
1. 整体介绍
应用审计是基于模型字段记录用户操作留痕记录,通过定义审计规则,平台基于审计规则订阅的字段记录形成日志。平台名词概念:
应用日志:针对已订阅的审计规则记录用户操作信息,是用户在各应用中操作行为留痕记录。
审计规则:业务审计中,数据变化订阅记录的规则。
操作入口:应用中心——业务审计应用。
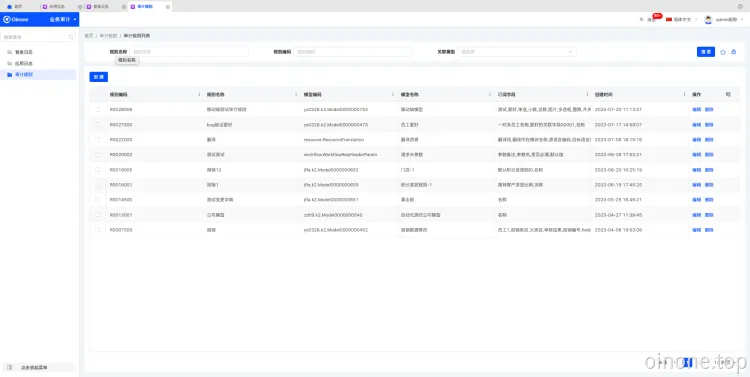
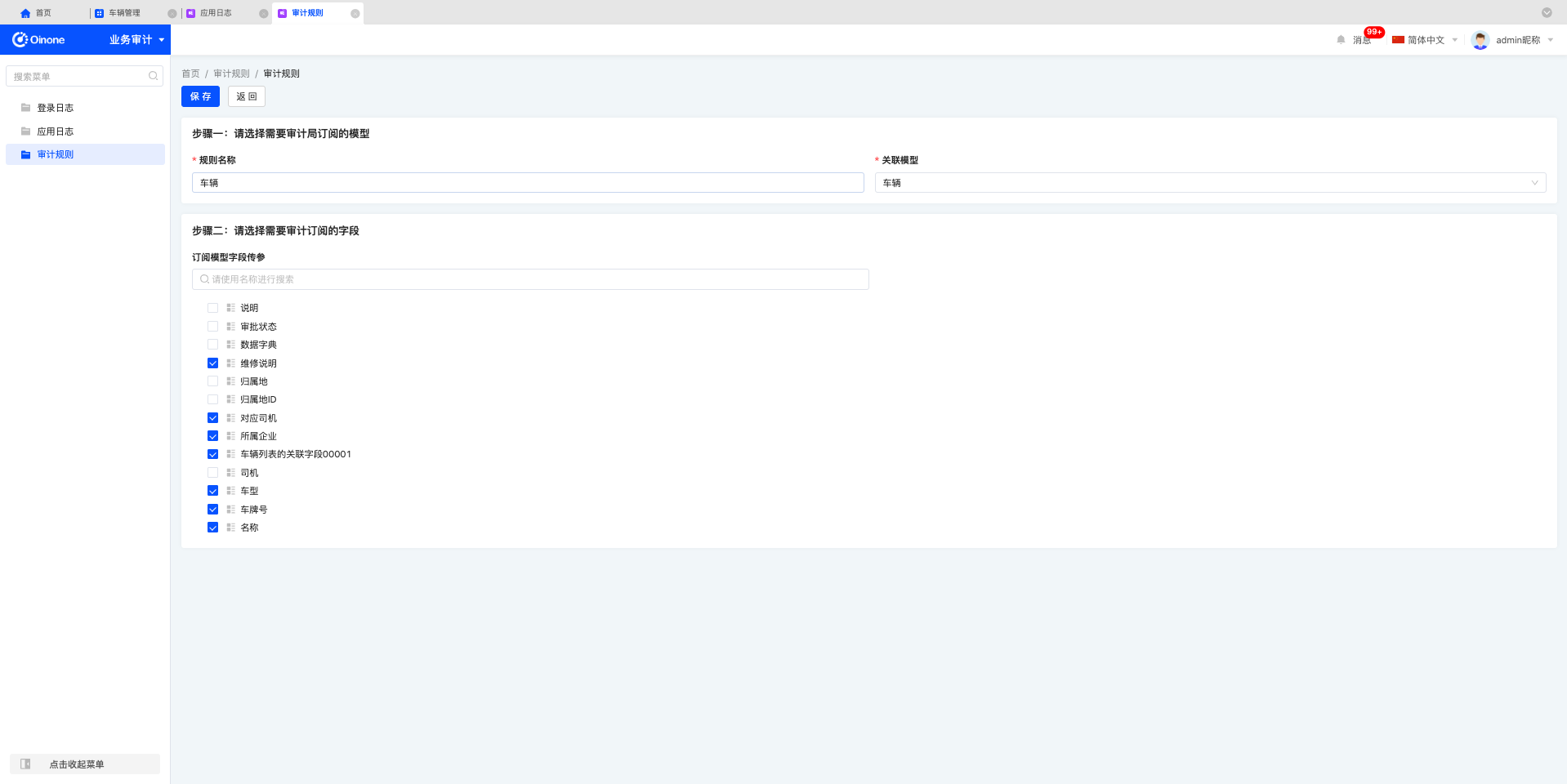
2. 审计规则
审计规则是指定义审计过程订阅数据变化的信息,根据模型、订阅到具体字段内容变化形成应用日志。如订阅销售订单的备注,销售订单S20231001888,订单备注【尽快发货】,备注修改为【需易碎品包装】,审计规则为:销售订单模型,订阅【备注】。
操作包括:新增、编辑、删除。

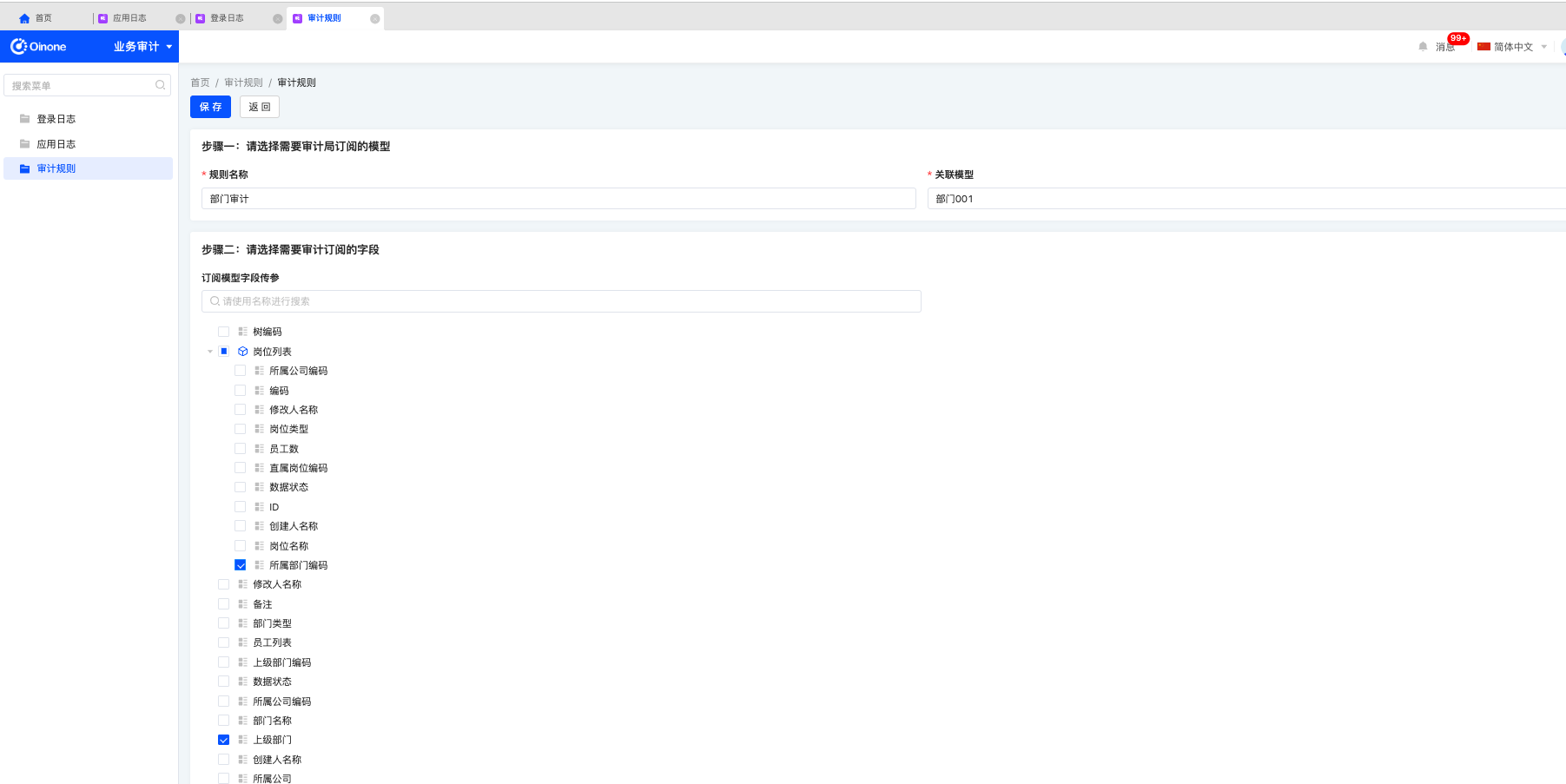
2.1. 新增
新增时,定义审计规则名称,选择需要审计的模型,指定需要订阅的字段信息,同时可以指定关联关系的字段。
需要注意:每个模型仅限定义单条审计规则。
2.2. 编辑
编辑同新增操作,不做赘述。
2.3. 删除
删除规则后,平台将不再监听对应数据的变更日志,请慎重删除。
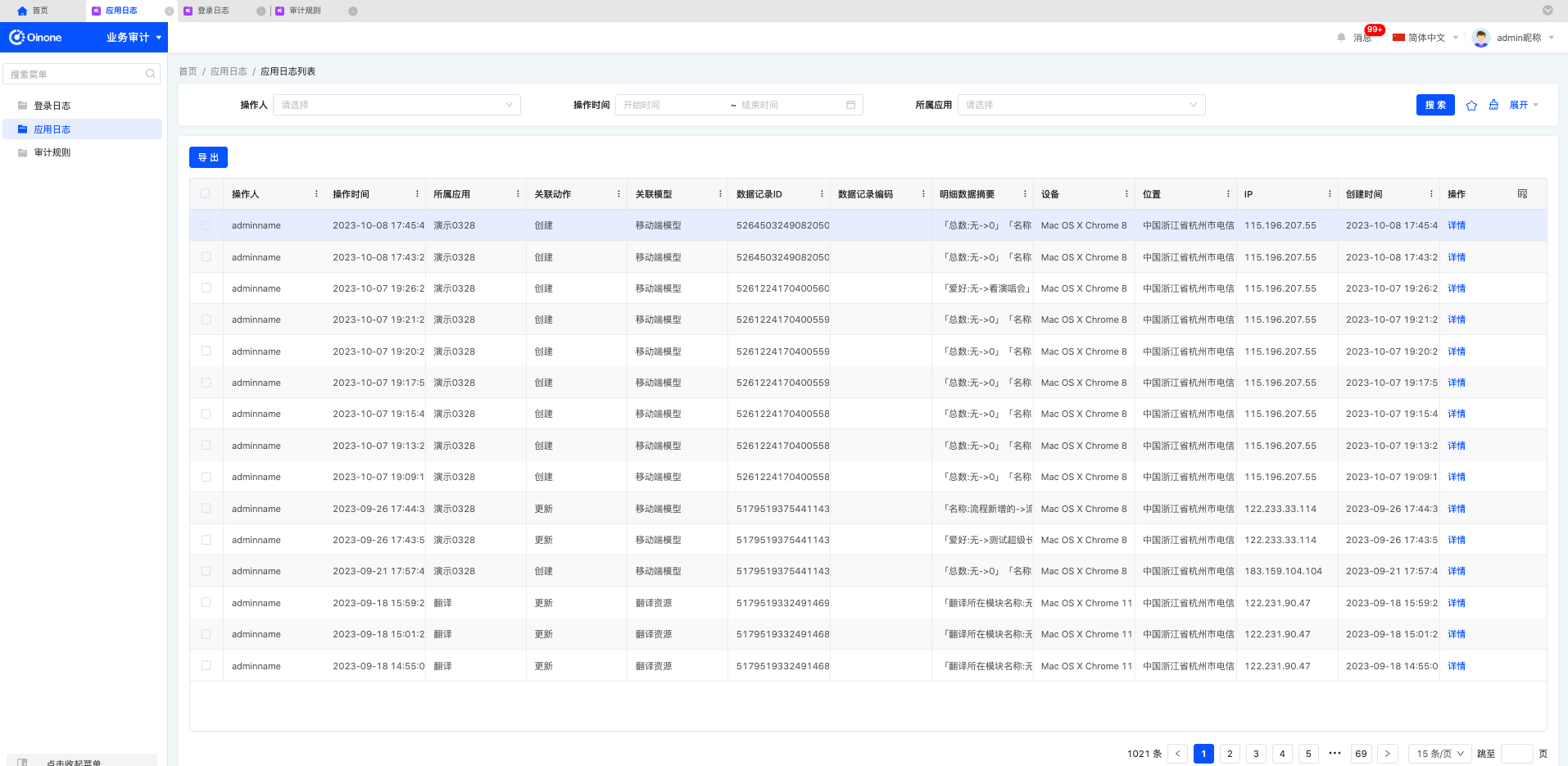
3. 应用日志
应用日志是针对已订阅的审计规则记录用户操作信息。记录操作用户、IP、登录设备、位置、订阅的字段变化内容。
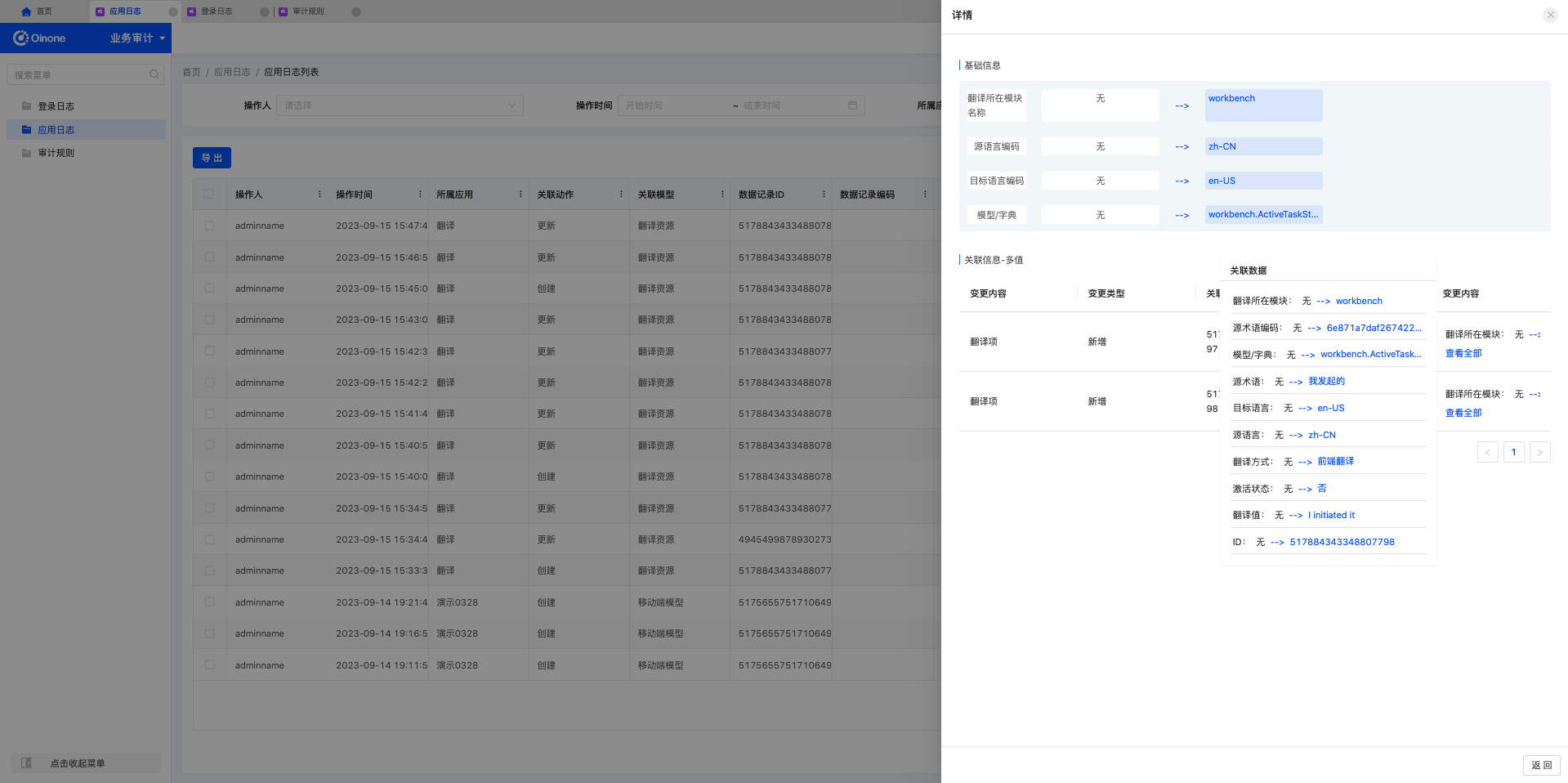
应用日志详情
4. 业务表达
4.1. 展示效果
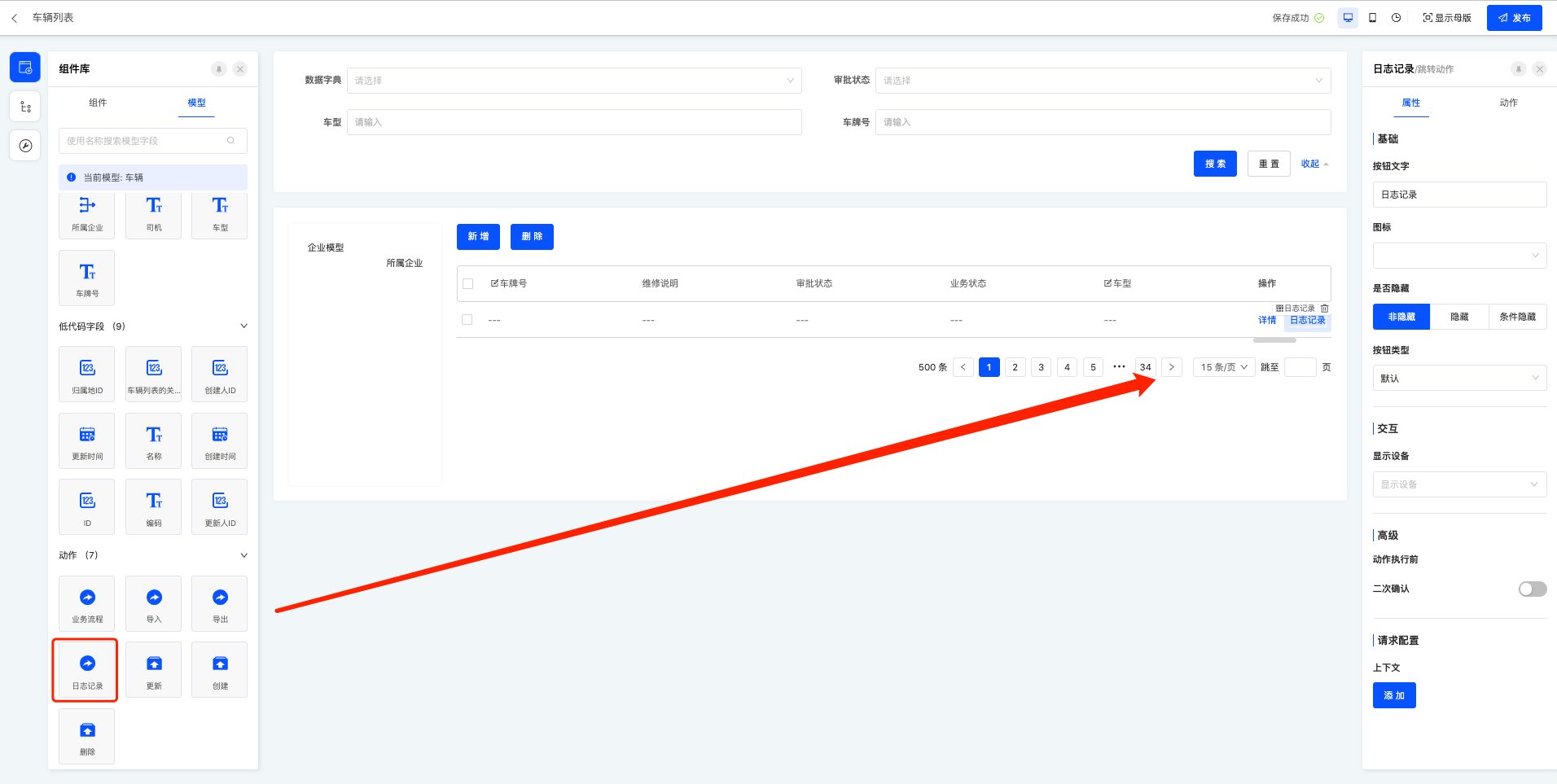
表格-行操作---日志记录
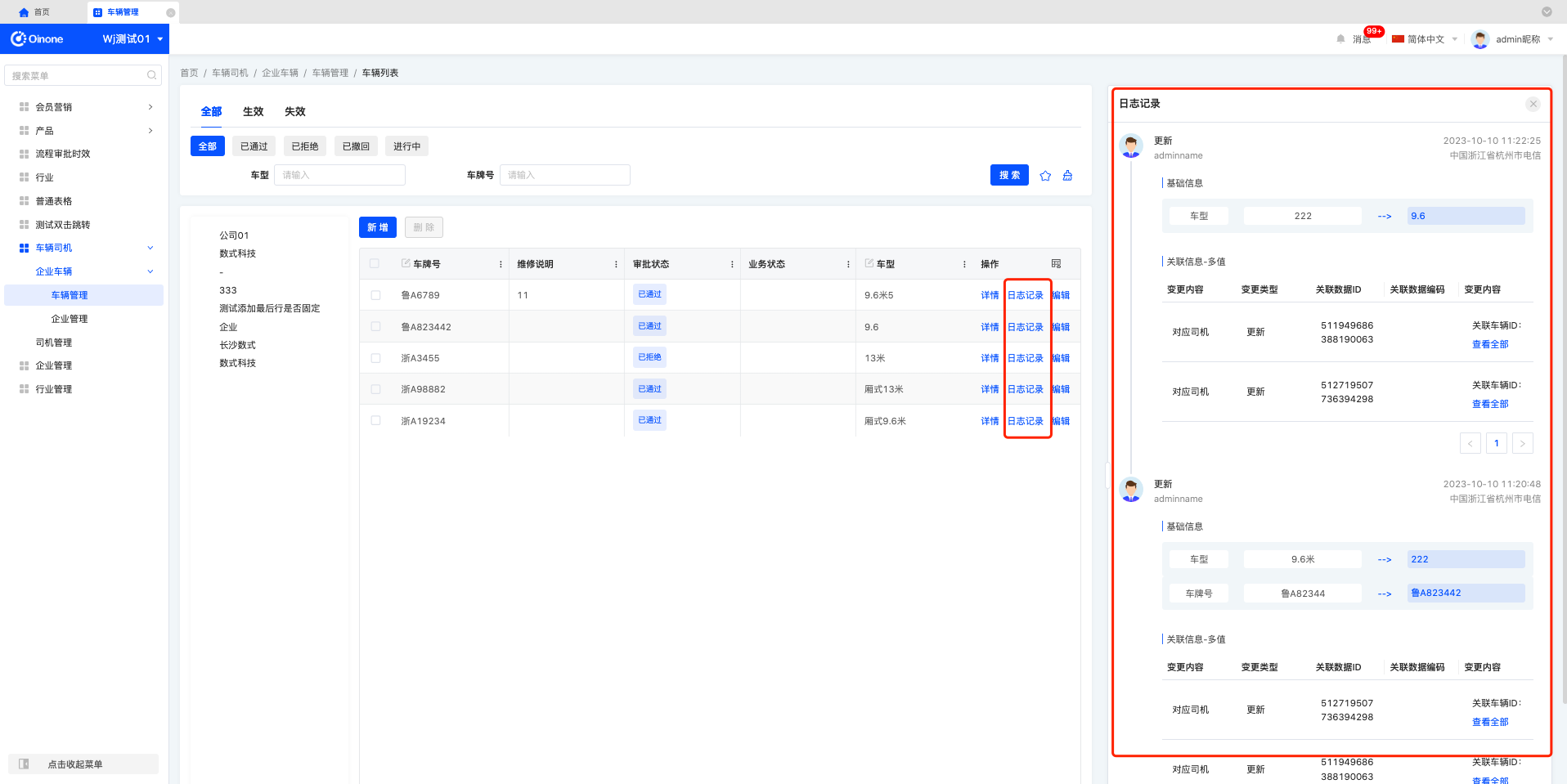
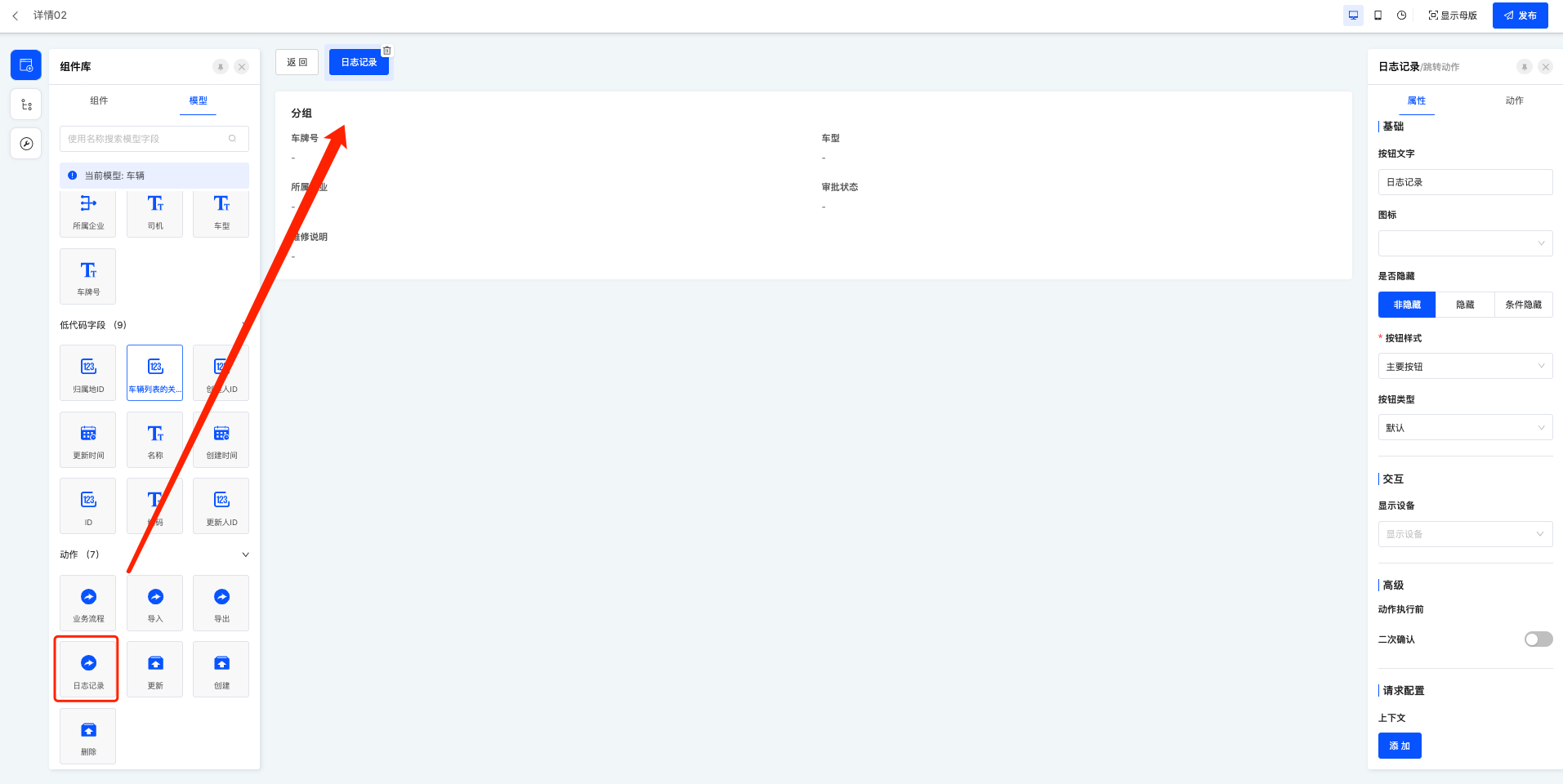
详情---日志记录
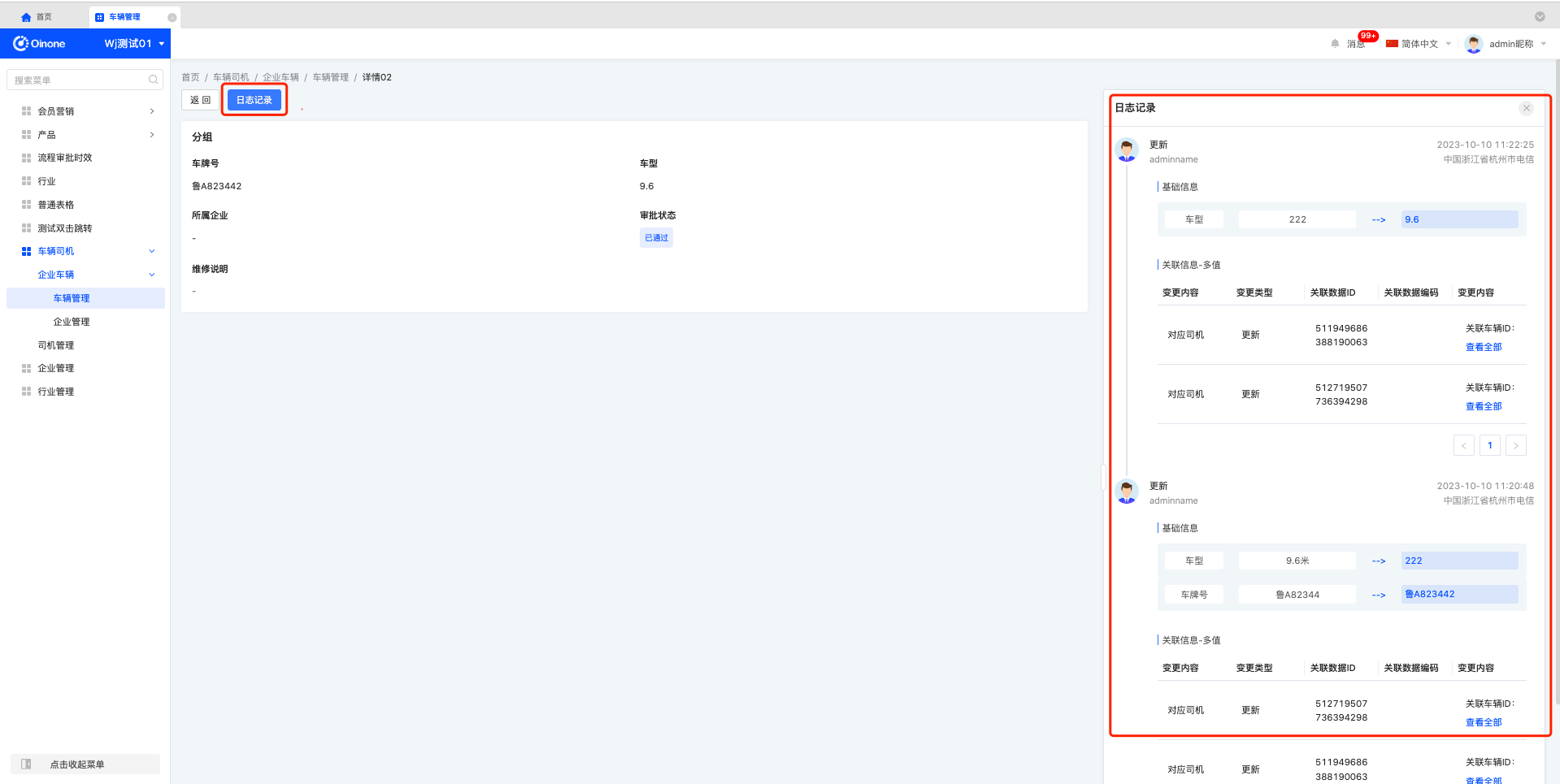
4.2. 操作步骤
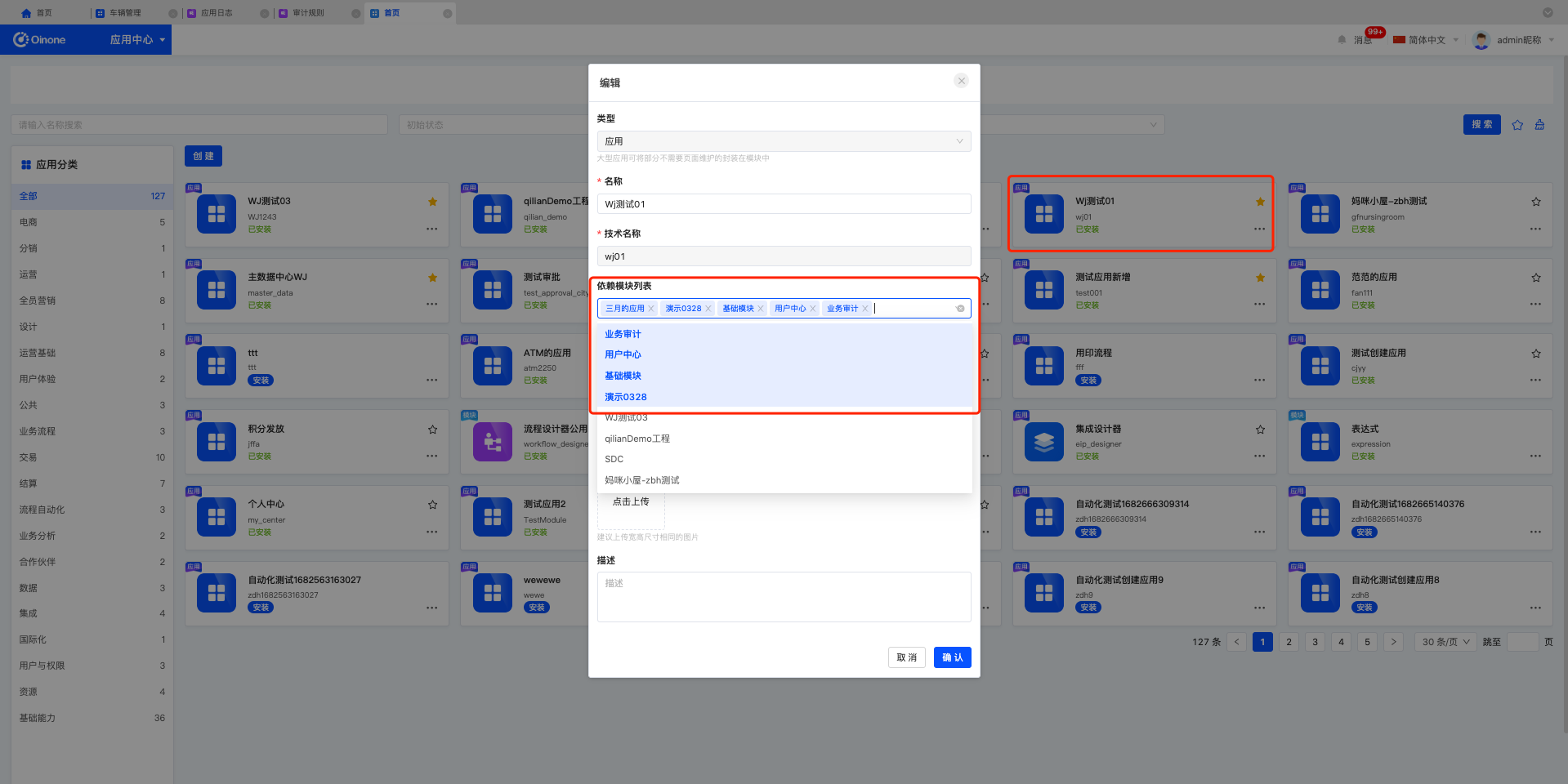
Step1:在应用中心,需要维护业务应用依赖业务审计应用;
操作入口:应用中心,找到业务应用——编辑,依赖模块选择业务审计。
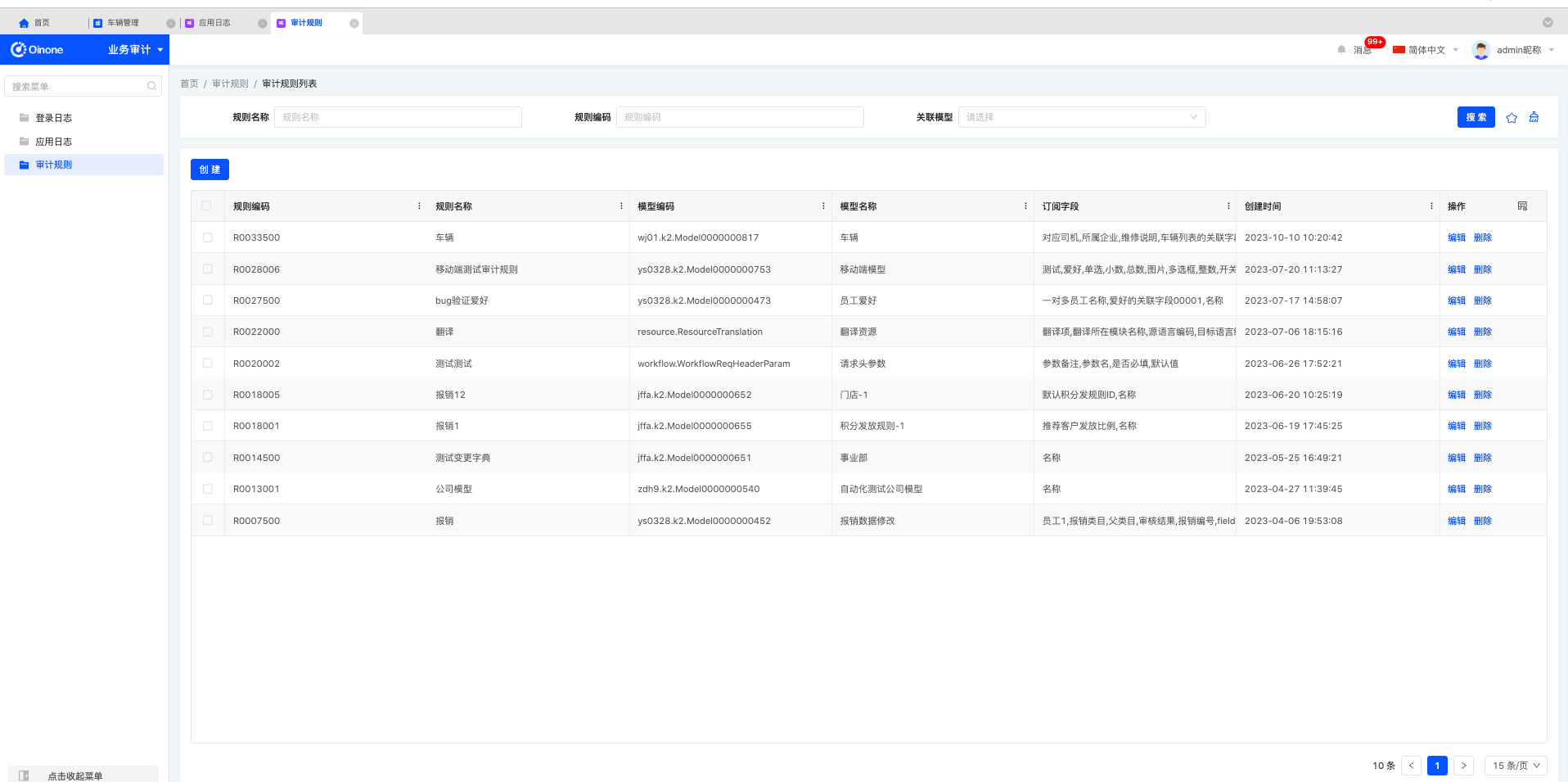
Step2:配置审计规则;
操作入口:业务审计应用——审计规则——新增规则。
Step2:界面设计器配置日志记录;
操作入口:界面设计器,找到需要配置的页面——模型组件,将动作区的日志记录拖动到页面中。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9397.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验