
我们默认视图已经基本可以用了,但实际业务中还是会有一些不大不小的自定义需求,写自定义视图又太麻烦,今天我们来学习一种更加轻量的模式即:后端研发可以通过注解来配置视觉交互。该系列注解以Ux开头,例如@UxHomepage、@UxMenu、@UxAction、@UxView、@UxWidget等等。
视图XML的配置优先级大于在代码上的注解,也就是代码上的注解影响的是默认展示逻辑。
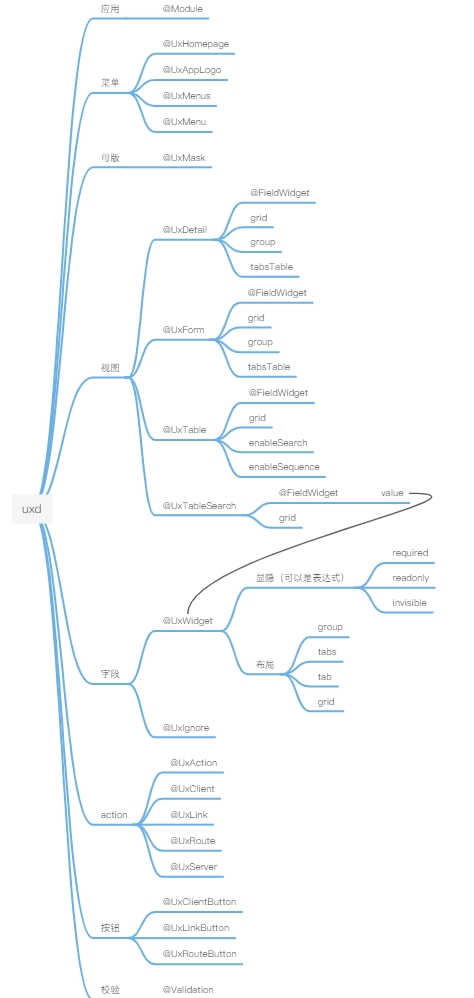
一、Ux家族图谱
我们先简单通过家族图谱做个简单了解,脑海里有一个影响当有需要的时候知道能不能做,深入了解还需要大家多多动手去尝试

二、默认视图后端配置举例
在下面的代码片段中UxTable、UxForm、UxDetail、UxTableSearch都有涉及,几个特殊点做些解释其他的留大家自行测试
-
Group分组的配置逻辑:为了不让一个分组内的字段不断的写Group,所以采取了第一个字段写了Group,到下一个出现的group之间的字段都自动归为一个Group
-
搜素整体不展示可以用“@UxTable(enableSearch = false)”配置在模型的类上。
-
字段搜索用“UxTableSearch”配置在模型的字段上,其特殊逻辑是只要你配了一个字段,系统就不自动补充了,例子中表格页的搜索栏只会留下店铺名称和店铺编码
……其他代码
//@UxTable(enableSearch = false),整体不支持搜索
public class PetShop extends AbstractDemoIdModel {
public static final String MODEL_MODEL="demo.PetShop";
@Field(displayName = "店铺编码")
@UxForm.FieldWidget(@UxWidget(group = "Form基础数据"))//Form分组
@UxTableSearch.FieldWidget(@UxWidget())//支持搜索
private String code;
@Field(displayName = "店铺编码2")
@Field.Sequence(sequence = "DATE_ORDERLY_SEQ",prefix = "C",size=6,step=1,initial = 10000,format = "yyyyMMdd")
private String codeTwo;
@UxTableSearch.FieldWidget(@UxWidget())//支持搜索
@UxTable.FieldWidget(@UxWidget(invisible = "true"))//表格中不展示支持搜索
@Field(displayName = "店铺名称",required = true,immutable=true)
private String shopName;
@Field(displayName = "一年内新店")
@UxForm.FieldWidget(@UxWidget(widget = "Switch",group = "Form基础数据"))//Switch,Checkbox可以切换着看,字段可选widget参考【字段的配置】一文
private Boolean oneYear;
@Field(displayName = "开店时间",required = true)
@UxDetail.FieldWidget(@UxWidget(invisible = "true"))//详情不展示
private Time openTime;
@Field(displayName = "闭店时间",required = true)
@UxDetail.FieldWidget(@UxWidget(invisible = "true"))//详情不展示
private Time closeTime;
…… 其他代码
}Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9256.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验