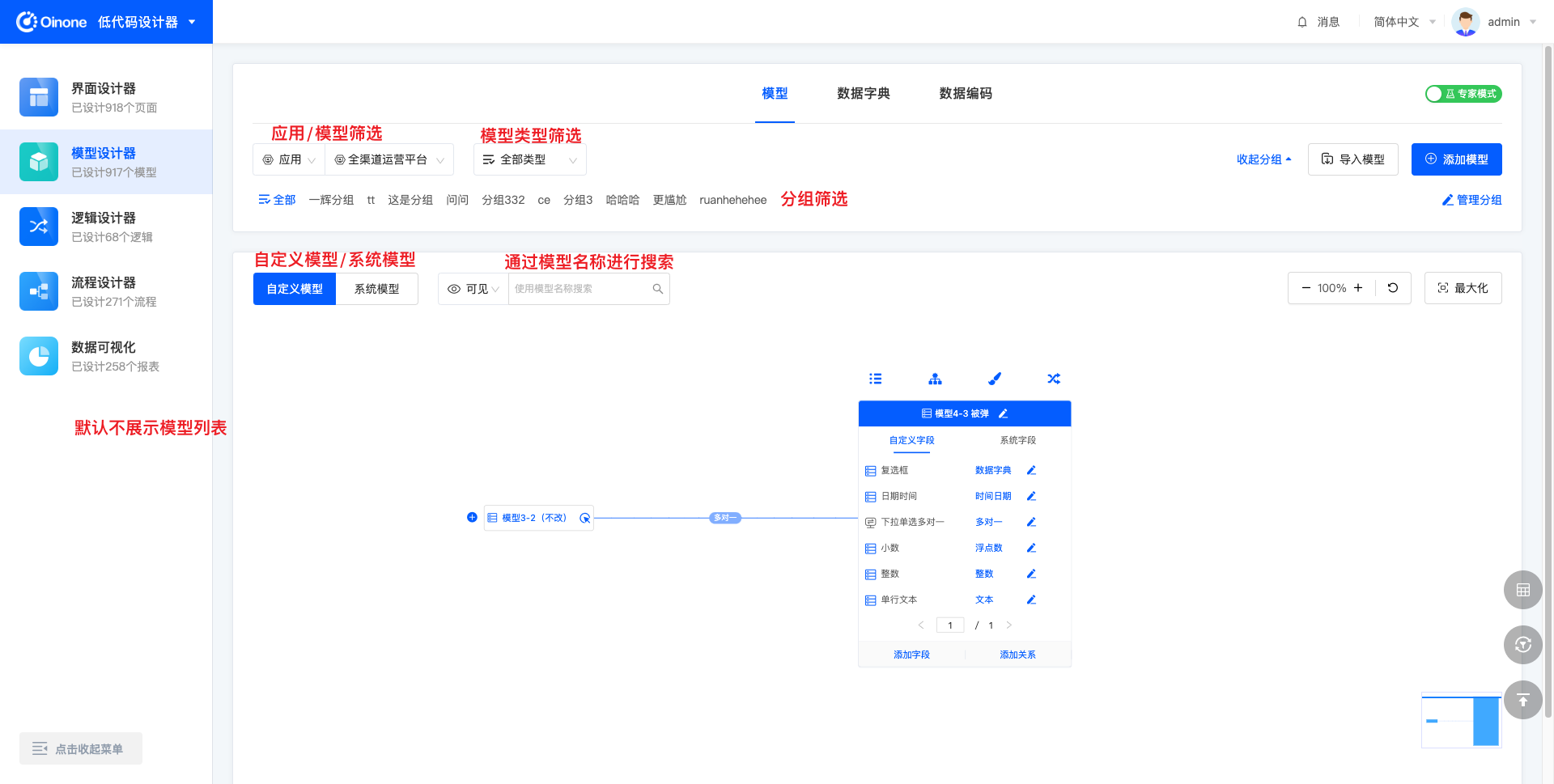
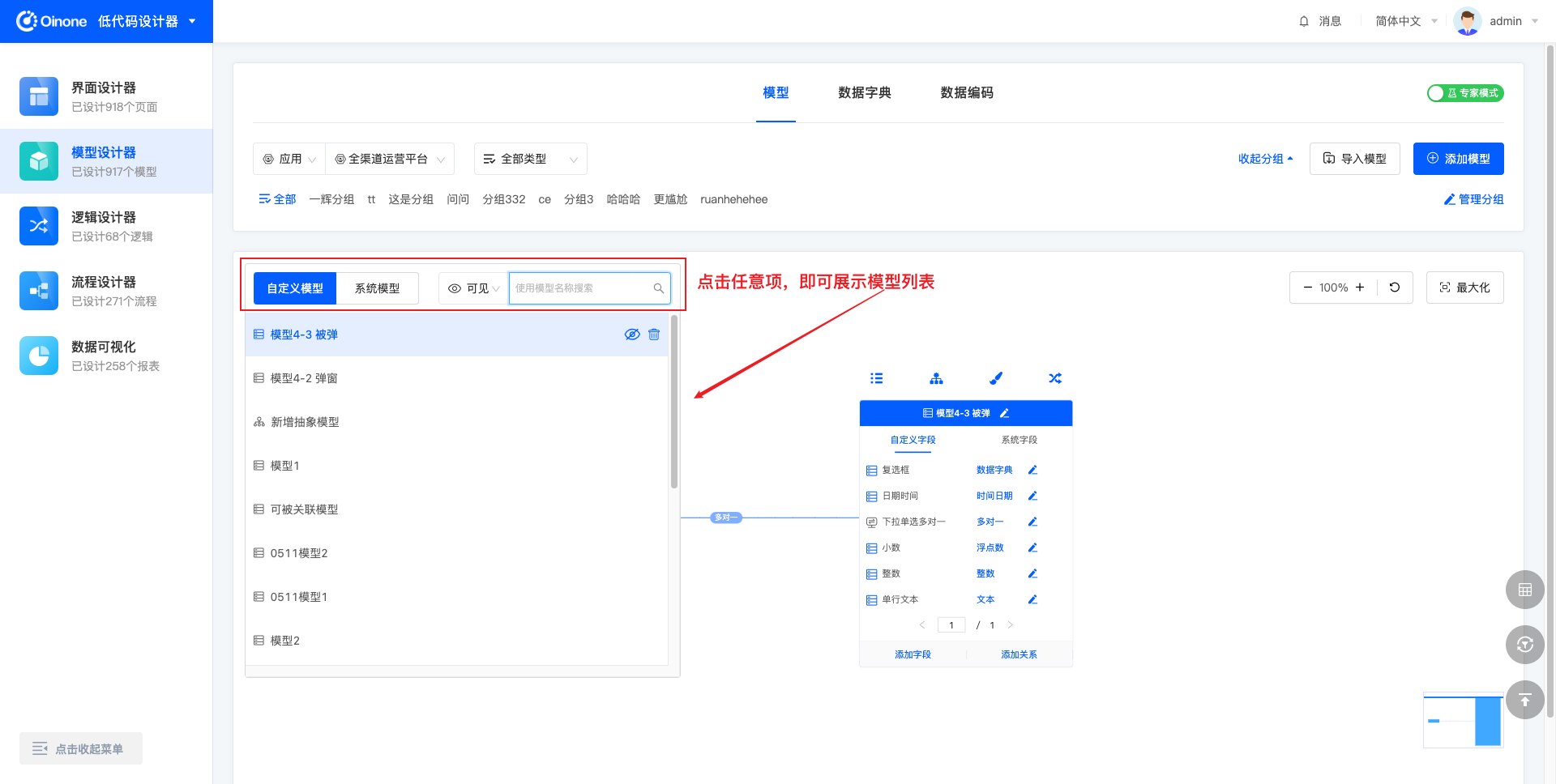
4.2.2 表模式筛选
在表模式下,顶部和图模式一致,都是应用/模块、模型类型、分组的筛选,模型操作区左侧会直接展示模型列表。
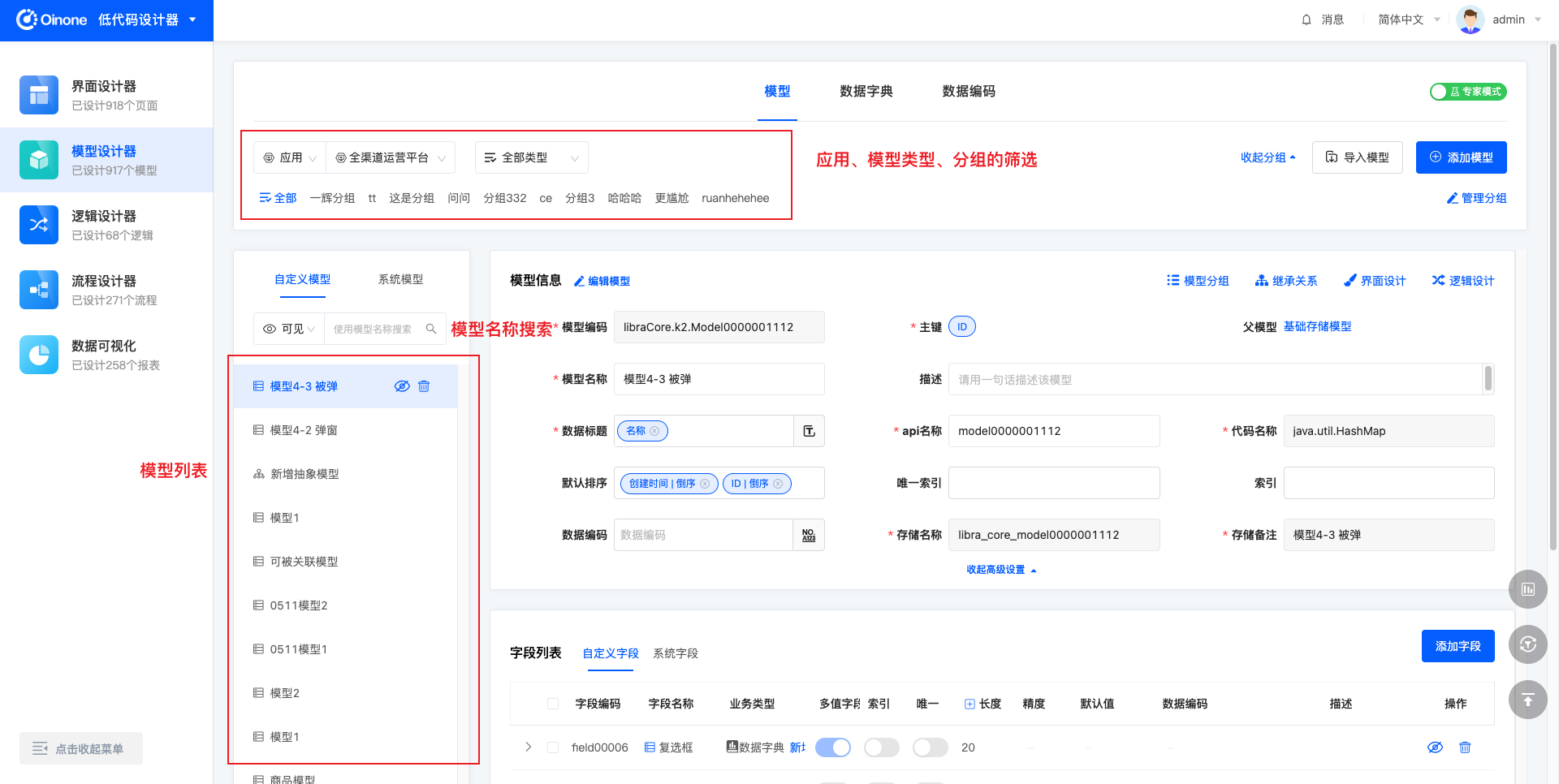
4.2.3 重置筛选
图模式和表模式下,右侧都有重置筛选的选项。如果点击“重置筛选”按钮,则将筛选栏恢复到进入页面时的选项。
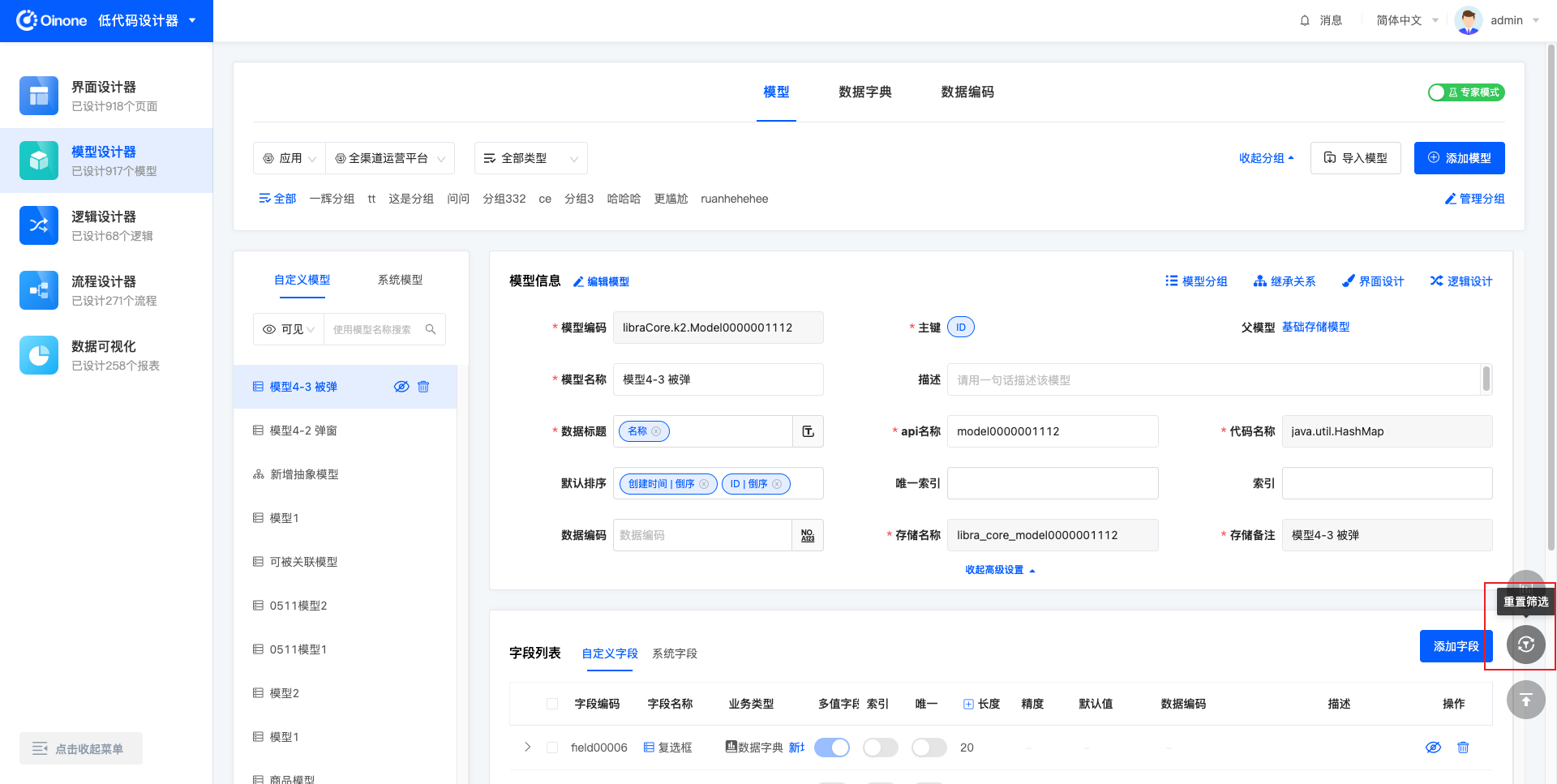
4.3 模型分组
模型新增成功后,默认无所属分组,每个模型可以设置所属分组,设置后通过分组进行筛选时,模型即展示在所属分组下。
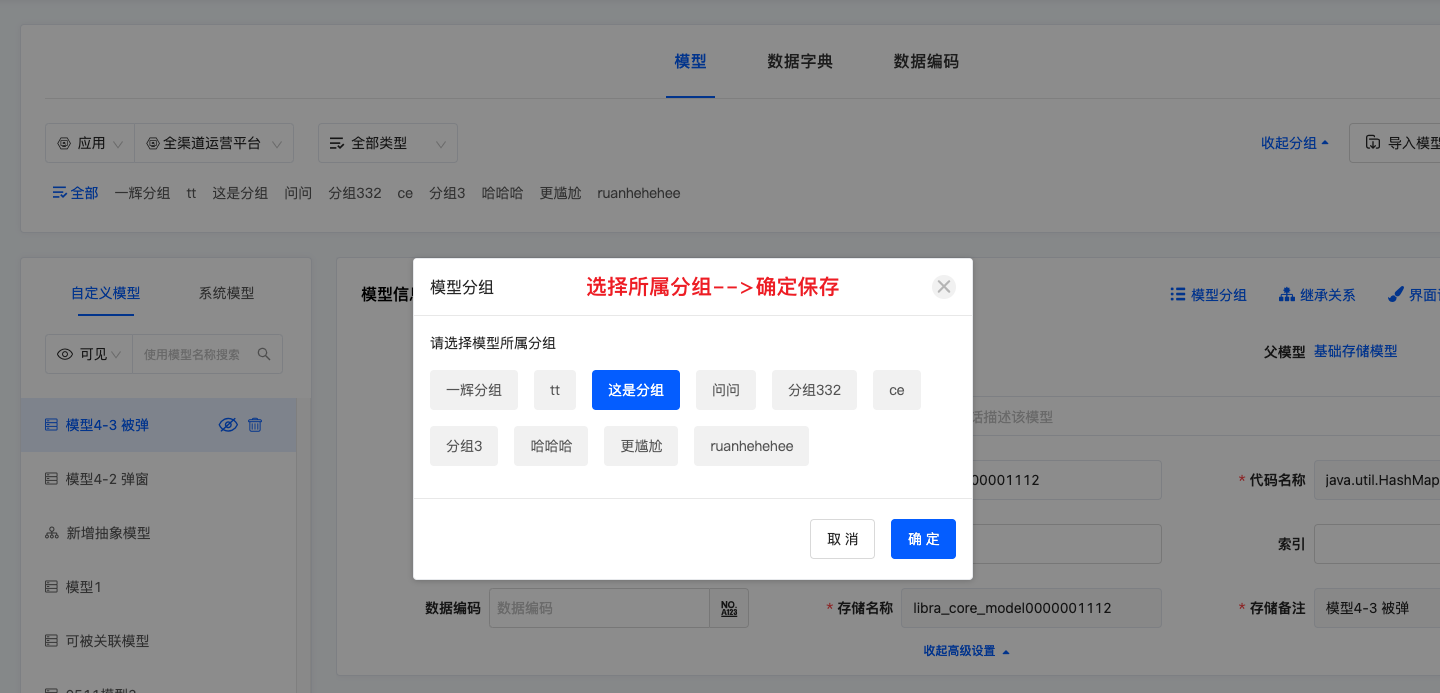
4.3.1 图模式设置分组
图模式下为模型设置分组,点击模型信息顶部第一个「模型分组」操作图标,点击后设置或修改分组。
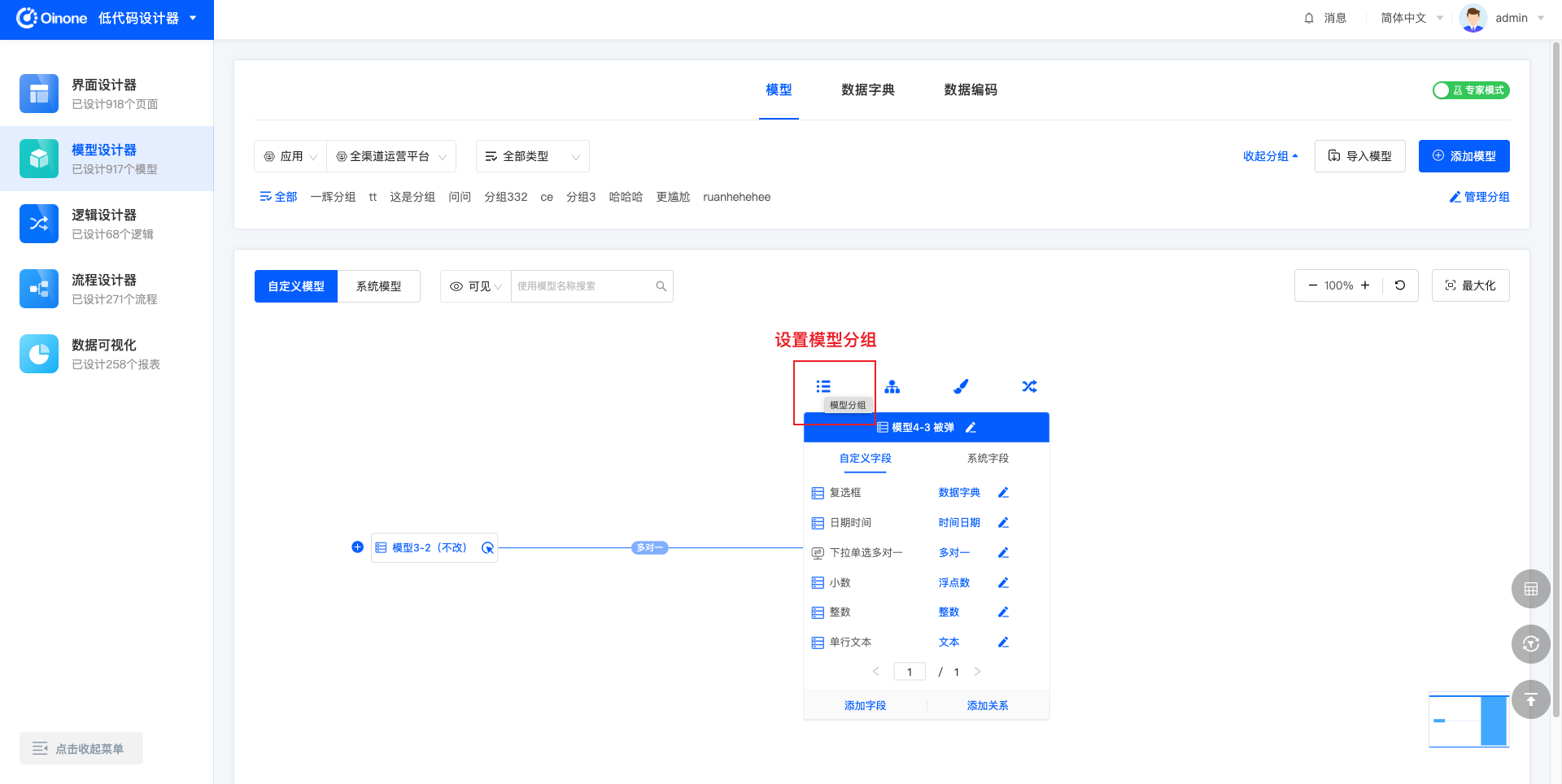
4.3.2 表模式设置分组
表模式下为模型设置分组,点击模型信息右上角第一个操作「模型分组」,点击后设置或修改分组。
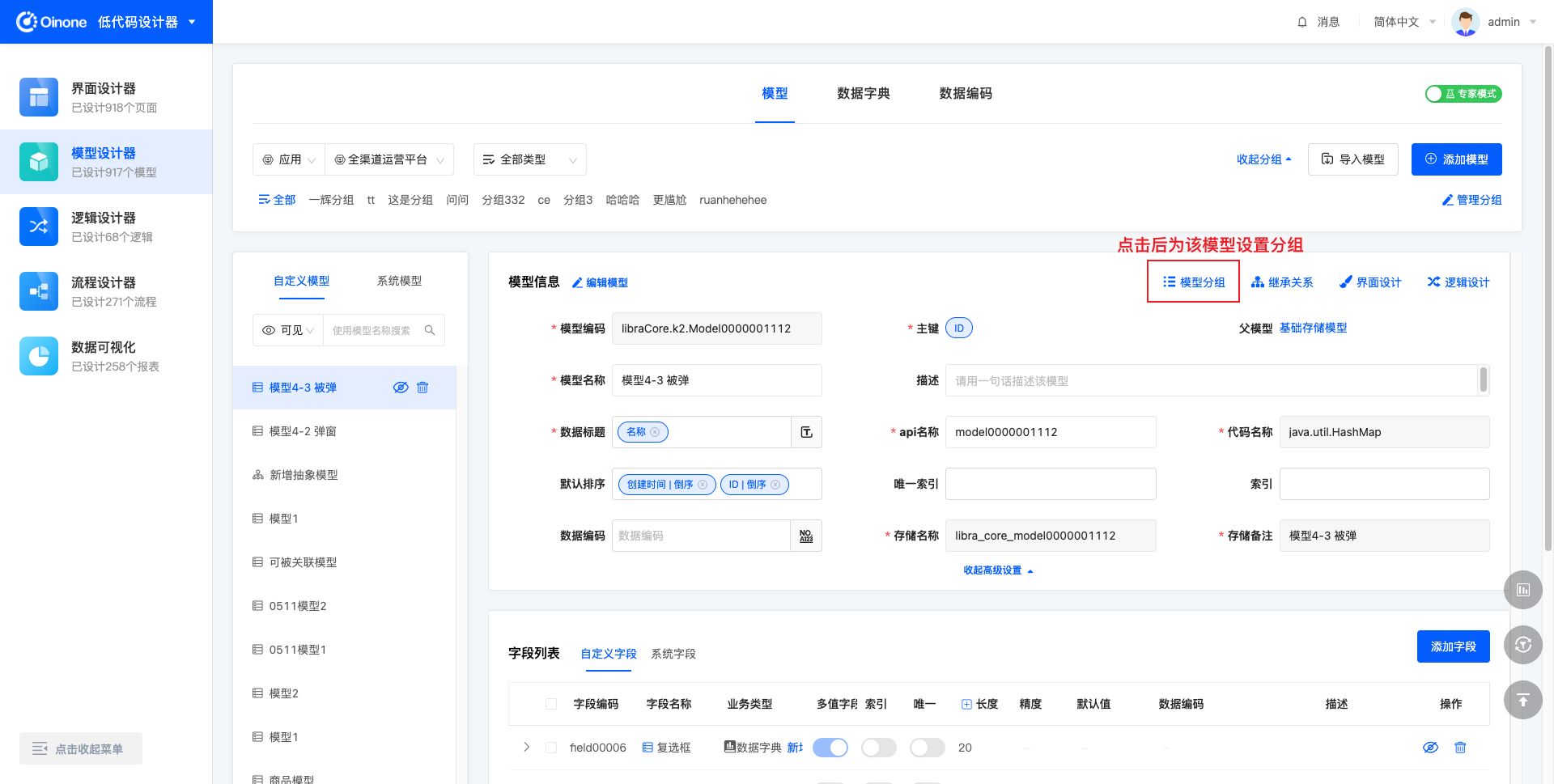
4.4 继承关系
查看模型的继承关系,点击展示跟当前模型有父子关系的模型关系图。
页面初始状态只展示一层父模型与一层子模型,父模型顶部和子模型底部有“展示更多”按钮,点击展示更多再向上或向下加载一层。连线的顶部展示“收起”按钮,点击“收起”按钮收起子模型。
- 点击非当前模型,会打开新窗口,链接跳转到点击模型的模型设计器页面,新页面满足点击模型的筛选条件;
- 支持设置显示比例,缩放模型关系图;
- 支持最大化全屏展示。
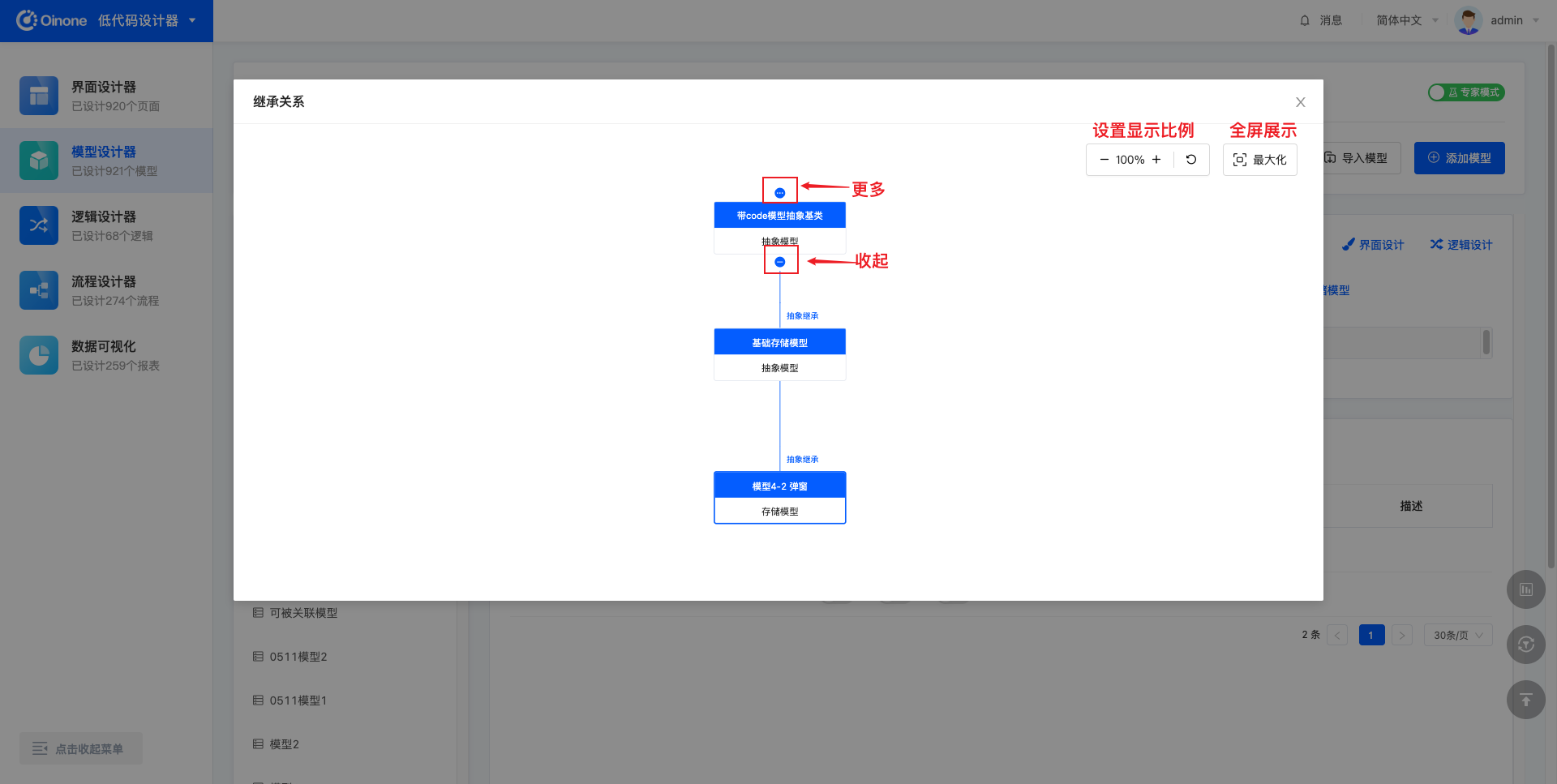
4.4.1 图模式继承关系
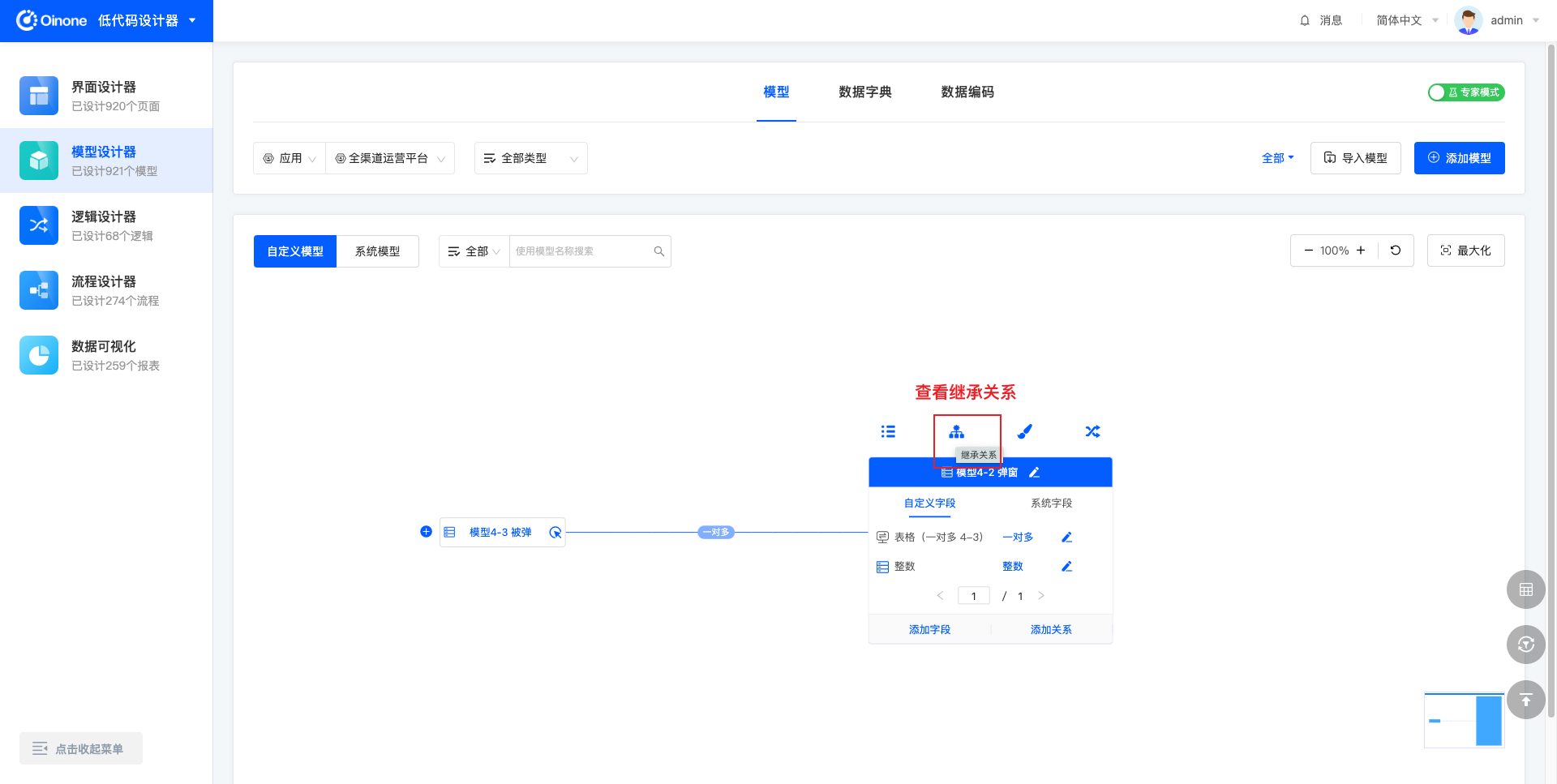
4.4.2 表模式继承关系
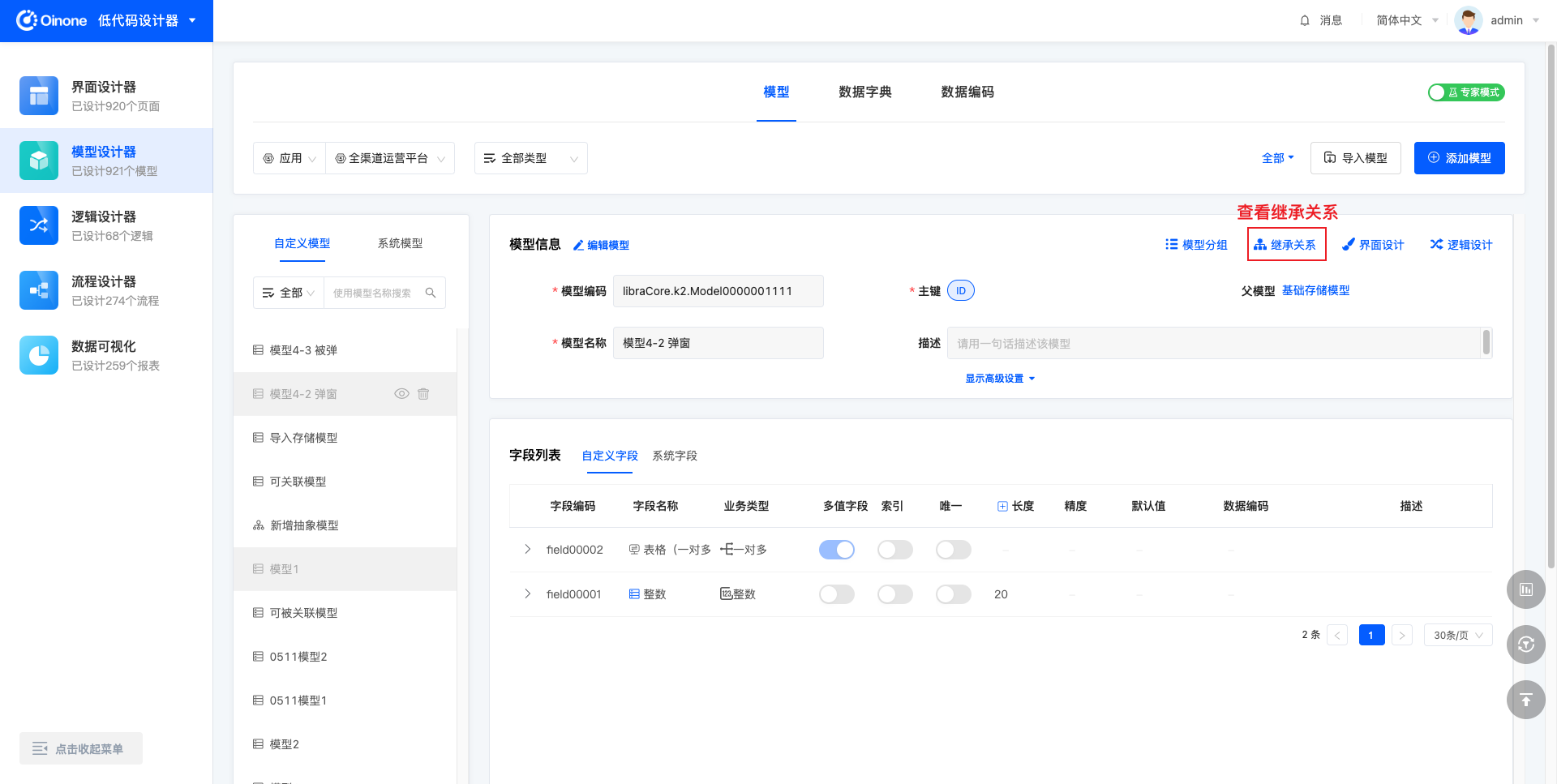
4.5 查看引用关系
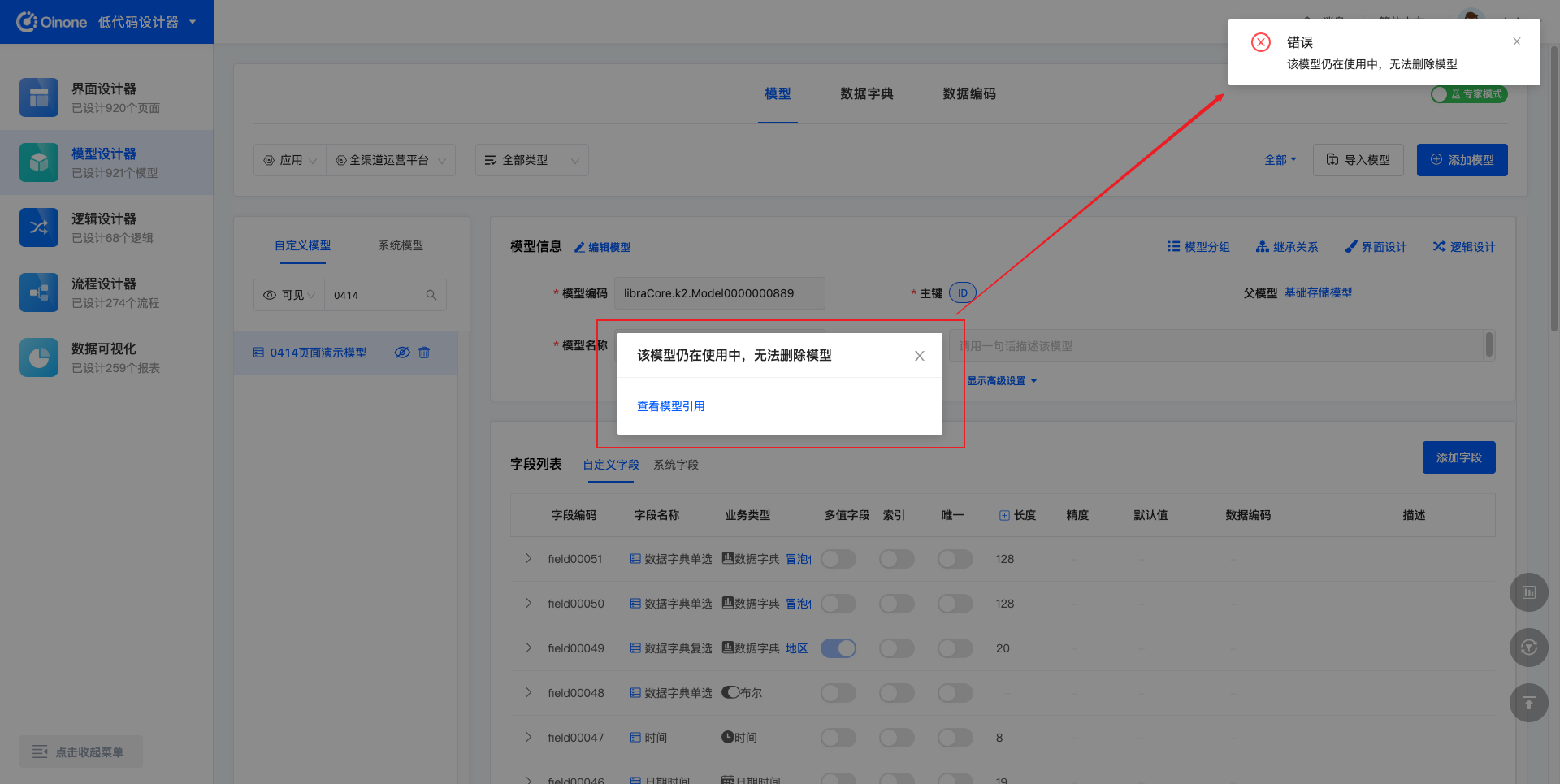
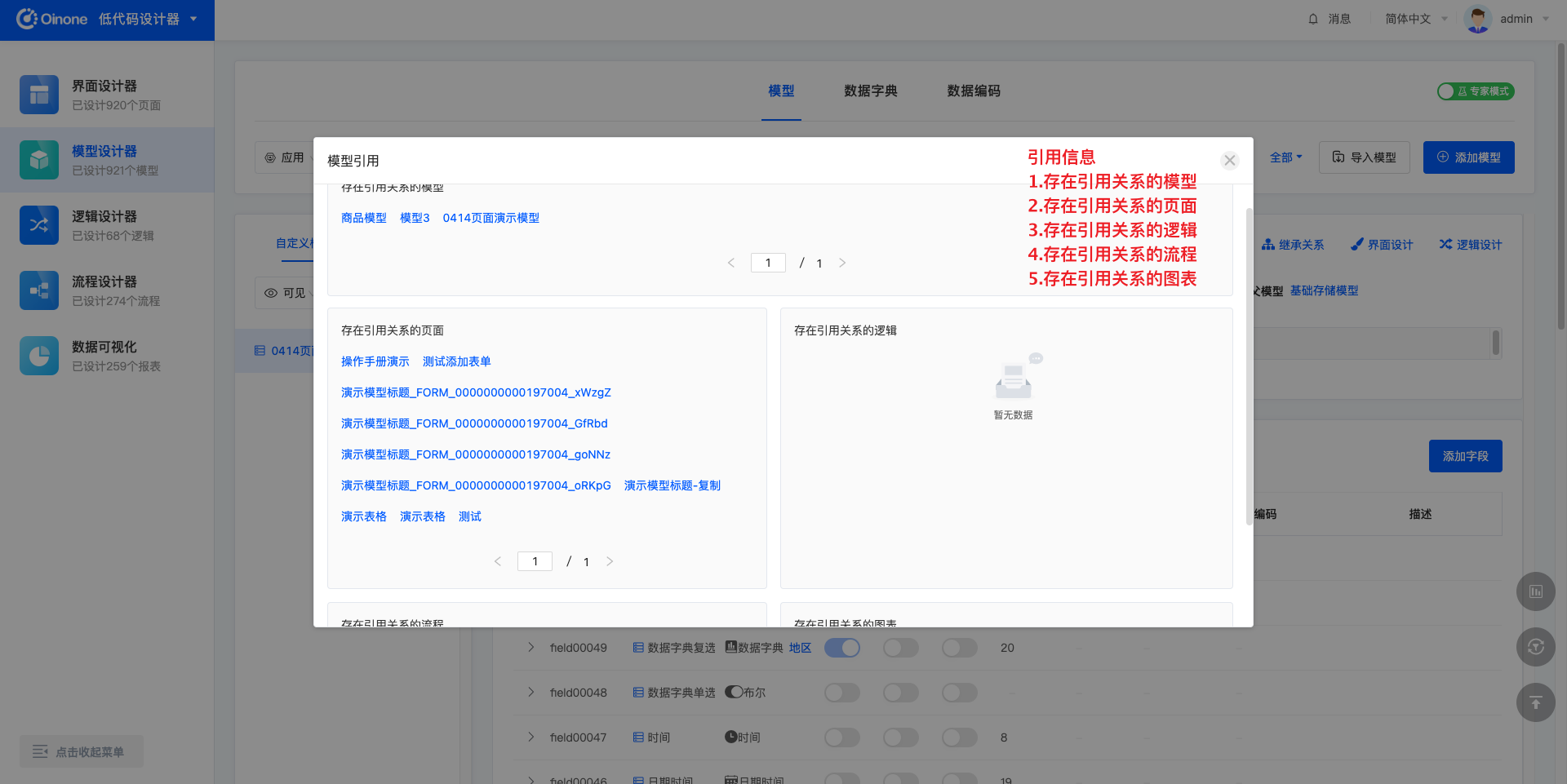
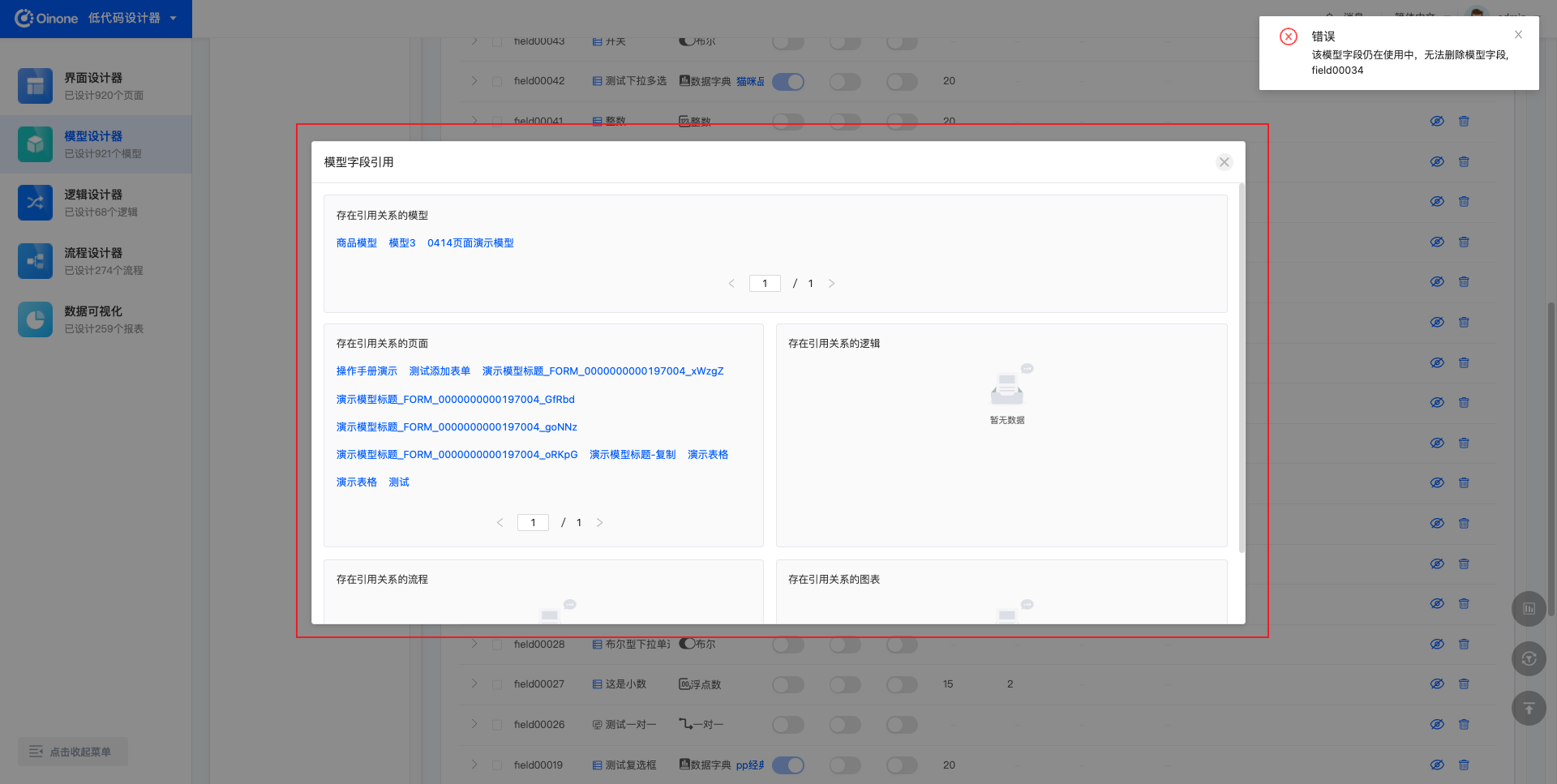
当删除模型时,如果模型有被其他设计器引用使用,则无法被删除。删除失败时会弹出“该模型仍在使用中,无法删除模型”的提示,并且可以点击「查看模型引用」,进而展示引用的详细信息。
-
引用包括五种:模型引用、页面引用、逻辑引用、流程引用、图表引用。
-
每种关系通过列表展示,列表项为链接(链接到对应的设计页面),内容为对应名称。例如,存在引用关系的流程的列表项显示的是流程的名称。列表项链接到对应流程的设计页面。
4.6 导入模型
导入模型的添加模型的一种方式,下载导入模板后在Excel中按照规则填写模型信息,成功导入后即添加模型成功。
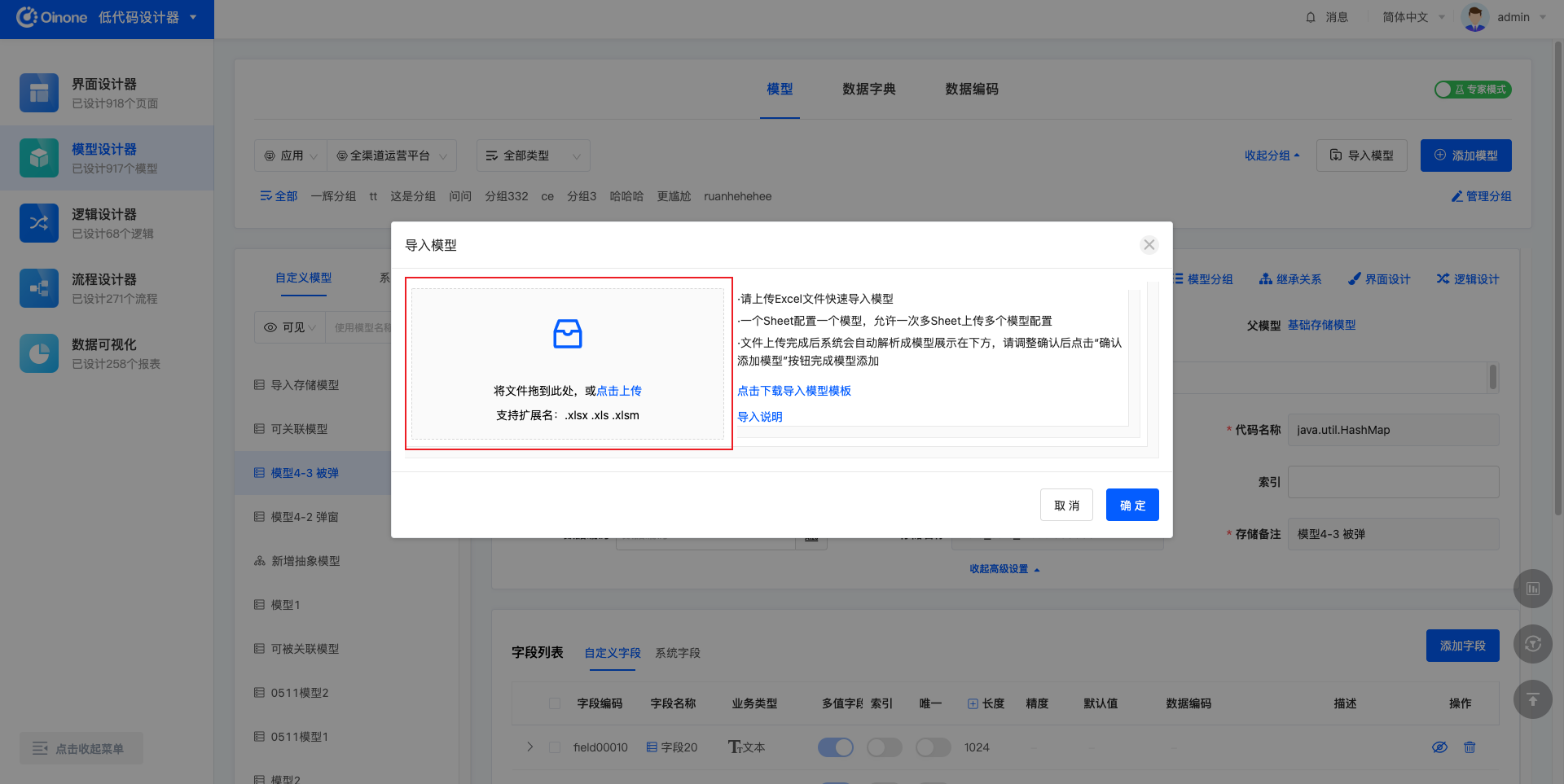
点击「导入模型」后,可在弹窗中下载导入模板、上传导入文件、查看导入说明。
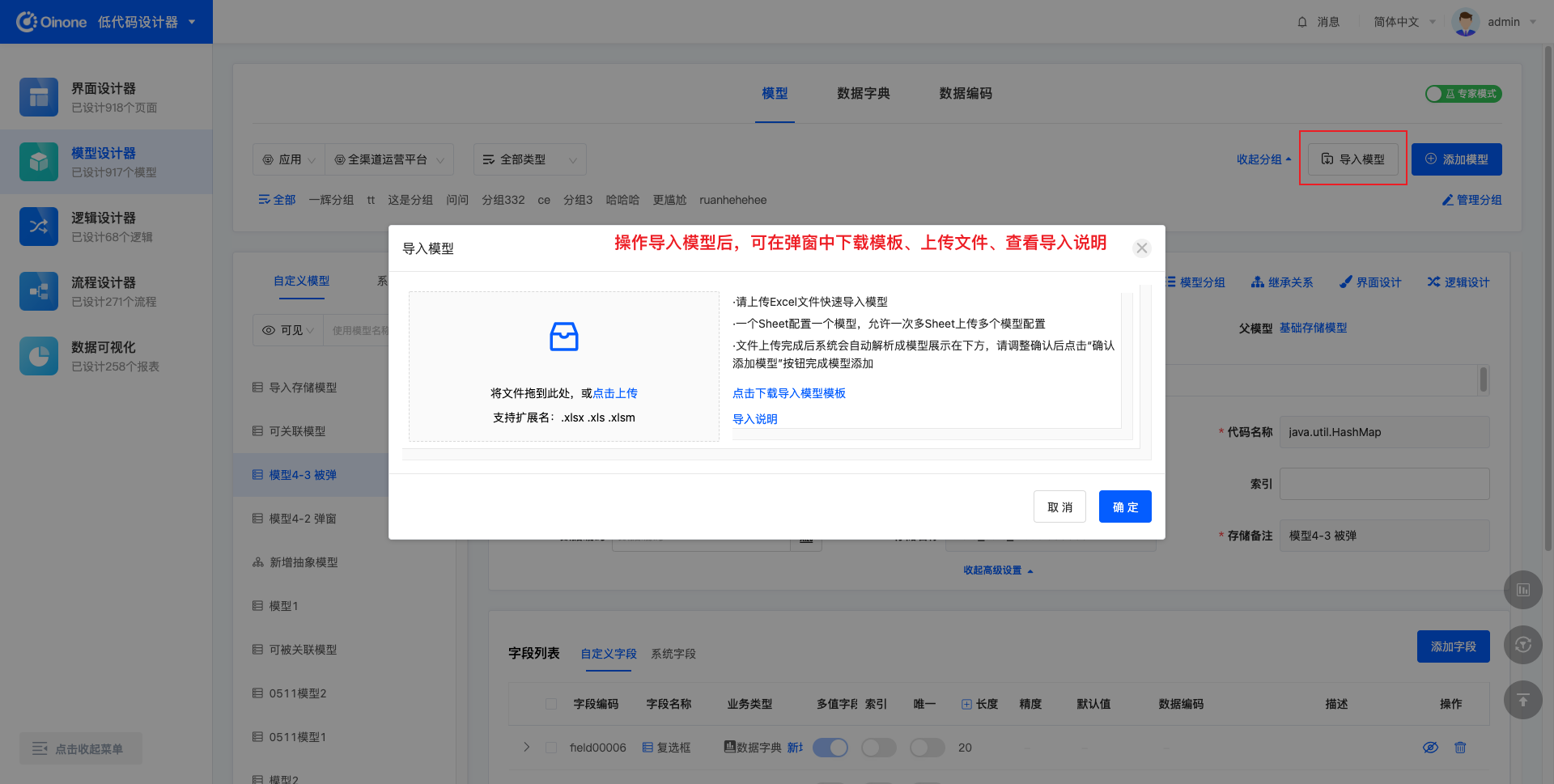
4.6.1 下载导入模板
下载导入模板时,会根据当前的操作模式不同,下载到的模板也不同。
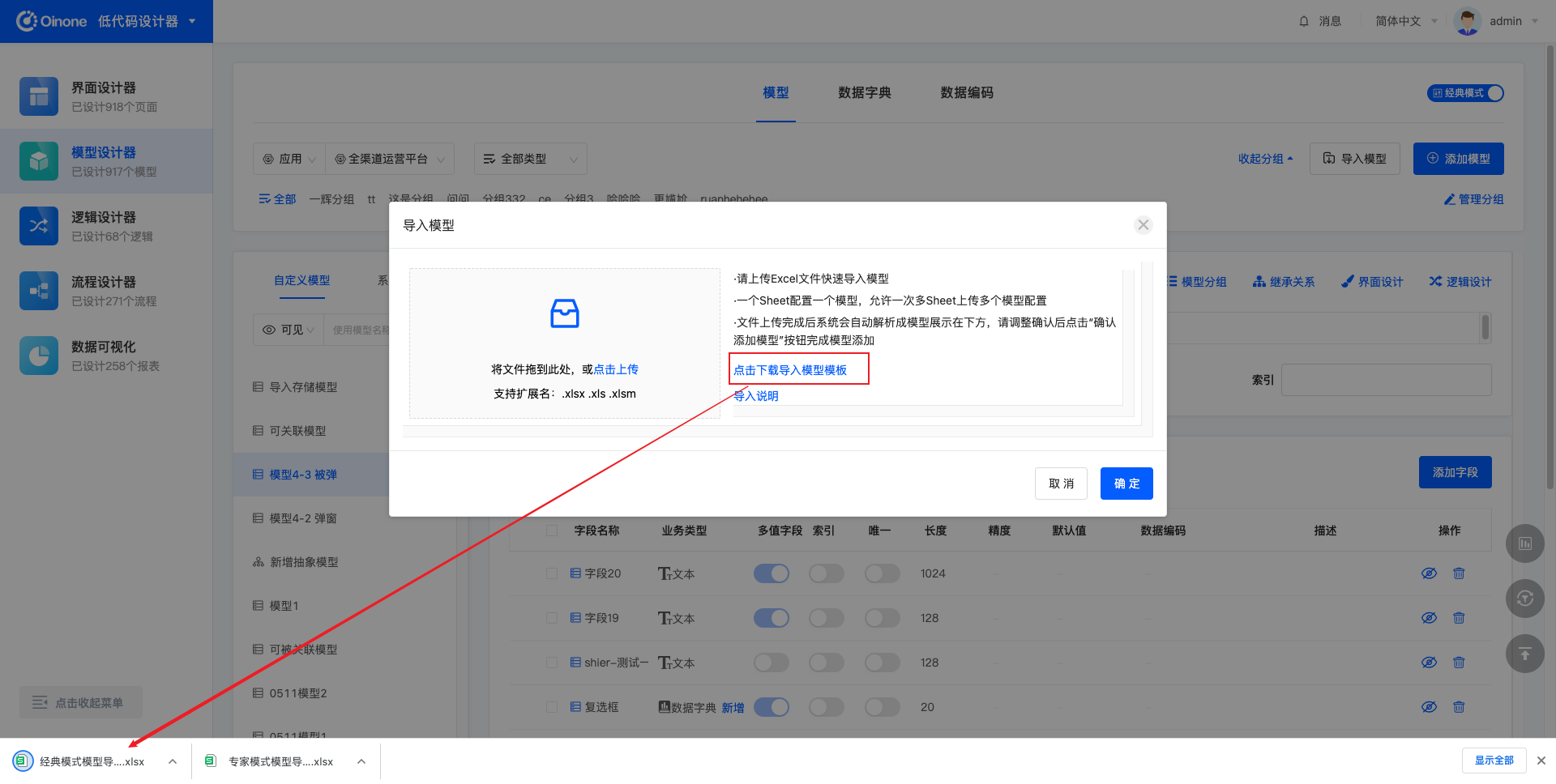
在经典模型下,下载的导入模板中需要填写的模型信息基础、数量少、易懂。
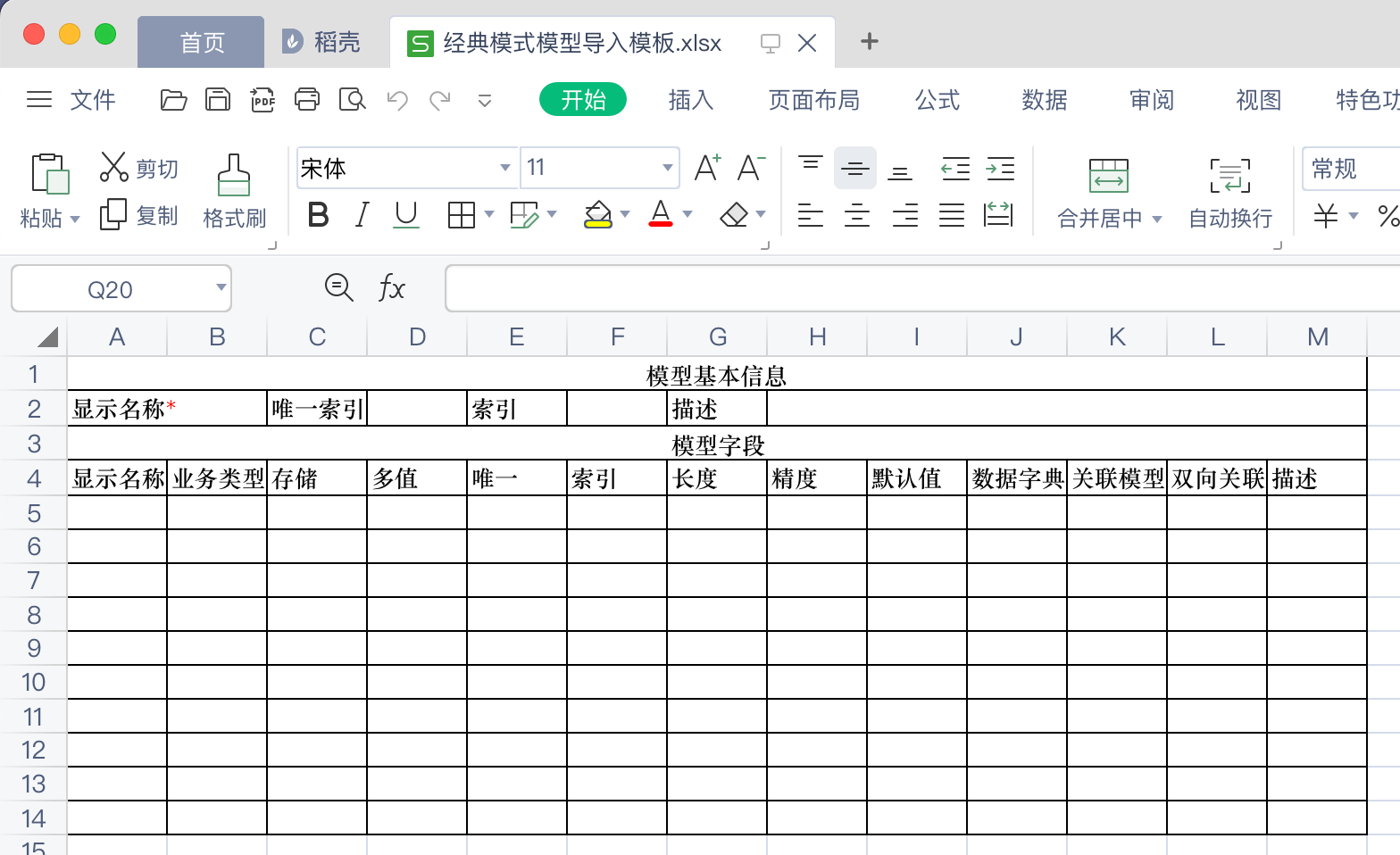
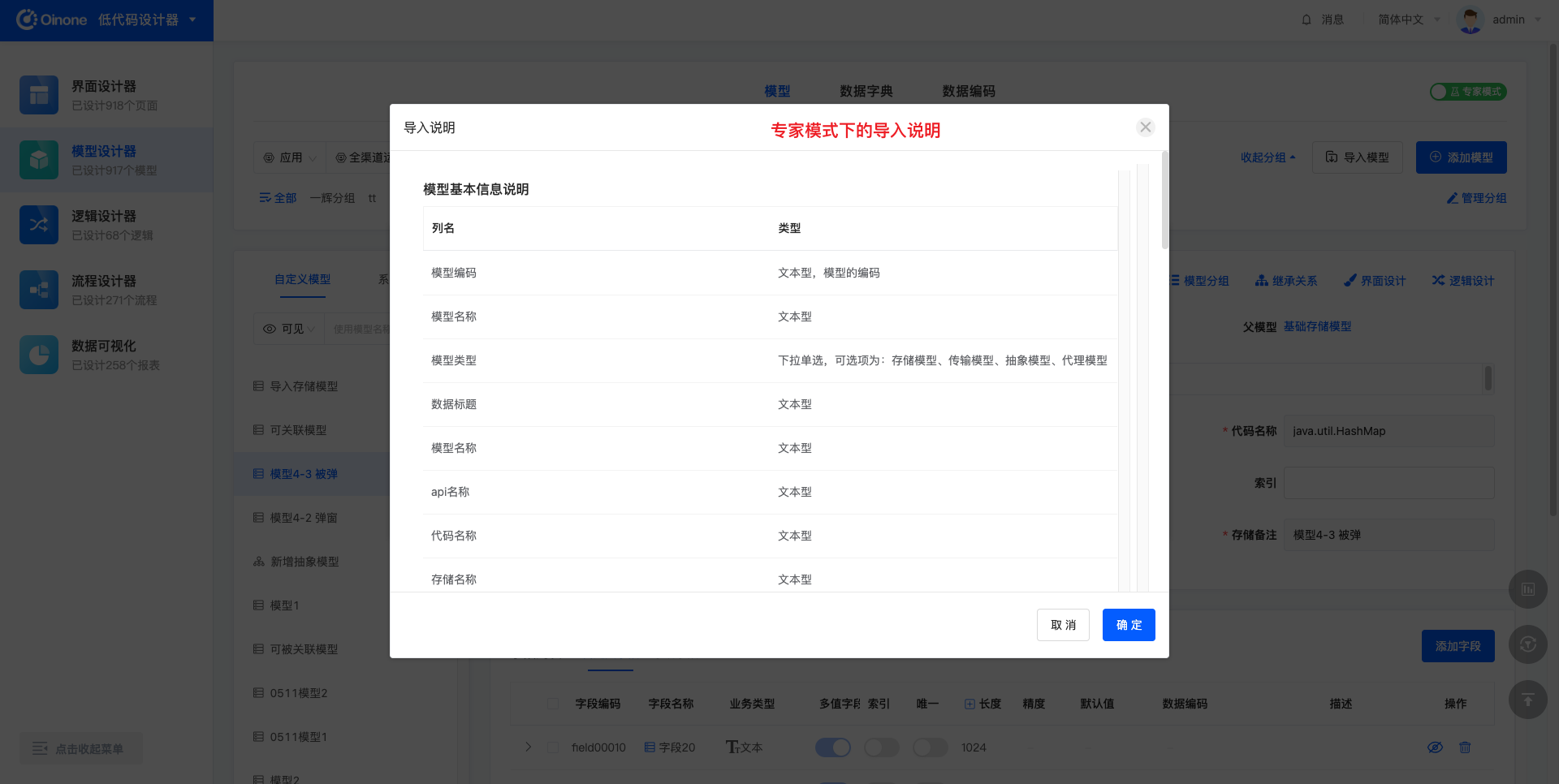
在专家模型下,下载的导入模板中需要填写的模型信息丰富、数量多、专业。
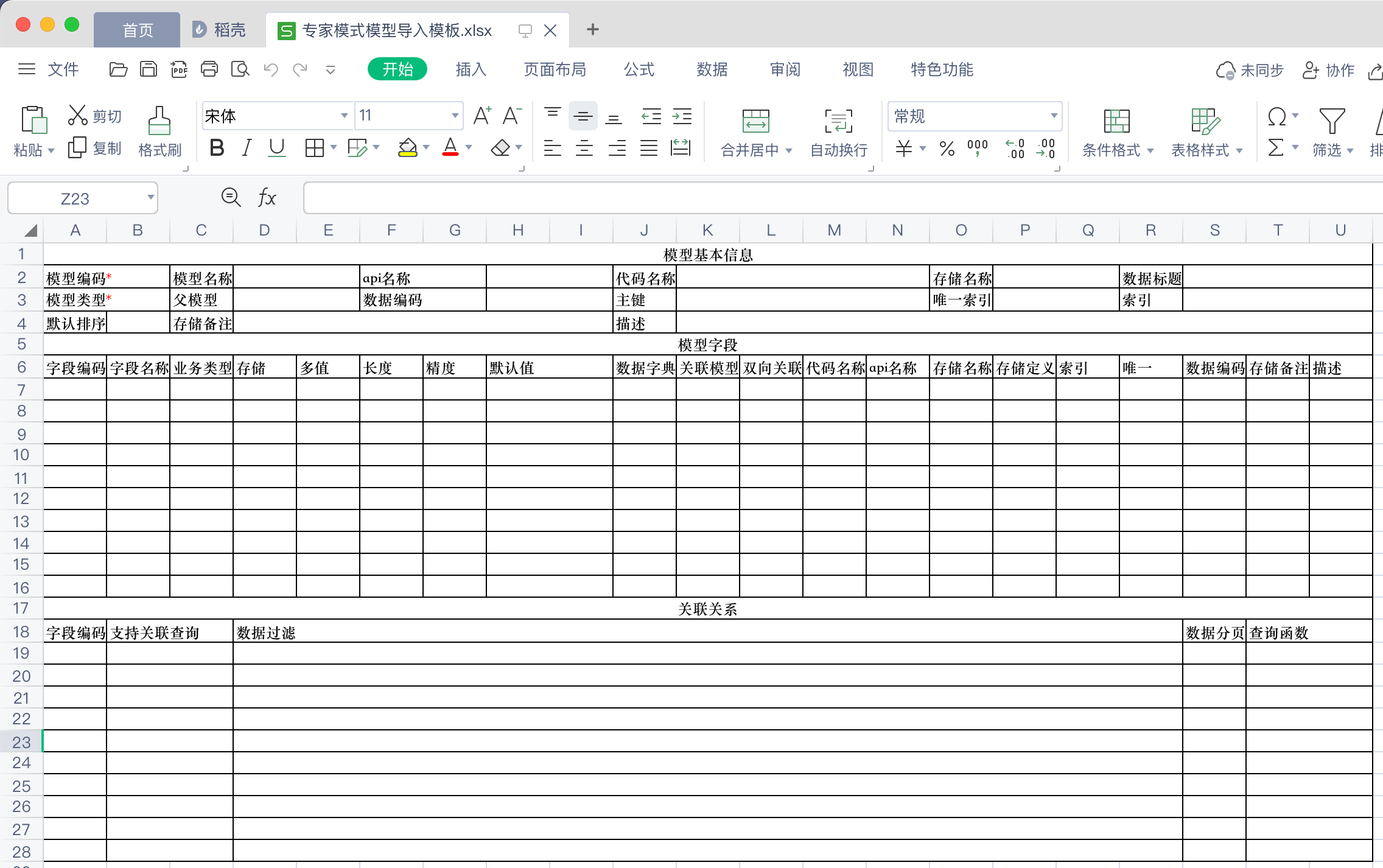
4.6.2 查看导入说明
导入说明中描述了导入模板中各项内容的含义、填写规则等,有助于用户正确填写导入文件。在经典模式或专家模式下点击「导入说明」后,分别弹出两种操作模式下的导入说明。
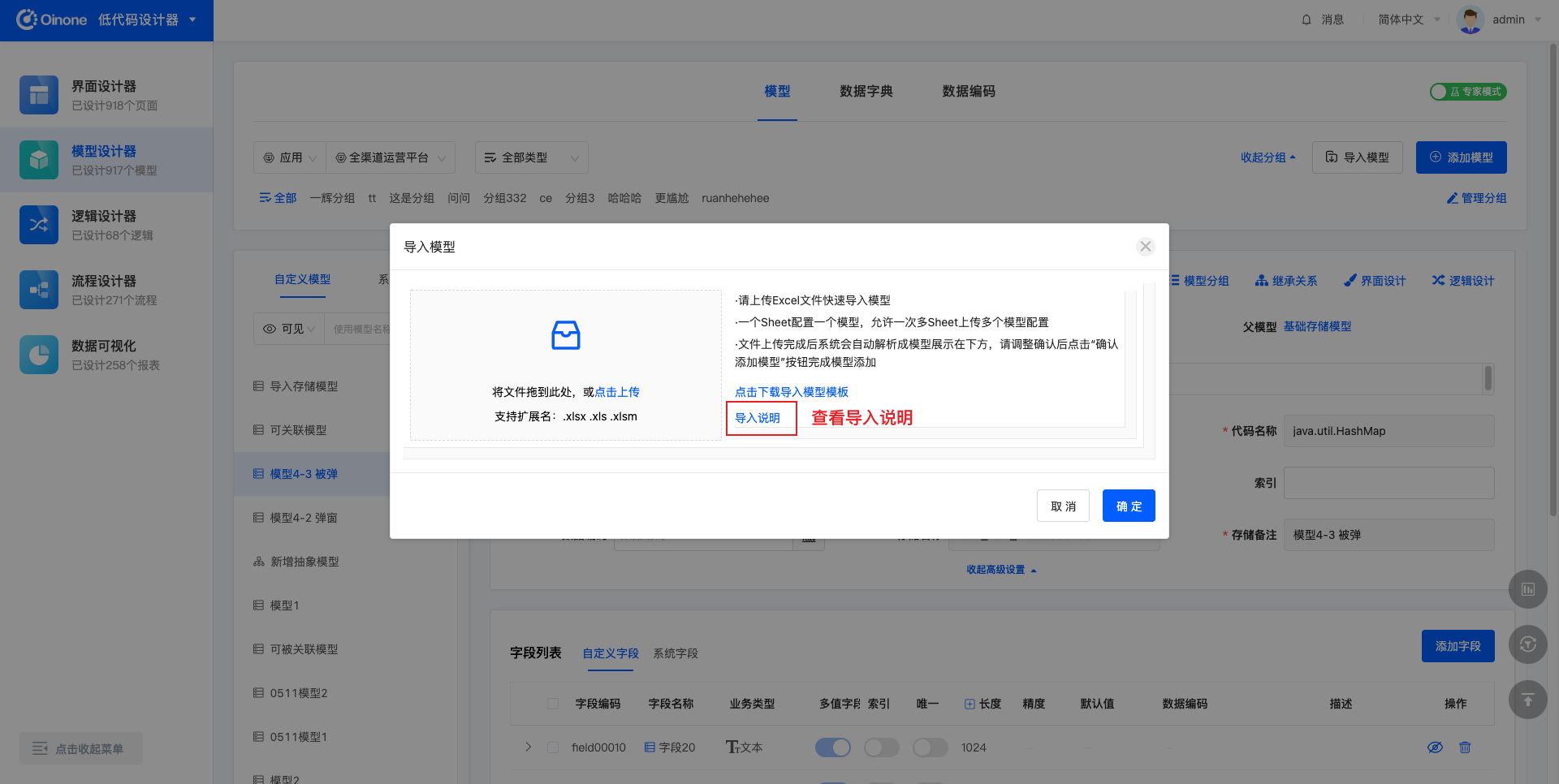
4.6.3 导入上传
导入文件正确填写后,在弹窗中选择Excel文件,或将Excel直接拖入弹窗中的文件上传区域。Excel文件仅支持三种格式:.xlsx .xls .xlsm。
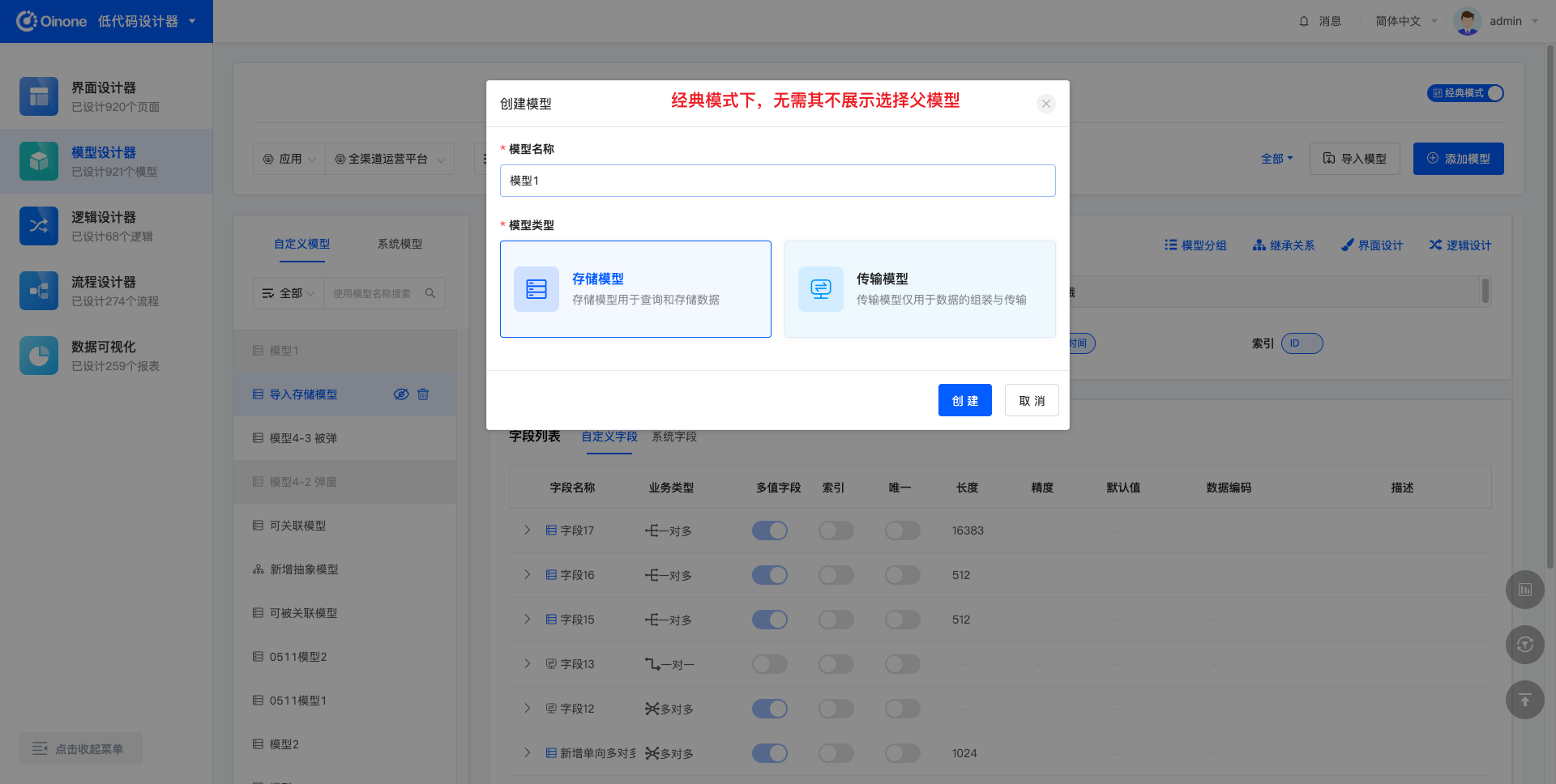
4.7 添加模型
点击「添加模型」,出现模型信息填写的弹窗,弹窗中包括:模型名称、模型类型、父模型。填写并保存成功后,模型即创建成功。
4.7.1 模型类型
专家模式下支持创建4种类型的模型:存储模型、传输模型、抽象模型、代理模型;经典模式下支持创建2种类型的模型:存储模型、传输模型。
- 存储模型:用于存储数据的模型,生成前后端交互协议、数据表、数据构造器和数据管理器。
- 抽象模型:用于配置多个子模型的公用字段和函数的模型,不会生成前后端交互协议、数据表、数据构造器和数据管理器。
- 传输模型:用于数据传输的模型,生成前后端交互协议和数据构造器,不生成数据表和数据管理器。
- 代理模型:用于以代理的方式扩展存储模型的模型,可以在存储模型的基础上增加传输字段和函数,与被代理的存储模型共用相同的数据管理器。
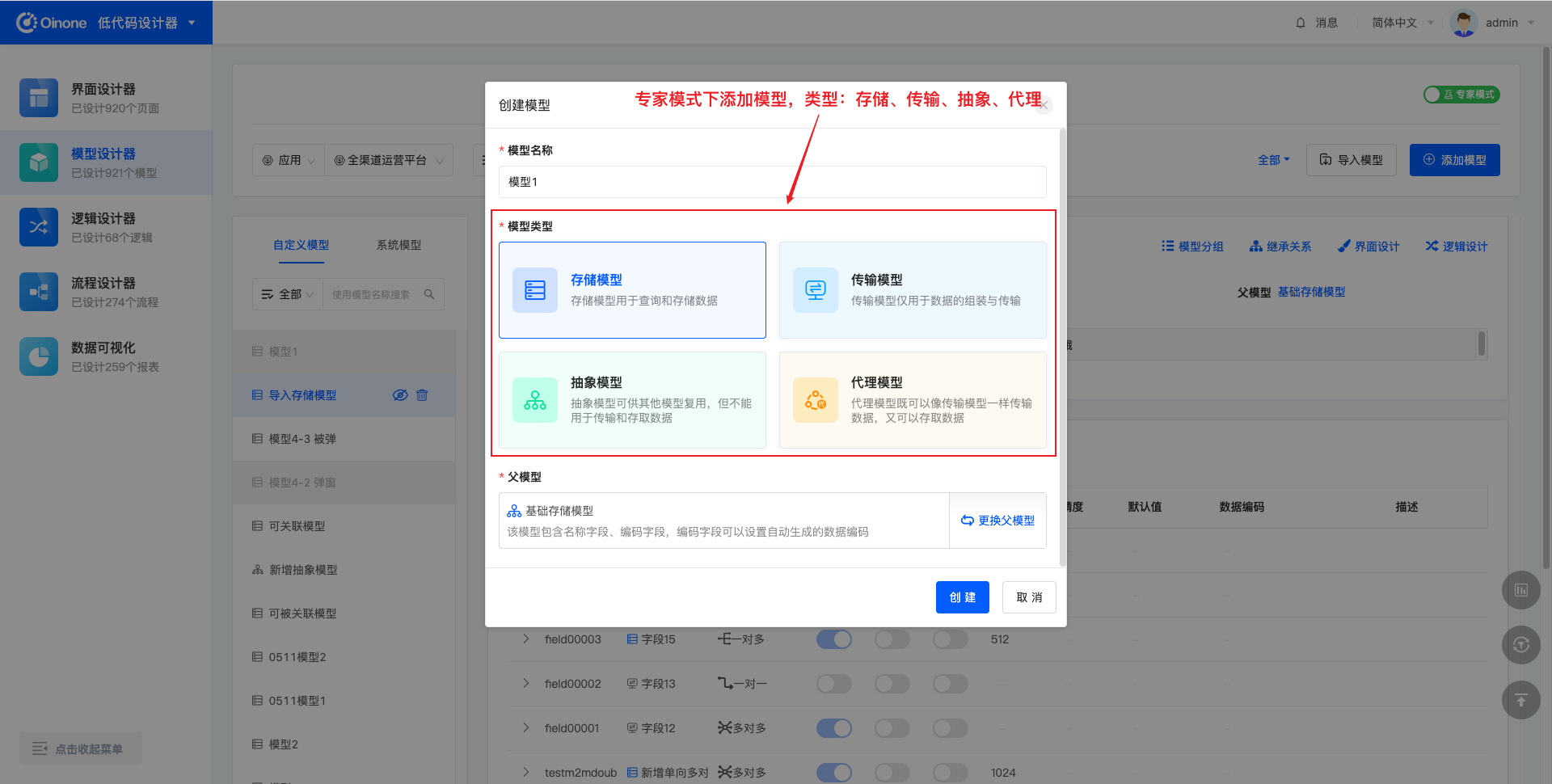
4.7.2 选择父模型
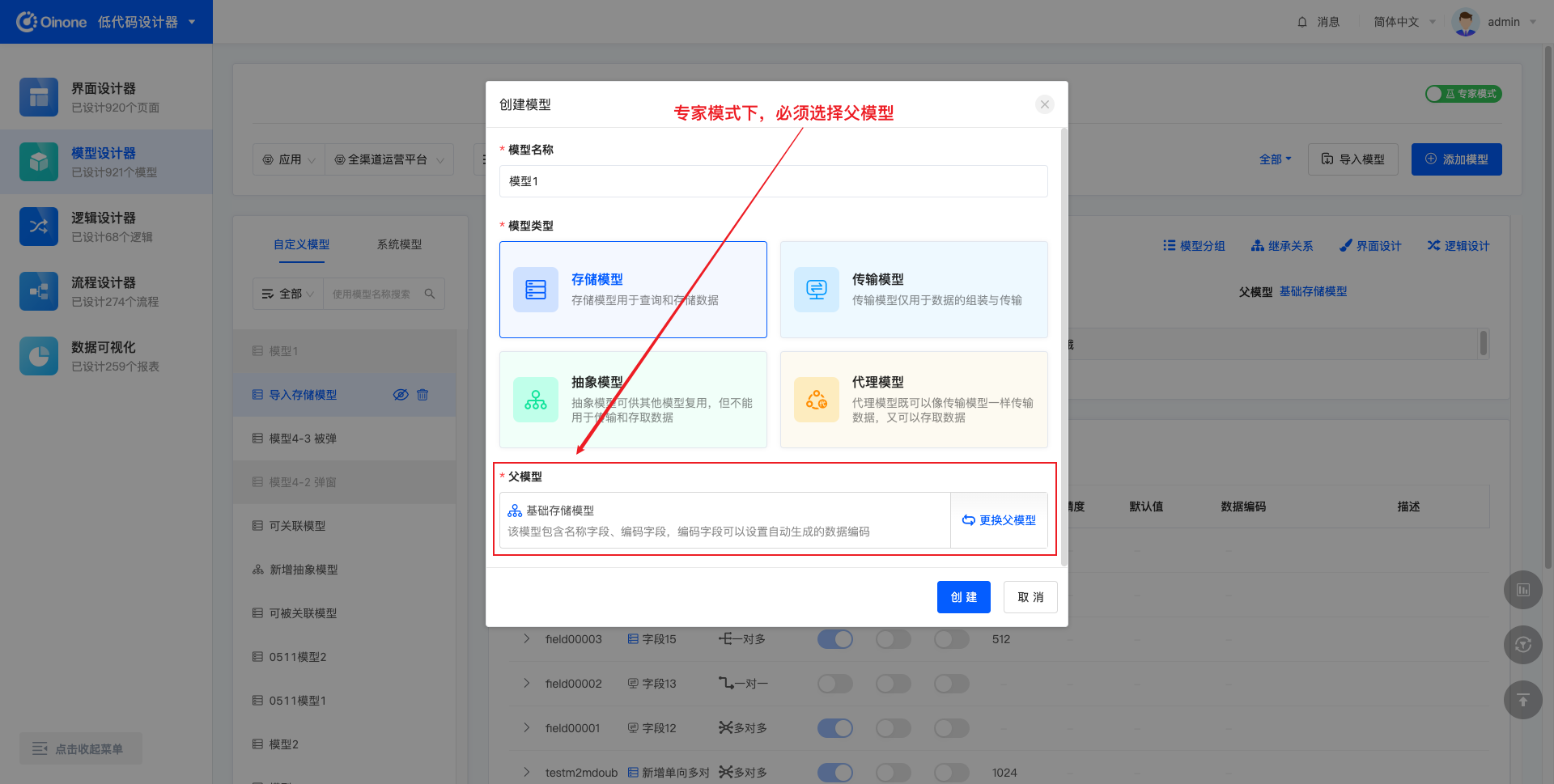
添加模型时,需要选择父模型,其中,经典模式下,无需且不展示父模型;专家模式下,必须选择父模型。
- 存储模型的父模型,默认是“基础存储模型”,可选项为可见的抽象模型和存储模型。
- 传输模型的父模型,默认是“基础存储模型”,可选项为可见的传输模型。
- 抽象模型的父模型,默认是“基础存储模型”,可选项为可见的抽象模型。
- 代理模型的父模型,无默认值,可选项为可见的存储模型和代理模型。
4.8 编辑模型
创建成功的模型,可以对其进行编辑,但只有部分信息支持编辑。
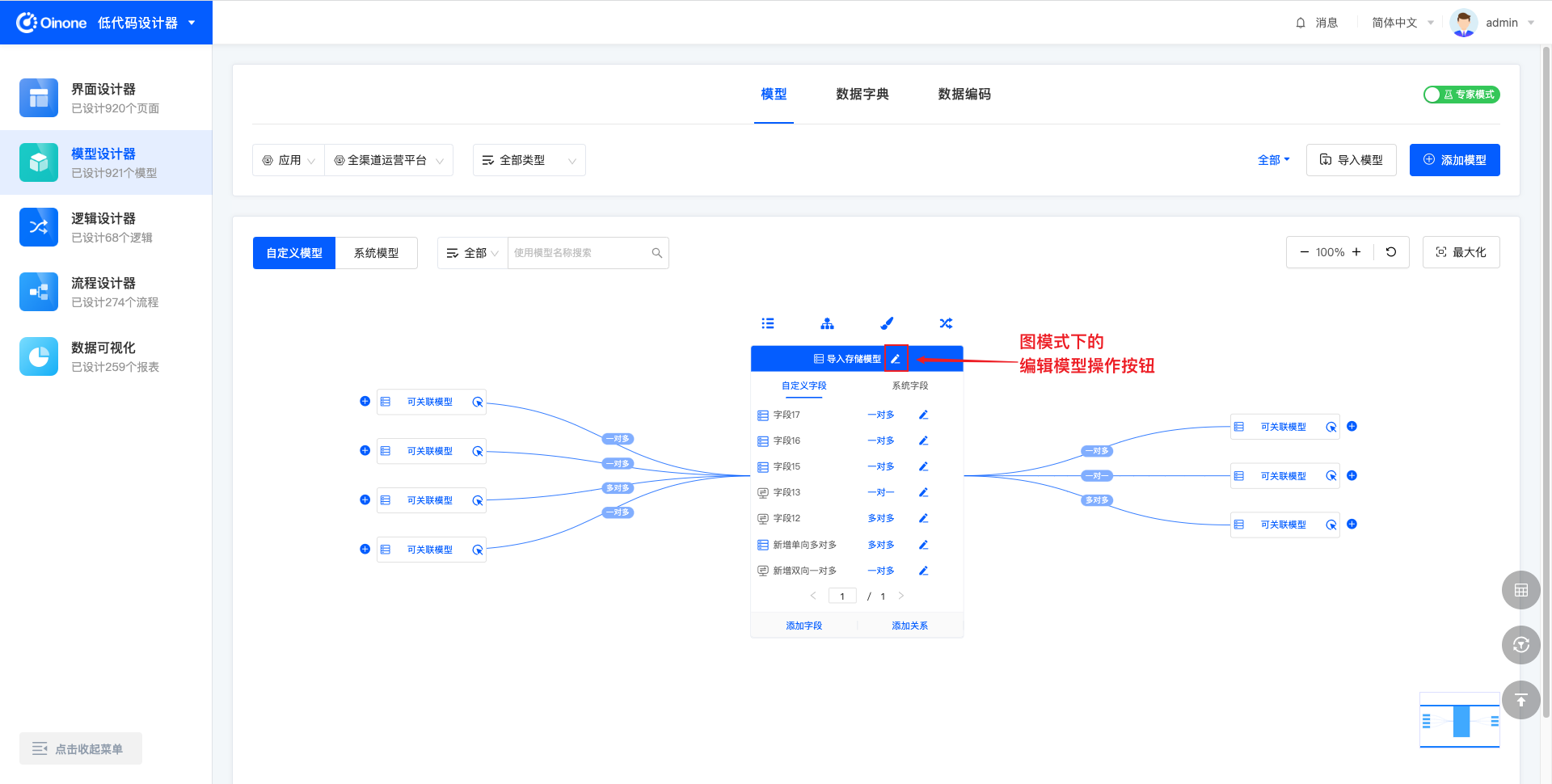
4.8.1 图模式编辑模型
图模式下,点击模型标题右侧的「编辑模型」按钮,即可在右侧弹出的抽屉中编辑模型信息。
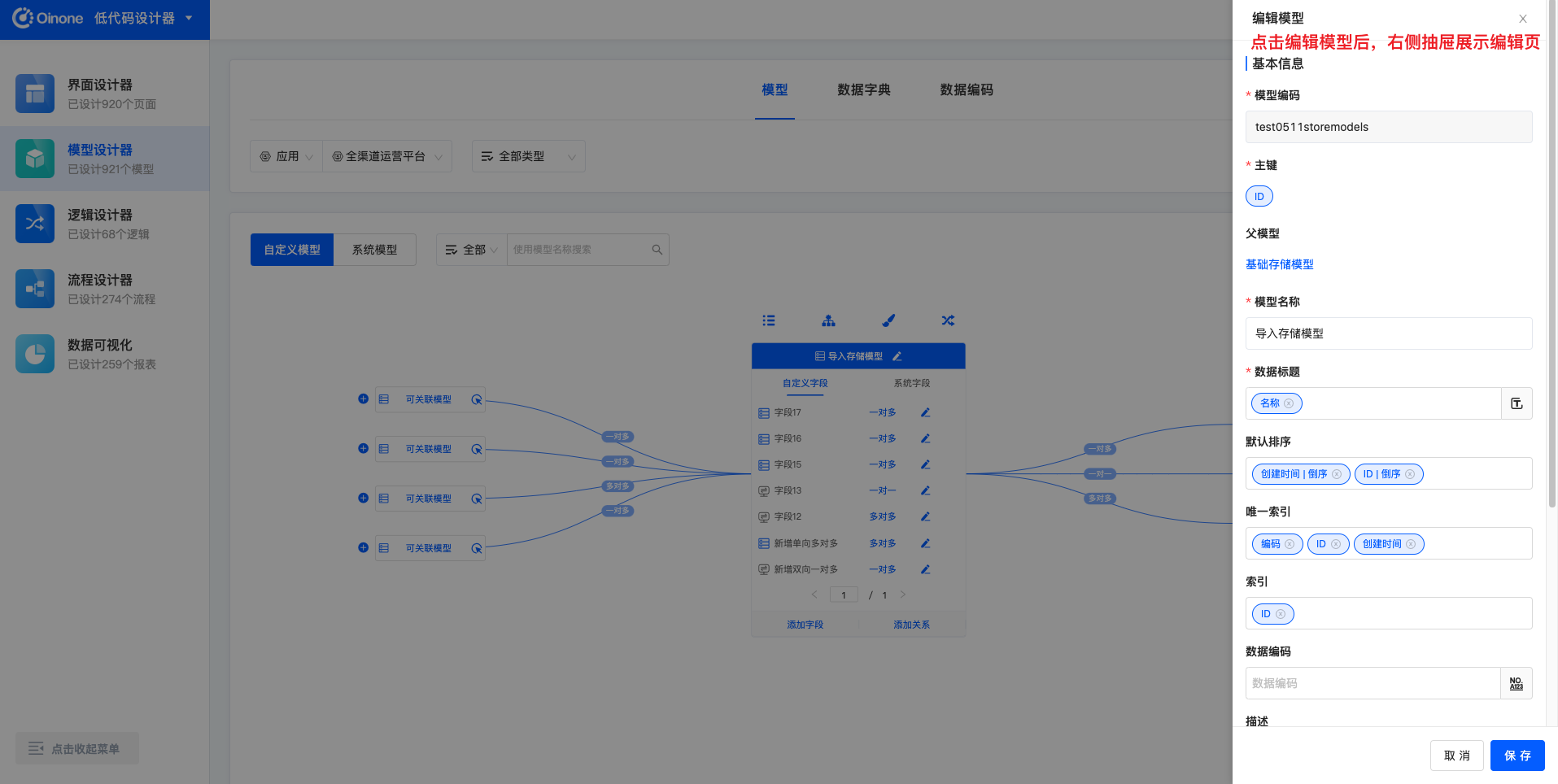
4.8.2 表模式编辑模型
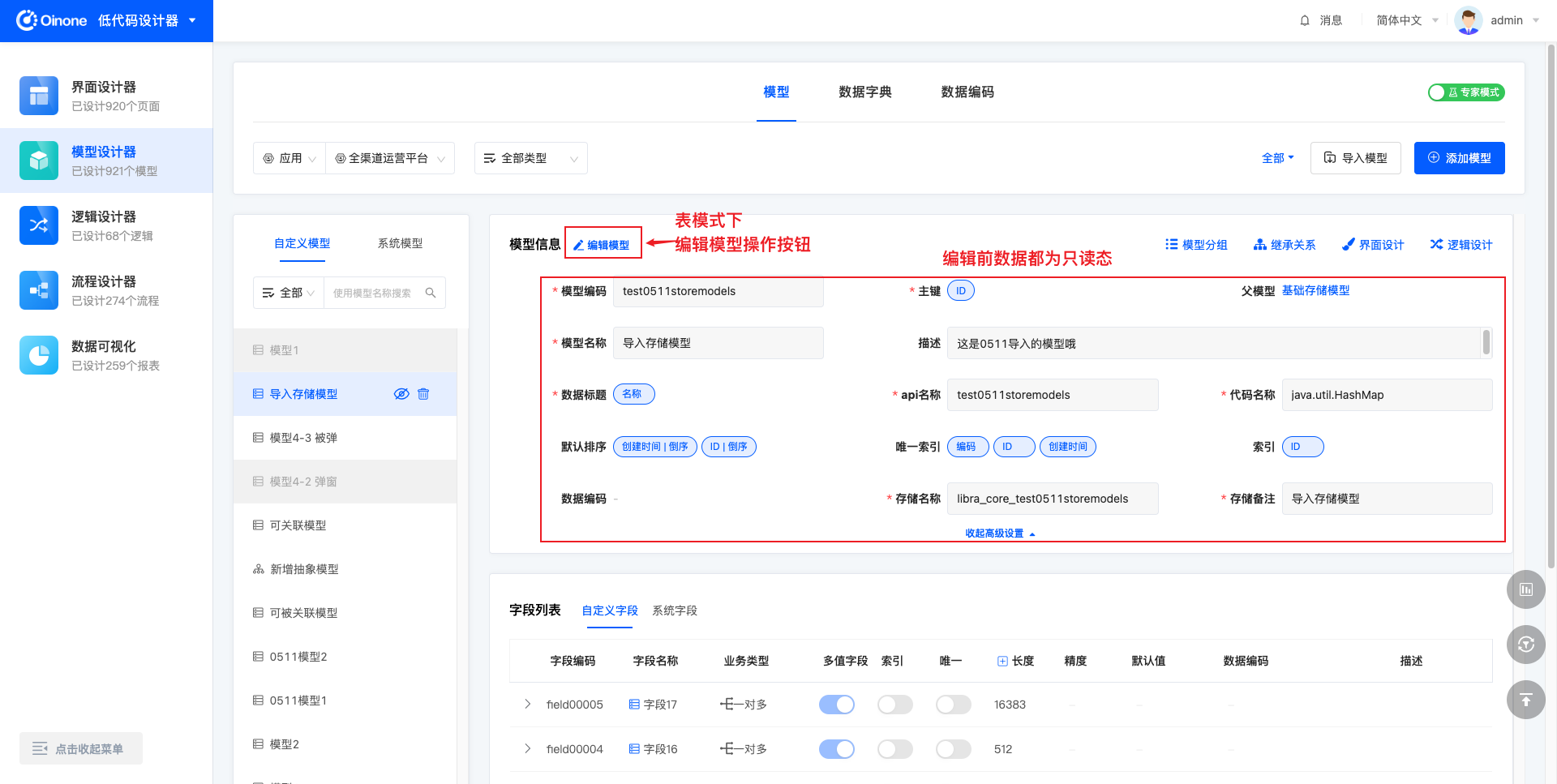
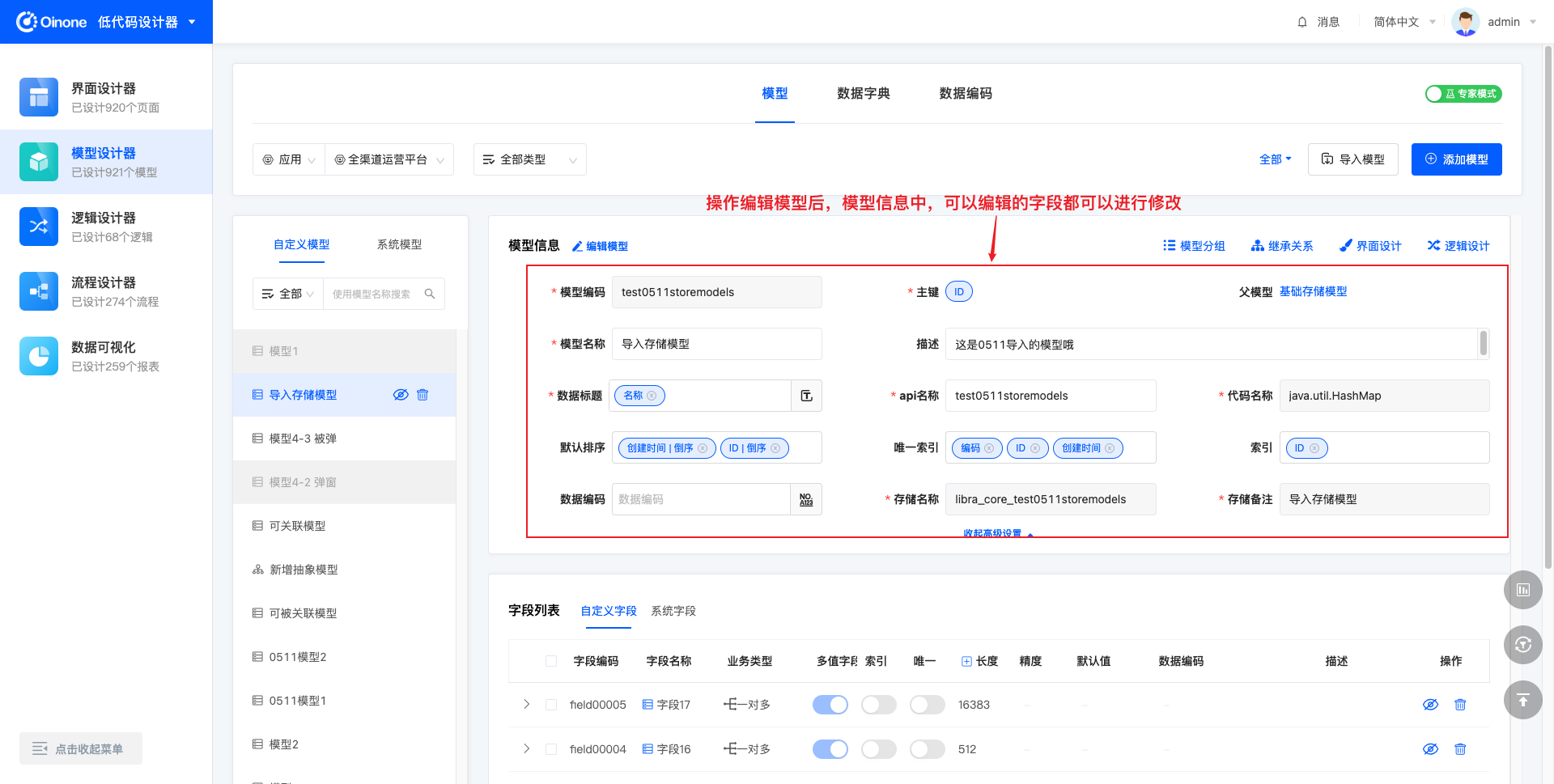
表模式下,点击模型信息标题右侧的「编辑模型」按钮,下方模型信息中可以被编辑修改的字段即由只读变为可编辑。
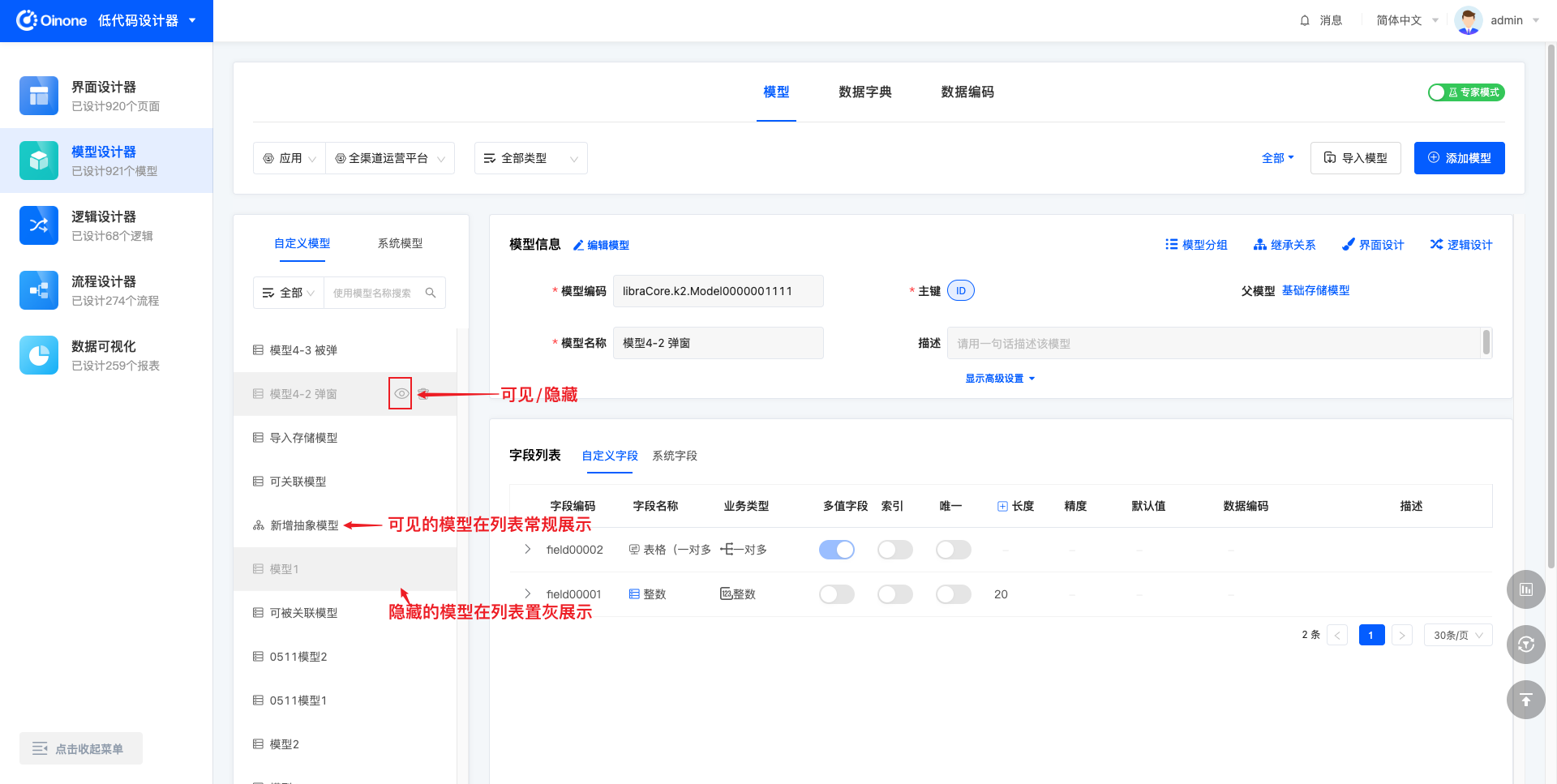
4.9 隐藏/可见模型
对于暂时不使用的模型,可以进行隐藏(隐藏后可再设置可见)的操作。
在其他设计器需要选择模型使用时,隐藏的模型将不被展示。对隐藏的模型再次操作可见后,即可选择到。
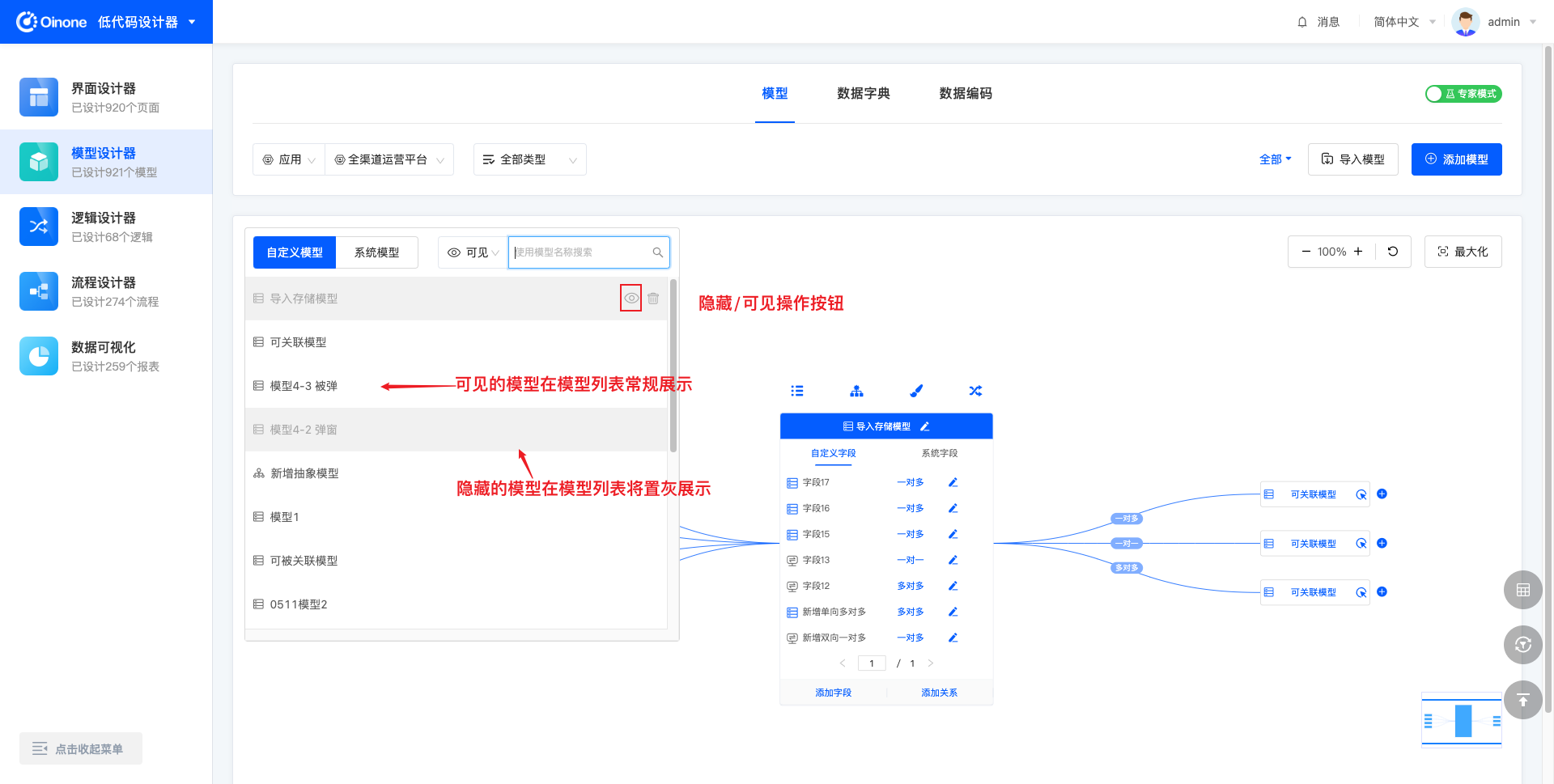
4.9.1 图模式隐藏/可见模型
图模式下,展开模型列表,模型列表中每个模型所在行的右侧,可点击隐藏/可见图标,以隐藏/可见该模型。
可见的模型常规展示,无特殊标识;隐藏后的模型在列表中将置灰展示。
4.9.1 表模式隐藏/可见模型
表模式下,模型信息左侧的模型列表中每个模型所在行的右侧,可点击隐藏/可见图标,以隐藏/可见该模型。
可见的模型常规展示,无特殊标识;隐藏后的模型在列表中将置灰展示。
4.10 删除模型
不再使用模型可以进行删除,删除时需要确保模型没有被其他设计器引用。删除成功后的模型将不在列表展示,且不可恢复,请谨慎操作。
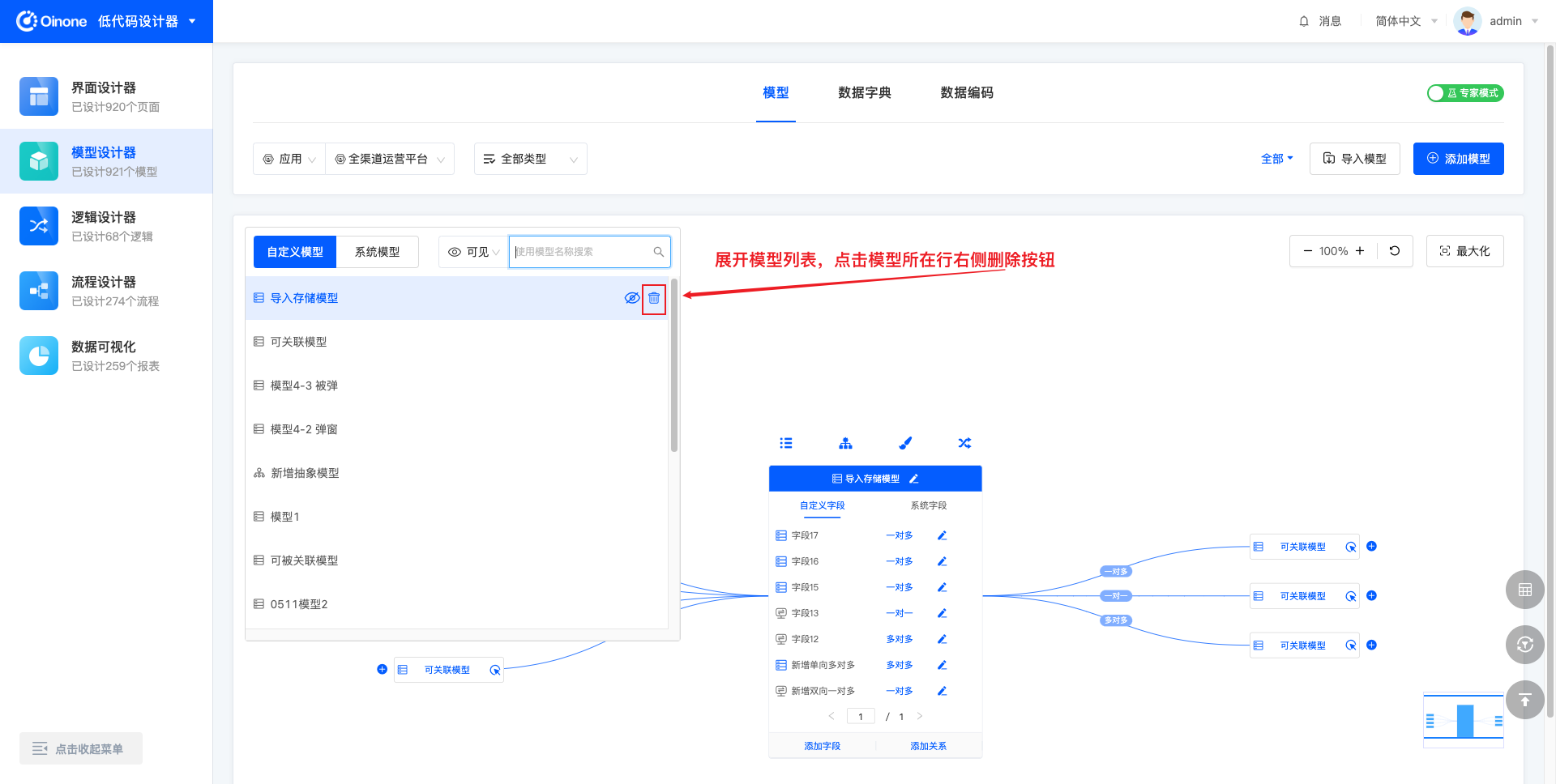
4.10.1 图模式删除模型
图模式下,展开模型列表,模型列表中每个模型所在行的右侧,可点击删除图标,以删除该模型。
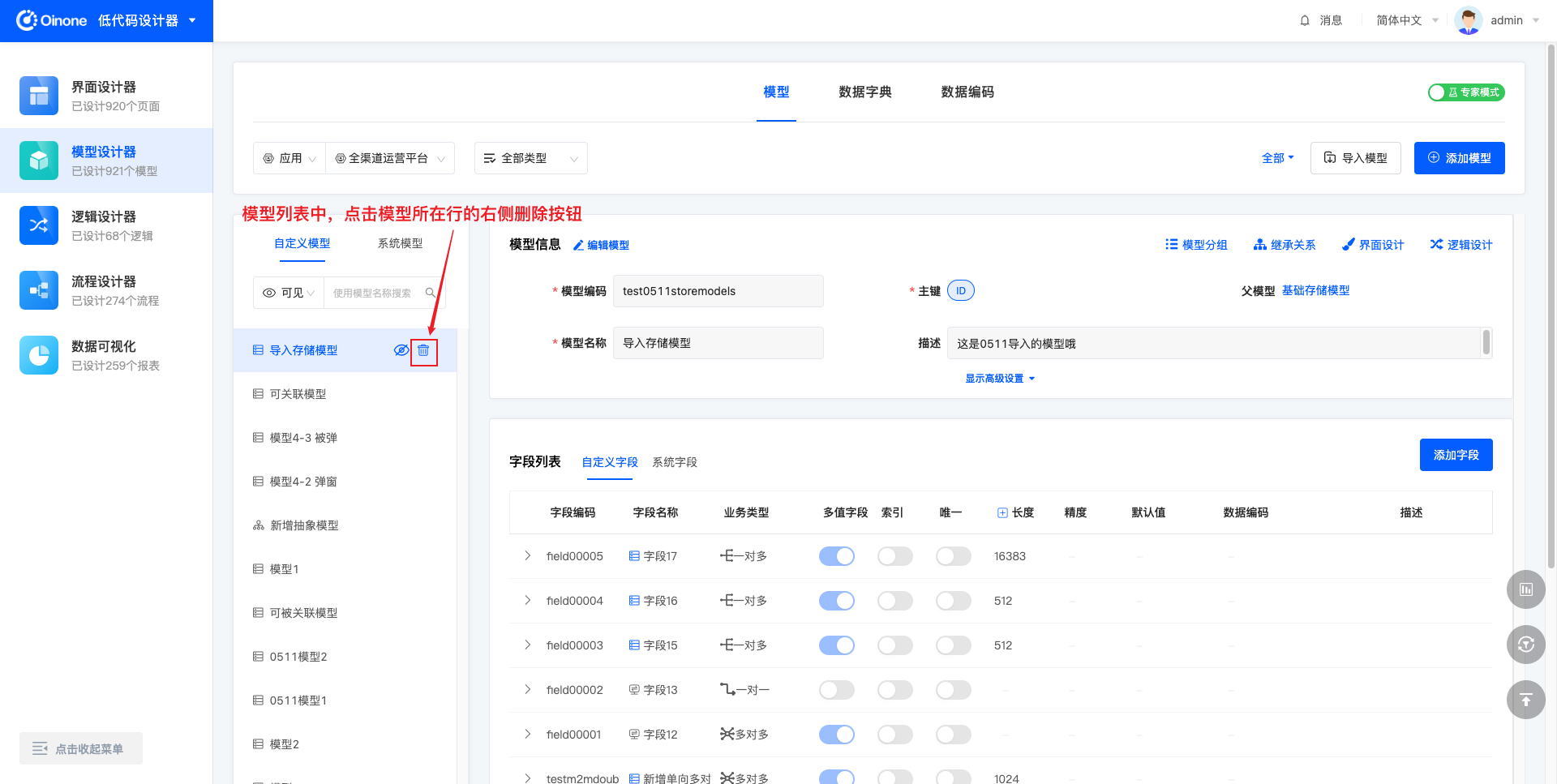
4.10.2 表模式删除模型
表模式下,模型信息左侧的模型列表中每个模型所在行的右侧,可点击删除图标,以删除该模型。
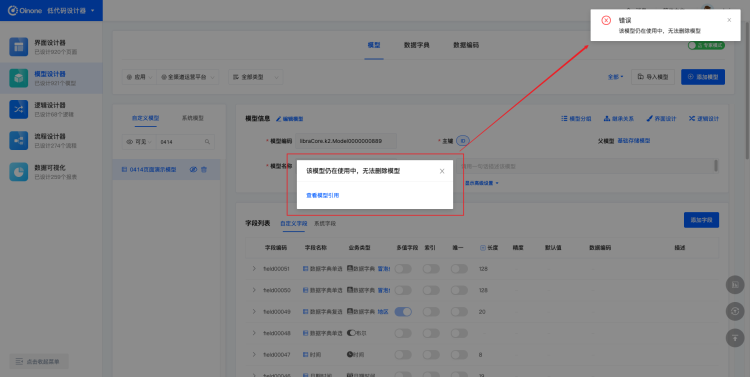
4.10.3 存在引用关系
如果删除的模型存在引用关系,则无法删除,并提示模型仍在使用。点击提示中的「查看模型引用」,可以查看这个模型引用情况。
5. 字段管理
在模型中,可以对字段进行增删改查等基础管理操作。
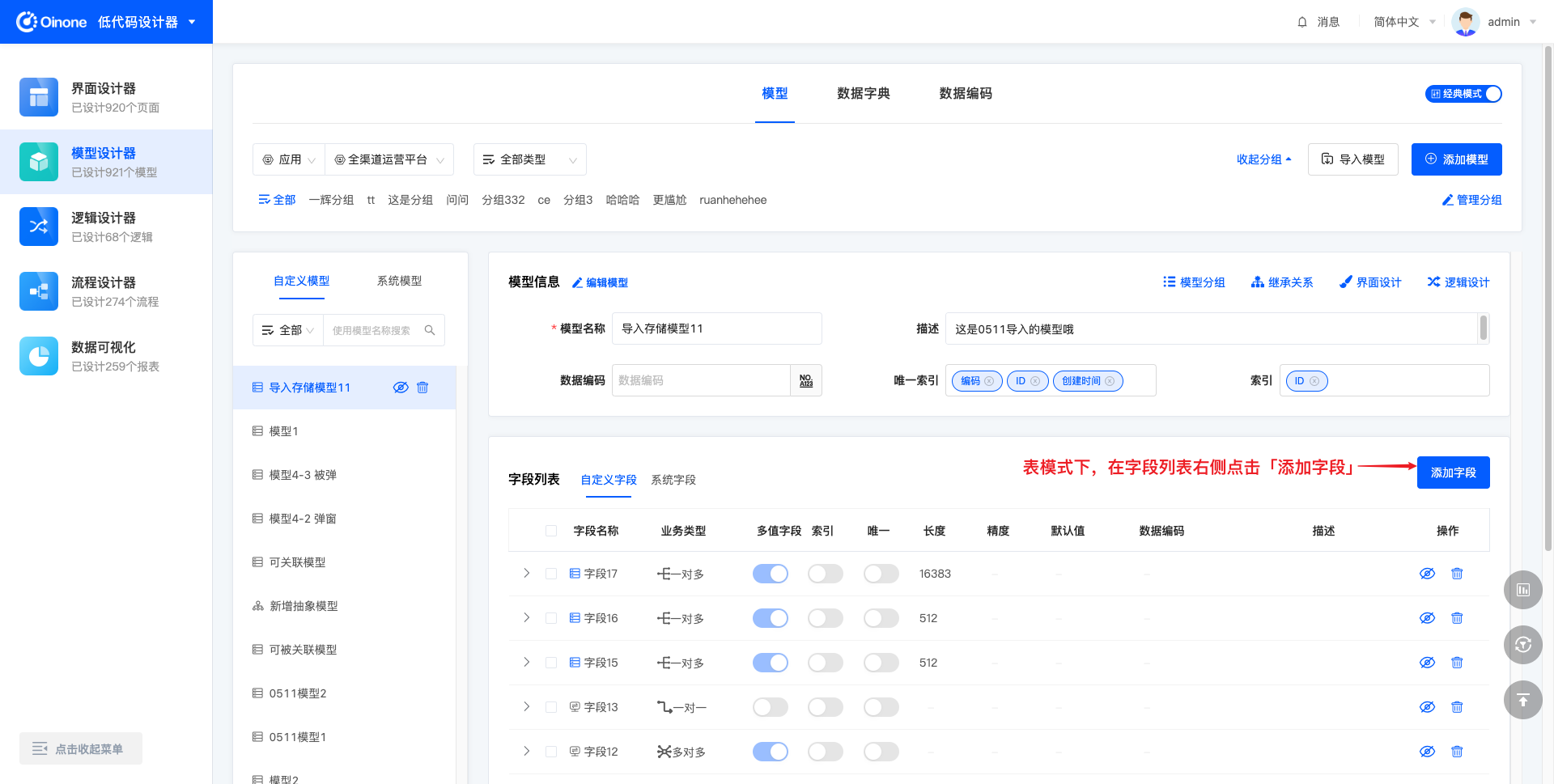
5.1 添加字段
每个模型中可以添加多个字段,手动添加的字段都为自定义字段。点击「添加字段」,右侧出现字段信息填写的抽屉,抽屉中包括:字段名称、字段业务类型、存储类型、长度(部分业务类型的字段无长度设置)。填写并保存成功后,字段即创建成功。
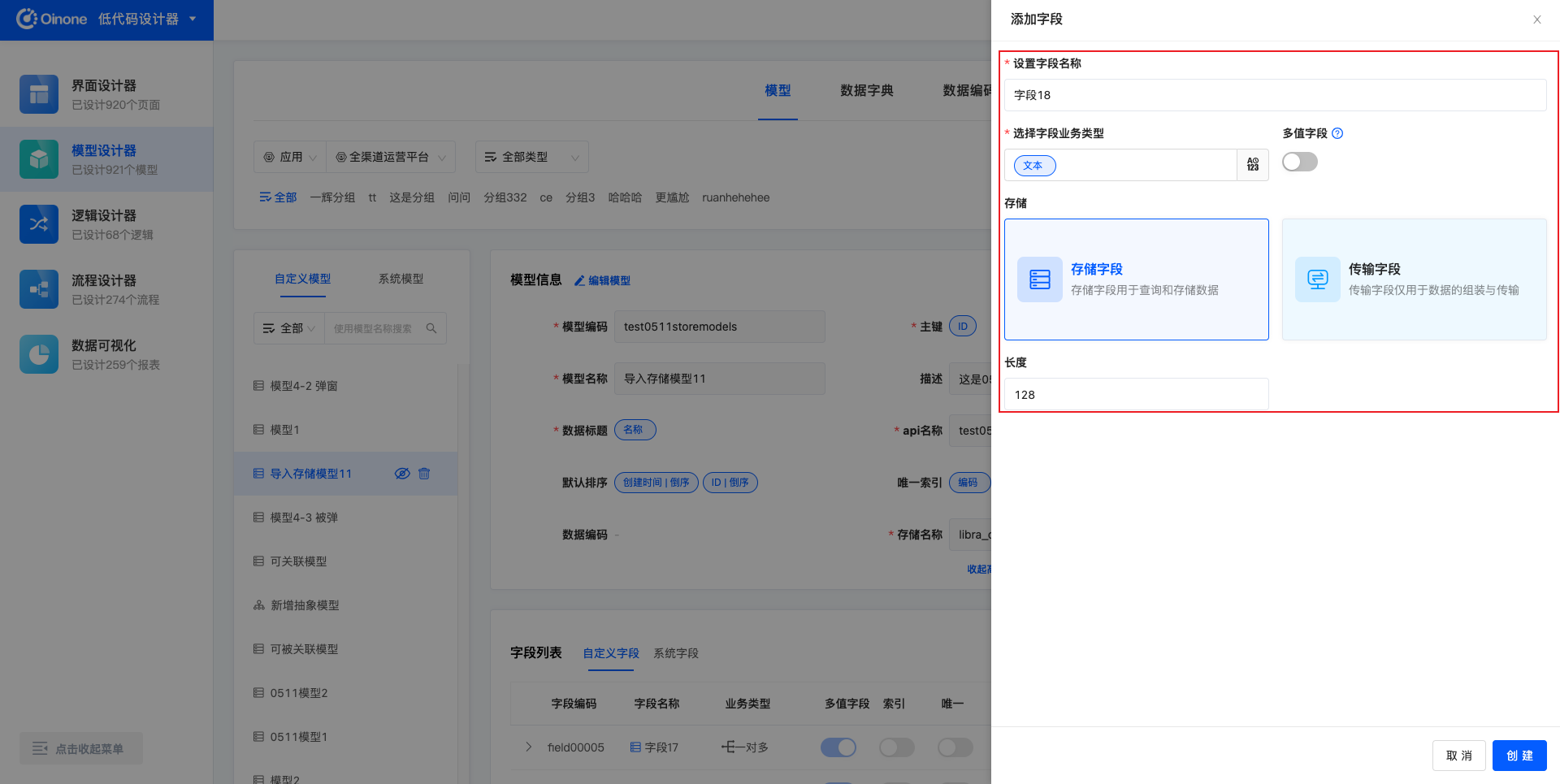
5.1.1 图模式添加字段
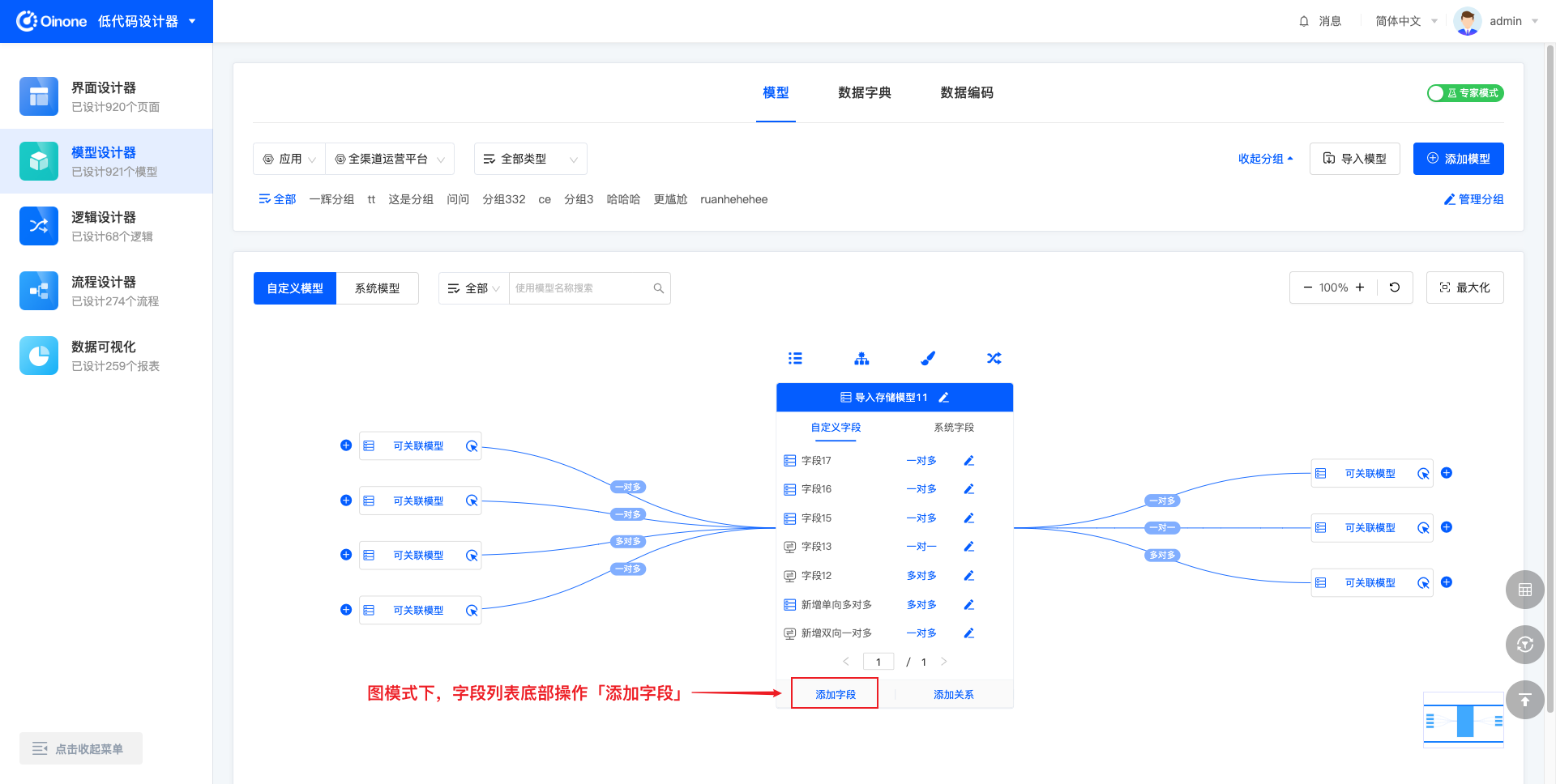
5.1.2 表模式添加字段
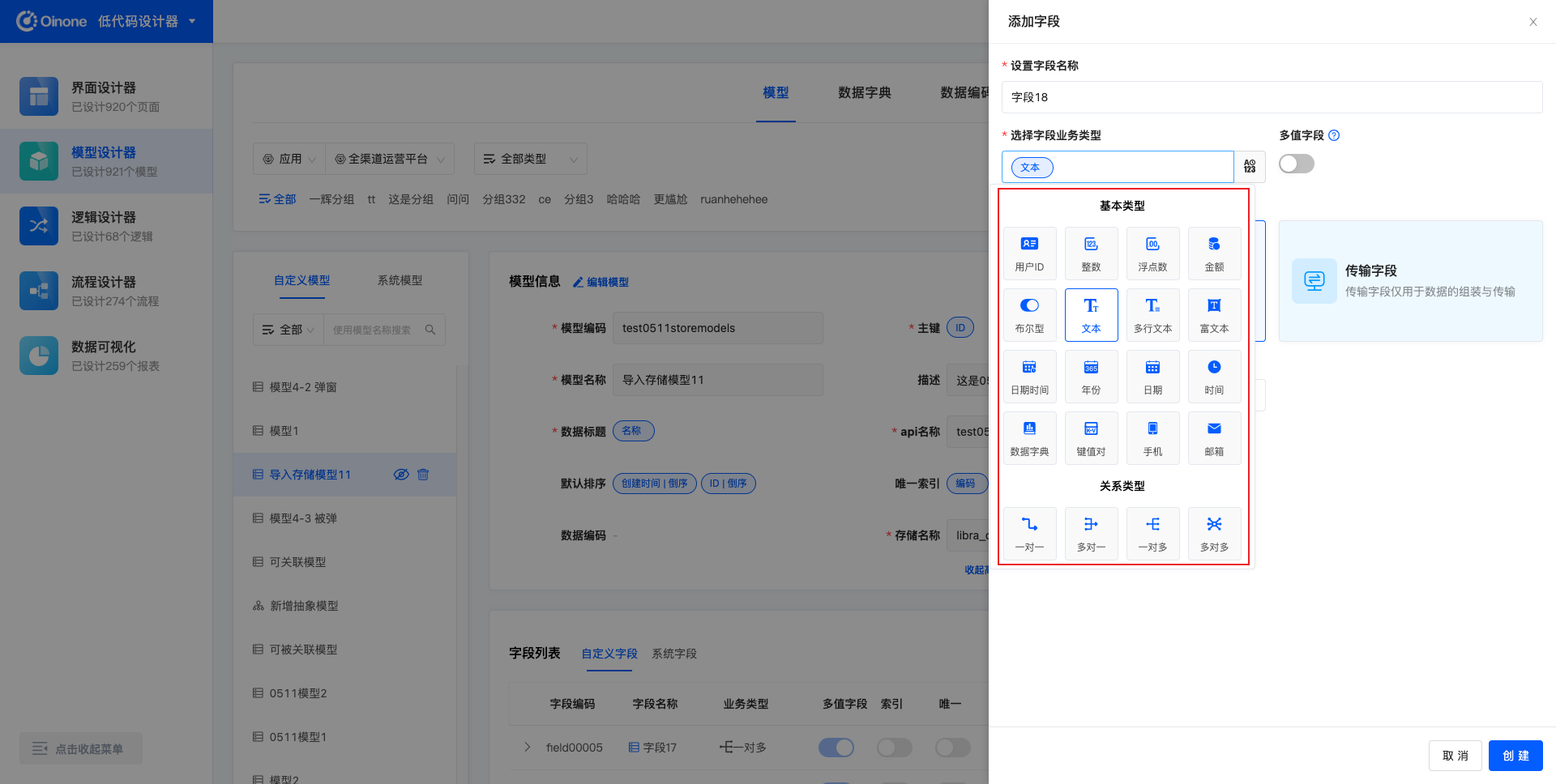
5.1.3 字段业务类型
添加字段时,支持设置16种基础类型的字段、支持设置4种关系类型字段。
- 基础类型:用户ID、整数、浮点数、金额、布尔型、文本、多行文本、富文本、日期时间、年份、日期、时间、数据字典、键值对、手机、邮箱;
- 字段为数据字典时需要选择一个数据字典。
- 关系类型:一对一、多对一、一对多、多对多
- 字段为关系类型字段时需要选择关联的模型。
5.1.4 多值字段
多值字段表示该字段可以存储或传输多个该业务类型的数据,非多值字段只能存储或传输单个该业务类型的数据。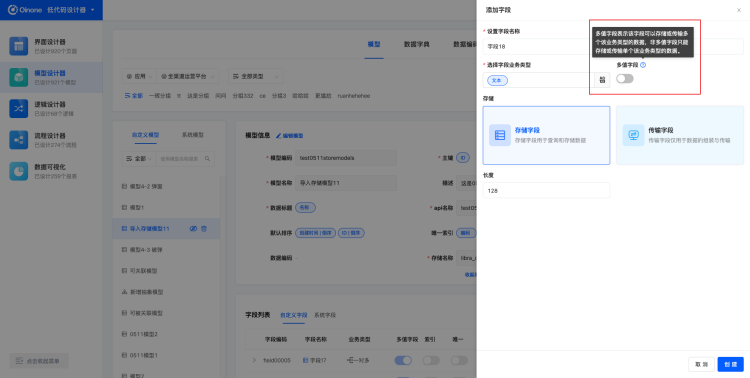
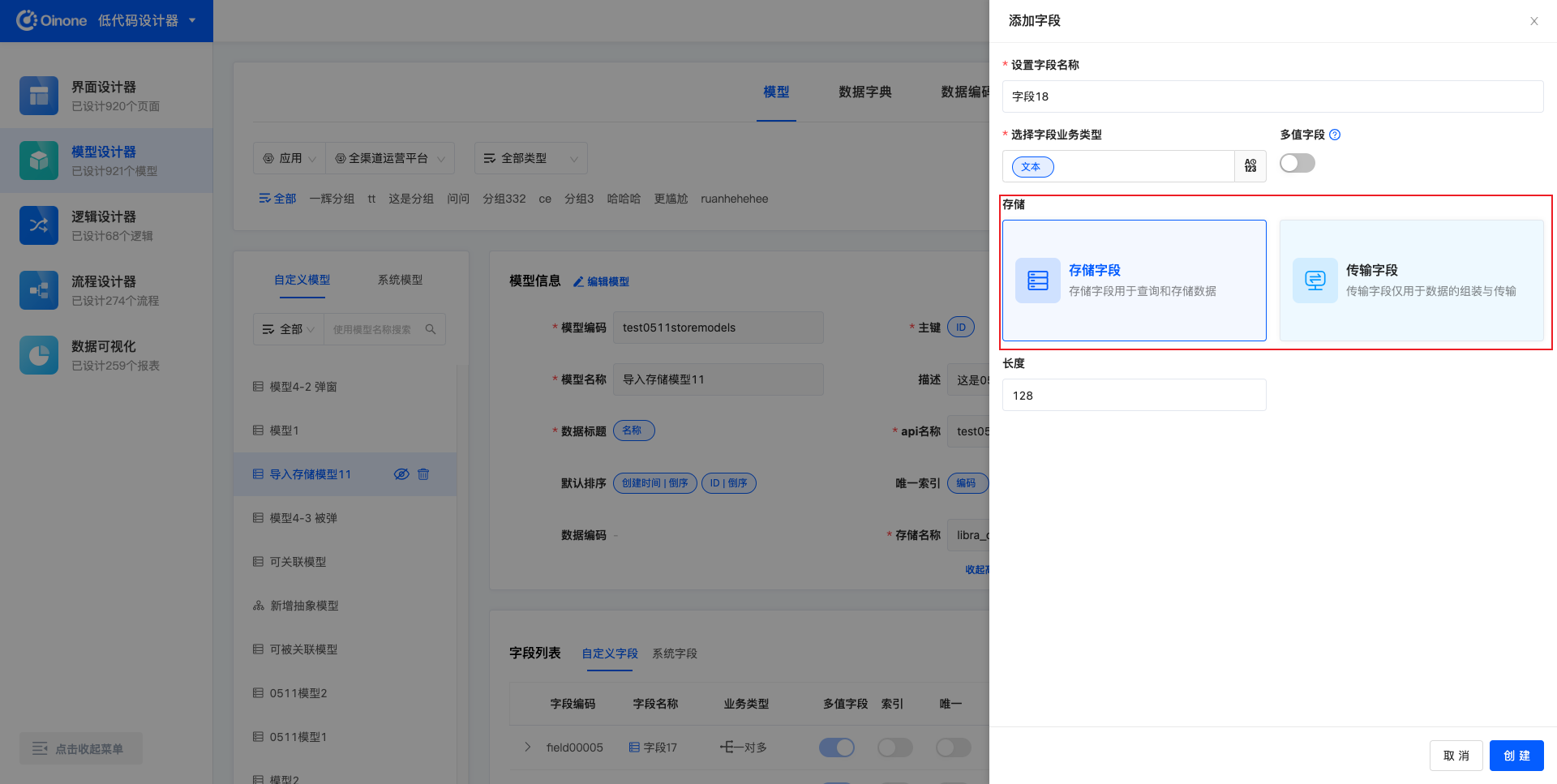
5.1.5 存储类型
设置字段的存储类型:存储字段、传输字段
- 存储字段:用于查询和存储字段
- 传输字段:仅用于数据的组装与存储
5.2 编辑字段
创建成功的字段,可以对其进行编辑,但只有部分信息支持编辑。
- 字段长度和精度只能由小往大改,不能由大往小改。
- 关联关系的关联模型、关联字段、关系字段、中间模型,中间关系字段、中间关联字段、支持关联查询不可修改。
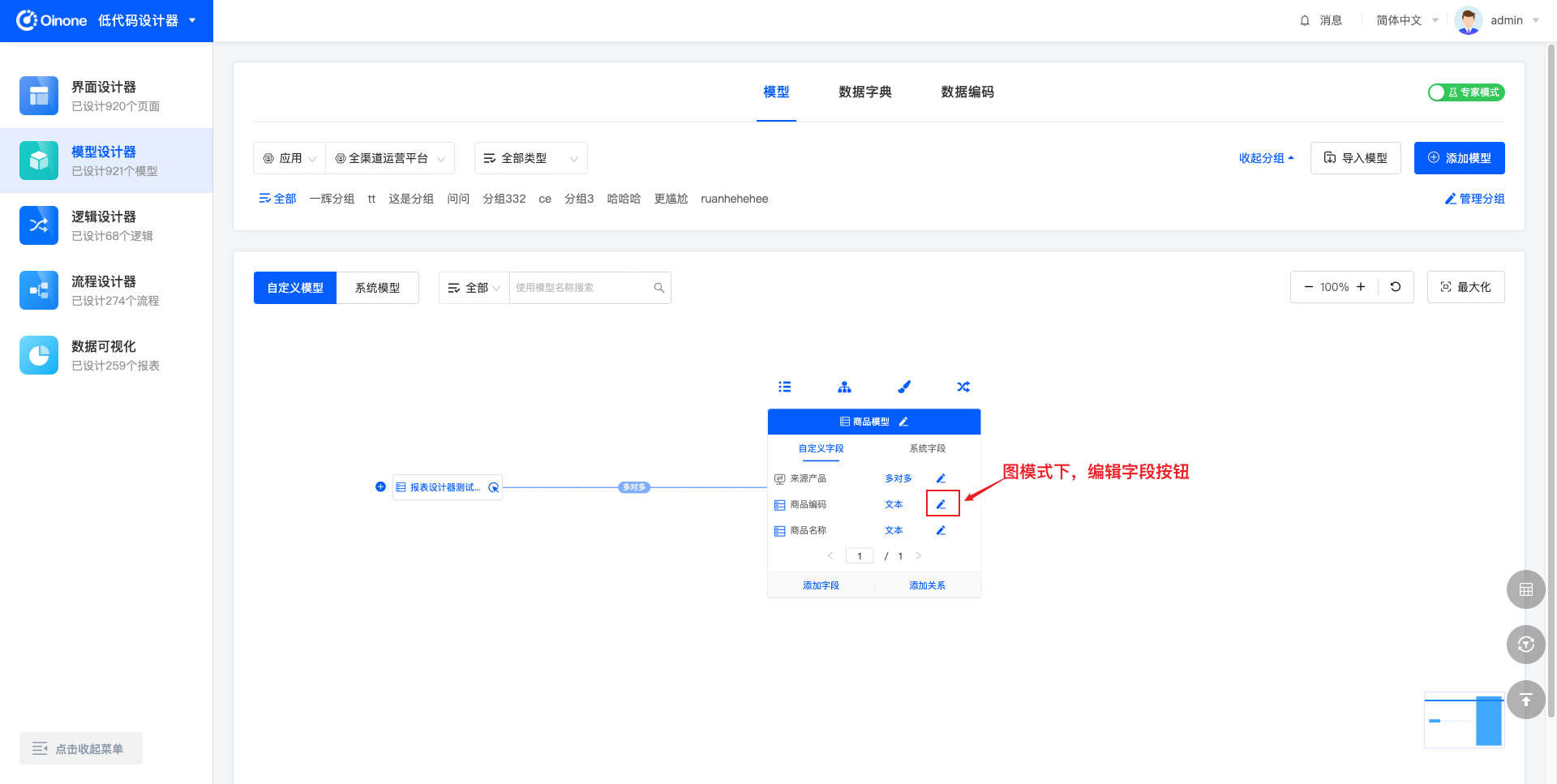
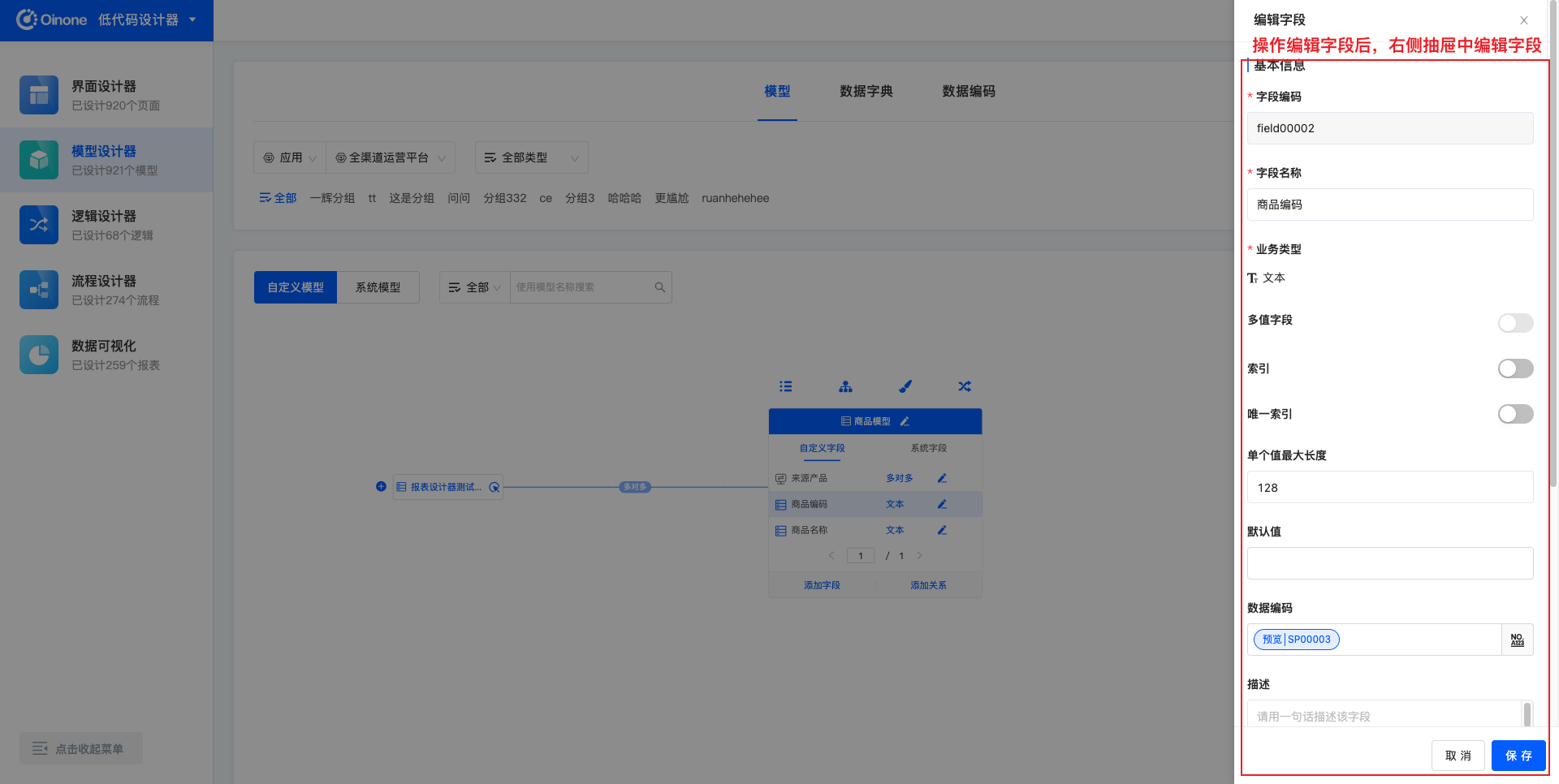
5.2.1 图模式编辑字段
图模式下,点击字段列表所在行右侧的「编辑字段」按钮,即可在右侧弹出的抽屉中编辑字段信息。
5.2.2 表模式编辑字段
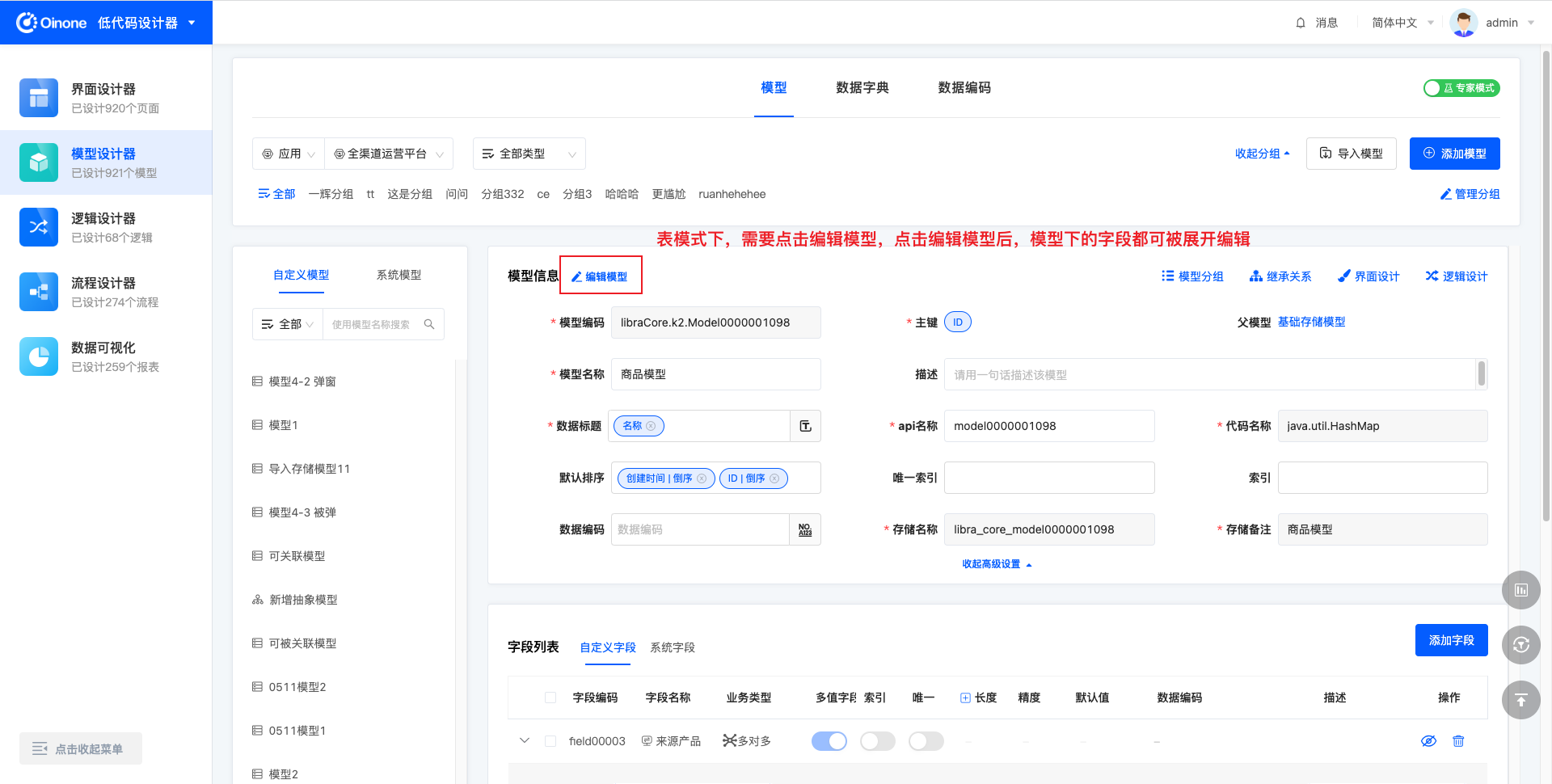
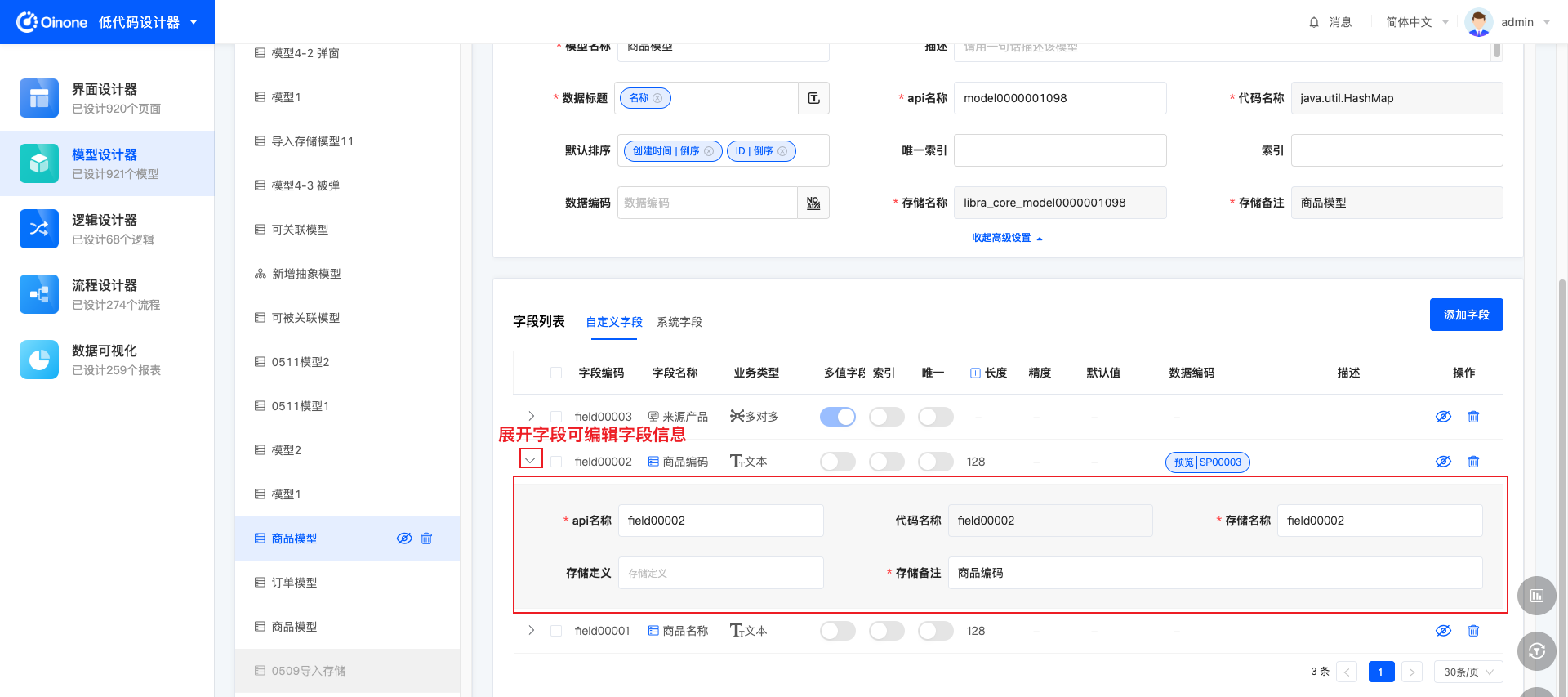
表模式下,点击模型信息标题右侧的「编辑模型」按钮,下方模型中的字段都可以被展开编辑。
5.3 隐藏/可见字段
对于暂时不使用的字段,可以进行隐藏(隐藏后可再设置可见)的操作。
在其他设计器需要选择字段使用时,隐藏的字段将不被展示。对隐藏的字段再次操作可见后,即可选择到。
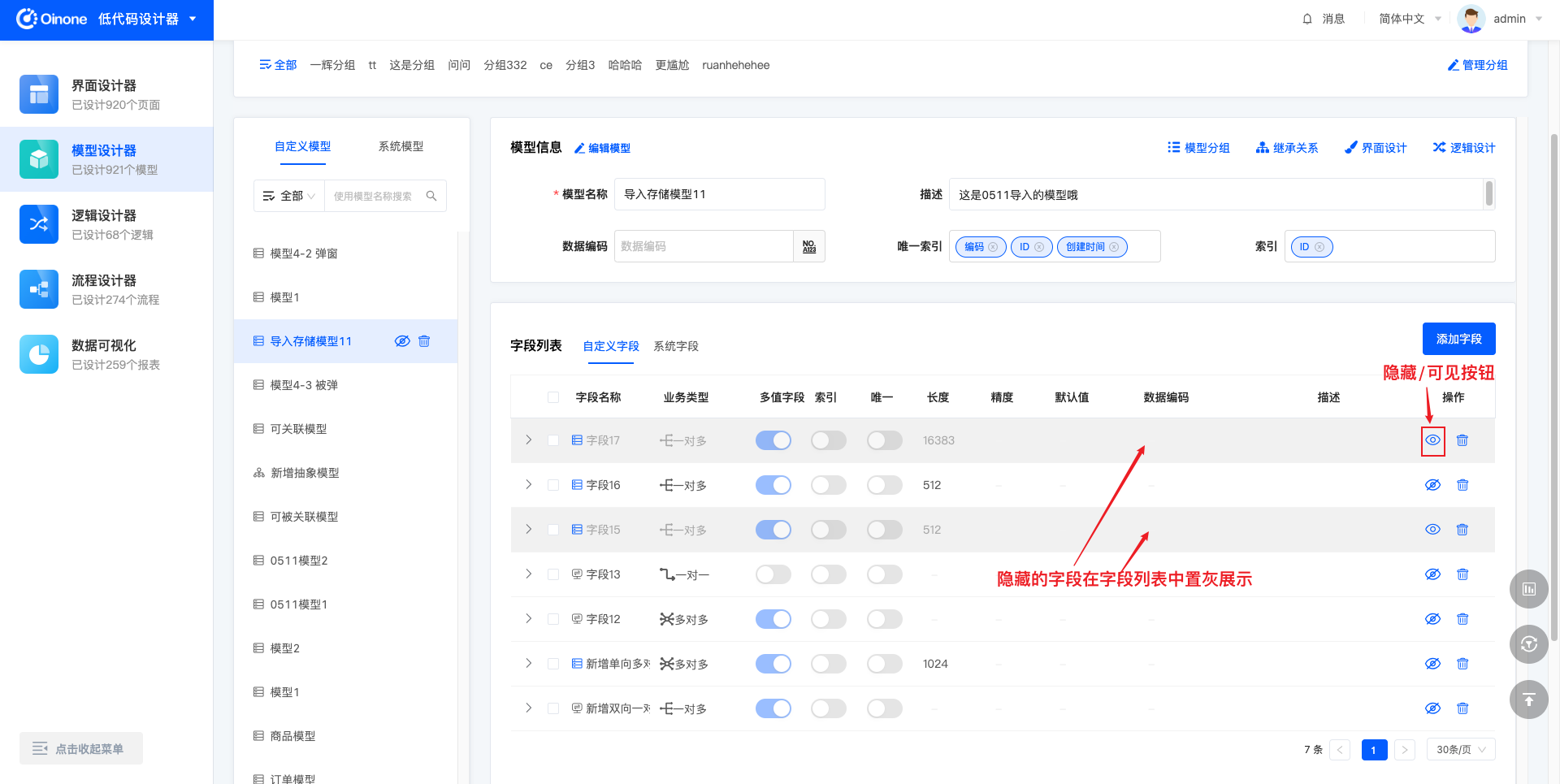
5.3.1 表模式隐藏/可见字段
表模式下,编辑模型时,字段所在行右侧可以操作隐藏/可见。
可见的字段常规展示,无特殊标识;隐藏的字段在列表中将置灰展示。
5.4 删除字段
不再使用的字段可以进行删除,删除时需要确保字段没有被其他设计器引用。删除成功后的字段将不在列表展示,且不可恢复,请谨慎操作。
- 字段的引用分为模型内引用和模型间引用
- 模型内引用包括:数据标题、关联关系、可选项条件、关联条件、关联函数;
- 模型间引用包括: 模型、页面、逻辑、流程、图表。
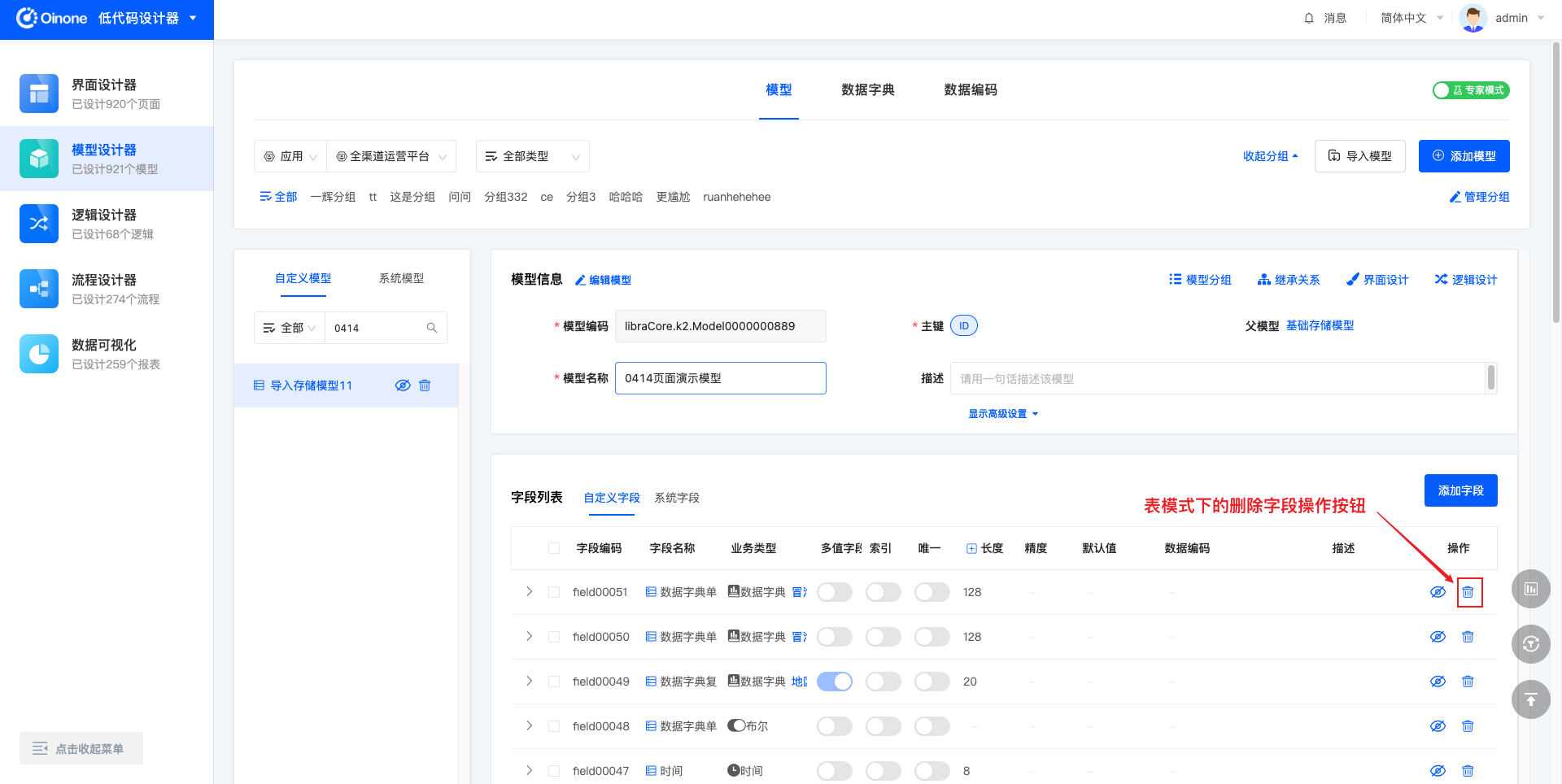
5.4.1 表模式删除字段
表模式下,编辑模型时,字段所在行右侧可以操作删除。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9399.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验