
,视图的大致配置在3.5.2.2【构建View的Template】一文中已经介绍过,这里主要介绍视图层的基本属性配置,这些配置会透传给视图内的组件Widget,组件会根据配置内容做出不同的呈现样式
视图的配置
Table的配置
| 配置项 | 可选值 | 默认值 | 作用 |
|---|---|---|---|
| activeCount | number | 5 | 表格上方动作区默认展示操作的数量,超过个数的操作将被折叠收起 |
| inlineActiveCount | number | 3 | 表格最右侧操作列默认展示操作的数量,超过个数的操作将被折叠收起 |
| defaultPageSize | number | 30 | 表格默认分页条数 |
Form/Detail的配置
| 配置项 | 可选值 | 默认值 | 作用 |
|---|---|---|---|
| direction | horizontal/vertical(大小写不明感) | vertical | 表单标题排列方式 |
Table的配置项举例
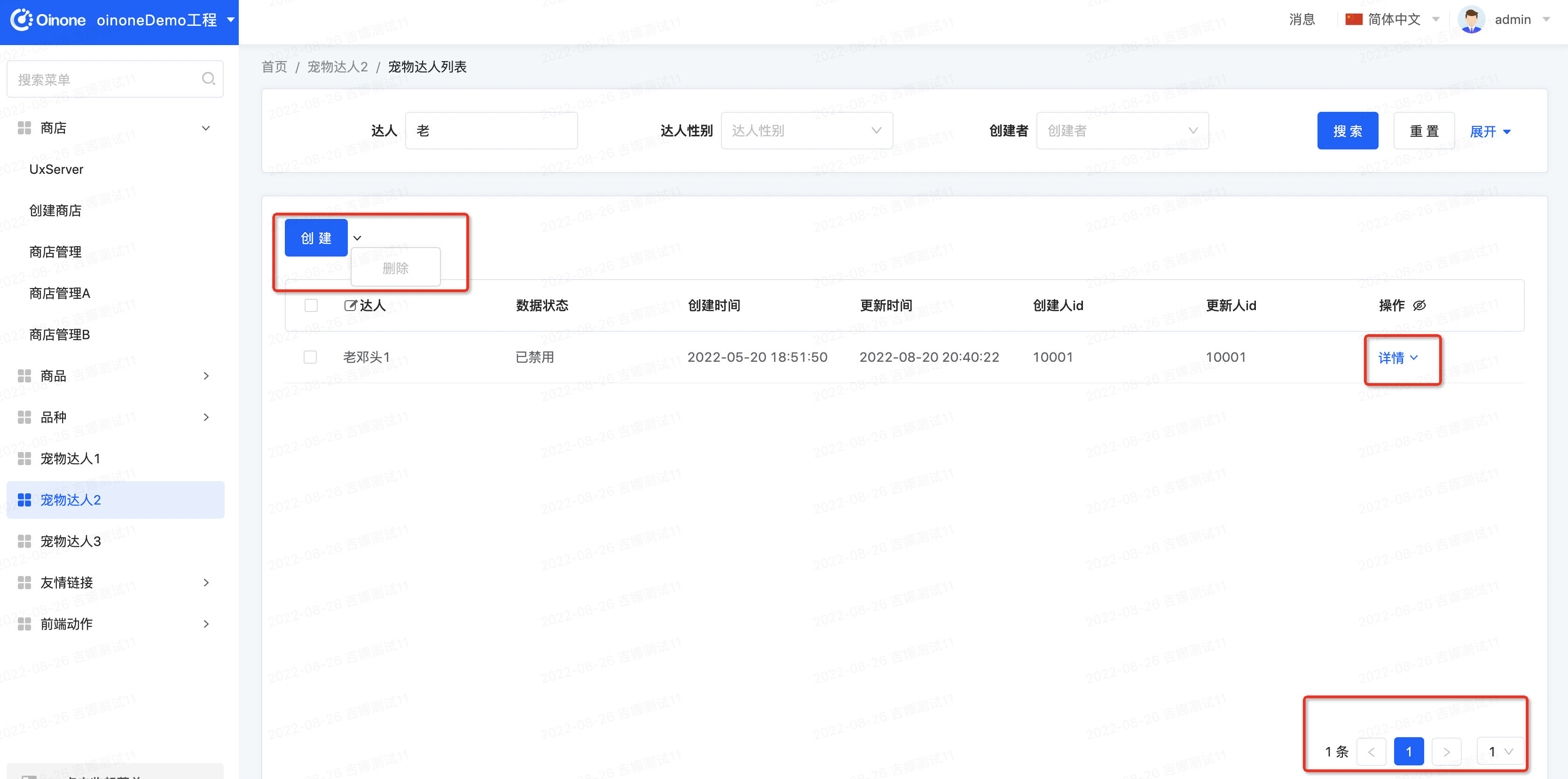
Step1 修改宠物达人的表格视图
我们在宠物达人的自定义表格视图的Template文件中增加三个属性配置activeCount="1" 、inlineActiveCount="1"、 defaultPageSize="1"
<view name=tableView model=demo.PetTalent cols=1 activeCount=1 inlineActiveCount=1 defaultPageSize=1 type=TABLE enableSequence=true >
</view>
Step2 重启看效果

Form的配置举例
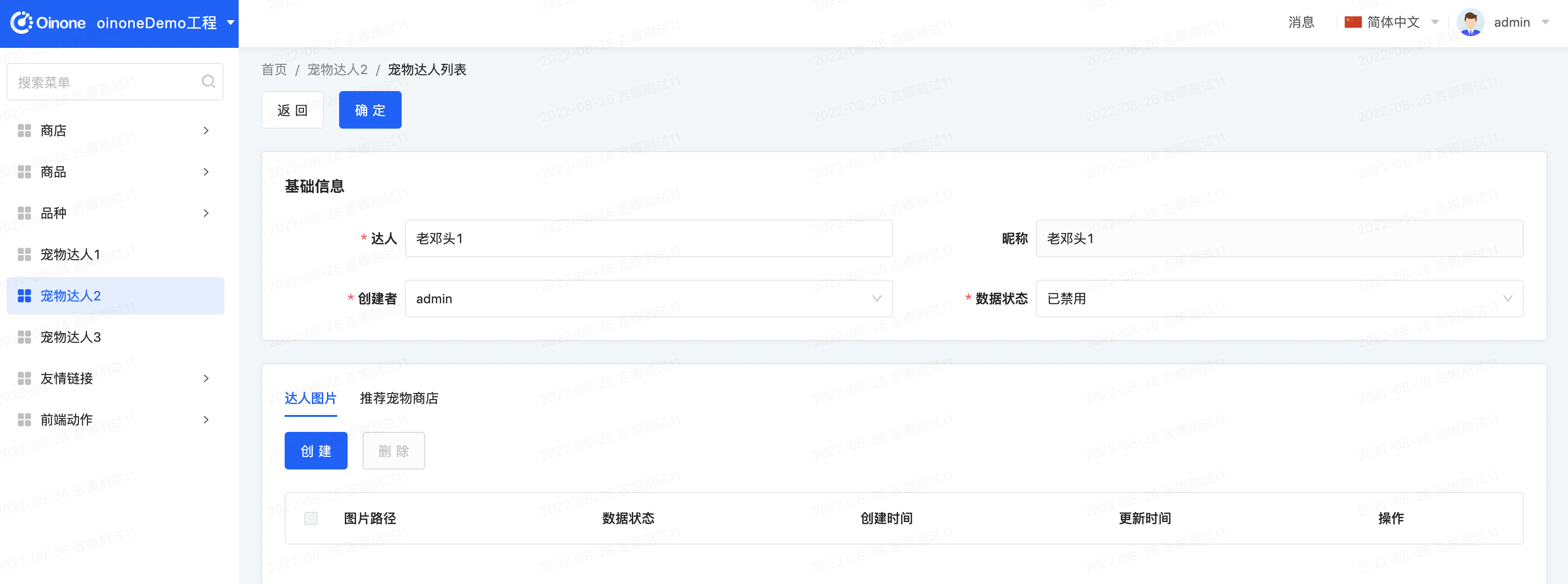
Step1 修改宠物达人的表单视图
我们在宠物达人的自定义表格视图的Template文件中增加一个属性配置direction = horizontal 。 另:宠物达人在之前的教程中增加了一些字段,大家利用默认视图把新增字段也展示出来。还是通过数据库查看默认页面定义,找到base_view表,过滤条件设置为model =\'demo.PetTalent\' and name =\'formView\',查看template字段,把里面涉及新增字段复制到pet_talent_form.xml文件中。
<view name=formView1 model=demo.PetTalent cols=2 type=FORM priority=1 direction = horizontal>
</view>direction = "horizontal"Step2 重启看效果
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9261.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验