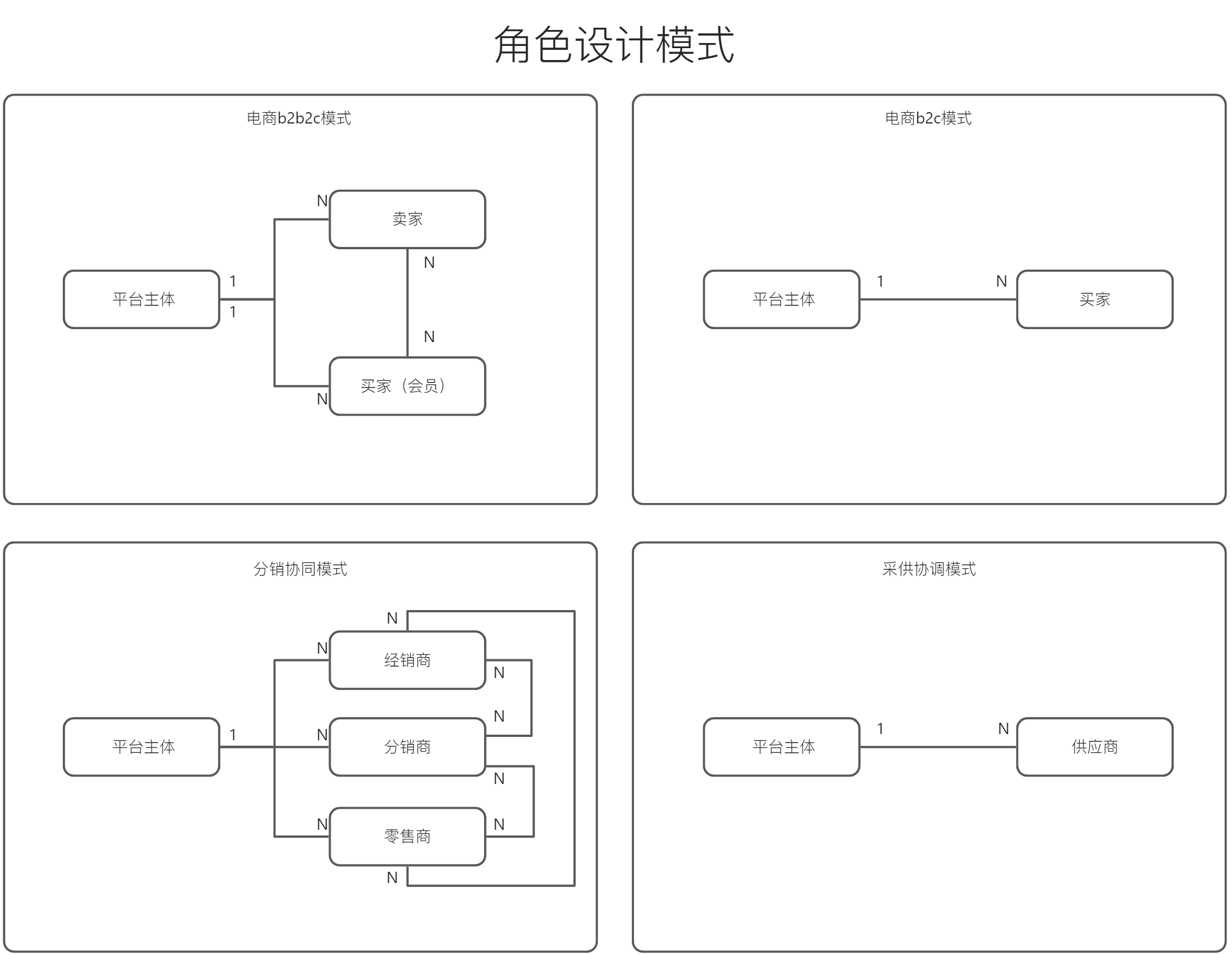
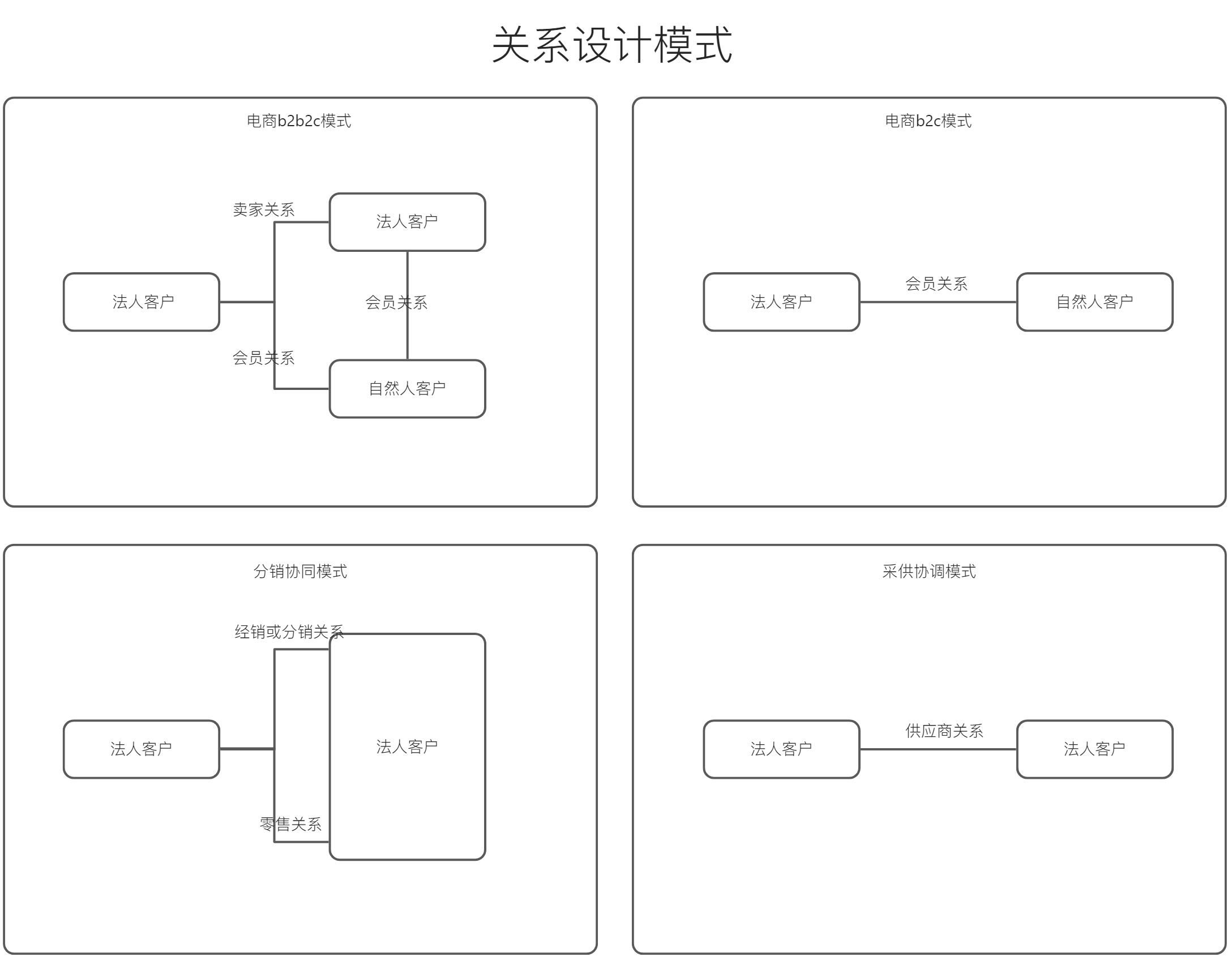
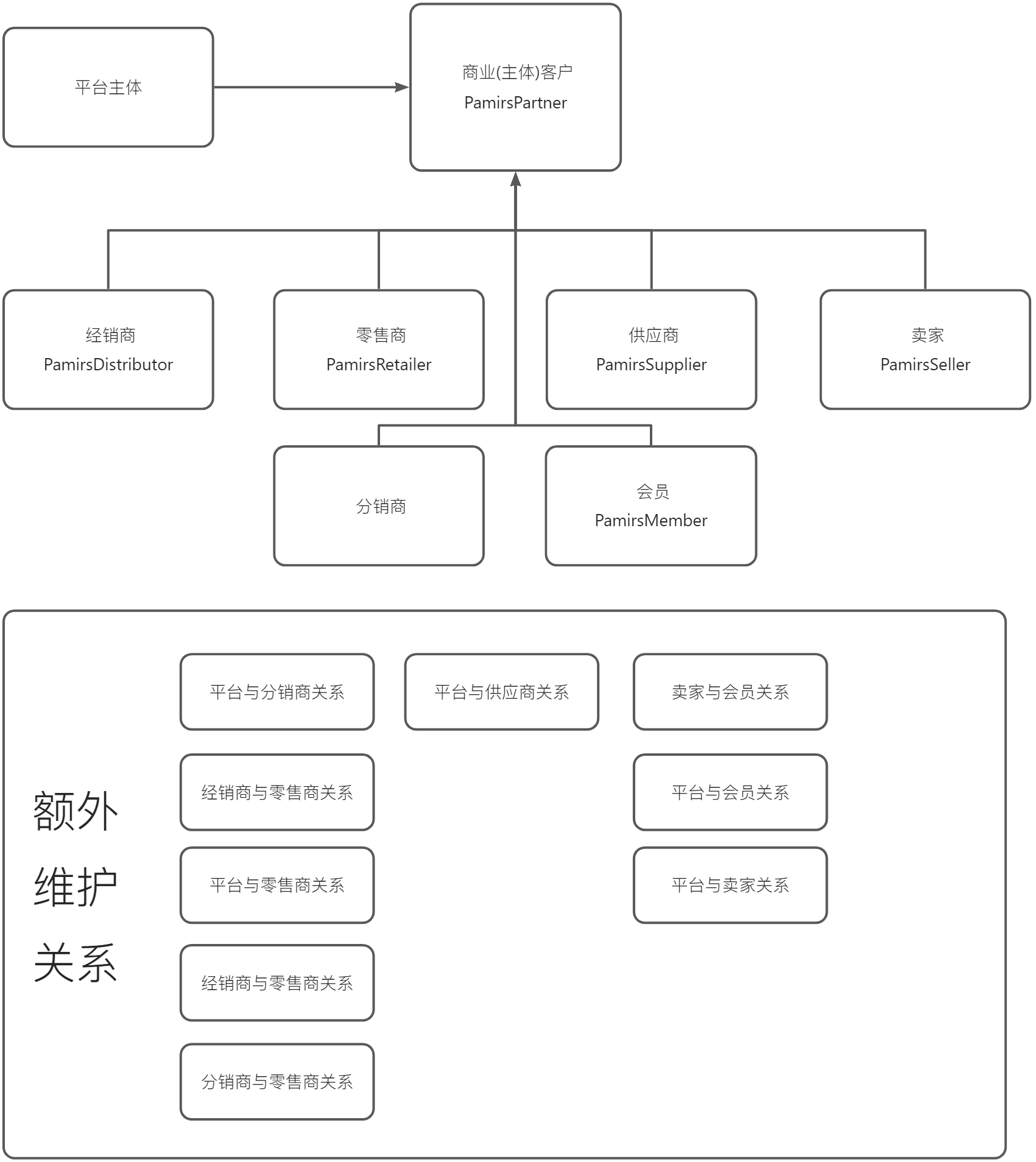
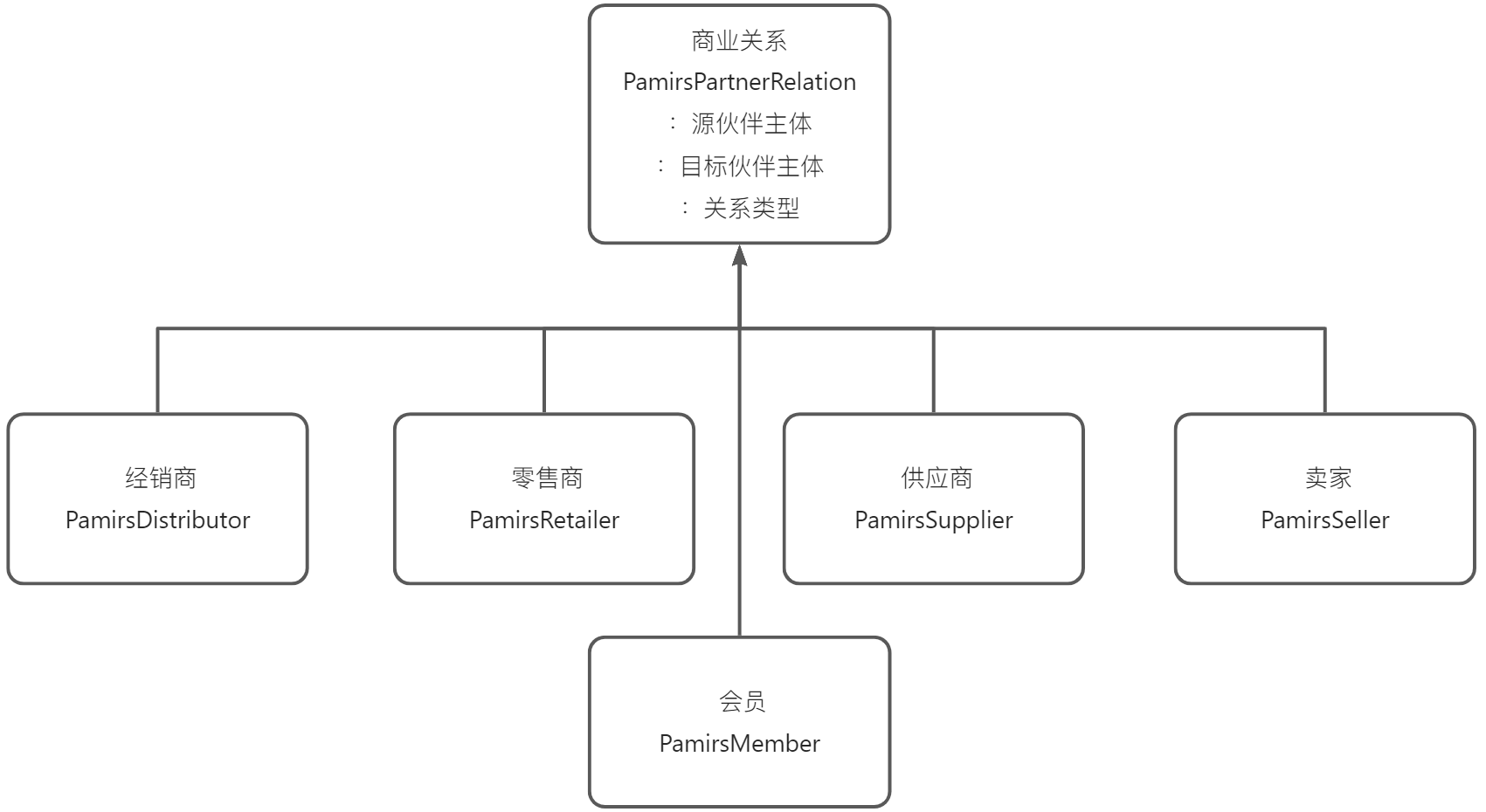
本文核心是带大家全面了解oinone的序列方式,包括支持的序列化类型、注意点、如果新增客户化序列化方式以及字段默认值的反序列化。 一、数据存储的序列化 (举例) 使用@Field注解的serialize属性来配置非字符串类型属性的序列化与反序列化方式,最终会以序列化后的字符串持久化到存储中。 ### Step1 新建PetItemDetail模型、并为PetItem添加两个字段 PetItemDetail继承TransientModel,增加两个字段,分别为备注和备注人 package pro.shushi.pamirs.demo.api.tmodel; import pro.shushi.pamirs.meta.annotation.Field; import pro.shushi.pamirs.meta.annotation.Model; import pro.shushi.pamirs.meta.base.TransientModel; import pro.shushi.pamirs.user.api.model.PamirsUser; @Model.model(PetItemDetail.MODEL_MODEL) @Model(displayName = "商品详情",summary = "商品详情",labelFields = {"remark"}) public class PetItemDetail extends TransientModel { public static final String MODEL_MODEL="demo.PetItemDetail"; @Field.String(min = "2",max = "20") @Field(displayName = "备注",required = true) private String remark; @Field(displayName = "备注人",required = true) private PamirsUser user; } 图3-3-7-1 PetItemDetail继承TransientModel 修改PetItem,增加两个字段petItemDetails类型为List和tags类型为List,并设置为不同的序列化方式,petItemDetails为JSON(缺省就是JSON,可不配),tags为COMMA。同时设置 @Field.Advanced(columnDefinition = varchar(1024)),防止序列化后存储过长 package pro.shushi.pamirs.demo.api.model; import pro.shushi.pamirs.demo.api.tmodel.PetItemDetail; import pro.shushi.pamirs.meta.annotation.Field; import pro.shushi.pamirs.meta.annotation.Model; import pro.shushi.pamirs.meta.enmu.NullableBoolEnum; import java.math.BigDecimal; import java.util.List; @Model.model(PetItem.MODEL_MODEL) @Model(displayName = "宠物商品",summary="宠物商品",labelFields = {"itemName"}) public class PetItem extends AbstractDemoCodeModel{ public static final String MODEL_MODEL="demo.PetItem"; @Field(displayName = "商品名称",required = true) private String itemName; @Field(displayName = "商品价格",required = true) private BigDecimal price; @Field(displayName = "店铺",required = true) @Field.Relation(relationFields = {"shopId"},referenceFields = {"id"}) private PetShop shop; @Field(displayName = "店铺Id",invisible = true) private Long shopId; @Field(displayName = "品种") @Field.many2one @Field.Relation(relationFields = {"typeId"},referenceFields = {"id"}) private PetType type; @Field(displayName = "品种类型",invisible = true) private Long typeId; @Field(displayName = "详情", serialize = Field.serialize.JSON, store = NullableBoolEnum.TRUE) @Field.Advanced(columnDefinition = "varchar(1024)") private List<PetItemDetail> petItemDetails; @Field(displayName = "商品标签",serialize = Field.serialize.COMMA,store = NullableBoolEnum.TRUE,multi = true) @Field.Advanced(columnDefinition = "varchar(1024)") private…