
一、拦截器
拦截器为平台满足条件的函数以非侵入方式根据优先级扩展函数执行前和执行后的逻辑。
使用方法上的@Hook注解可以标识方法为拦截器。前置扩展点需要实现HookBefore接口;后置扩展点需要实现HookAfter接口。入参包含当前拦截函数定义与该函数的入参。拦截器可以根据函数定义与入参增加处理逻辑。
拦截器分为前置拦截器和后置拦截器,前者的出入参为所拦截函数的入参,后者的出入参为所拦截函数的出参。可以使用@Hook注解或Hook模型的非必填字段module、model、fun、函数类型、active来筛选出对当前拦截方法所需要生效的拦截器。若未配置任何过滤属性,拦截器将对所有函数生效。
根据拦截器的优先级priority属性可以对拦截器的执行顺序进行调整。priority数字越小,越先执行。
二、前置拦截(举例)
增加一个前置拦截,对PetShop的sayHello函数进行前置拦截,修改函数的入参的shopName属性,在其前面增加"hookbefore:"字符串。并查看效果
Step1 新增PetShopSayHelloHookBefore实现HookBefore接口
为run方法增加@Hook注解
-
配置module={DemoModule.MODULE_MODULE},这里module代表的是执行模块,该Hook只匹配由DemoModule模块为发起入口的请求
-
配置model={PetShop.MODEL_MODEL},该Hook只匹配PetShop模型
-
配置fun={"sayHello"},该Hook只匹配函数编码为sayHello的函数
package pro.shushi.pamirs.demo.core.hook;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.DemoModule;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.meta.annotation.Hook;
import pro.shushi.pamirs.meta.api.core.faas.HookBefore;
import pro.shushi.pamirs.meta.api.dto.fun.Function;
@Component
public class PetShopSayHelloHookBefore implements HookBefore {
@Override
@Hook(module = {DemoModule.MODULE_MODULE},model = {PetShop.MODEL_MODEL},fun = {"sayHello"})
public Object run(Function function, Object... args) {
if(args!=null && args[0]!=null){
PetShop arg = (PetShop)args[0];
arg.setShopName("hookbefore:"+ arg.getShopName());
}
return args;
}
}
Step2 重启查看效果
用graphQL工具Insomnia查看效果,如果访问提示未登陆,则请先登陆。详见3.4.1【构建第一个Function】一文
- 用 http://127.0.0.1:8090/pamirs/base 访问,结果我们会发现PetShopSayHelloHookBefore不起作用。是因为本次请求是以base模块作为发起模块,而我们用module={DemoModule.MODULE_MODULE}声明了该Hook只匹配由DemoModule模块为发起入口的请求
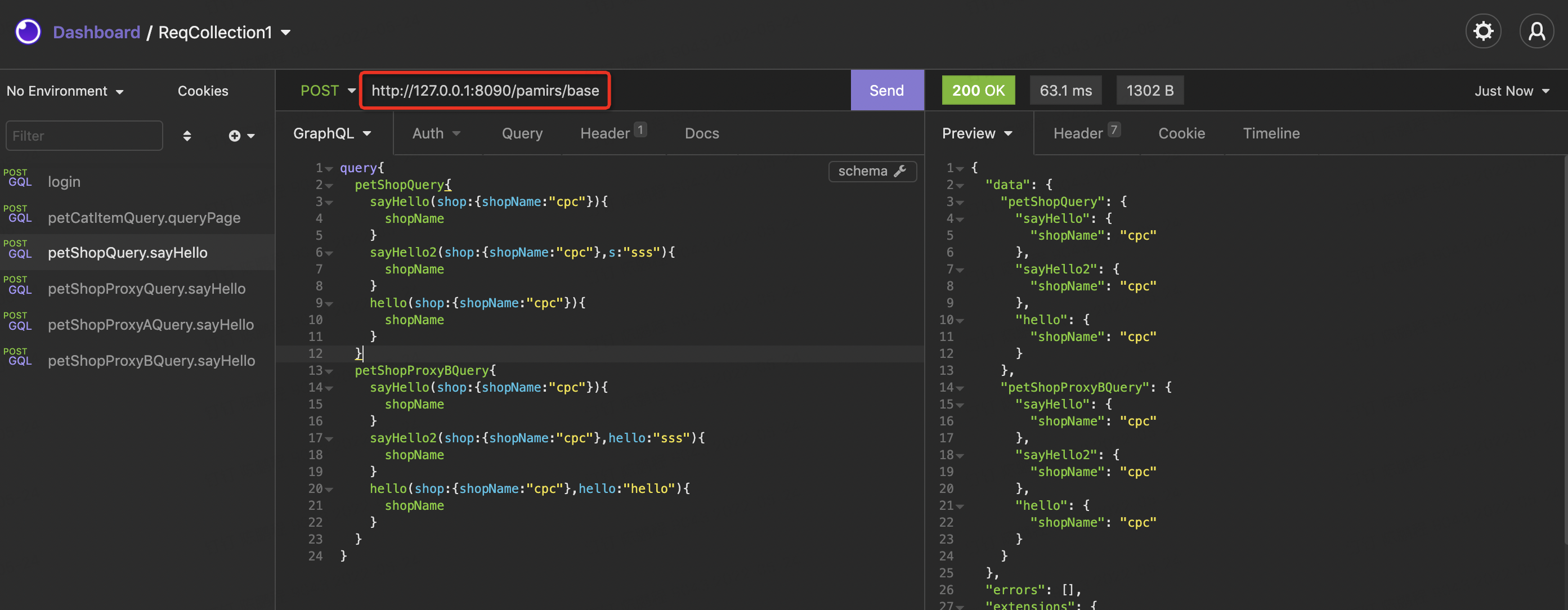

- 用 http://127.0.0.1:8090/pamirs/demoCore 访问,前端是以模块名作为访问入口不是模块编码这里大家要注意下
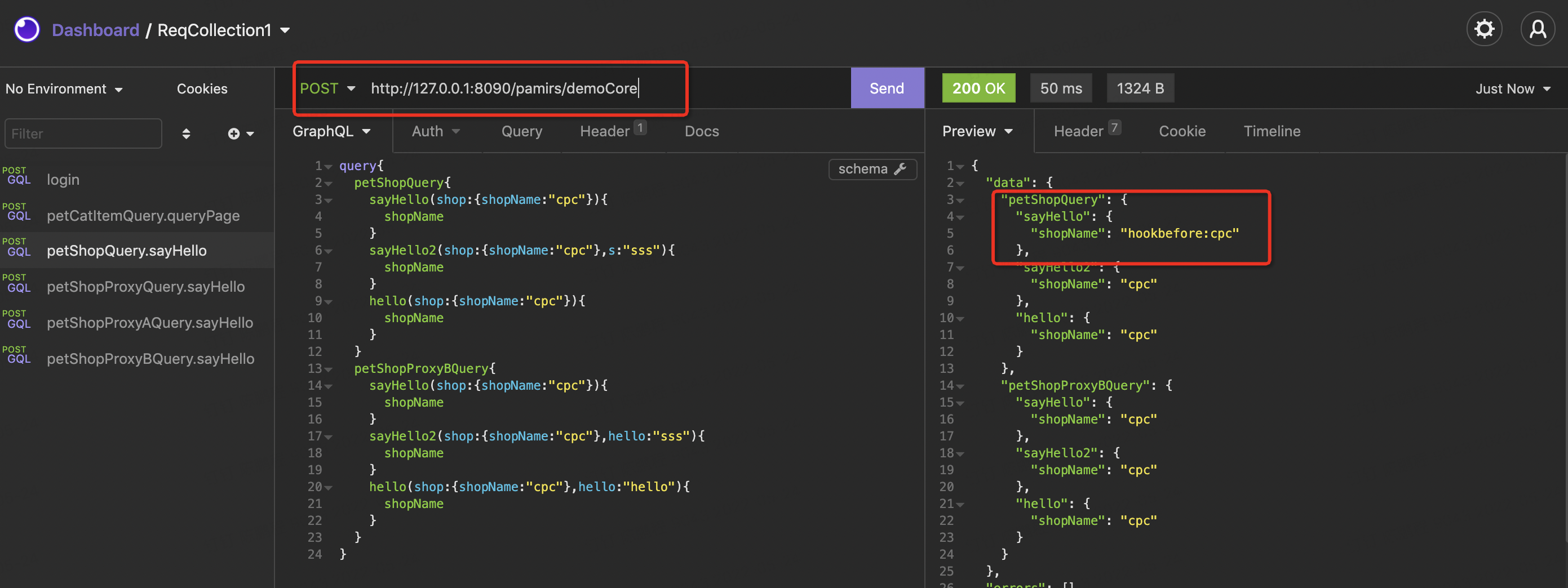
- 用 http://127.0.0.1:8090/pamirs/demoCore 访问,更换到petShop的子模型petShopProxy来访问sayHello函数,结果我们发现是没有效果的。因为配置model={PetShop.MODEL_MODEL},该Hook只匹配PetShop模型
三、后置拦截(举例)
增加一个后置拦截,对PetShop的sayHello函数进行后置拦截,修改函数的返回结果的shopName属性,在其后面增加"hookAfter:"字符串。并查看效果
Step1 新增PetShopSayHelloHookAfter实现HookAfter接口
为run方法增加@Hook注解
-
配置model={PetShop.MODEL_MODEL},该Hook只匹配PetShop模型
-
配置fun={"sayHello"},该Hook只匹配函数编码为sayHello的函数
package pro.shushi.pamirs.demo.core.hook;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.meta.annotation.Hook;
import pro.shushi.pamirs.meta.api.core.faas.HookAfter;
import pro.shushi.pamirs.meta.api.dto.fun.Function;
@Component
public class PetShopSayHelloHookAfter implements HookAfter {
@Override
@Hook(model = {PetShop.MODEL_MODEL},fun = {"sayHello"})
public Object run(Function function, Object ret) {
if (ret == null) {
return null;
}
PetShop result =null;
if (ret instanceof Object[]) {
Object[] rets = (Object[])((Object[])ret);
if (rets.length == 1) {
result = (PetShop)rets[0];
}
} else {
result = (PetShop)ret;
}
result.setShopName(result.getShopName()+":hookAfter");
return result;
}
}
Step2 重启查看效果
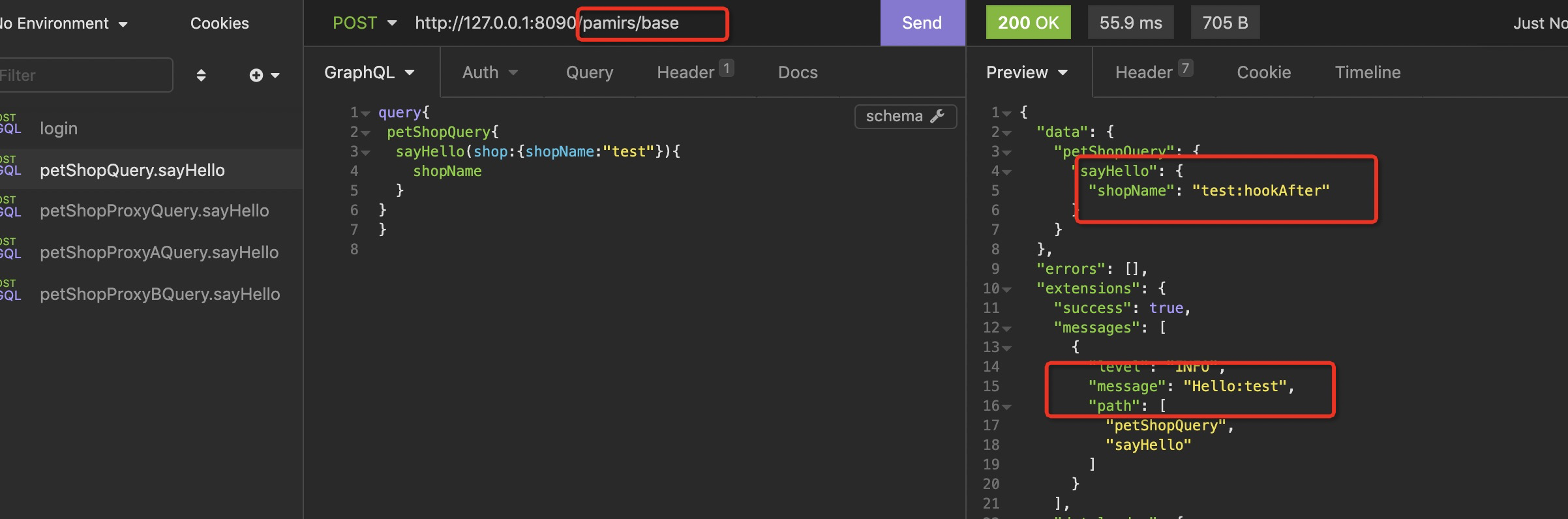
- 用 http://127.0.0.1:8090/pamirs/base 访问,结果我们会发现PetShopSayHelloHookAfter是起作用。PetShopSayHelloHookBefore没有配置模块过滤。
- 用访问,结果我们会发现PetShopSayHelloHookAfte和PetShopSayHelloHookBefore同时起作用
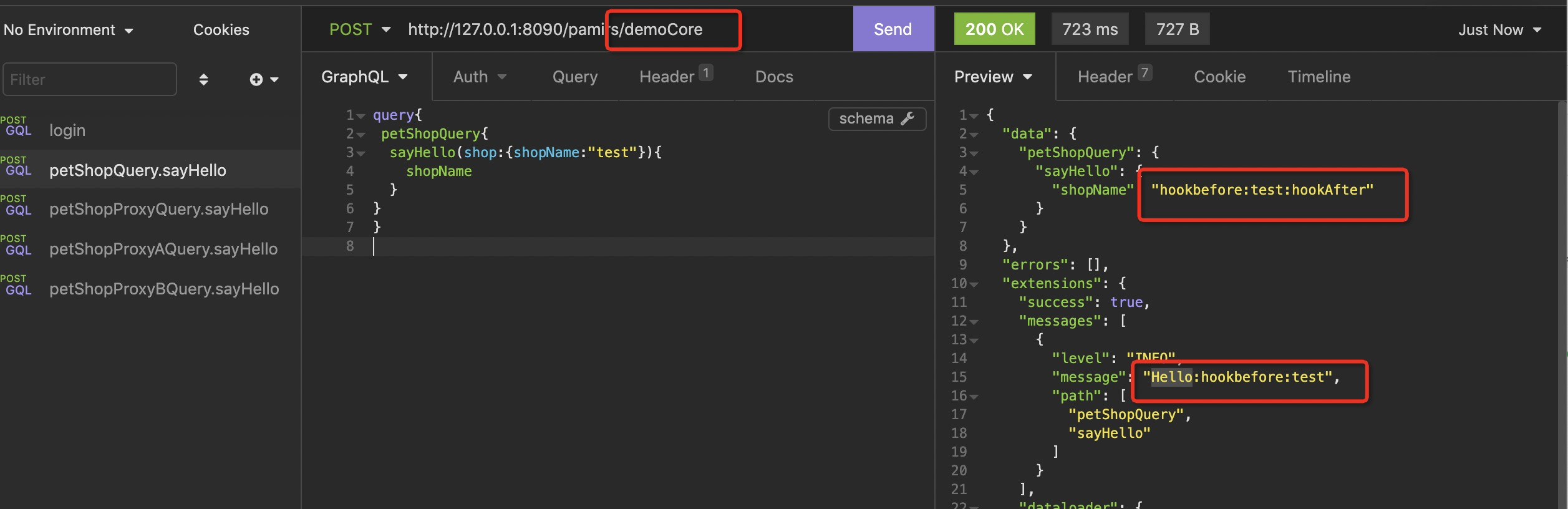
- 我们会发现HookAfter只对结果做了修改,所以message中可以看到hookbefore,但看不到hookAfter
四、注意点
-
不管前置拦截器,还是后置拦截器都可以配置多个,根据拦截器的优先级priority属性可以对拦截器的执行顺序进行调整。priority数字越小,越先执行。小伙伴们可以自行尝试
-
拦截器必须是jar依赖,不然执行会报错。特别是有的小伙伴配置了一个没有过滤条件的拦截器,就要非常小心
-
模块启动yml文件可以过滤不需要执行的hook,具体配置详见4.1.1【模块之yml文件结构详解】一文
-
调用入口不是由前端发起而是后端编程中直接调用,默认不会生效,如果要生效请参考4.1.9【函数之元位指令】一文
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9247.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验