
一、事务管理介绍
函数Function支持事务字段为isTransaction(默认为false),事务传播行为propagationBehavior(默认PROPAGATION_SUPPORTS),事务隔离级别isolationLevel(默认使用数据库默认的事务隔离级别),所以不会默认为函数添加事务。另外事务配置提供全局配置。
平台事务管理兼容Spring声明式与编程式事务,支持多数据源事务管理。事务管理中多数据源嵌套独立事务,不会造成死锁风险。使用多数据源或分表操作,不会导致脏读。如果需要多数据源分布式事务,请使用PamirsTransational分布式事务管理方案(@PamirsTransational(enableXa=true))。分布式事务一般用于量小的跨模块配置管理场景
使用方式
- 声明式事务,使用@PamirsTransactional注解在需要事务管理的类或方法上标注。在非无代码场景下,与@Transactional注解功能一致。
- 编程式事务,使用PamirsTransactionTemplate即可。在非无代码场景下,与TransactionTemplate功能一致。
- 配置式事务,使用TxConfig模型在模块安装时初始化存储事务配置数据。
事务特性
- 原子性 (atomicity):强调事务的不可分割.
- 一致性 (consistency):事务的执行的前后数据的完整性保持一致.
- 隔离性 (isolation):一个事务执行的过程中,不应该受到其他事务的干扰
- 持久性(durability) :事务一旦结束,数据就持久到数据库
事务隔离级别
事务隔离级别指的是一个事务对数据的修改与另一个并行的事务的隔离程度,当多个事务同时访问相同数据时,如果没有采取必要的隔离机制,就可能发生以下问题:
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务未提交的更新数据,所谓脏读,就是指事务A读到了事务B还没有提交的数据,比如银行取钱,事务A开启事务,此时切换到事务B,事务B开启事务–>取走100元,此时切换回事务A,事务A读取的肯定是数据库里面的原始数据,因为事务B取走了100块钱,并没有提交,数据库里面的账务余额肯定还是原始余额,这就是脏读 |
| 不可重复读 | 在一个事务里面的操作中发现了未被操作的数据 比方说在同一个事务中先后执行两条一模一样的select语句,期间在此次事务中没有执行过任何DDL语句,但先后得到的结果不一致,这就是不可重复读 |
| 幻读 | 是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。 同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象 发生了幻觉一样。 |
Pamirs(Spring)支持的隔离级别
| 隔离级别 | 描述 |
|---|---|
| DEFAULT | 使用数据库本身使用的隔离级别 ORACLE(读已提交) MySQL(可重复读) |
| READ_UNCOMITTED | 读未提交(脏读)最低的隔离级别,一切皆有可能。 |
| READ_COMMITED | 读已提交,ORACLE默认隔离级别,有不可重复读以及幻读风险。 |
| REPEATABLE_READ | 可重复读,解决不可重复读的隔离级别,但还是有幻读风险。 |
| SERLALIZABLE | 串行化,最高的事务隔离级别,不管多少事务,挨个运行完一个事务的所有子事务之后才可以执行另外一个事务里面的所有子事务,这样就解决了脏读、不可重复读和幻读的问题了 |
| 隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁度 |
|---|---|---|---|---|
| READ_UNCOMITTED | 是 | 是 | 是 | 否 |
| READ_COMMITED | 否 | 是 | 是 | 否 |
| REPEATABLE_READ | 否 | 否 | 是 | 否 |
| SERLALIZABLE | 否 | 否 | 否 | 是 |
事务的传播行为
-
保证同一个事务中
-
PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认)
-
PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务
-
PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常
-
保证没有在同一个事务中
-
PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务
-
PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务
-
PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常
-
PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
A中嵌套B事务,嵌套PROPAGATION_REQUIRES_NEW方法勿与A在同类中。
| 异常状态 | PROPAGATION_REQUIRES_NEW (两个独立事务) | PROPAGATION_NESTED (B的事务嵌套在A的事务中) | PROPAGATION_REQUIRED (同一个事务) |
|---|---|---|---|
| A抛异常 B正常 | A回滚,B正常提交 | A与B一起回滚 | A与B一起回滚 |
| A正常 B抛异常 | 1.如果A中捕获B的异常,并没有继续向上抛异常,则B先回滚,A再正常提交; 2.如果A未捕获B的异常,默认则会将B的异常向上抛,则B先回滚,A再回滚 | B先回滚,A再正常提交 | A与B一起回滚 |
| A抛异常B抛异常 | B先回滚,A再回滚 | A与B一起回滚 | A与B一起回滚 |
| A正常 B正常 | B先提交,A再提交 | A与B一起提交 | A与B一起提交 |
二、声明式事务(举例)
Step1 修改PetShopBatchUpdateAction
用@PamirsTransactional或者@Transactional注解来声明事务,PamirsTransactional跟Spring的Transactional区别在于PamirsTransactional支持多库事务,但此多库事务为非严格的分布式多库事务,之所以选择这个方案,原因如下
a. 不损害任何性能。
b. 事务保障率超过4个9
c. 经过阿里的大厂验证,特别是在阿里的结算平台中得到了很好的验证
@PamirsTransactional更多配置项请详见4.1.7【函数之元数据详解】一文,自己多试试。同时@PamirsTransactional百分百兼容@Transactional
@Action(displayName = "确定",bindingType = ViewTypeEnum.FORM,contextType = ActionContextTypeEnum.SINGLE)
@PamirsTransactional
//@Transactional
public PetShopBatchUpdate conform(PetShopBatchUpdate data){
if(data.getPetShopList() == null || data.getPetShopList().size()==0){
throw PamirsException.construct(DemoExpEnumerate.PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL).errThrow();
}
List<PetShopProxy> proxyList = data.getPetShopList();
for(PetShopProxy petShopProxy:proxyList){
petShopProxy.setDataStatus(data.getDataStatus());
}
new PetShopProxy().updateBatch(proxyList);
throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).errThrow();
// return data;
}Step2 重启看效果
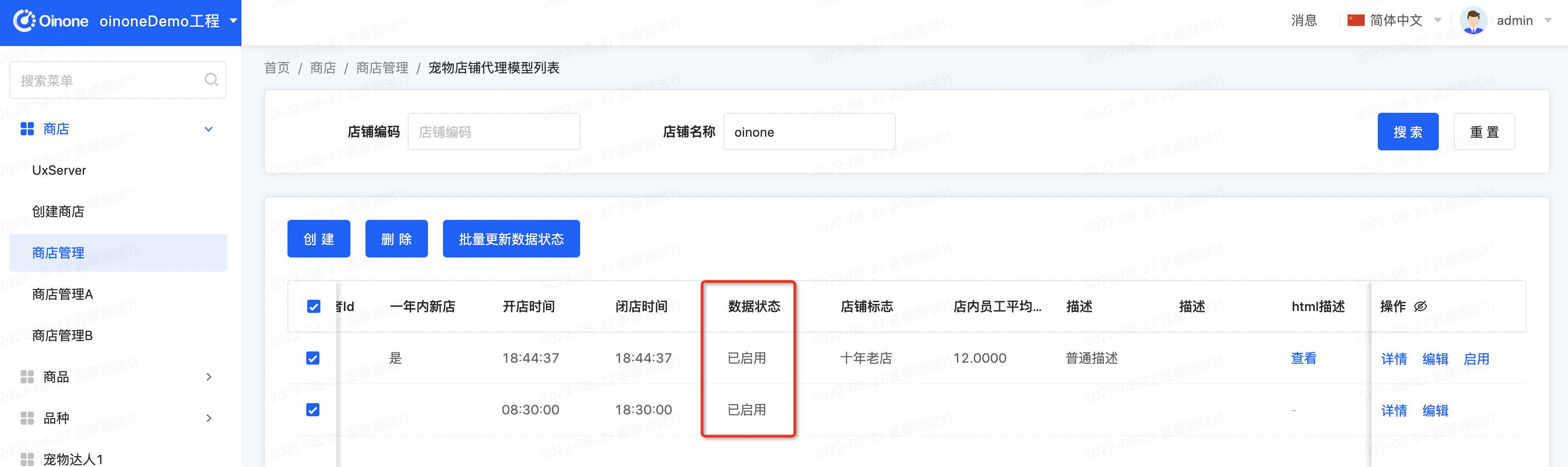
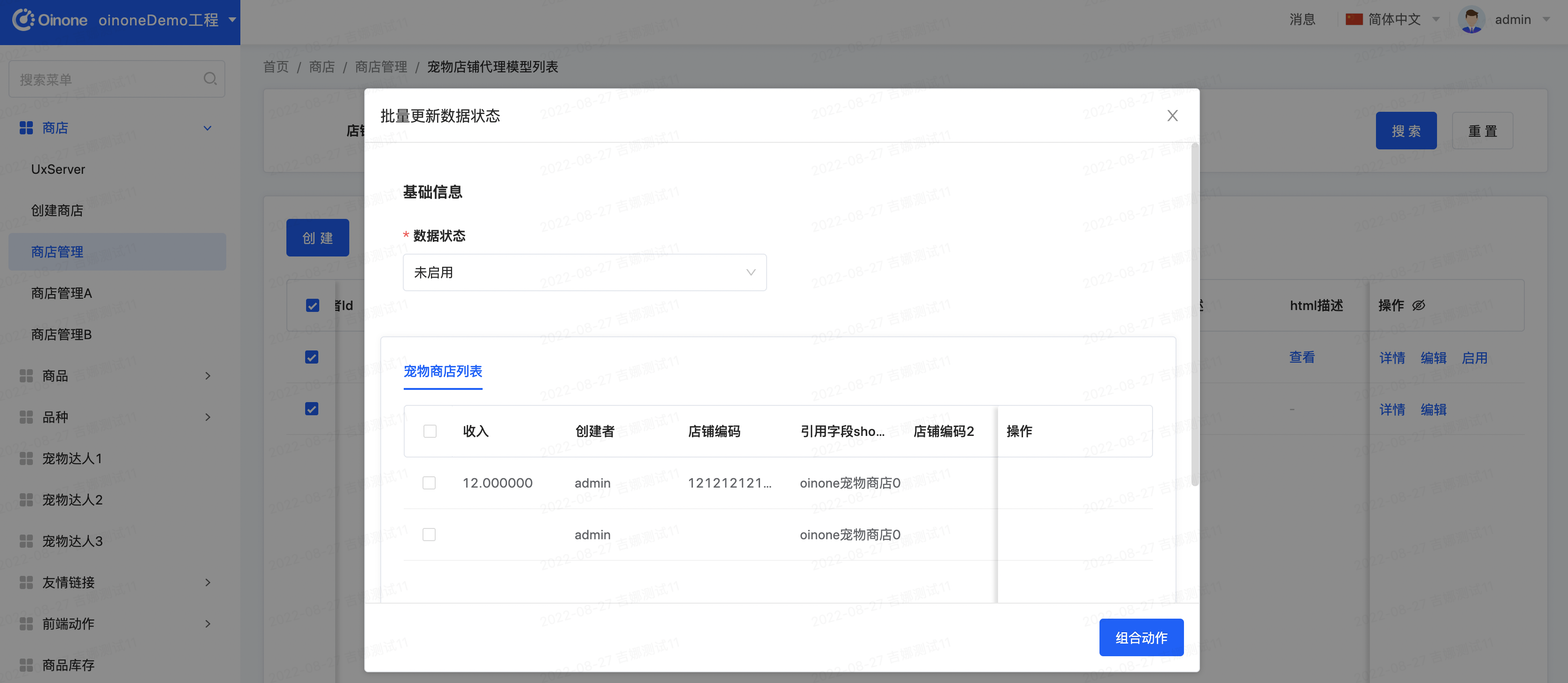
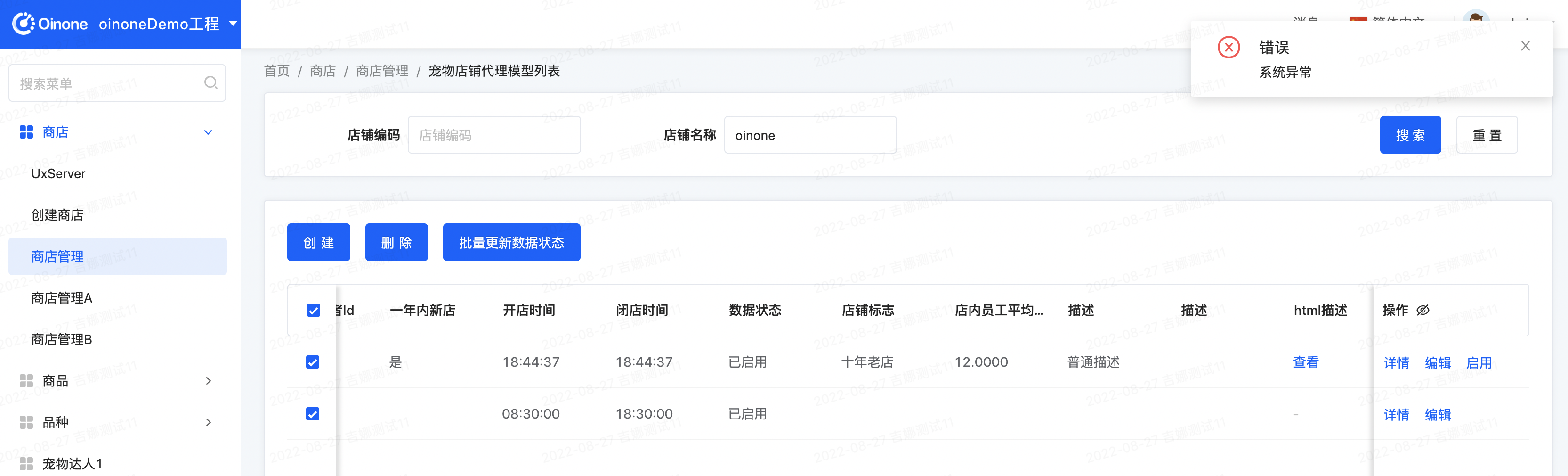
进入店铺管理列表页,选择记录点击【批量更新数据状态】按钮,修改记录的数据状态为【未启用】,提交看效果。期望效果为:提示系统异常,数据修改失败

三、编程式事务(举例)
为了提升性能,特别是在高并发场景,编程式事务开发模式有利于精细化控制事务开启长度,尽可能地在事务开启前,把费时的查询工作、数据准备做完。基本套路如下
Tx.build(new TxConfig().setPropagation(Propagation.REQUIRED.value())).executeWithoutResult(status -> {
//执行逻辑
});Step1 修改PetShopBatchUpdateAction
@Action(displayName = "确定",bindingType = ViewTypeEnum.FORM,contextType = ActionContextTypeEnum.SINGLE)
public PetShopBatchUpdate conform(PetShopBatchUpdate data){
if(data.getPetShopList() == null || data.getPetShopList().size()==0){
throw PamirsException.construct(DemoExpEnumerate.PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL).errThrow();
}
List<PetShopProxy> proxyList = data.getPetShopList();
for(PetShopProxy petShopProxy:proxyList){
petShopProxy.setDataStatus(data.getDataStatus());
}
Tx.build(new TxConfig().setPropagation(Propagation.REQUIRED.value())).executeWithoutResult(status -> {
new PetShopProxy().updateBatch(proxyList);
throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).errThrow();
});
return data;
}Step2 重启看效果
跟声明式事务一致的效果
四、配置式事务
略,该模式一般用于平台内部使用以及无代码编辑器管理事务时用到,就不举例了
分布式事务(不建议使用)
如果要严格意义上的分布式事务,需要配置enableXa为true,@PamirsTransational(enableXa=true)。同时引入依赖包
<groupId>pro.shushi.pamirs.framework</groupId>
<artifactId>pamirs-connectors-data-xa</artifactId>注:该版本还不支持远程RPC后的分布式事务,因该模式有很大的弊端,也就是把原本无状态的服务变成有状态,导致性能和耦合度都极差。所以我们一般使用事务性消息、异步任务等最终一致性方案去替代。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9283.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验