
布局是将页面拆分成一个一个的小单元,按照上下中左右进行排列。
前沿
在前端领域中,布局可以分为三大块「Float、Flex、Grid 」,Float可以说的上是上古时期的布局了,如今市面还是很少见的,除了一些古老的网站。
目前,平台主要支持通过配置XML上面的cols和span来进行布局。平台也同样支持自由布局,合理的使用row、col、containers和container四个布局容器相关组件,将可以实现各种类型的布局样式,换句话说,平台实现的自由布局功能是Flex和Grid的结合体。
这里主要是讲解Flex和Grid布局,以及目前新的模板布局实现的思路。
Flex布局
Flex布局采用的是一维布局,那么什么是一维布局呢,所谓的一维布局就是只有一个方向、没有体积、面积,比如一条直线。它适合做局部布局,就像我们原来的顶部菜单、面包屑导航,以及现在的主视图字段配置。
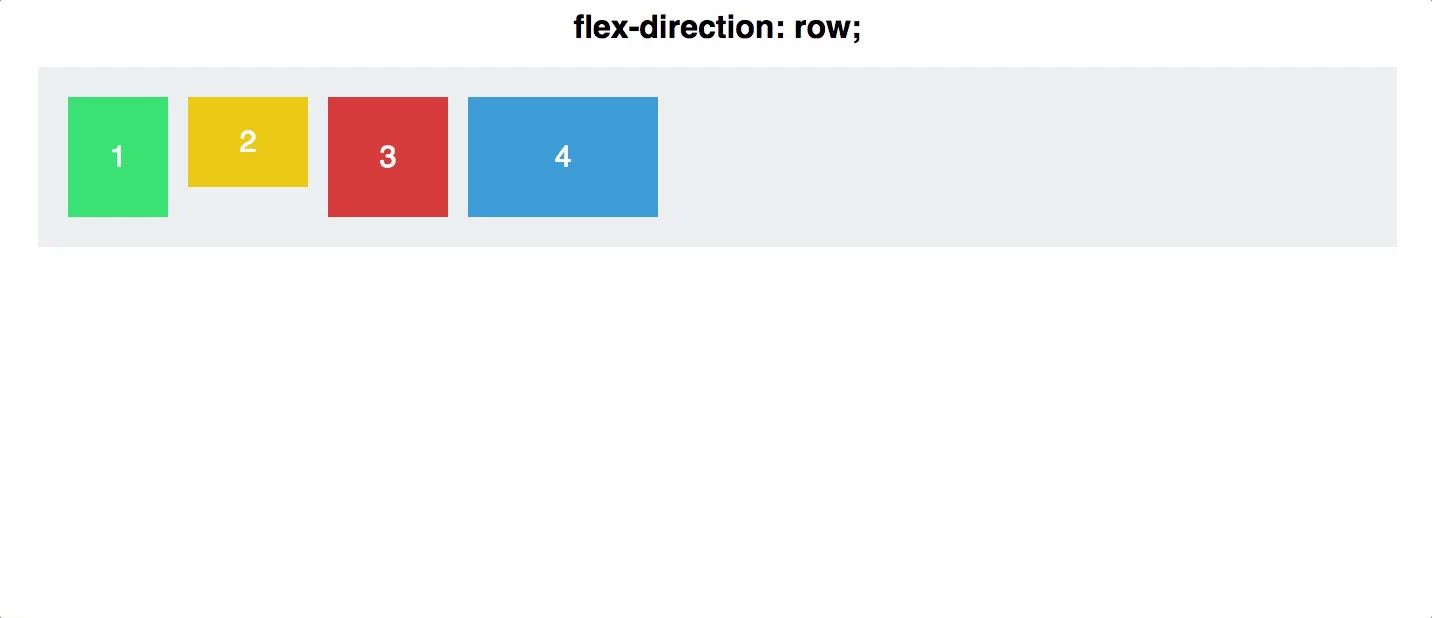

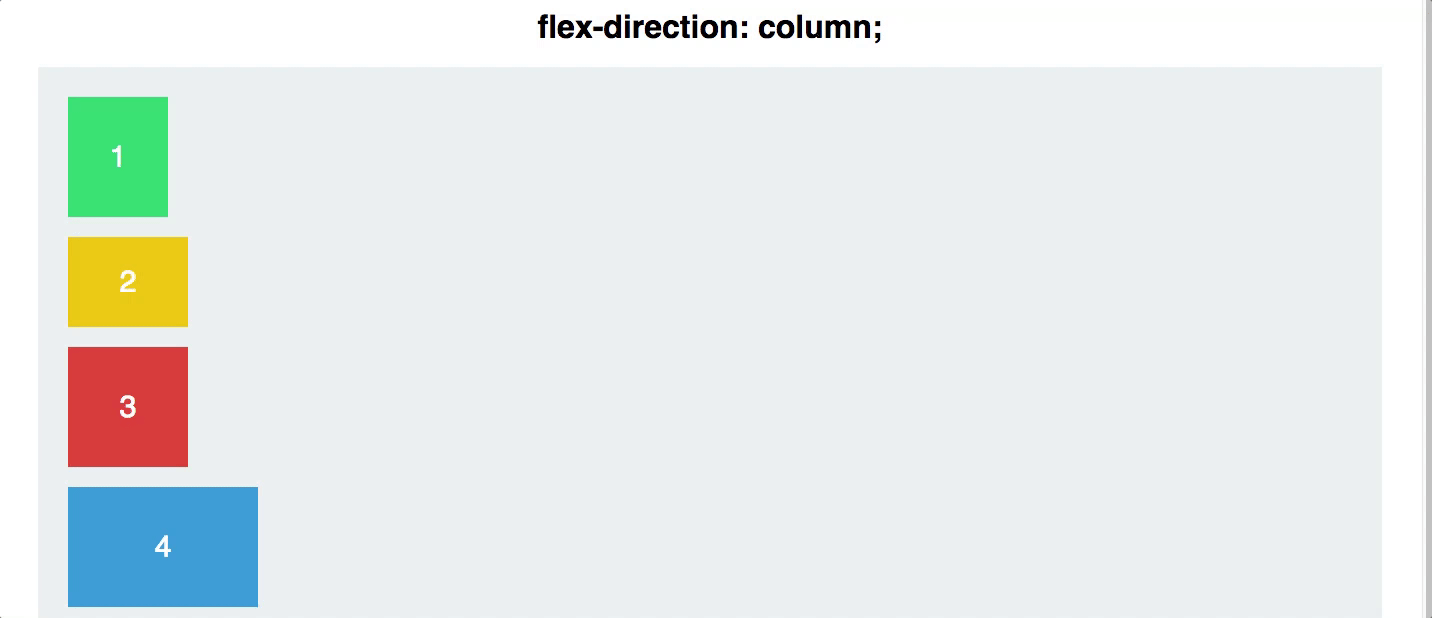
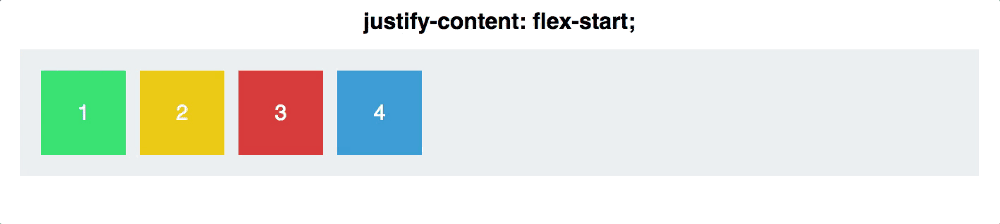
从上图可以看看出,Flex布局只能在X、Y轴进行转换,它无法对上下左右四个方向同时处理,因为它没“面积”的概念。所以它最适合做局部布局。
优点
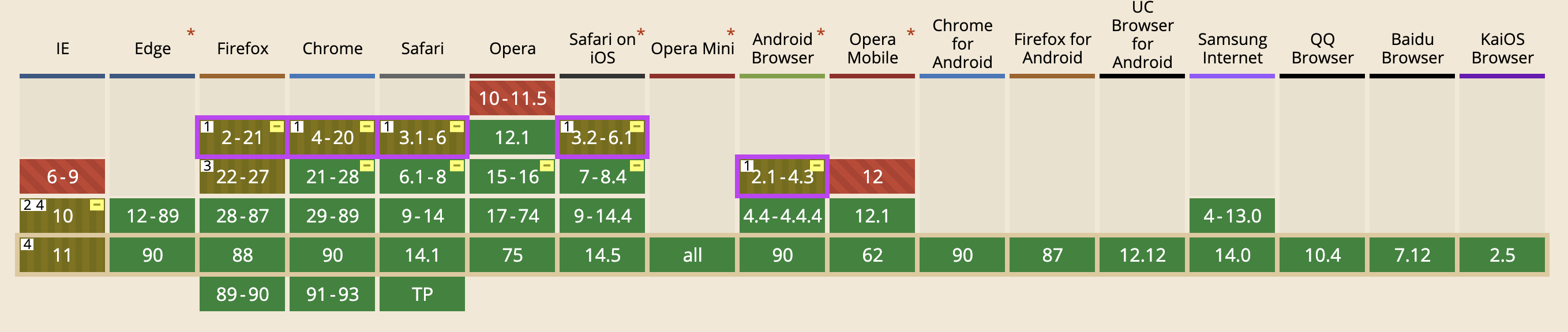
Flex的兼容性,可以看得出来,目前主流的浏览器都支持该属性。所以Flex兼容性强,如果你想对局部做布局处理,Flex是最好选择。
缺陷
刚刚也提到了,用户想要的布局是千奇百怪的,如果他想要的布局在现有的功能中无法实现怎么办?让用户放弃?还是说服他使用现在的布局。
Grid布局
Grid布局系统采用的是二维布局,二维布局有四个方向:上、下、左、右,它只有面积没有体积,比如一张纸、网格。
Grid布局
<div id="grid-container-one">
<div class="one-1">Grid Item 1</div>
<div>Grid Item 2</div>
<div>Grid Item 3</div>
<div>Grid Item 4</div>
<div>Grid Item 5</div>
<div class="one-6">Grid Item 6</div>
</div>
<div id="grid-container-two">
<div class="tow-1">Grid Item 1</div>
<div class="tow-2">Grid Item 2</div>
<div>Grid Item 3</div>
<div>Grid Item 4</div>
<div>Grid Item 5</div>
<div>Grid Item 6</div>
</div>
<div id="grid-container-three">
<div>Grid Item 1</div>
<div>Grid Item 2</div>
<div class="grid">Grid Item 3</div>
<div class="grid-column">Grid Item 4</div>
<div>Grid Item 5</div>
<div>Grid Item 6</div>
<div>Grid Item 7</div>
<div class="grid-column">Grid Item 8</div>
</div>
HTML CSSResult Skip Results Iframe
EDIT ON
* {
box-sizing: border-box;
padding: 0;
margin: 0;
line-height: 1.5;
font-weight: bold;
text-align: center;
}
#grid-container-one{
background-color: black;
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: repeat(2, 50px);
gap: 10px;
border: solid black 2px;
margin-bottom: 20px;
color: salmon;
}
#grid-container-one div {
border: solid white 2px;
padding: 10px;
}
#grid-container-one .one-1 {
grid-area: span 1/span 3;
text-aligin: center
}
#grid-container-one .one-6 {
grid-column: 3 /4;
}
#grid-container-two{
background-color: CADETBLUE;
display: grid;
grid-template-columns: 15% repeat(2, 1fr);
grid-template-rows: 100px;
text-shadow: 1px 1px 3px black;
margin-bottom: 20px;
color: salmon;
}
.tow-1 {
grid-area: span 3 / span 1
}
.tow-2 {
grid-area: span 1 / span 2
}
#grid-container-two div{
border: solid white 2px;
padding: 10px;
}
#grid-container-three{
display: grid;
grid-template-columns: repeat(4, 1fr);
grid-template-rows: 25%;
grid-auto-rows: 200px;
grid-auto-columns: 100px;
gap: 2px;
color: black;
text-decoration: underline;
margin-bottom: 2%;
}
#grid-container-three div{
background-color: salmon;
border: solid black 5px;
padding: 10px;
}
.grid-column{
grid-column: 5 / 7;
}
.grid{
grid-row: 1 /1;
grid-column: 4 / 5;
}
.grid-container-inline{
display: inline-grid;
grid-template-columns: repeat(2, 200px);
grid-template-rows: 100px 100px;
gap: 2px;
margin-bottom: 20px;
}
.grid-container-inline div{
padding: 35px;
border: solid black 2px;
background-color: PINK;
}
Resources1× 0.5× 0.25×Rerun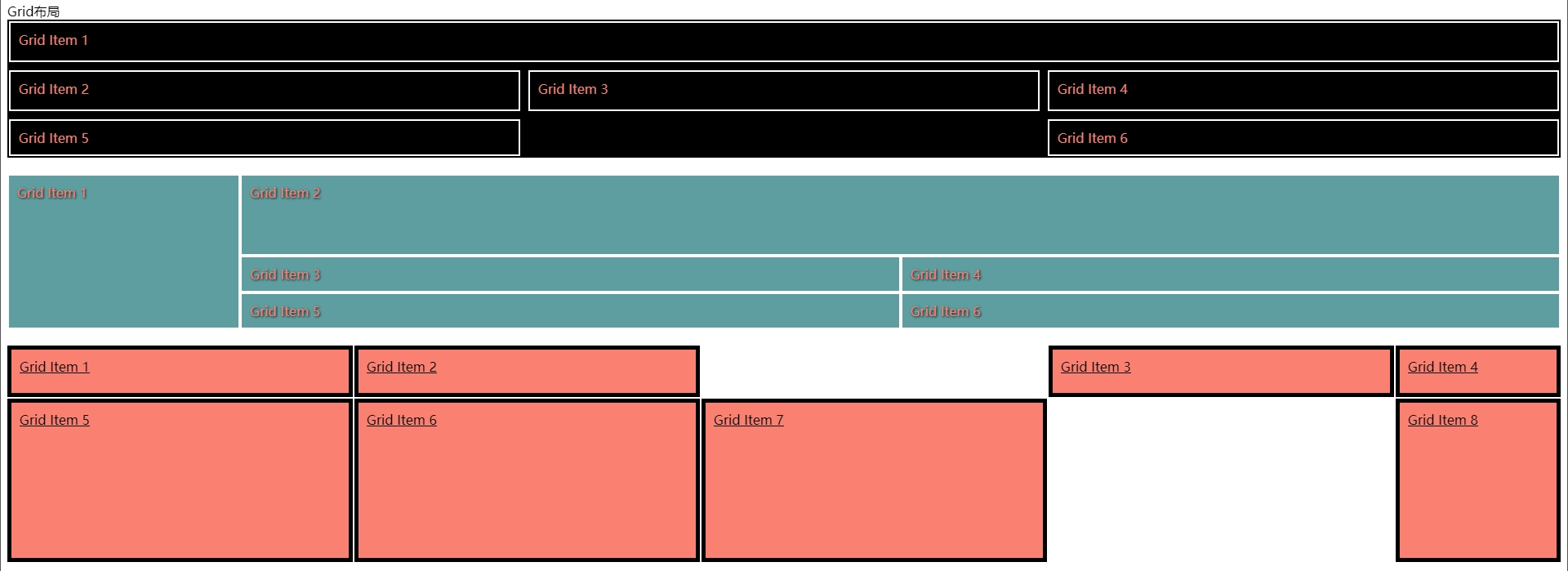
从上面的代码可以看出,Grid天生的支持整体布局,它甚至可以移行换位,它的强大之处可以颠覆你对布局的认知。
缺陷
虽然Grid很强大,但是它有一个致命的缺陷,那就是兼容性。
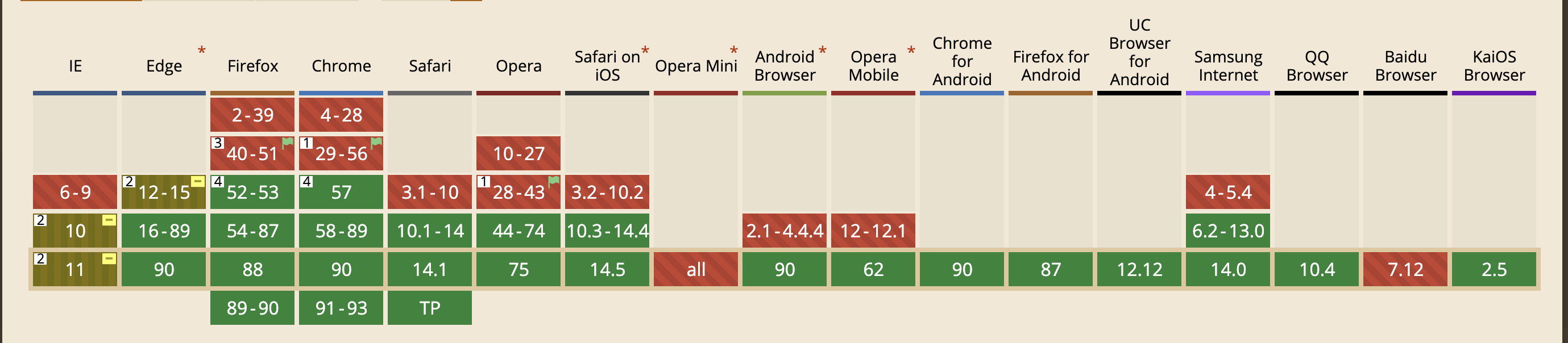
从上图可以看出,IE10以下、Chrome56以下、Firefox51以下等等都不支持该属性。
平台布局
名词解释
-布局容器相关组件:row 、col 、containers 和container这四个组件的统称。
-基础布局属性:包括cols 、colSpan、span 和offset。
概述
一般的,我们对大多数组件提供了基本的布局属性配置,包括:
- cols:将内容区中的每行拆分的列数;当前元素未配置该属性时,将取离当前元素最近父元素属性。默认:1
- colSpan:当前元素相对于父元素在每行中所占列比例;优先于span。默认:FULL
- FULL:1
- HALF:1/2
- THIRD:1/3
- TWO_THIRDS:2/3
- QUARTER:1/4
- THREE_QUARTERS:3/4
- span:当前元素相对于父元素在每行中所占列数。默认:cols
- offset:当前元素相对于原所在列的偏移列数。
我们规定了默认栅格数为24,基础布局属性均是相对于默认栅格数而言的。
在使用基础布局属性时,请尽可能保证公式 (24 / cols) * span 以及以下列举的公式,其计算结果为整数,否则可能出现不符合预期的结果。
在使用colSpan时,span的计算公式为:span = cols * colSpan
在使用offset时,offset的计算公式为:offset = (24 / cols) * offset
平台内置组件
下面列举了平台内置组件在Form和Detail视图中使用时所支持的布局相关属性,包括可能影响部分区域显隐的相关属性。
表头说明:
- tag:xml配置标签
- widget:组件名称;xml属性;多个值属于别称。如:widget="form"
- 配置项:xml属性名称。
- 可选值:声明支持的配置项属性类型,不可识别或不可解析时将采用默认值。
- 作用:对配置项的简单描述,部分布局属性在上方进行了描述,不再赘述。
| tag | widget | 配置项 | 可选值 | 默认值 | 作用 |
|---|---|---|---|---|---|
| view | cols | number | 1 | ||
| element | form | cols | number | 1 | |
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | ||||
| detail | cols | number | 1 | ||
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | ||||
| DateTimeRangePicker | colSpan | enum | FULL | ||
| span | number | cols | |||
| offset | number | ||||
| DateRangePicker | colSpan | enum | FULL | ||
| span | number | cols | |||
| offset | number | ||||
| TimeRangePicker | colSpan | enum | FULL | ||
| span | number | cols | |||
| offset | number | ||||
| colSpan | enum | FULL | |||
| YearRangePicker | span | number | cols | ||
| offset | number | ||||
| field | 任意 | colSpan | enum | FULL | |
| span | number | cols | |||
| offset | number | ||||
| pack | fieldset/group | cols | number | 1 | |
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | ||||
| title | string | 分组 | 标题;空字符串或不填,则隐藏标题区; | ||
| tabs | cols | number | 1 | ||
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | ||||
| tab | cols | number | 1 | ||
| title | string | 选项页 | 标题;必填;空字符串或不填则显示默认值; | ||
| row | cols | number | 1 | ||
| align | top/middle/bottom | 垂直对齐方式 | |||
| justify | start/end/center/space-around/space-between | 水平对齐方式 | |||
| gutter | number,number?示例:24 = 24,2412,12 | 24,24 | 水平/垂直间距 | ||
| wrap | boolean | true | 是否允许换行 | ||
| col | cols | number | 1 | ||
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | 偏移单元格数 | |||
| mode/widthType | manual/full | manual | 列模式;手动/自动填充;使用自动填充时,将忽略span、offset属性; | ||
| containers | cols | number | 1 | ||
| align | top/middle/bottom | 垂直对齐方式 | |||
| justify | start/end/center/space-around/space-between | 水平对齐方式 | |||
| gutter | number,number?示例:24 = 24,2412,12 | 0,24 | 水平/垂直间距 | ||
| wrap | boolean | true | 是否允许换行 | ||
| container | cols | number | 1 | ||
| colSpan | enum | FULL | |||
| span | number | cols | |||
| offset | number | 偏移单元格数 | |||
| align | top/middle/bottom | 垂直对齐方式 | |||
| justify | start/end/center/space-around/space-between | 水平对齐方式 | |||
| gutter | number,number?示例:24 = 24,2412,12 | 0,24 | 水平/垂直间距 | ||
| wrap | boolean | true | 是否允许换行 | ||
| mode/widthType | manual/full | full | 列模式;手动/自动填充;使用自动填充时,将忽略span、offset属性; |
基础布局
基础布局提供了在不使用任何布局容器相关组件的情况下,仅使用cols、span、offset这三个属性控制行列的布局能力。
其本质上是flex布局的扩展,但依旧无法脱离flex布局本身的限制,即元素始终是自上而下、自左向右紧凑的。
下面将使用fieldset和tabs/tab组件来介绍各个属性在实际场景中的使用。示例1:默认撑满一行
<pack widget="fieldset" title="示例1">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>结果展示

示例2:一行两列:cols=2; colSpan=HALF/span=1
<pack widget="fieldset" title="示例2" cols="2">
<field data="code" widget="Input" colSpan="HALF" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" colSpan="HALF" label="名称" placeholder="请输入" required="true" />
</pack>
------------------------------ 或 ------------------------------
<pack widget="fieldset" title="示例2" cols="2">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" span="1" label="名称" placeholder="请输入" required="true" />
</pack>结果展示

示例3:使用offset实现中间空一个字段空间的布局
<pack widget="fieldset" title="示例3" cols="3">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" span="1" offset="1" label="名称" placeholder="请输入" required="true" />
</pack>PS:offset的作用有限,offset最优实践的前提是在同一行中进行偏移,要实现特殊布局功能,请使用自由布局相关布局能力。
结果展示

示例4:属性cols就近取值
<!-- 所有tab将使用cols="2"属性 -->
<pack widget="tabs" cols="2">
<pack widget="tab" title="示例4-1">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="tab" title="示例4-2">
<field data="name" widget="Input" span="1" label="名称" placeholder="请输入" required="true" />
</pack>
</pack>结果展示


<!-- 所有tab将使用cols="2"属性 -->
<pack widget="tabs" cols="2">
<!-- 特指该tab使用cols="1"属性,其他tab继续使用tabs配置的cols="2"属性 -->
<pack widget="tab" title="示例4-1" cols="1">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="tab" title="示例4-2">
<field data="name" widget="Input" span="1" label="名称" placeholder="请输入" required="true" />
</pack>
</pack>结果展示


自由布局
自由布局提供了无法通过基础布局能力实现的其他布局能力,总的来说,自由布局是对grid布局和flex布局的结合,它既拥有grid布局对页面进行单元格拆/合的能力,在每个单元格中,使用flex布局进行紧凑排列。
下面将使用fieldset组件介绍各个属性在实际场景中的使用。
组件组合
row/col:两个组件共同形成行和列,在一行中拆分成24个栅格,每个列的跨度不超过24。当一行中,所有列的跨度和超过24时,将会自动换行。
containers/row/container:三个组件共同形成一个二维网格,以此实现grid布局的基本能力。每个单元格(container)中使用flex布局。
PS:以下示例为了体现布局效果,可能会出现重复字段定义,业务上在使用时需要避免这种定义。
示例1:仅使用1/2左侧空间
小贴士:在使用row和col组合时,如果在一个col中有且仅有一个子元素,则col可以缺省。col相关属性可以配置在该子元素上。
<pack widget="fieldset" title="示例1">
<pack widget="row" cols="2">
<!-- 此处显式定义col组件,field标签上的基础布局属性将失效 -->
<pack widget="col" span="1">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>
<pack widget="row" cols="2">
<pack widget="col" span="1">
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>
</pack>
</pack>
------------------------------ 或 ------------------------------
<pack widget="fieldset" title="示例1">
<pack widget="row" cols="2">
<!-- 此处缺省col组件,field标签上的基础布局属性可生效 -->
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="row" cols="2">
<field data="name" widget="Input" span="1" label="名称" placeholder="请输入" required="true" />
</pack>
</pack>结果展示

示例2:使用布局容器实现中间空一个字段空间的布局
<pack widget="fieldset" title="示例2">
<pack widget="containers">
<pack widget="row">
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container"></pack>
<pack widget="container">
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>
</pack>
</pack>
</pack>结果展示

图3-5-6-40 示例效果
示例3:一行5列(基础布局属性公式无法计算出整数的情况)
<pack widget="fieldset" title="示例3">
<pack widget="containers">
<pack widget="row">
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>
</pack>
</pack>结果展示

示例4:共2行,其中1行未3列,另1行为2列
该示例可以使用任何一种组件组合都可以实现,结果一致。
<!-- 使用containers/row/container -->
<pack widget="fieldset" title="示例4">
<pack widget="containers">
<pack widget="row">
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>
<pack widget="row">
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>
</pack>
</pack>
------------------------------ 或 ------------------------------
<!-- 使用row/col,其中col缺省 -->
<pack widget="fieldset" title="示例4">
<pack widget="row" cols="3">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" span="1" label="名称" placeholder="请输入" required="true" />
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
</pack>
<pack widget="row" cols="2">
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
<field data="code" widget="Input" span="1" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>结果展示

示例5:布局容器的垂直居中
左侧容器高度被子元素撑开,右侧容器在垂直方向居中
<pack widget="fieldset" title="示例5">
<pack widget="containers">
<pack widget="row">
<pack widget="container">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
<field data="name" widget="Input" label="名称" placeholder="请输入" required="true" />
</pack>
<pack widget="container" align="middle">
<field data="code" widget="Input" label="编码" placeholder="请输入" required="true" />
</pack>
</pack>
</pack>
</pack>结果展示

举例
这里拿PetTalent举例,仿造教程上面效果,除了例子中的效果,自己可以做更多的尝试
Step1 修改PetTalent的form视图如下
给creater字段增加一个属性配置 offset="1"
<field data="creater" widget="SSConstructSelect" offset="1" submitFields="creater,name" responseFields="name"/>Step2 重启看效果
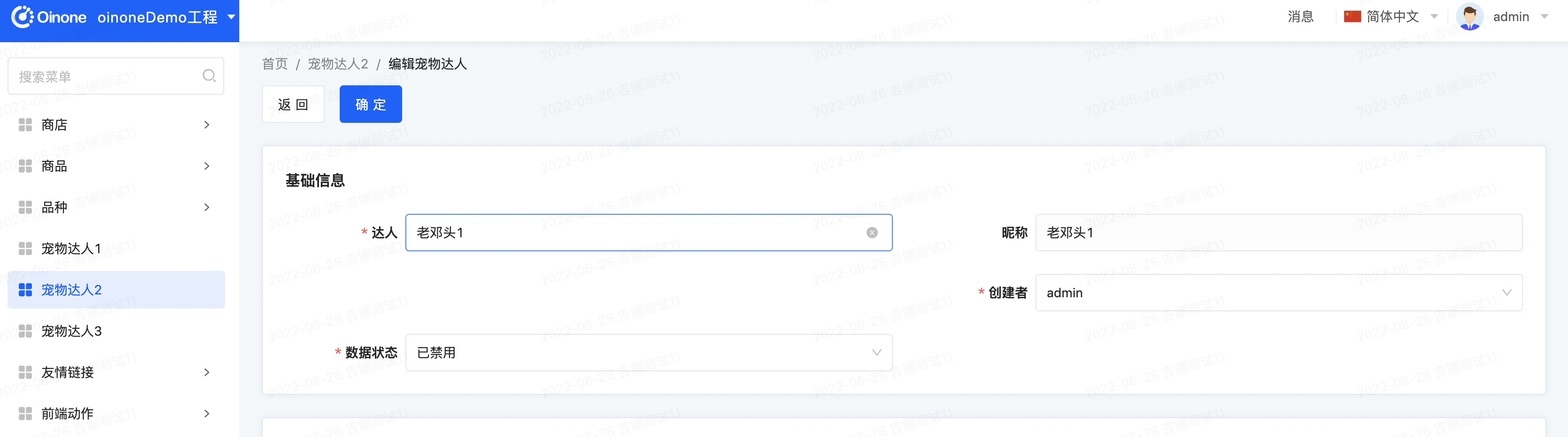
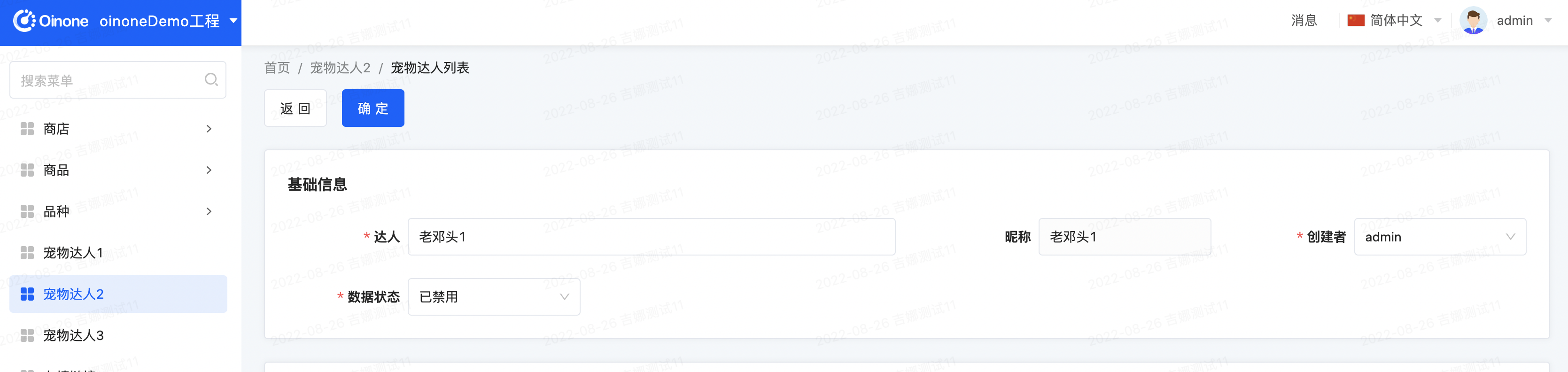
Step3 修改PetTalent的form视图如下
给【基础信息】增加一个属性cols="4",给name字段增加一个属性span="2",给creater和nick字段增加一个属性span="1":
<pack widget="group" title="基础信息" cols="4">
<field invisible="true" data="id" label="ID" readonly="true"/>
<field data="name" label="达人" required ="true" span="2"/>
<field data="nick" compute="activeRecord.name" readonly = "true" span="1"/>
<field data="creater" widget="SSConstructSelect" submitFields="creater,name" responseFields="name" span="1"/>
<field data="dataStatus" label="数据状态" >
<options>
<!-- option name="DRAFT" displayName="草稿" value="DRAFT" state="ACTIVE"/ -->
<option name="NOT_ENABLED" displayName="未启用" value="NOT_ENABLED" state="ACTIVE"/>
<option name="ENABLED" displayName="已启用" value="ENABLED" state="ACTIVE"/>
<option name="DISABLED" displayName="已禁用" value="DISABLED" state="ACTIVE"/>
</options>
</field>
<field invisible="true" data="createDate" label="创建时间" readonly="true"/>
<field invisible="true" data="writeDate" label="更新时间" readonly="true"/>
<field data="createUid" label="创建人id"/>
<field data="writeUid" label="更新人id"/>
</pack>Step4 重启看效果
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9262.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验