
在App Finder 中点击应用中心可以进入oinone的应用中心,可以看到oinone平台所有应用列表、应用大屏、以及技术可视化。
一、应用列表
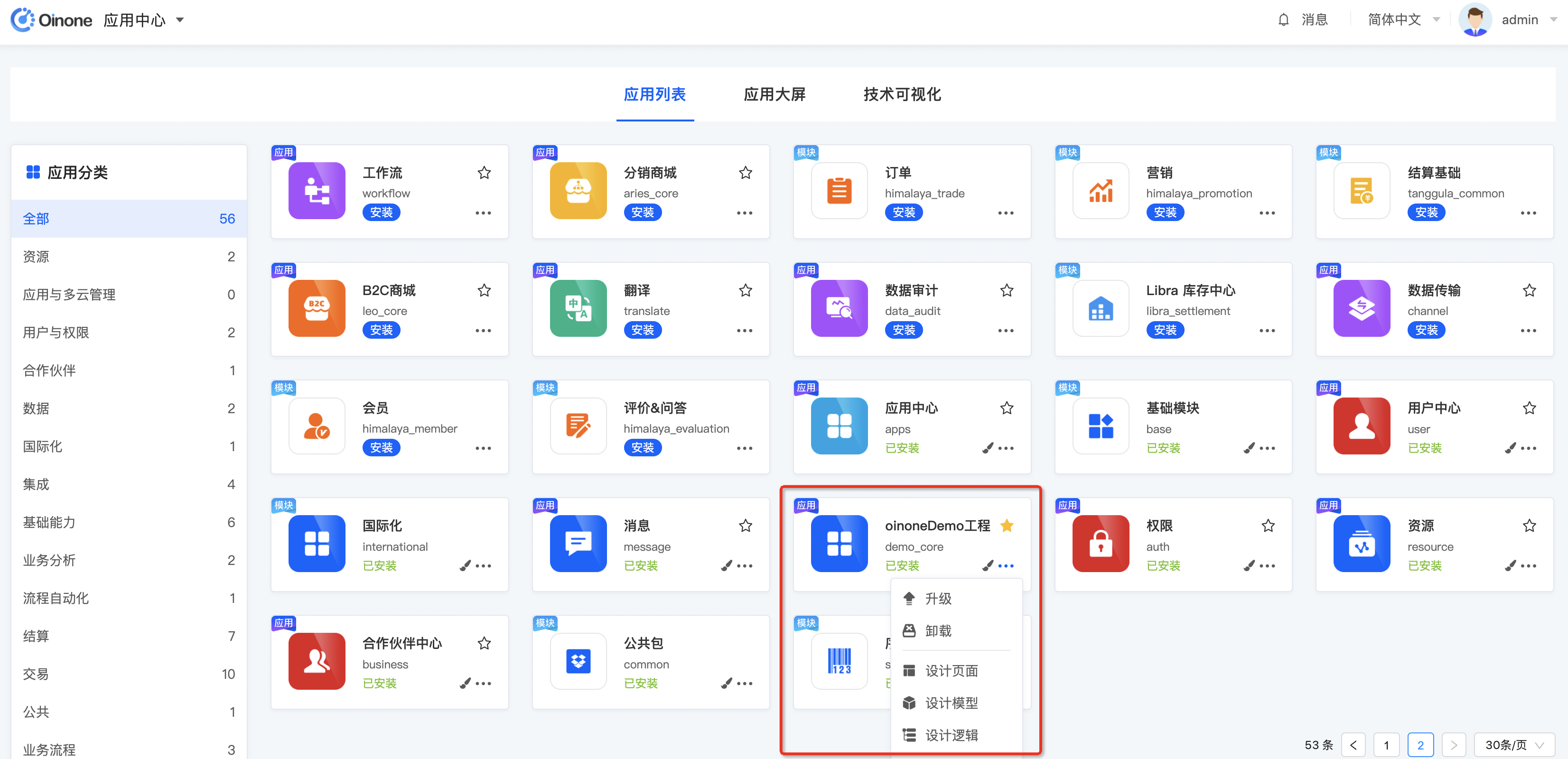
标准版本不支持在线安装,只能通过boot工程的yml文件来配置安装模块。在 www.oinone.top 官方SaaS平台客户可以在线管理应用生命周期如:安装、升级、卸载。同时针对已安装应用可以进行无代码设计(前提安装了设计器),针对应用类的模块则可进行收藏,收藏后会在App Finder中的我收藏的应用中出现。在应用列表中可以看到我们已经安装的应用以及模块,我们oinoneDemo工程也在其中。

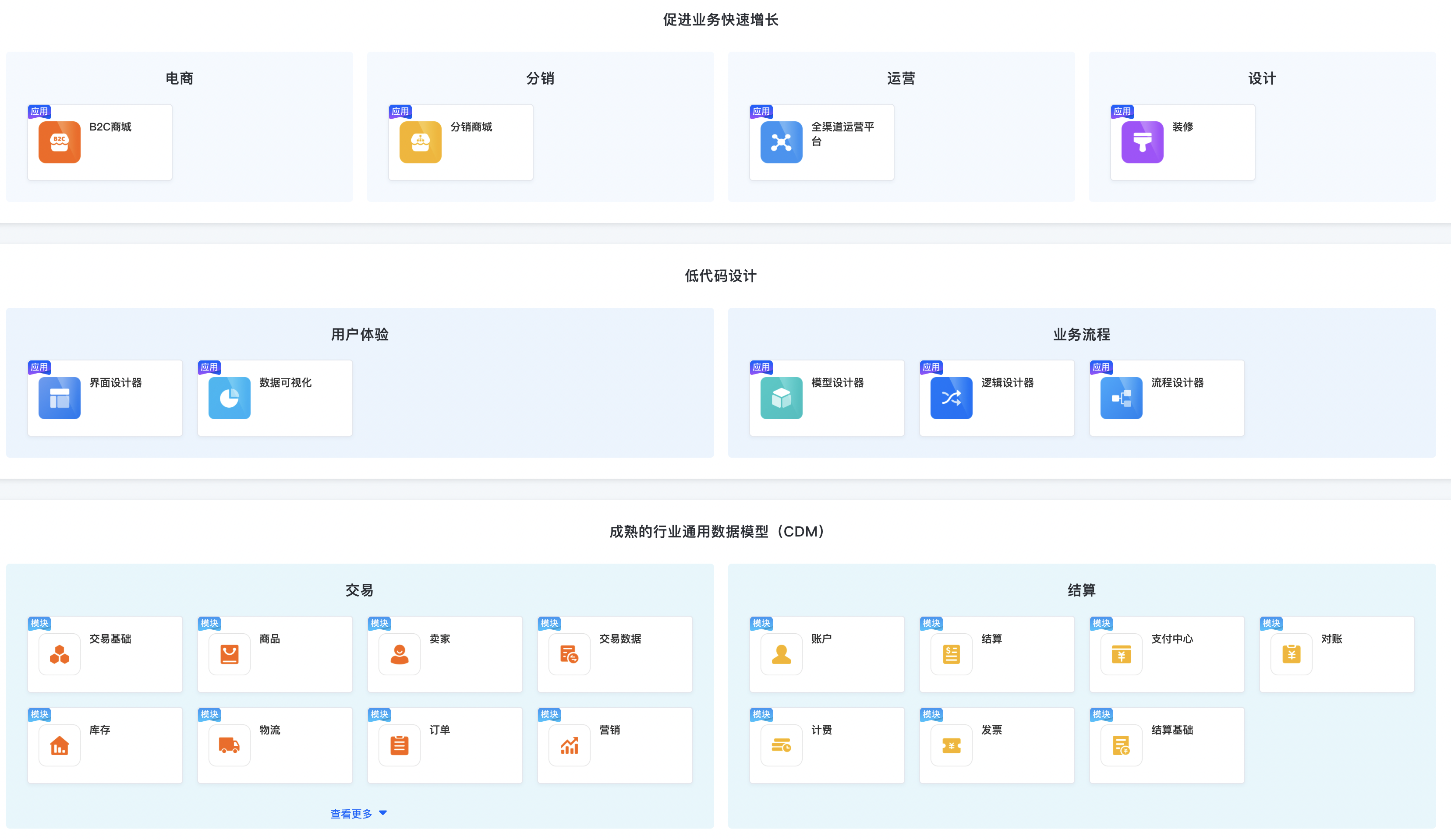
二、应用大屏
但我们的测试应用没有设置应用类目,则无法在应用大屏中呈现。
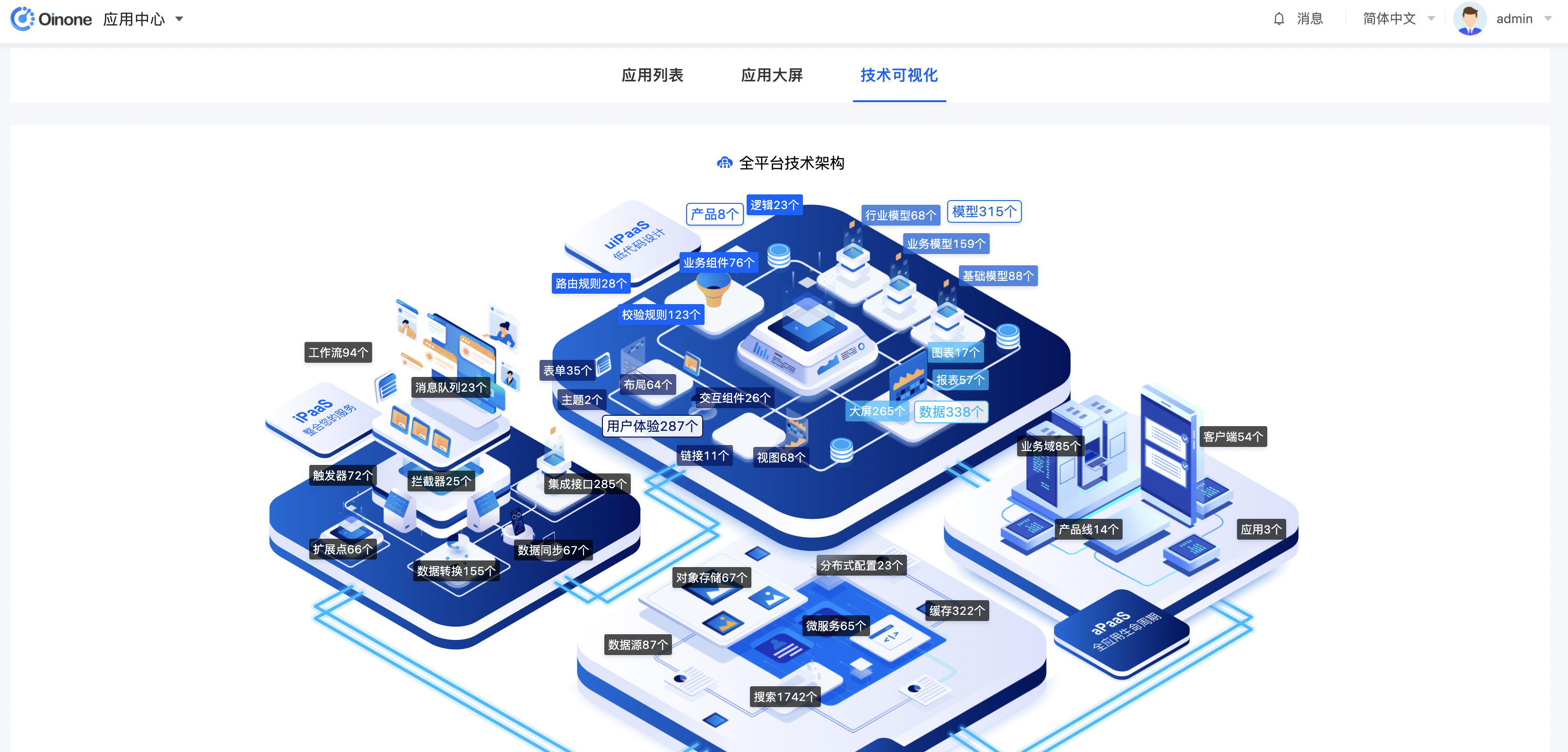
三、技术可视化
在技术可视化页面,出展示已经安装模块的元数据,并进行分类呈现
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9230.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验