
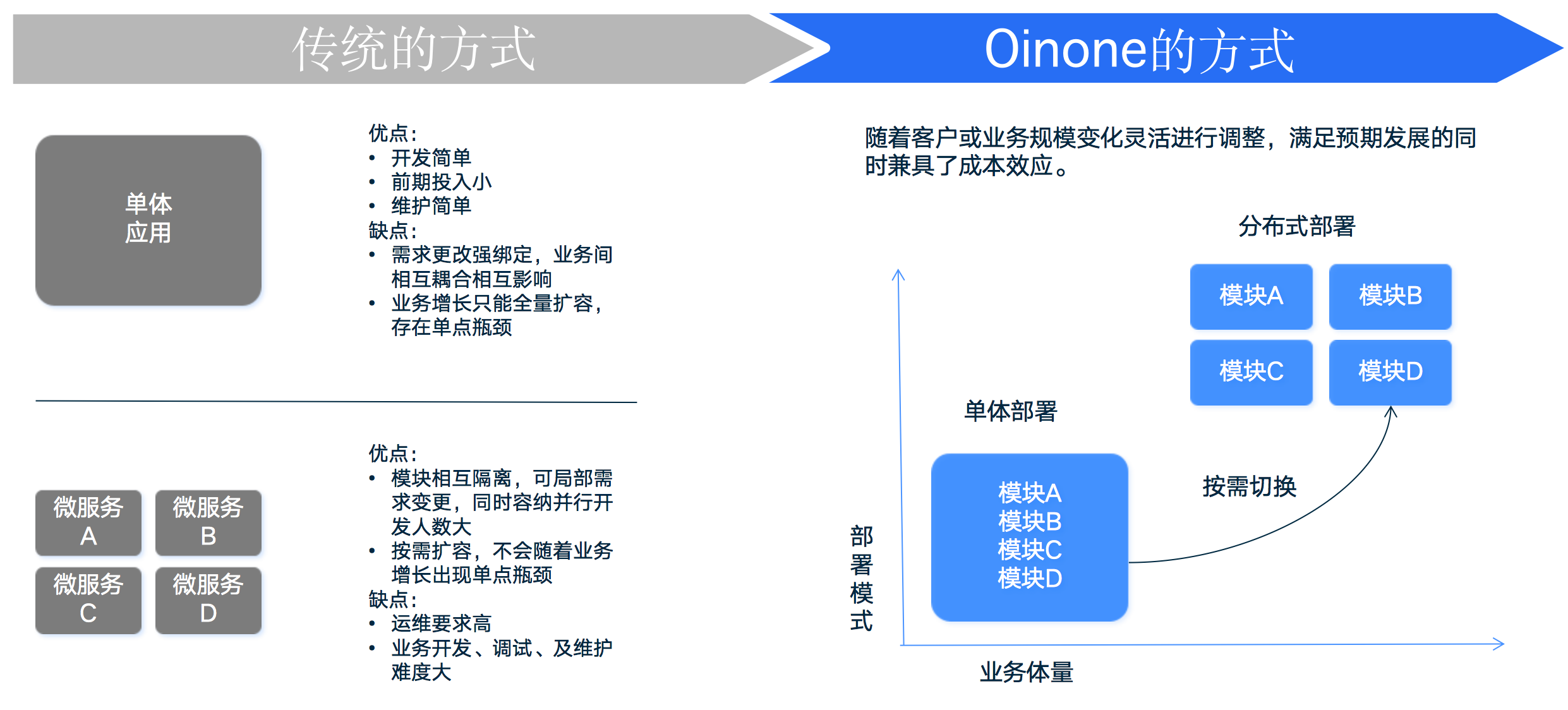
企业数字化转型需要处理分布式带来的复杂性和成本问题。尽管这些问题令人望而却步,但分布式架构对于大部分企业仍然是必须的选择。如果一个低代码平台缺乏分布式能力,那么它的性能就无法满足客户的要求。相比之下,Oinone平台通过对部署的创新(如图2-6所示),成功实现了分布式架构的支持,而且能够按照客户的业务发展需求,灵活选择不同的部署模式,同时节约企业成本,提升创新效率。这一创新是Oinone平台与其他低代码平台的重要区别,能够满足客户预期发展并兼顾成本效益。

实现原理
要实现灵活部署的特性,必须满足两个基本要求:
-
开发过程中不需要过多关注分布式技术,就像开发单体应用一样简单。代码在运行时应该能够根据模块是否在运行容器中,来决定路由走本地还是远程。这样可以大大减少研发人员的工作量和技术复杂度。
-
研发与部署要分离,即"开发单体应用一样开发分布式应用,而部署形式由后期决定"。为此,我们的工程结构支持多种启动模式,并逐一介绍了针对不同场景的工程结构类型(如下图2-7所示)。这样可以让客户在后期根据业务发展情况和需求,选择最适合的部署模式,从而达到灵活部署的目的。

图2-7 Oinone工程结构梳理
在整个工程结构上,我们秉承了Spring Boot的规范,不会改变大家的工程习惯。而Oinone的部署能力则可以让我们更灵活地应对各种情况。现在,我们来逐一介绍几种常规的工程结构以及它们适用的场景:
-
单模块工程结构(常规操作)
a. 这是非常标准的Spring Boot工程,适用于简单的应用场景开发以及入门学习。
-
多模块工程结构(常规操作)
a. 这是非常标准的多Spring Boot工程,可以实现分布式独立启动,适用于常规的分布式应用场景开发。
-
多模块工程结构-独立boot工程模式
a. 这种工程结构在多模块工程的基础上,通过独立的boot工程来支撑多部署方式。适用于中大型分布式应用场景开发。
b. 然而,随着工程越来越多,我们也会面临一些问题:
ⅰ研发:环境准备非常困难,每个模块都要单独启动,研发调试跟踪困难。
ⅱ部署:分布式的高可靠性保证需要每个模块至少有两个部署节点,但在模块较多的情况下,起步成本非常高。同时,企业初期业务不稳定且规模较小,使用多模块工程的第二种模式会增加问题排查难度和成本。
c. 此时,Oinone的多模块工程下的独立boot工程模式部署就可以发挥其灵活性,让研发和业务起步阶段可以选择all-in-one模式,等到业务发展到一定规模的时候,只需要把线上部署模式切换成模块独立部署,而研发还可以保留all-in-one模式的优势。
d. 值得注意的是,分分合合的部署模式在传统互联网架构和低代码或无代码平台上都是有代价的,但是Oinone却可以灵活适配,只需要在boot工程的yml文件中写入需要加载的模块就可以解决。此处我们仅介绍多模块加载配置,选择性忽略其他无关配置,具体配置(如下图2-8所示)。
pamirs: boot: init: true sync: true modules: - base - resource - sequence - user - auth - web tenants: - pamirs图2-8 Oinone yml配置图 大型多场景工程结构-独立boot工程模式:
a. 在多模块工程结构基础上的加强版,增加CDM层设计,让不同场景即保持数据统一,又保持逻辑独立。这种工程结构特别适用于大型企业软件开发,其中涉及到多个场景的情况,例如B端和C端的应用,或者跨不同业务线的应用,能够保证数据的一致性,同时也能够保持逻辑独立,避免不同场景间的代码冲突。
b. 这种工程结构是我们Oinone支撑“企业级软件生态”的核心,我们可以把场景A当作我们官方应用,场景B当作其他第三方伙伴应用。在这个工程结构下,我们的客户可以定制化开发自己的应用,同时我们也可以通过这种模式来支持我们的伙伴们进行开发,实现多方共赢。
c. 基于独立boot工程模式,我们同样对应多种部署模式应对不同情况,并统一管理所有伙伴应用。这种工程结构的优点是扩展性好,可以支持不同规模的应用,并且可以根据需要进行快速扩展或缩小规模,具有很高的灵活性。
-
基于标准产品的二开工程结构,是指基于标准产品进行二次开发,满足客户特定需求的工程结构。这种模式下,Oinone提供标准产品,客户可以根据自己的需求进行二次开发,实现定制化需求,同时可以利用我们的模块化开发特性,将每一个需求作为一个模块进行开发和管理。这种工程结构的优点是能够快速满足客户特定需求,同时也具有很好的可维护性和可扩展性,因为每个需求都是一个独立的模块,可以方便地进行维护和扩展。在下一篇“Oinone独特性之每一个需求都是一个模块”文章中有详细介绍。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9220.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验