
1. 业务场景
报表不局限于表格的样式,还能以各式各样的图表形式展现各项汇总数据 这有利于管理者更为直观地了解公司的经营情况,便于后续进行分析,提高对公司的管理水平。
2. 操作流程
1)进入数据可视化,进入报表tab,维护分组信息;
2)在二级分组名称后点击“+”【添加报表】,对报表进行编辑设计;
3)创建完成后可以【编辑】报表标题、备注;
4)需要通过【选择图表、创建图表】完善报表内容;
5)完善后可以点击【发布】报表,则报表此时可以被引用;
6)如果报表有更新,则可以点击【更新发布】,使业务系统引用对报表变为最新的报表信息;
7)如果报表数据不再可以公开使用,则需要通过【隐藏】功能将报表的引用权限收起,此时数据大屏、前端业务系统均不可再引用该报表,但不影响已被引用的报表;
8)隐藏后可以【取消隐藏】,报表恢复隐藏前的状态和功能,可以被引用。
3. 操作流程图解
3.1 创建分组
1)操作流程:创建分组
2)操作路径:数据可视化-报表-创建分组
3)点击搜索框后的「+」创建一级分组,输入一级分组名称后,点击一级分组后的「+」创建二级分组,输入二级分组名称后,此时分组创建完成,可以在二级分组下创建报表
3.2 编辑分组名称
1)操作流程:选择分组-编辑分组名称
2)操作路径:数据可视化-报表-编辑分组名称
3)鼠标移动至需要修改的分组上,点击出现的「编辑图标」,可以修改分组名称,修改后分组名称实时更新
3.3 删除分组
1)操作流程:选择分组-删除分组
2)操作路径:数据可视化-报表-删除分组
3)鼠标移动至需要删除的分组上,当分组下无报表时出现「删除图标」,可以点击图标后删除分组,删除一级分组时对应所有的二级分组也会被删除,删除后消失,只要分组下没有报表的分组才能直接删除成功
3.4 创建报表
1)操作流程:选择二级分组-创建报表
2)操作路径:数据可视化-报表-二级分组-创建报表
3)鼠标移动至需要创建报表的二级分组上,出现「+」,点击图标后=需要填写报表标题;
a. 报表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复;
4)创建后可以选择报表需要展示的图表
3.5 删除报表
1)操作流程:选择报表-删除报表
2)操作路径:数据可视化-报表-二级分组-报表名称-删除图表
3)未发布或者已发布但没有被隐藏的报表,并且没被前端或者数据大屏引用,才展示报表菜单名称后的删除图标
4)删除报表后报表消失
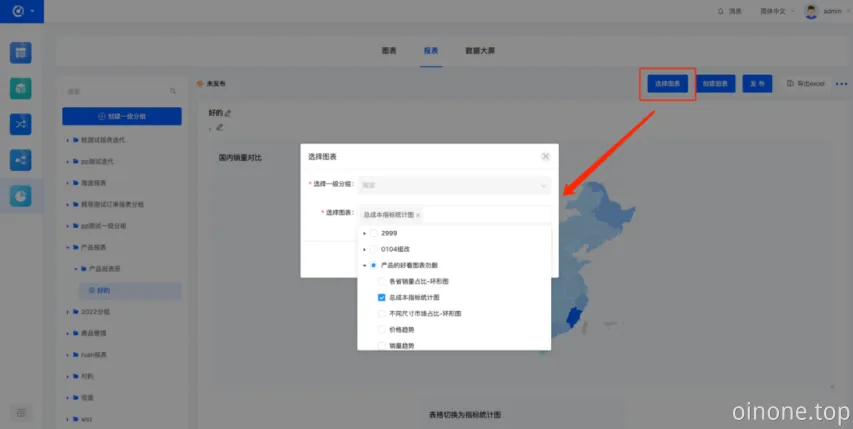
3.6 选择图表
1)操作流程:选择报表-为报表选择图表
2)操作路径:数据可视化-报表-二级分组-报表名称-选择图表
3)选择单个未发布或者已发布但没有被隐藏的报表,点击【选择图表】,弹出“选择图表”弹窗,对该报表需要展示的图表进行选择
a. 需要选择图表的一级分组后才能选择图表;
b. 可以多选图表,选择的图表只能是已选一级分组下的未隐藏的未被选择的图表;选择一个二级分组时,默认该二级分组下的图表会全部被选中,图表会按照选中的顺序展示在报表列表;
4)选择图表后,报表信息保持展示图表的最新效果;如果图表更新了,但是报表没有发布最新,则报表在前端展示的仍为最近发布的版本;
5)如果图表中存在超过一行的图内筛选项,则在报表处原始的图表尺寸只能查看一行图内筛选项,需要根据图表在报表处的等比拖动效果展示更多的图内筛选项

3.7 创建图表
1)操作流程:选择报表-创建图表
2)操作路径:数据可视化-报表-二级分组-创建图表
3)选择单个未发布或者已发布但没有被隐藏的报表,点击【创建图表】,弹出“创建图表”弹窗,需要填写图表标题、模型、方法;
a. 图表标题:最大支持20个字,支持汉字、数字、大小写字母、-;同个一级分组下不允许重复;
b. 模型:需要选择来源数据对应的模型;
c. 方法:选择模型后需要选择方法,方法是用来提取模型数据的逻辑;
4)选择成功后进入图表设计页面,创建图表保存后返回,返回到当前报表页面,新创建的图表展示在报表的第一个位置
3.8 拖拽图表
1)操作流程:选择报表-拖拽图表
2) 操作路径:数据可视化-报表-二级分组-报表名称-拖拽图表
3)所有的报表均可拖拽图表,拖拽时需要选择图表,可以上下左右等比拖动,图表的内容也会根据拖动的比例进行缩放,展示全部的被遮挡图表内容
4)拖拽后实时生效,报表信息保持展示最新效果
3.9 移除图表
1)操作流程:选择报表-移除图表
2)操作路径:数据可视化-报表-二级分组-报表名称-移除图表
3)未发布或者已发布但没有被隐藏的报表,并且没被前端或者数据大屏引用,此时可以针对不需要的图表进行移除
4)选择移除后不展示在报表中,不影响原图表
5)报表移除图表后实时更新,更新发布后,前端可以展示最新的报表信息,如果未发布,则仅数据大屏可展示最新的报表信息,前端仍为最近发布的报表
3.10 设置报表筛选项
1)操作流程:选择报表-设置报表筛选项
2)操作路径:数据可视化-报表-二级分组-报表名称-更多-报表筛选项-添加
3)添加时选择筛选项字段的类型,关联每个图表对应的字段,一个图表只能关联一个
4)关联后可以按关联字段查询图表数据
3.11 发布
1)操作流程:选择报表-发布报表
2)操作路径:数据可视化-图表-二级分组-报表-发布
3)选择单个未发布且没有被隐藏的报表,点击【发布】按钮,报表发布后可以被前端引用,报表状态变为已发布,展示最近发布时间;
4)如果报表发布后有更新内容,会展示的更新类型:更新报表信息/更新图表内容/选择图表/移除图表
3.12 查看最近一次发布的版本
1)操作流程:选择报表-查看最近一次发布的版本
2)操作路径:数据可视化-报表-二级分组-报表名称-查看最近一次发布的版本
3)当报表发布后有更新,在最近发布时间左侧展示【查看】,在最近发布时间下展示更新的类型,点击查看可以查看最近发布的版
3.13 更新发布
1)操作流程:选择报表-更新发布报表
2)操作路径:数据可视化-报表-二级分组-报表名称-更新发布报表
3)选择单个已发布且没有被隐藏的报表,并且该报表在上次发布后有所更新,可以点击【更新发布】按钮,将最新的报表内容发布至业务系统,业务系统引用的报表为最新内容;
4)如果更新了内容,但未点击更新发布,则前端业务系统查看的报表仍为最近发布的报表
3.14 隐藏
1)操作流程:选择报表-隐藏报表
2)操作路径:数据可视化-报表-二级分组-报表名称-隐藏报表
3)报表默认不隐藏,可以切换是否隐藏=是
a. 未发布的报表,较隐藏前,不可以操作【发布】,可以【取消隐藏】;
b. 已发布的图表,较隐藏前,只能操作【导出图片、导出excel、取消隐藏】;
c. 隐藏后的报表不可以被引用,但不影响已经被引用的数据
3.15 取消隐藏
1) 操作流程:选择报表-取消隐藏报表
2) 操作路径:数据可视化-报表-二级分组-报表名称-取消隐藏报表
3) 隐藏后的报表可以取消隐藏,切换是否隐藏=否,取消隐藏后,报表恢复隐藏前的状态和功能,可以被引用
3.16 查看引用
1)流程:选择报表-查看被哪些页面引用
2)操作路径:数据可视化-报表-二级分组-报表-更多-查看引用
3)选择具体的报表,查看当前报表被引用的所有信息
3.17 不允许别人编辑
1)流程:选择报表-不允许别人编辑
2)操作路径:数据可视化-报表-二级分组-报表-更多-不允许别人编辑
3)选择自己创建的报表,对报表是否允许其他人编辑进行设置;如果设置为不允许,则其他人无法编辑报表
3.18 不允许别人引用
1)流程:选择图表-更多-不允许别人引用
2)操作路径:数据可视化-报表-二级分组-报表-更多-不允许别人引用
3)选择自己创建的报表,对报表是否允许他人引用进行设置;如果设置为不允许,则其他人无法引用到该报表
3.19 导出图片
1) 操作流程:选择报表-导出图片
2) 操作路径:数据可视化-报表-二级分组-报表名称-导出图片
3) 选择报表后,点击【导出图片】按钮可以将当前报表导出为图片
3.20 导出EXCEL
1)操作流程:选择报表-导出EXCEL
2)操作路径:数据可视化-报表-二级分组-报表名称-报表导出EXCEL
3)选择报表后,点击【导出EXCEL】按钮可以将当前报表导出为EXCEL
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9423.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验