
search默认查询的是模型的queryPage函数,但我们有时候需要替换调用的函数,这个特性会在下个版本支持。其核心场景为当搜索条件中有非存储字段,如果直接用queryPage函数的rsql拼接就会报错,所以非存储字段不会增加在rsql中。本文介绍一个比较友好的临时替代方案。
非存储字段条件(举例)
Step1 为PetTalent新增一个非存储字段unStore
@Field(displayName = "非存储字段测试",store = NullableBoolEnum.FALSE)
private String unStore;Step2 修改PetTalent的Table视图的Template
在标签内增加一个查询条件
<field data="unStore" />Step3 重启看效果
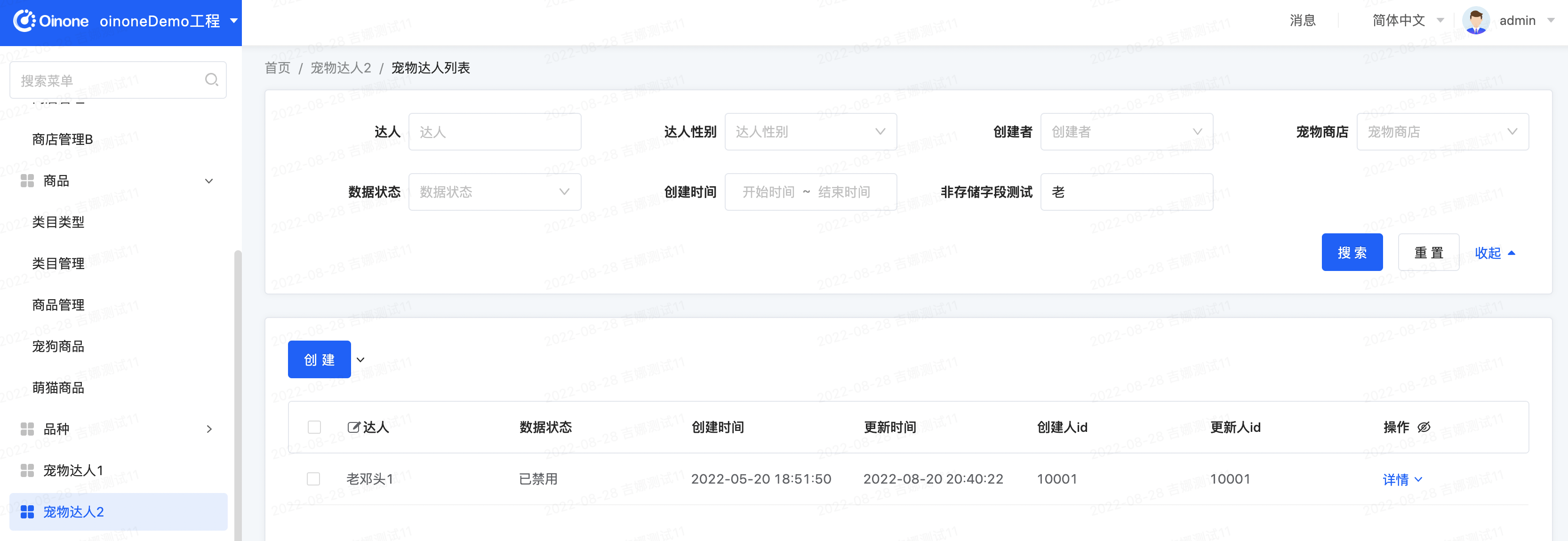
进入宠物达人列表页,在搜索框【非存储字段测试】输入查询内容,点击搜索跟无条件一致
Step4 修改PetTalentAction的queryPage方法
package pro.shushi.pamirs.demo.core.action;
…… 引入依赖类
@Model.model(PetTalent.MODEL_MODEL)
@Component
public class PetTalentAction {
……其他代码
@Function.Advanced(type= FunctionTypeEnum.QUERY)
@Function.fun(FunctionConstants.queryPage)
@Function(openLevel = {FunctionOpenEnum.API})
public Pagination<PetTalent> queryPage(Pagination<PetTalent> page, IWrapper<PetTalent> queryWrapper){
QueryWrapper<PetTalent> queryWrapper1 = (QueryWrapper<PetTalent>) queryWrapper;
Map<String, Object> queryData = queryWrapper.getQueryData();
String unStore = (String) queryData.get(LambdaUtil.fetchFieldName(PetTalent::getUnStore));
if (StringUtils.isNotEmpty(unStore)) {
//转换查询条件
queryWrapper1.like(Step5 重启看效果
在搜索框【非存储字段测试】输入查询内容,跟通过【达人】字段搜索的效果是一致的

Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9289.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验