
异步任务是非常常见的一种开发模式,它在分布式的开发模式中有很多应用场景如:
-
高并发场景中,我们一般采用把长流程切短,用异步方式去掉可以异步的非关键功能,缩小主流程响应时间,提升用户体验
-
异构系统的集成调用,通过异步任务完成解耦与自动重试
-
分布式系统最终一致性的可选方案
今天我们了解oinone是如何结合Spring+TbSchedule来完成异步任务
一、TbSchedule介绍
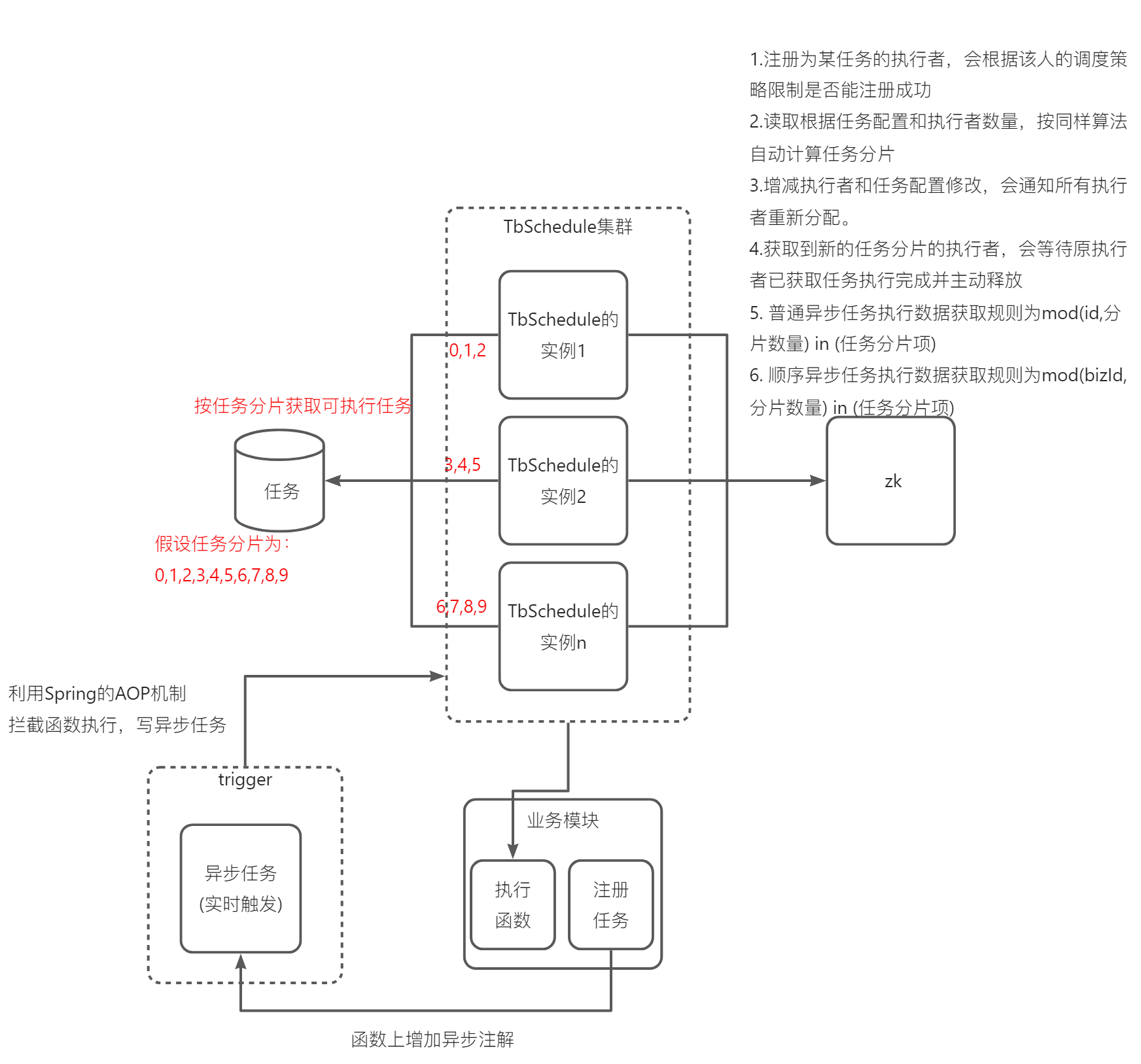
它是一个支持分布式的调度框架,让批量任务或者不断变化的任务能够被动态的分配到多个主机的JVM中,在不同的线程组中并行执行,所有的任务能够被不重复,不遗漏的快速处理。基于ZooKeeper的纯Java实现,由Alibaba开源。在互联网和电商领域TBSchedule的使用非常广泛,目前被应用于阿里巴巴、淘宝、支付宝、京东、聚美、汽车之家、国美等很多互联网企业的流程调度系统。也是笔者早期在阿里参与设计的一款产品。
oinone的异步任务执行原理(如下图4-1-11-1所示),先做一个大致了解:

基础管理工具
下载tbSchedule的控制台jar包去除文件后缀.txt(详见本书籍【附件一】)pamirs-middleware-schedule-console-3.0.1.jar.txt(31.2 MB)
启动控制台
java -jar pamirs-middleware-schedule-console-3.0.1.jar
访问地址
http://127.0.0.1:10014/schedule/index.jsp?manager=true
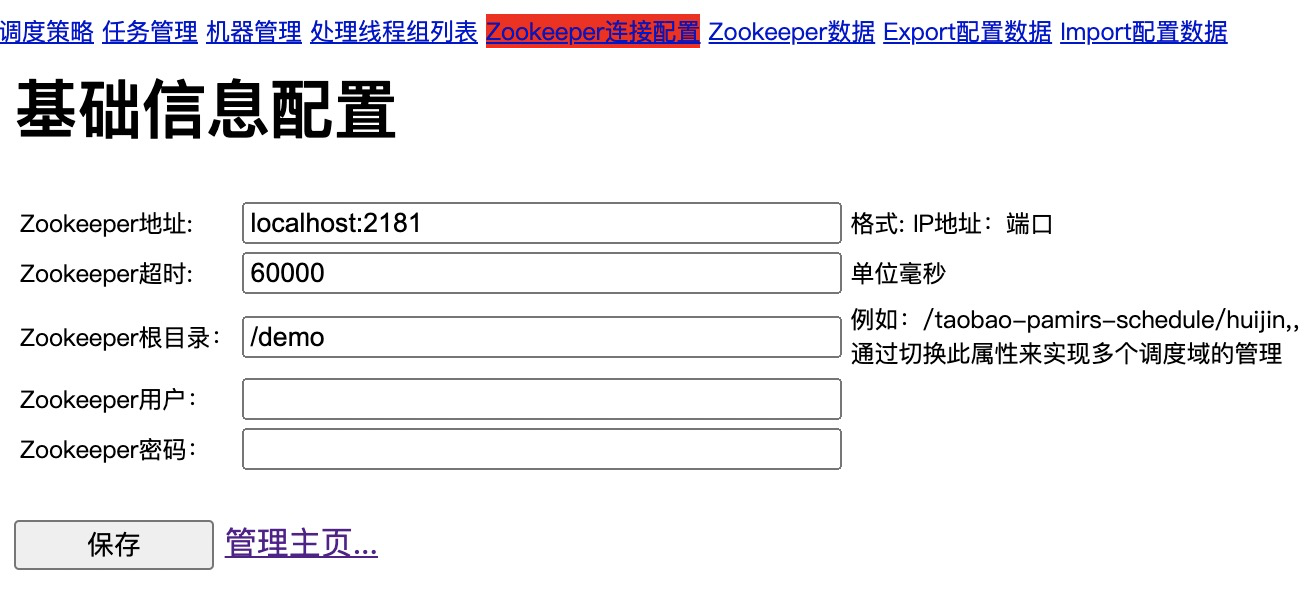
配置zk连接参数
oinone默认实现任务类型
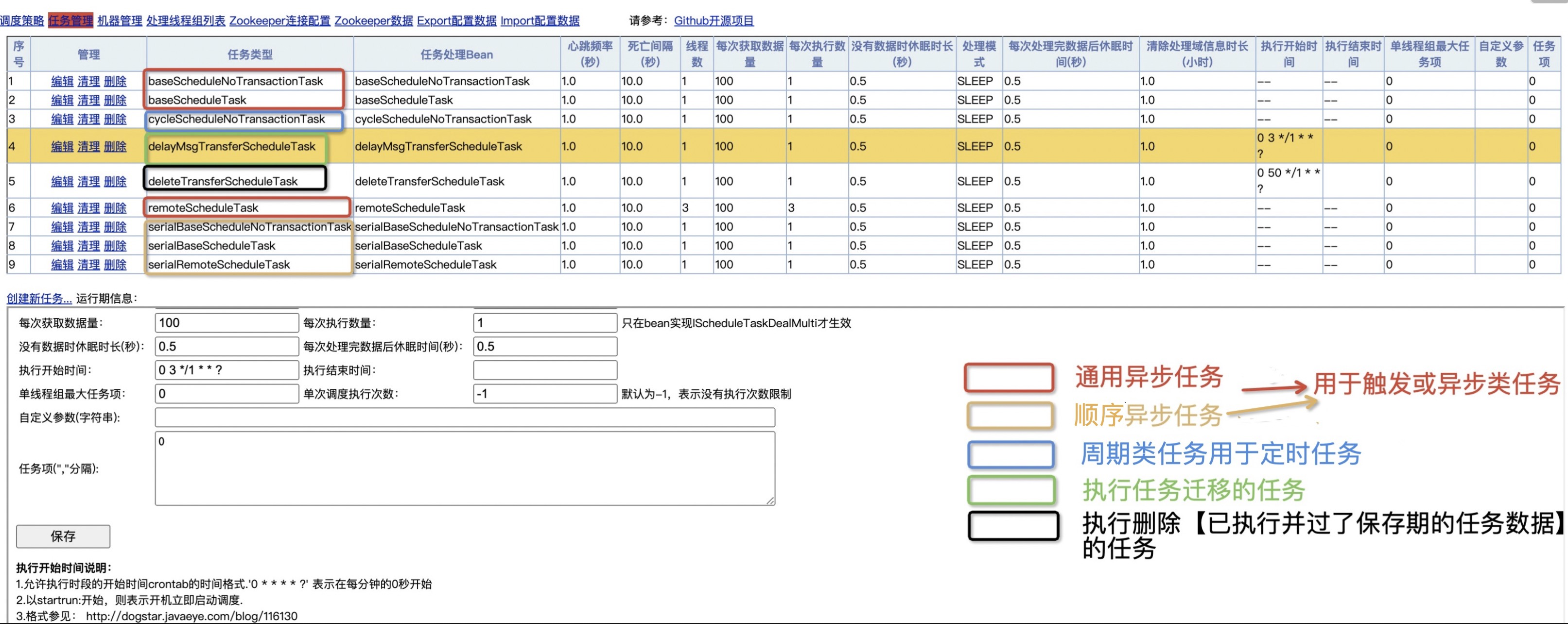
- baseScheduleNoTransactionTask
- baseScheduleTask
- remoteScheduleTask --- 适用于pamirs-middleware-schedule独立部署场景
- serialBaseScheduleNoTransactionTask
- serialBaseScheduleTask
- serialRemoteScheduleTask --- 适用于pamirs-middleware-schedule独立部署场景
- cycleScheduleNoTransactionTask
- delayMsgTransferScheduleTask
- deleteTransferScheduleTask
注:
a. 默认情况下:所有任务的任务项都只配置了一个任务项0,只有一台机器能分配任务。
1. 如果要修改配置可以在启动项目中放置schedule.json,来修改配置
2. 人工进入控制修改任务对应任务项的配置b. 如果想为某一个核心任务配置的独立调度器,不受其他任务执行影响。那么见独立调度的异步任务
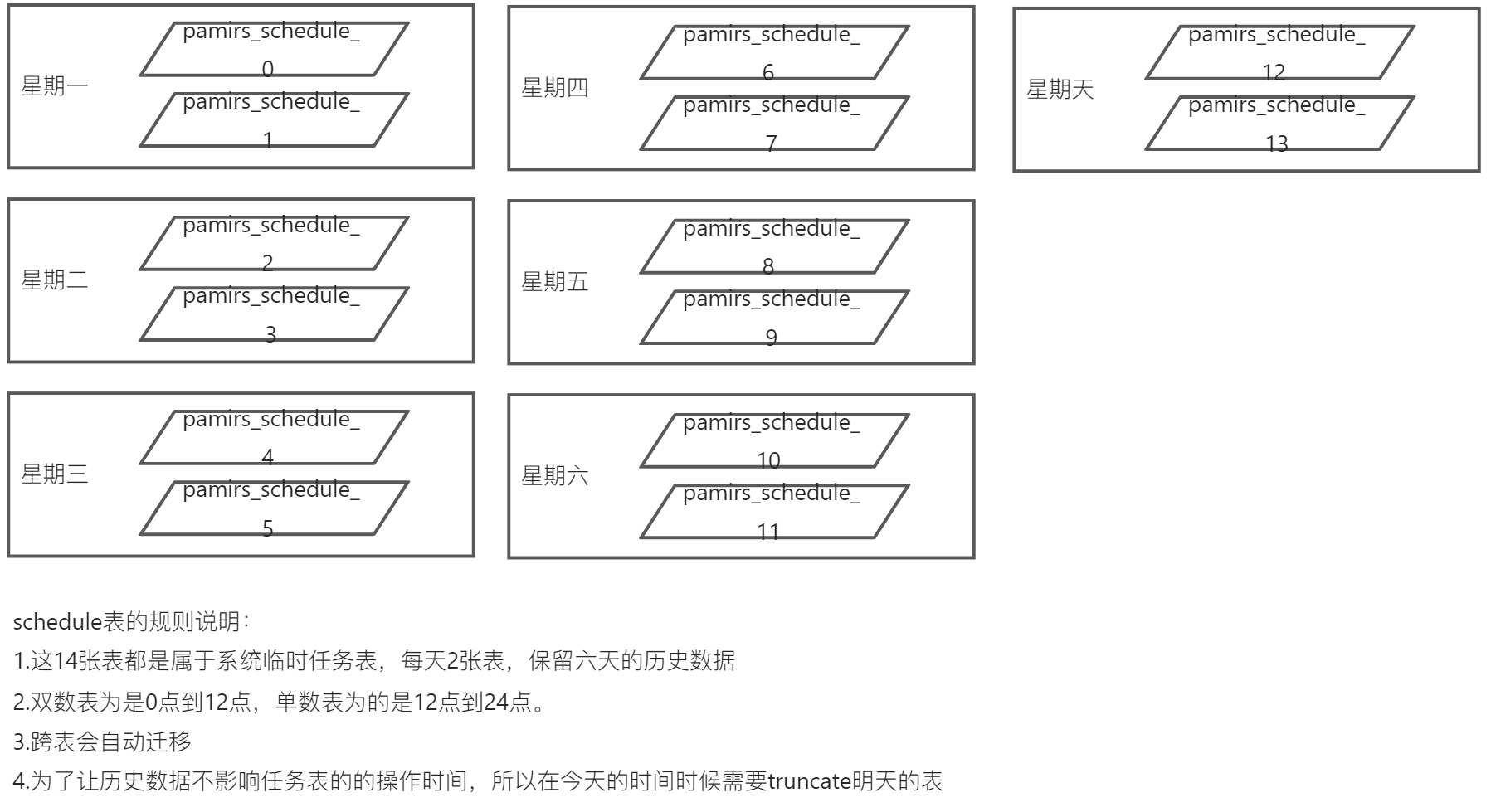
任务表相关说明
二、构建第一个异步任务(举例)
Step1 新建PetShopService和PetShopServiceImpl
1 新建PetShopService定义updatePetShops方法
package pro.shushi.pamirs.demo.api.service;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
import java.util.List;
@Fun(PetShopService.FUN_NAMESPACE)
public interface PetShopService {
String FUN_NAMESPACE = "demo.PetShop.PetShopService";
@Function
void updatePetShops(List<PetShop> petShops);
}-
PetShopServiceImpl实现PetShopService接口并在updatePetShops增加@XAsync注解
-
displayName = "异步批量更新宠物商店",定义异步任务展示名称
-
limitRetryNumber = 3,定义任务失败重试次数,,默认:-1不断重试
-
nextRetryTimeValue = 60,定义任务失败重试的时间数,默认:3
-
nextRetryTimeUnit,定义任务失败重试的时间单位,默认:TimeUnitEnum.SECOND
-
delayTime,定义任务延迟执行的时间数,默认:0
-
delayTimeUnit,定义任务延迟执行的时间单位,默认:TimeUnitEnum.SECOND
-
package pro.shushi.pamirs.demo.core.service;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.demo.api.service.PetShopService;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.trigger.annotation.XAsync;
import java.util.List;
@Fun(PetShopService.FUN_NAMESPACE)
@Component
public class PetShopServiceImpl implements PetShopService {
@Override
@Function
@XAsync(displayName = "异步批量更新宠物商店",limitRetryNumber = 3,nextRetryTimeValue = 60)
public void updatePetShops(List<PetShop> petShops) {
new PetShop().updateBatch(petShops);
}
}Step2 修改PetShopBatchUpdateAction的conform方法
-
引入PetShopService
-
修改conform方法
-
利用ArgUtils进行参数转化,ArgUtils会经常用到。
-
调用petShopService.updatePetShops方法
-
package pro.shushi.pamirs.demo.core.action;
…… 引依赖类
@Model.model(PetShopBatchUpdate.MODEL_MODEL)
@Component
public class PetShopBatchUpdateAction {
@Autowired
private PetShopService petShopService;
……其他代码
@Action(displayName = "确定",bindingType = ViewTypeEnum.FORM,contextType = ActionContextTypeEnum.SINGLE)
public PetShopBatchUpdate conform(PetShopBatchUpdate data){
if(data.getPetShopList() == null || data.getPetShopList().size()==0){
throw PamirsException.construct(DemoExpEnumerate.PET_SHOP_BATCH_UPDATE_SHOPLIST_IS_NULL).errThrow();
}
List<PetShopProxy> proxyList = data.getPetShopList();
for(PetShopProxy petShopProxy:proxyList){
petShopProxy.setDataStatus(data.getDataStatus());
}
Tx.build(new TxConfig().setPropagation(Propagation.REQUIRED.value())).executeWithoutResult(status -> {
new PetShopProxy().updateBatch(proxyList);
//利用ArgUtils进行参数转化
List<PetShop> shops = ArgUtils.convert(PetShopProxy.MODEL_MODEL, PetShop.MODEL_MODEL,proxyList);
petShopService.updatePetShops(shops);
// throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).errThrow();
});
return data;
}
}
Step3 重启看效果
异步会有一定的延迟,我们按以下步骤测试下异步执行效果
- 进入商店管理列表页,选择中一行数据点击批量更新数据状态按钮进入批量修改宠物商店数据状态页面:
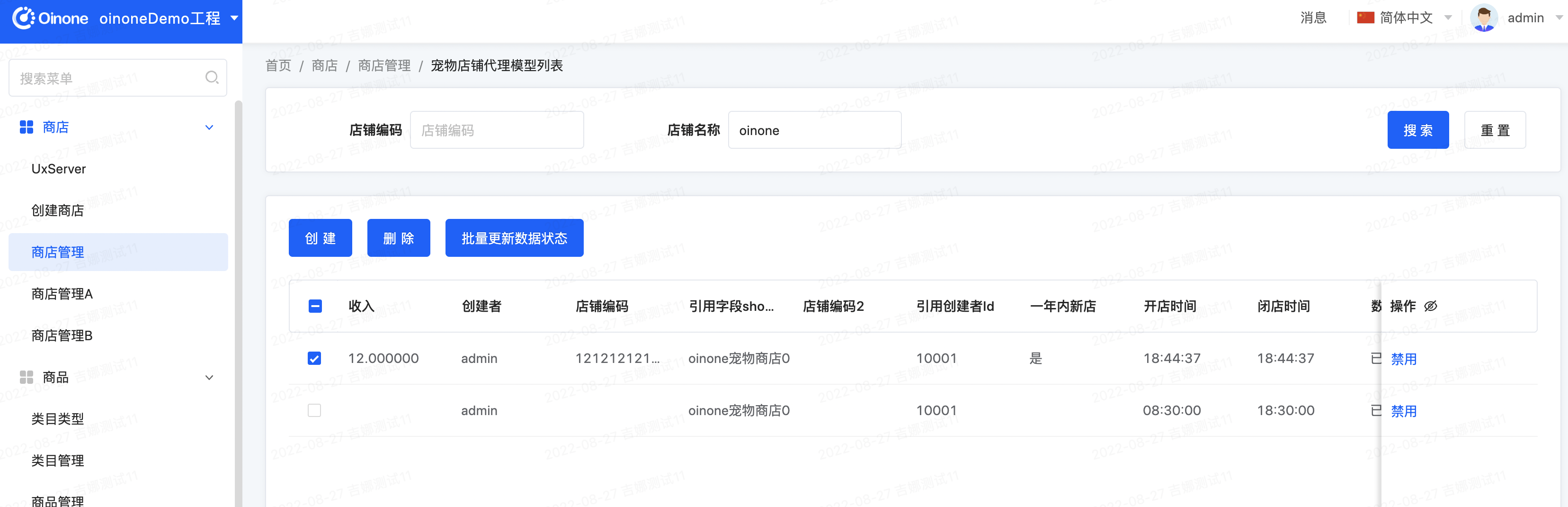
- 在批量修改宠物商店数据状态页面,数据状态设置为未启用,点击组合动作按钮回到商店管理列表页:
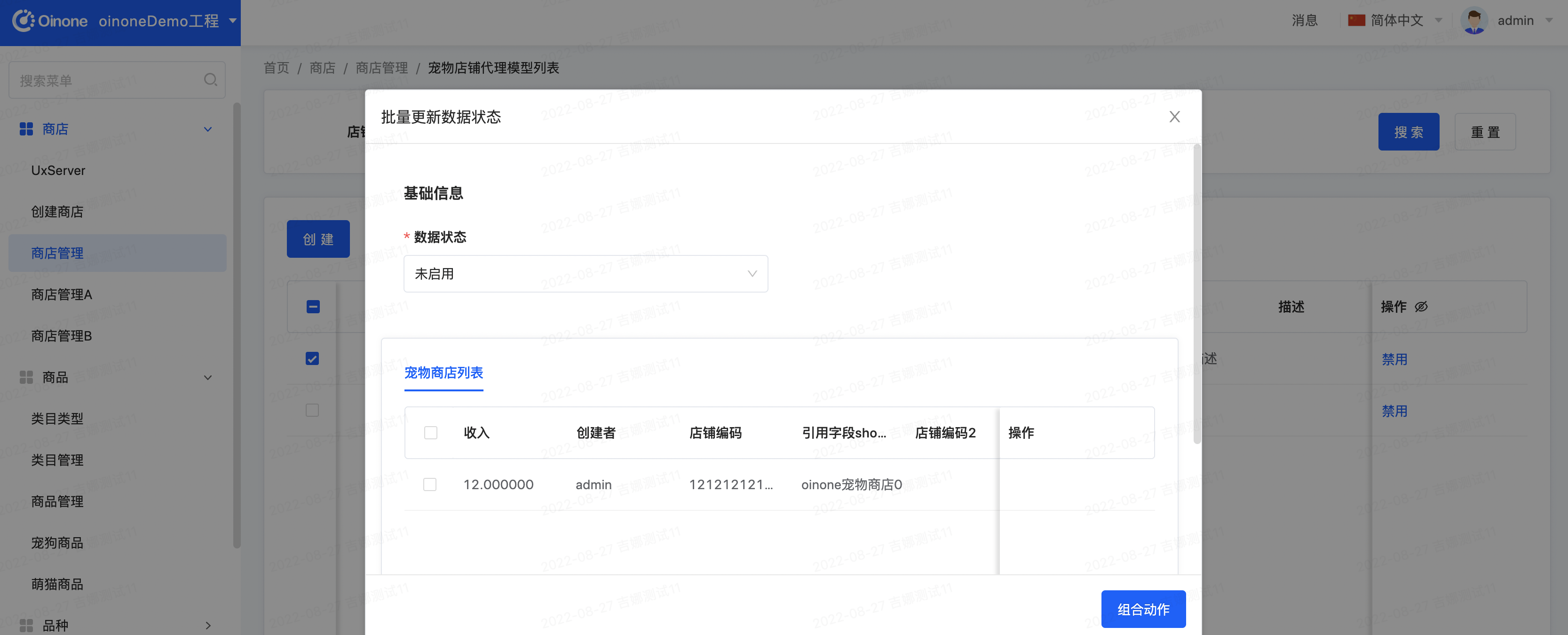
- 查看商店管理列表页的数据记录的数据状态字段是否修改成功,此时可能未修改成功,也可能已经修改成功,因为本身就是毫秒级的速度,点击搜索刷新数据,发现数据记录的数据状态字段修改成功:
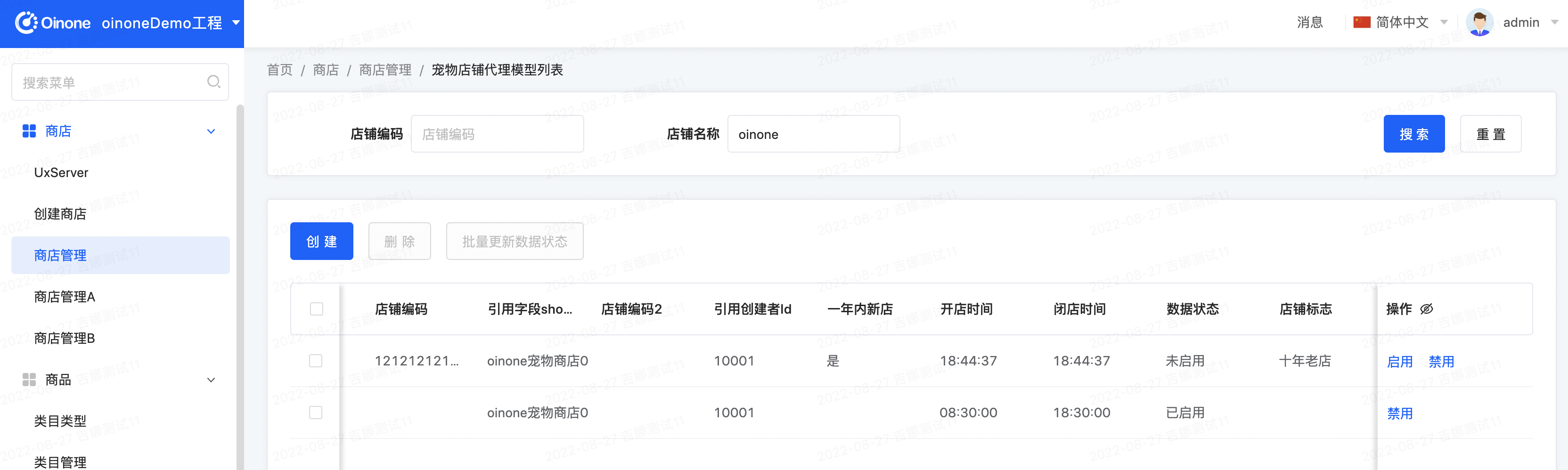
- 查看任务表,根据任务表与日期的对照关系查询指定表

三、异步任务高级玩法
顺序异步任务(举例)
这里的顺序任务是指把任务按一定规则分组以后按时间顺序串行执行,不同分组间的任务不相互影响。有点类似mq的顺序消息
eg:订单的状态变更的异步任务需要根据任务产生时间顺序执行。那么分组规则是按订单id分组,执行顺序按任务产生顺序执行
Step1 PetShopService和PetShopServiceImpl
- 修改PetShopService新增定义asyncSerialUpdatePetShops方法
package pro.shushi.pamirs.demo.api.service;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
import java.util.List;
@Fun(PetShopService.FUN_NAMESPACE)
public interface PetShopService {
String FUN_NAMESPACE = "demo.PetShop.PetShopService";
@Function
void updatePetShops(List<PetShop> petShops);
@Function
void asyncSerialUpdatePetShops(List<PetShop> petShops);
}-
修改PetShopServiceImpl实现ScheduleAction接口,并增加asyncSerialUpdatePetShops方法
-
引入executeTaskActionService用于提交异步串行任务ExecuteTaskAction
1.setExecuteNamespace(getInterfaceName()),确保跟getInterfaceName()一致
2.setExecuteFun("execute");跟执行函数名“execute”一致
3.setTaskType(TaskType.SERIAL_BASE_SCHEDULE_NO_TRANSACTION_TASK.getValue()),必须用SERIAL_BASE_SCHEDULE_NO_TRANSACTION_TASK,其为顺序执行任务类型
4.setBizId(petShop.getCreateUid())//根据创建人Id分组,根据实际业务情况决定
-
getInterfaceName()跟函数的命名空间保持一致
-
package pro.shushi.pamirs.demo.core.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.core.common.enmu.TimeUnitEnum;
import pro.shushi.pamirs.demo.api.model.PetShop;
import pro.shushi.pamirs.demo.api.service.PetShopService;
import pro.shushi.pamirs.framework.connectors.data.tx.interceptor.PamirsTransactional;
import pro.shushi.pamirs.meta.annotation.Fun;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.util.JsonUtils;
import pro.shushi.pamirs.middleware.schedule.api.ScheduleAction;
import pro.shushi.pamirs.middleware.schedule.common.Result;
import pro.shushi.pamirs.middleware.schedule.domain.ScheduleItem;
import pro.shushi.pamirs.middleware.schedule.eunmeration.TaskType;
import pro.shushi.pamirs.trigger.annotation.XAsync;
import pro.shushi.pamirs.trigger.model.ExecuteTaskAction;
import pro.shushi.pamirs.trigger.service.ExecuteTaskActionService;
import java.util.List;
@Fun(PetShopService.FUN_NAMESPACE)
@Component
public class PetShopServiceImpl implements PetShopService, ScheduleAction {
@Autowired
private ExecuteTaskActionService executeTaskActionService;
@Override
@Function
@XAsync(displayName = "异步批量更新宠物商店",limitRetryNumber = 3,nextRetryTimeValue = 60)
public void updatePetShops(List<PetShop> petShops) {
new PetShop().updateBatch(petShops);
}
@PamirsTransactional
@Override
@Function
public void asyncSerialUpdatePetShops(List<PetShop> petShops){
for(PetShop petShop:petShops) {
executeTaskActionService.submit((ExecuteTaskAction) new ExecuteTaskAction()
.setBizId(petShop.getCreateUid())//根据创建人Id分组,根据实际业务情况决定
.setTaskType(TaskType.SERIAL_BASE_SCHEDULE_NO_TRANSACTION_TASK.getValue())
.setNextRetryTimeUnit(TimeUnitEnum.SECOND)//失败重试时间单位
.setNextRetryTimeValue(10)//失败重试时间数
.setLimitRetryNumber(6)//最多重试次数
.setDisplayName("异步顺序任务-更新宠物商店,以createUid分组")
.setExecuteNamespace(getInterfaceName())
.setExecuteFun("execute")
.setContext(JsonUtils.toJSONString(petShop)));
}
}
@Override
public String getInterfaceName() {
return PetShopService.FUN_NAMESPACE;
}
@Override
@Function
public Result<Void> execute(ScheduleItem scheduleItem) {
Result<Void> result = new Result<>();
PetShop petShop = JsonUtils.parseObject(scheduleItem.getContext(),PetShop.class);
petShop.updateById();
return result;
}
}
Step2 修改PetShopBatchUpdateAction的conform方法
改调用异步顺序方法,petShopService.asyncSerialUpdatePetShops(shops)
package pro.shushi.pamirs.demo.core.action;
…… 引依赖类
@Model.model(PetShopBatchUpdate.MODEL_MODEL)
@Component
public class PetShopBatchUpdateAction {
@Autowired
private PetShopService petShopService;
……其他代码
@Action(displayName = "确定",bindingType = ViewTypeEnum.FORM,contextType = ActionContextTypeEnum.SINGLE)
public PetShopBatchUpdate conform(PetShopBatchUpdate data){
if(data.getDataStatus() == null){
throw PamirsException.construct(DemoExpEnumerate.PET_SHOP_BATCH_UPDATE_DATASTATUS_IS_NULL).errThrow();
}
List<PetShopProxy> proxyList = data.getPetShopList();
for(PetShopProxy petShopProxy:proxyList){
petShopProxy.setDataStatus(data.getDataStatus());
}
Tx.build(new TxConfig().setPropagation(Propagation.REQUIRED.value())).executeWithoutResult(status -> {
//利用ArgUtils进行参数转化
List<PetShop> shops = ArgUtils.convert(PetShopProxy.MODEL_MODEL, PetShop.MODEL_MODEL,proxyList);
// petShopService.updatePetShops(shops);
petShopService.asyncSerialUpdatePetShops(shops);
// throw PamirsException.construct(DemoExpEnumerate.SYSTEM_ERROR).errThrow();
});
return data;
}
}
Step3 重启看效果
页面效果跟构建第一个异步任务一样,但任务生产和执行逻辑不一样。会根据biz_id分配任务项与分组确保执行顺序
-
分配任务项,相同任务项一定会分配给同一个schedule的执行者
-
分组,任务在同一个schedule的执行者,相同分组Id一定会分配给同一个线程执行
页面操作完以后查看数据任务表

独立调度的异步任务(举例)
如果把所有任务都放在同一个任务类型下,复用同一套任务策略、任务配置、任务执行器。那么当某些不重要的异步任务大量失败会影响其他任务的执行,所以我们在一些高并发大任务量的场景下会独立给一些核心异步任务配置独立调度策略。
Step1 修改pamirs-demo-core的pom
增加对pamirs-middleware-schedule-core依赖,为了复用oinone默认实现任务类型的基础逻辑,在例子中我们自定义的异步任务继承SerialBaseScheduleNoTransactionTask的基础逻辑
<dependency>
<groupId>pro.shushi.pamirs.middleware.schedule</groupId>
<artifactId>pamirs-middleware-schedule-core</artifactId>
</dependency>Step2 新建PetShopUpdateCustomAsyncTask
package pro.shushi.pamirs.demo.core.task;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.middleware.schedule.core.tasks.SerialBaseScheduleNoTransactionTask;
@Component
public class PetShopUpdateCustomAsyncTask extends SerialBaseScheduleNoTransactionTask {
public static final String TASK_TYPE = PetShopUpdateCustomAsyncTask.class.getSimpleName();
@Override
public String getTaskType() {
return TASK_TYPE;
}
}Step3 修改PetShopServiceImpl的asyncSerialUpdatePetShops方法
修改TaskType为PetShopUpdateCustomAsyncTask.TASK_TYPE
@PamirsTransactional
@Override
@Function
public void asyncSerialUpdatePetShops(List<PetShop> petShops){
for(PetShop petShop:petShops) {
executeTaskActionService.submit((ExecuteTaskAction) new ExecuteTaskAction()
.setBizId(petShop.getCreateUid())//根据创建人Id分组,根据实际业务情况决定
// .setTaskType(TaskType.SERIAL_BASE_SCHEDULE_NO_TRANSACTION_TASK.getValue())
.setTaskType(PetShopUpdateCustomAsyncTask.TASK_TYPE)
.setNextRetryTimeUnit(TimeUnitEnum.SECOND)//失败重试时间单位
.setNextRetryTimeValue(10)//失败重试时间数
.setLimitRetryNumber(6)//最多重试次数
.setDisplayName("异步顺序任务-更新宠物商店,以createUid分组")
.setExecuteNamespace(getInterfaceName())
.setExecuteFun("execute")
.setContext(JsonUtils.toJSONString(petShop)));
}
}Step4 初始化数据
下载以下文件放在pamirs-demo-boot的src/main/resources/init目录下
schedule.json.txt(8 KB)
我们在系统原有提供的schedule.json,中增入任务类型为petShopUpdateCustomAsyncTask的配置,配置项"taskType": "CUSTOM",标志为客户自定义。实际注册到TbSchedule会按beanNames转化为taskType,其他参数含义见TbSchedule的管理控制台有对应中文说明
{
"taskType": "CUSTOM",
"beanNames": "petShopUpdateCustomAsyncTask",
"values": {
"heartBeatRate": 1000,
"judgeDeadInterval": 10000,
"sleepTimeNoData": 500,
"sleepTimeInterval": 500,
"fetchDataNumber": 500,
"executeNumber": 1,
"threadNumber": 8,
"processorType": "SLEEP",
"expireOwnSignInterval": 1.0,
"taskParameter": "",
"taskKind": "static",
"taskItems": [
0,1,2,3,4,5,6,7
],
"maxTaskItemsOfOneThreadGroup": 0,
"version": 0,
"sts": "resume",
"fetchDataCountEachSchedule": -1
},
"strategy": {
"IPList": [
"127.0.0.1"
],
"numOfSingleServer": 1,
"assignNum": 4,
"kind": "Schedule",
"taskParameter": "",
"sts": "resume"
}
}Step5 重启看效果
页面效果跟构建第一个异步任务一样,但任务生产和执行逻辑不一样。会根据biz_id分配任务项与分组确保执行顺序,同时会有独立的调度器以及规则配置
- 在tbSchedule的管理控制台,可以看见多了一个“petShopUpdateCustomAsyncTask”的任务类型,点编辑就可以看到我们配置任务类型对应的参数
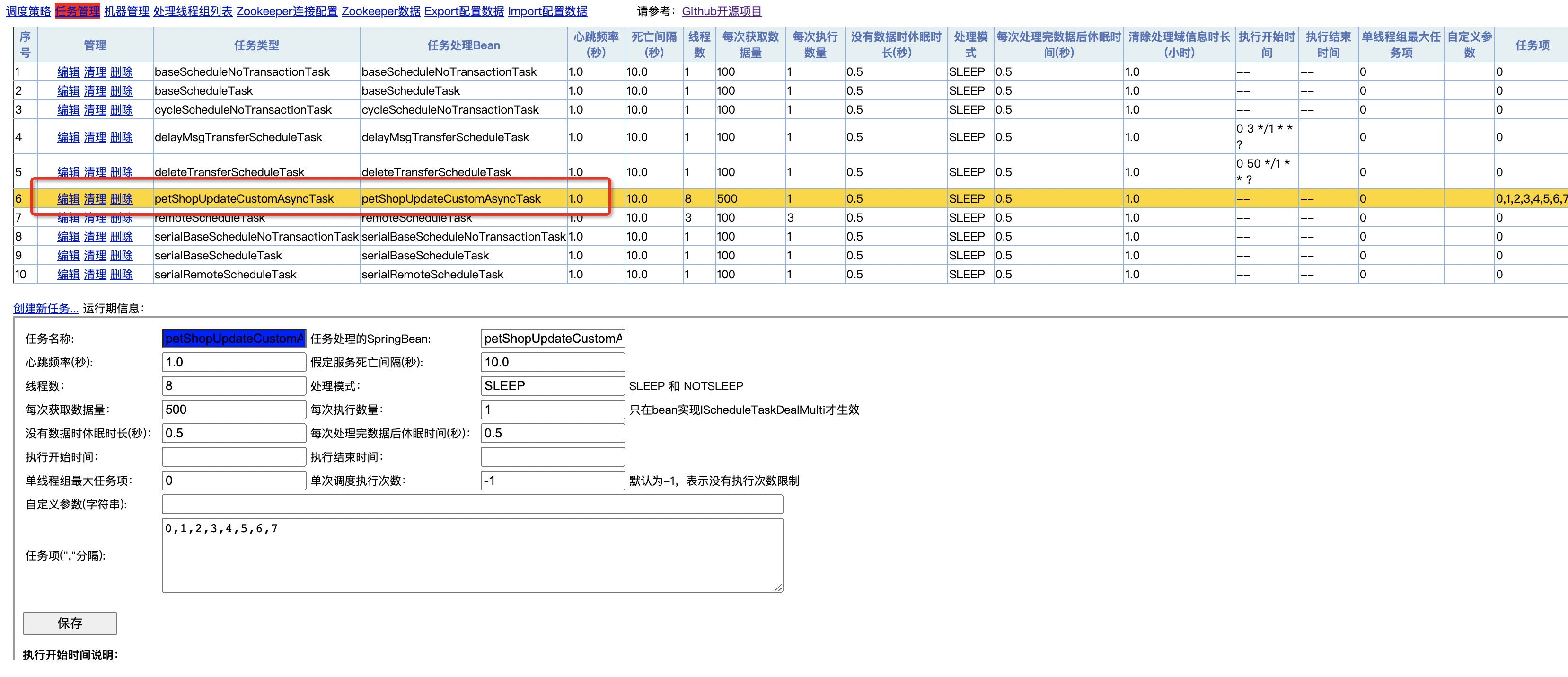
- 页面操作完以后查看对应数据任务表

四、不同应用如何隔离执行单元
在schedule跟模块部署一起的时候,多模块独立boot的情况下,需要做必要的配置。如果schedule独立部署则没有必要,因为全部走远程,不存在类找不到的问题
-
通过配置pamirs.zookeeper.rootPath,确保两组机器都能覆盖所有任务分片,这样不会漏数据
-
通过pamirs.event.schedule.ownSign来隔离。确保两组机器只取各自产生的数据,这样不会重复执行数据
pamirs:
zookeeper:
zkConnectString: 127.0.0.1:2181
zkSessionTimeout: 60000
rootPath: /demo
event:
enabled: true
schedule:
enabled: true
ownSign: demo
rocket-mq:
namesrv-addr: 127.0.0.1:9876Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9286.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验