
所有环境准备就绪,就让我们踏上oinone的奇妙之旅吧。先搞个demo模块【展示名为“oinone的Demo工程”,名称为“demoCore”,编码为“demo_core”】试试看,本节学习目的就是能把它启动起来,有个大概的认知。
一、后端工程脚手架
使用如下命令来利用项目脚手架生成启动工程:
- 新建archetype-project-generate.sh脚本,或者直接下载archetype-project-generate.sh
#!/bin/bash
# 项目生成脚手架
# 用于新项目的构建
# 脚手架使用目录
# 本地 local
# 本地脚手架信息存储路径 ~/.m2/repository/archetype-catalog.xml
archetypeCatalog=local
# 以下参数以pamirs-demo为例
# 新项目的groupId
groupId=pro.shushi.pamirs.demo
# 新项目的artifactId
artifactId=pamirs-demo
# 新项目的version
version=1.0.0-SNAPSHOT
# Java包名前缀
packagePrefix=pro.shushi
# Java包名后缀
packageSuffix=pamirs.demo
# 新项目的pamirs platform version
pamirsVersion=4.7.8
# Java类名称前缀
javaClassNamePrefix=Demo
# 项目名称 module.displayName
projectName=OinoneDemo
# 模块 MODULE_MODULE 常量
moduleModule=demo_core
# 模块 MODULE_NAME 常量
moduleName=DemoCore
# spring.application.name
applicationName=pamirs-demo
# tomcat server address
serverAddress=0.0.0.0
# tomcat server port
serverPort=8090
# redis host
redisHost=127.0.0.1
# redis port
redisPort=6379
# 数据库名
db=demo
# zookeeper connect string
zkConnectString=127.0.0.1:2181
# zookeeper rootPath
zkRootPath=/demo
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeCatalog=${archetypeCatalog} \
-DarchetypeGroupId=pro.shushi.pamirs.archetype \
-DarchetypeArtifactId=pamirs-project-archetype \
-DarchetypeVersion=${pamirsVersion} \
-DgroupId=${groupId} \
-DartifactId=${artifactId} \
-Dversion=${version} \
-DpamirsVersion=${pamirsVersion} \
-Dpackage=${packagePrefix}.${packageSuffix} \
-DpackagePrefix=${packagePrefix} \
-DpackageSuffix=${packageSuffix} \
-DjavaClassNamePrefix=${javaClassNamePrefix} \
-DprojectName="${projectName}" \
-DmoduleModule=${moduleModule} \
-DmoduleName=${moduleName} \
-DapplicationName=${applicationName} \
-DserverAddress=${serverAddress} \
-DserverPort=${serverPort} \
-DredisHost=${redisHost} \
-DredisPort=${redisPort} \
-Ddb=${db} \
-DzkConnectString=${zkConnectString} \
-DzkRootPath=${zkRootPath}- Linux/Unix/Mac 需要执行以下命令添加执行权限
chmod +x archetype-project-generate.sh- 根据脚本中的注释修改项目变量(demo工程可无需编辑)
- 执行脚本
./archetype-project-generate.sh二、后端工程结构介绍
通过脚手架生成的demo工程是我们2.4.1【oinone独特性之单体与分布式的灵活切换】一文中介绍的单模块工程结构,属于入门级的一种,麻雀虽小五脏俱全,特别适合新手学习。
- 结构示意图(如下图3-2-4所示)


- 工程结构说明
| 工程名 | 包名 | 说明 |
|---|---|---|
| pamirs-demo-api | 对外api包,如果有其他模块需要依赖demo模块,则可以在其pom中引入pamirs-demo-api包 | |
| constant | 常量的包路径 | |
| enumeration | 枚举类的包路径 | |
| model | 该领域核心模型的包路径 | |
| service | 该领域对外暴露接口api的包路径 | |
| tmodel | 存放该领域的非存储模型如:用于传输的临时模型 | |
| DemoModule | 该类是Demo模块的定义 | |
| pamirs-demo-boot | demo模块的启动类 | |
| boot | 启动类的包路径 | |
| DemoApplication | Demo模块的应用启动类,遵循spring boot 规范 | |
| resources/config/application-dev.yml | 研发环境的yml配置文件,遵循spring boot 规范 | |
| resources/bootstrap.yml | 启动的yml配置文件,遵循spring boot 规范 | |
| pamirs-demo-core | ||
| action | 模型对外交互的行为的包路径 | |
| init | 模块初始化工作的包路径 | |
| manager | manager是 service的一些公共逻辑,不会定义为独立的function的类 | |
| service | service是对应api工程中service接口的实现类,是模型的function |
三、pom.xml介绍
父pom的依赖管理
- 一个是启动包依赖
a. pamirs-boot里是有我们多种启动模式依赖包。教程只介绍标准启动模式
b. pamirs-base-standard
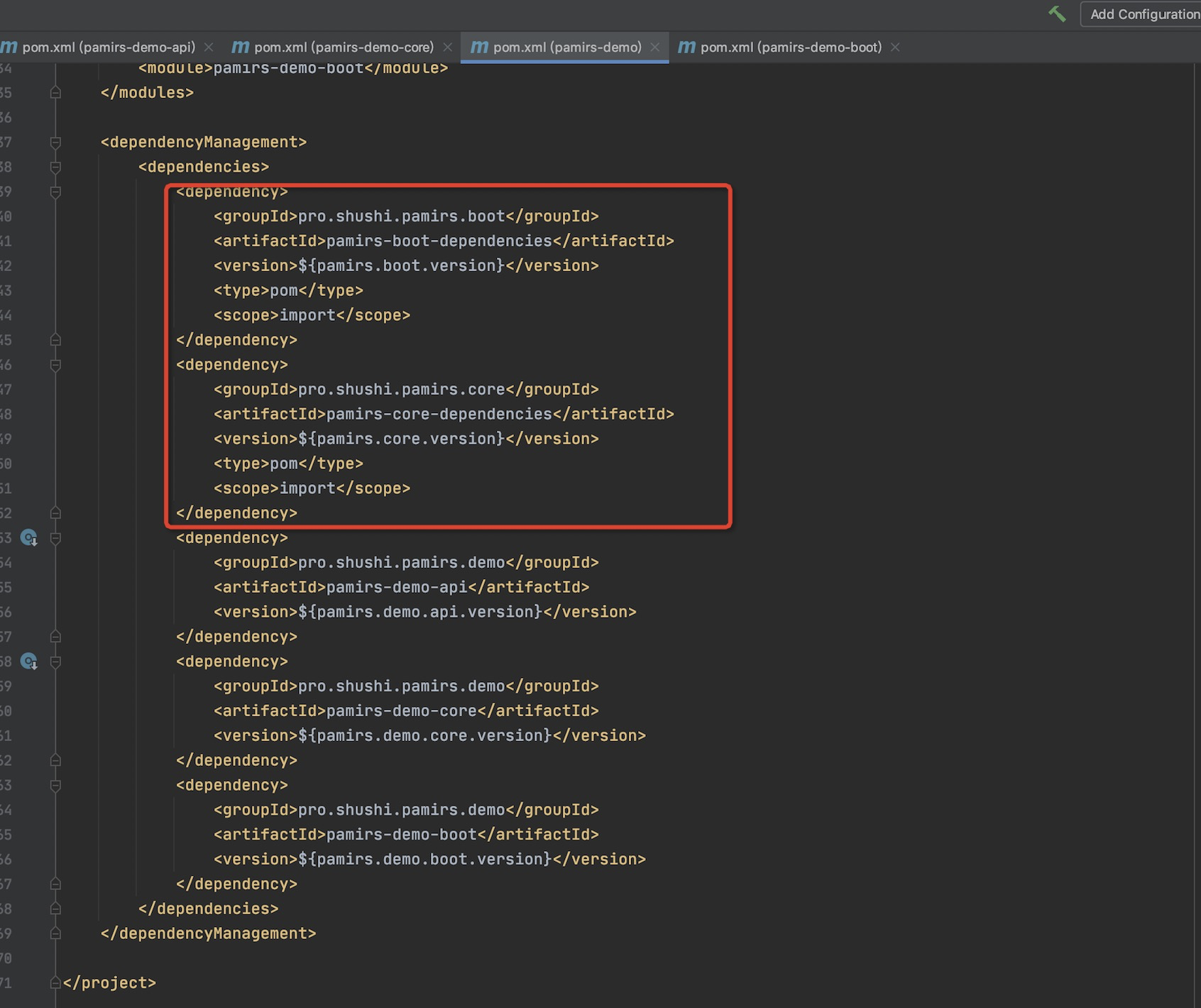
pamirs-domo-api
一个标准java工程,可以看出只是依赖了,我们的pamirs-base-standard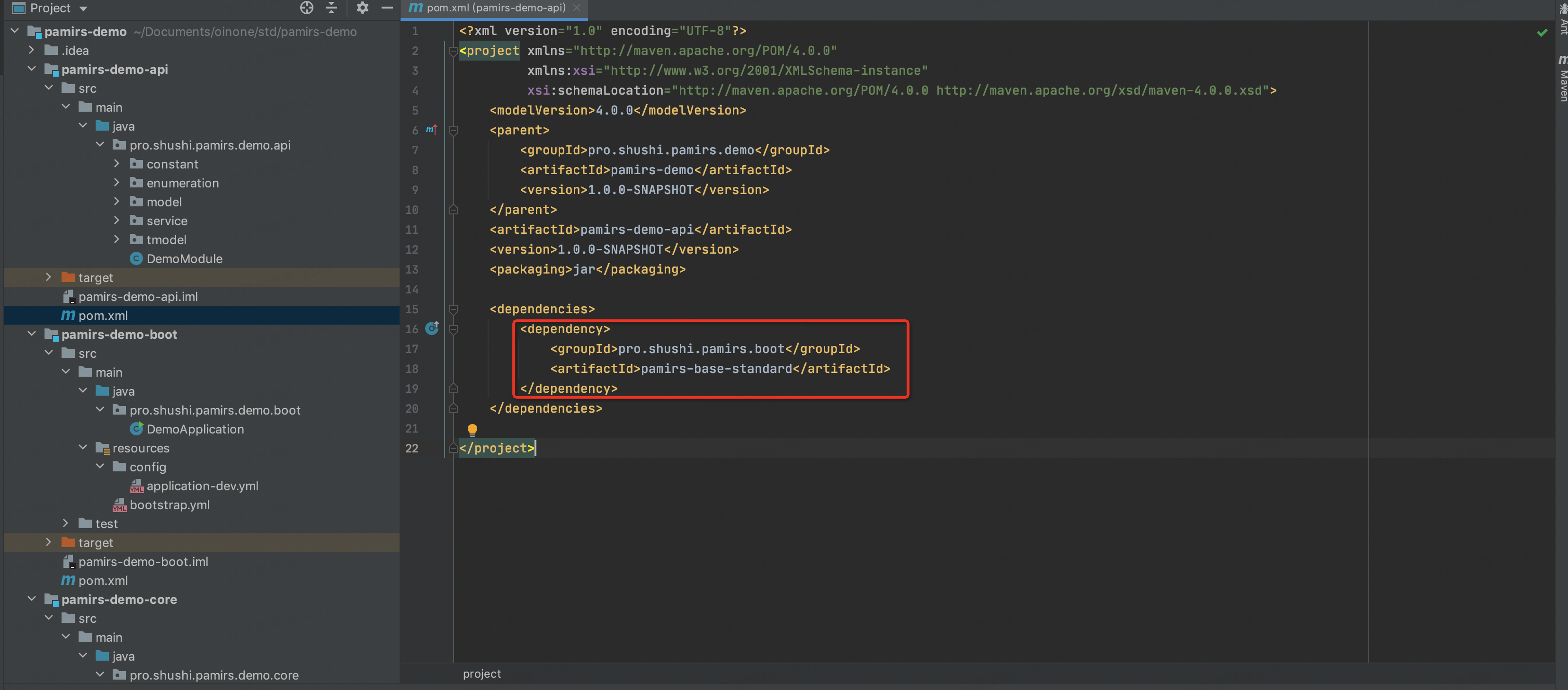
pamirs-demo-core
一个标准java工程,可以看出只是依赖了,我们的pamirs-demo-api
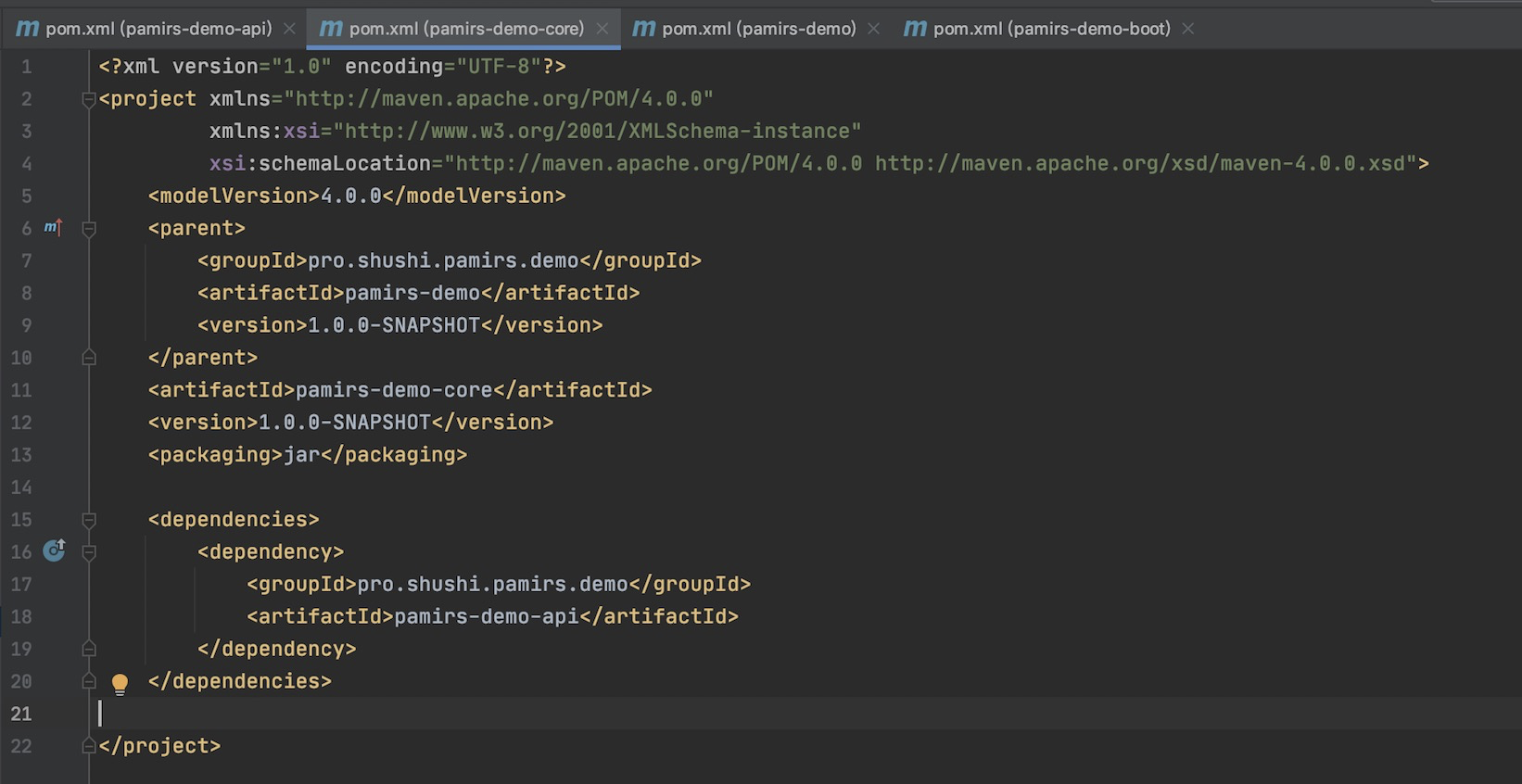
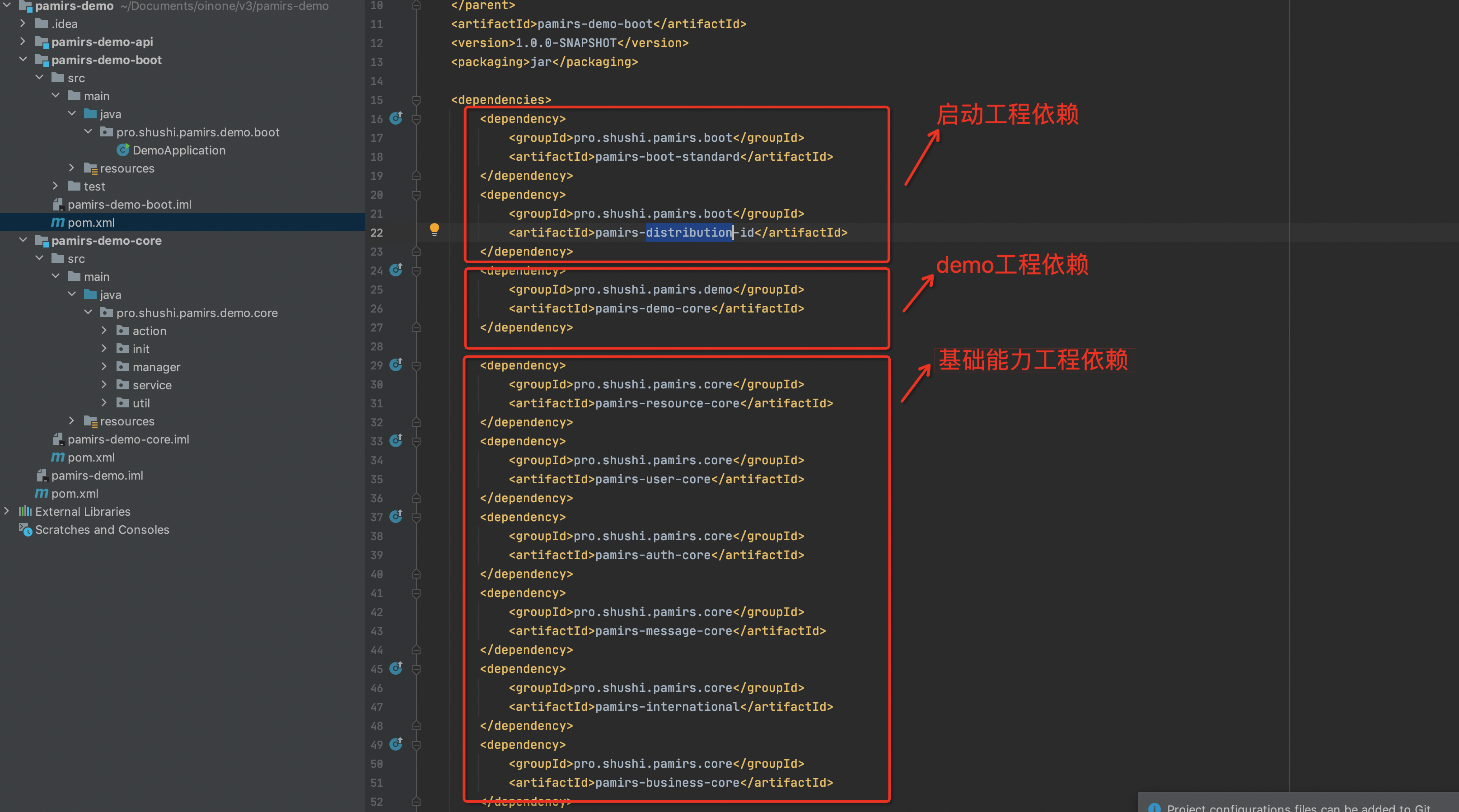
pamirs-demo-boot
把启动的时候,需要启动的module(模块)对应的jar,进行依赖引入。这样就可以在我们的yml文件中进行启动module的配置
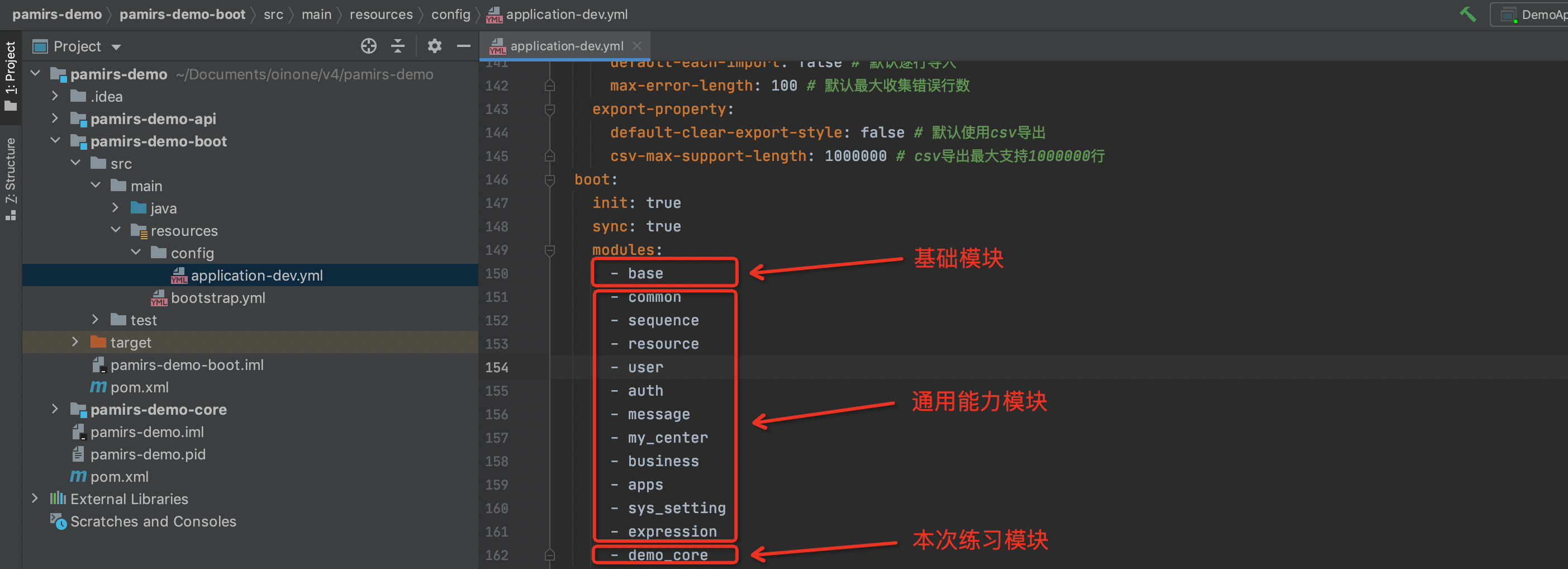
- 所需module(模块)对应的jar(如下图3-2-8所示)
- yml文件基础配置,boot工程的yml配置详见4.1.1【模块之yml文件结构详解】一文
四、DemoModule的定义
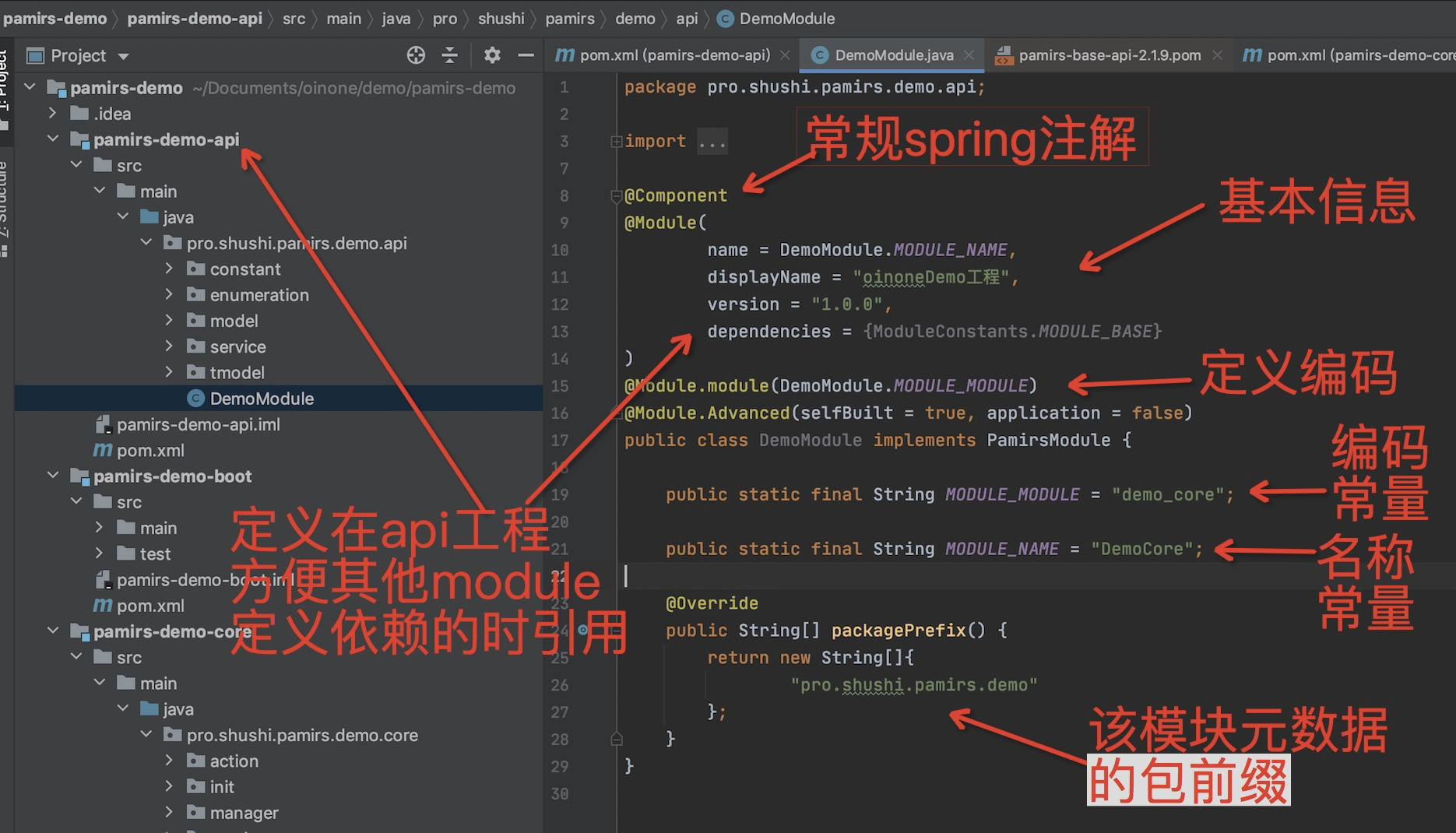
到此我们一个oinone中的一个module对应的工程就介绍完了。到目前为止跟一般的spring boot的工程没有太多区别,就多做了一个DemoModule的定义,oinone的所有Module都继承自PamirsModule。
配置注解
通过@Module的name属性配置模块技术名称,前端与后端交互协议使用模块技术名称来定位模块。
通过@Module的displayName属性配置模块展示名称,在产品视觉交互层展现。
通过@Module的version属性配置模块版本,系统会比较版本号来决定模块是否需要进行升级。
通过@Module的priority属性配置模块优先级(数字越小,优先级越高),系统会根据优先级取优先级最高的应用设置的首页来作为整个平台的首页。
通过@Module的dependencies属性和exclusions属性来配置模块间的依赖互斥关系,值为模块编码数组。如果模块继承了另一模块的模型或者与另一模块的模型建立了关联关系,则需要为该模块的依赖模块列表配置另一模块的模块编码。
通过@Module.module配置模块编码,模块编码是模块在系统中的唯一标识。
通过@Module.Advanced的selfBuilt属性配置模块是否为平台自建模块。
通过@Module.Advanced的application属性配置模块是否为应用(具有视觉交互页面的模块)。模块切换组件只能查看到应用。
通过@UxHomepage注解配置首页。@UxHomepage注解的model属性指定跳转页面的模型编码,name属性指定跳转页面的视图动作,默认为列表页。如果配置首页为列表页且未定义ViewAction,系统会根据首页配置自动生成。
更多Module的详细元数据描述,详见4.1.4【模块元数据详解】一文
配置扫描路径
设置扫描模型配置的包路径:
-
使用packagePrefix方法来配置模块需要扫描模型配置的包路径
-
使用dependentPackagePrefix方法来配置依赖模块的模型配置的包路径;如果不配置,会默认根据依赖模块的配置扫描模型配置的包路径扫描依赖模型
-
不同模块包路径包含会导致模型加载模块出问题
命名规范
| 属性 | 默认取值规则 | 命名规范 |
|---|---|---|
| module | 无默认值 开发人员定义规范示例: {项目名称}_{模块功能示意名称} |
使用下划线命名法 仅支持数字、大写或小写字母、下划线 必须以字母开头 不能以下划线结尾 长度必须小于等于128个字符 |
| name | 无默认值 | 使用大驼峰命名法 仅支持数字、字母 必须以字母开头 长度必须小于等于128个字符 |
五、DemoModule的启动
-
修改yml文件中数据源配置,数据库地址与密码修改为自己本地
-
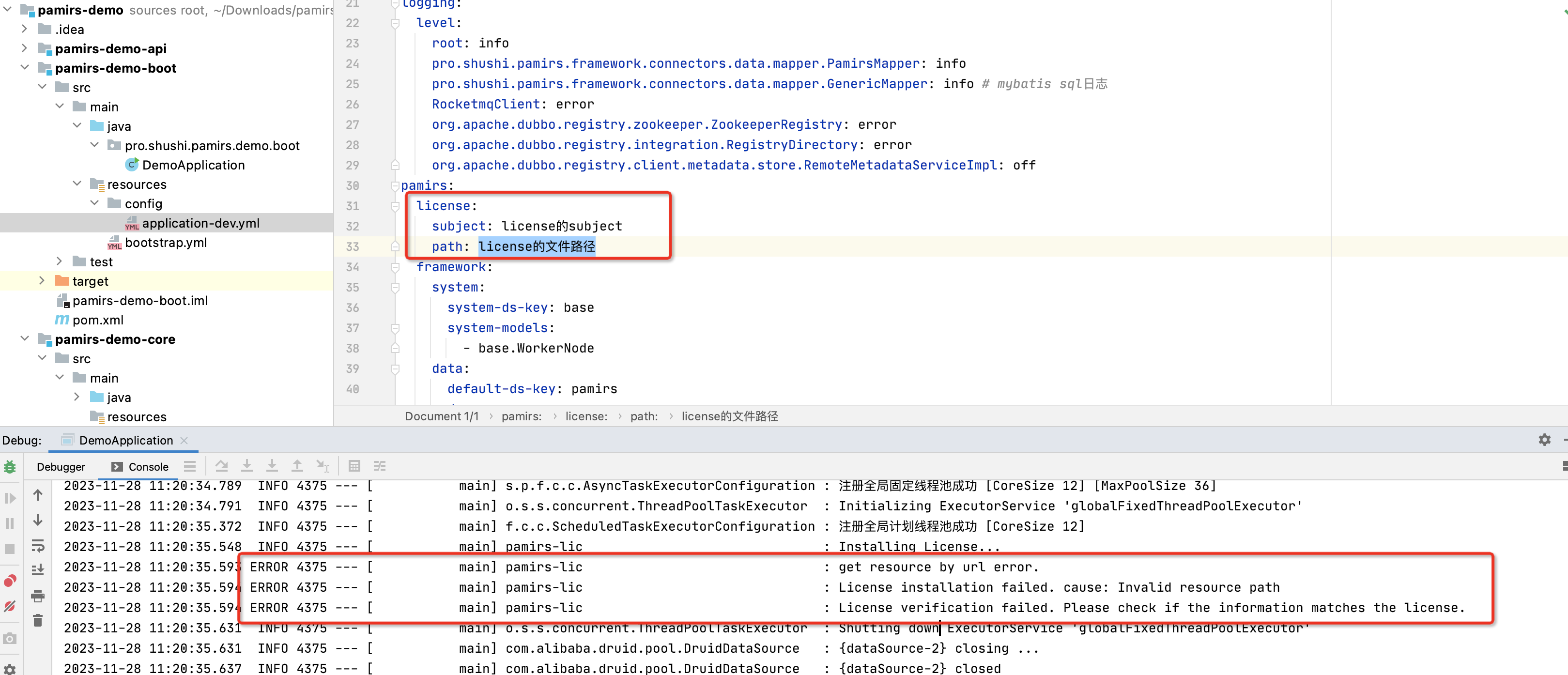
配置license,否则启动会报错,获取授权文件请找官方客户
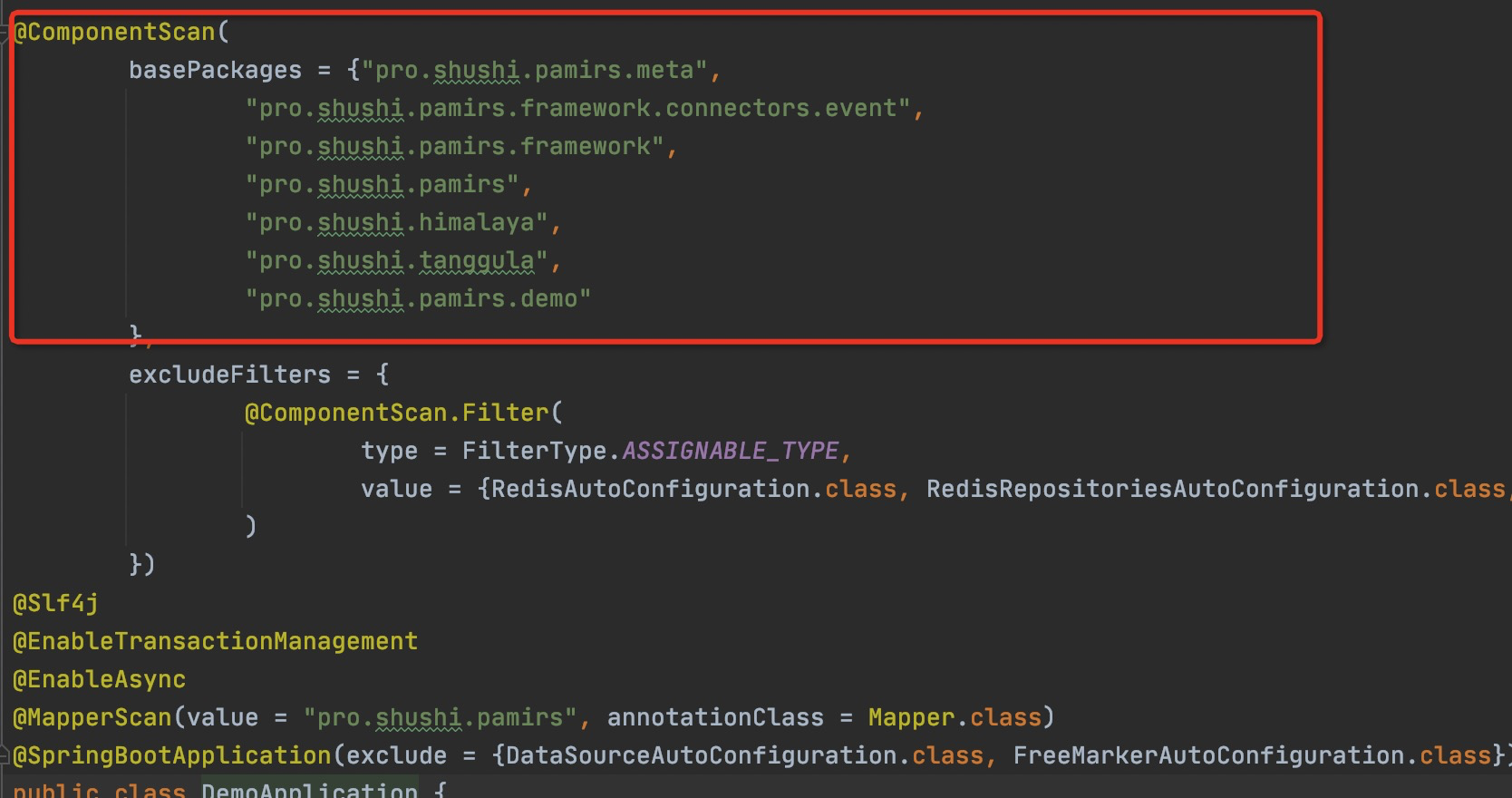
- 需要为启动或依赖模块配置扫描路径,配置扫描路径:pmairs是我们的oinone的基础包(必选),himalaya,tanggula是我们的业务模型基础包(可选),pro.shushi.pamirs.demo是我们测试项目包路径(必选,只不过它也在pamirs路径下,不填也不错)
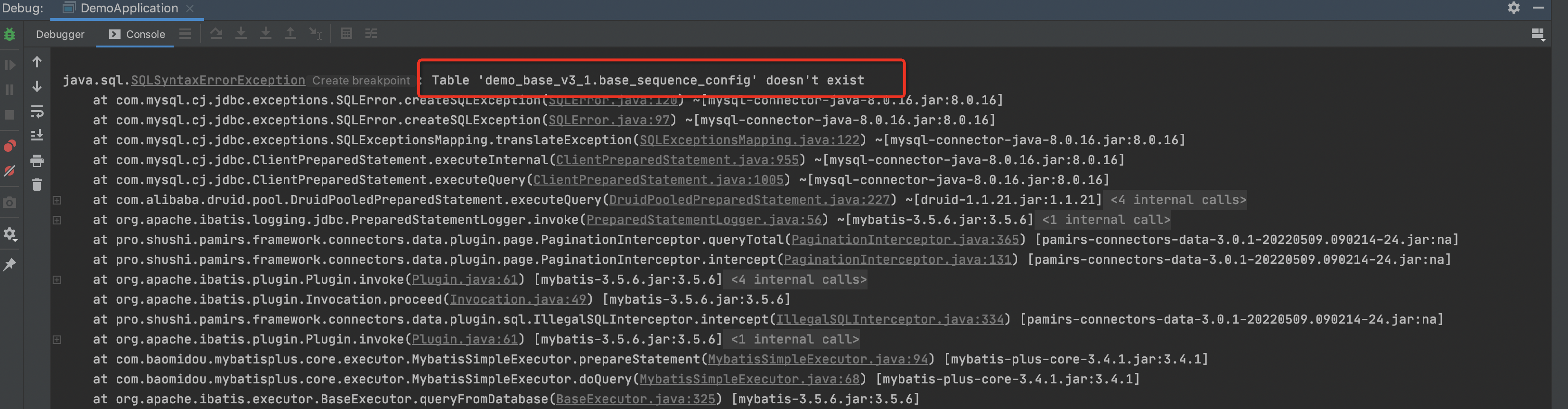
- 启动应用,我们会发现会报错。这个错误主要因为Oinone默认的是RELOAD(重启)模式,这种模式下只会从数据库中读取已安装模块并与yml文件中配置需要加载的模块对比。如果数据库中没有则会报没有安装过**模块,而我们是第一次启动,前面必然没有安装过模块,所以我们要把模式变为INSTALL,启动参数详见4.1.2【模块之启动指令】一文。如果整个平台第一次启动则回报 'base_sequence_config' doesn't exist
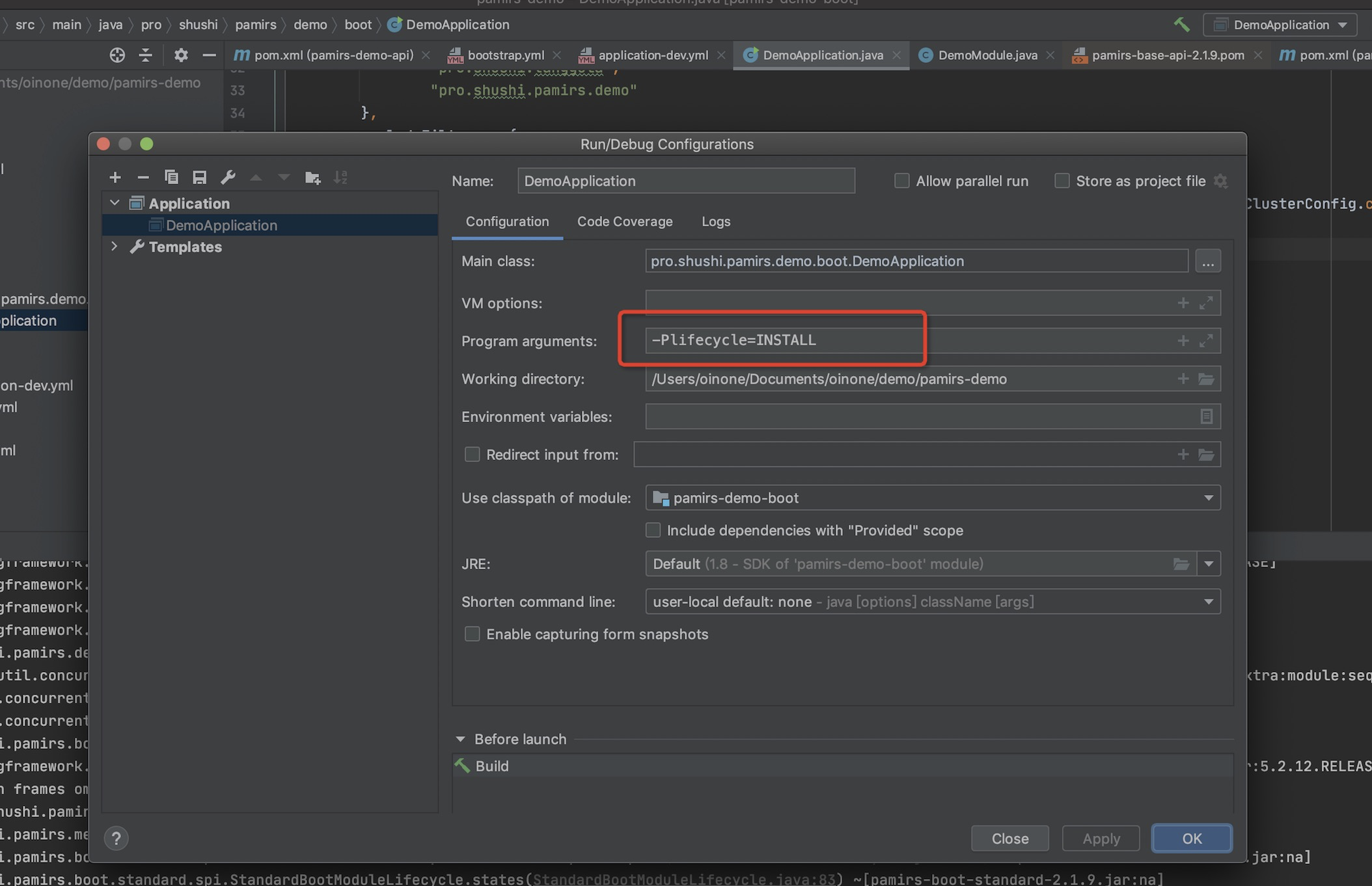
- 把模式变为INSTALL再次启动
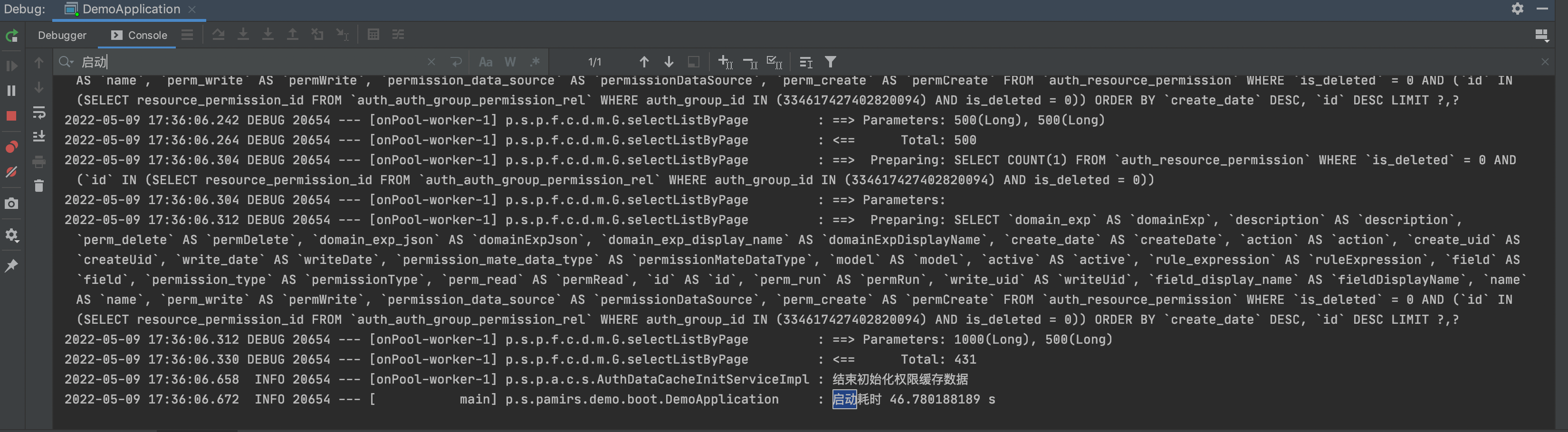
- 查看日志,看到对应启动字样才代表启动完成,而非Spring Boot的启动完成日志。我们的oinone的启动是在Spring Boot 启动完以后异步启动的
-
打开GraphQL客户端Insomnia看对应服务是否暴露
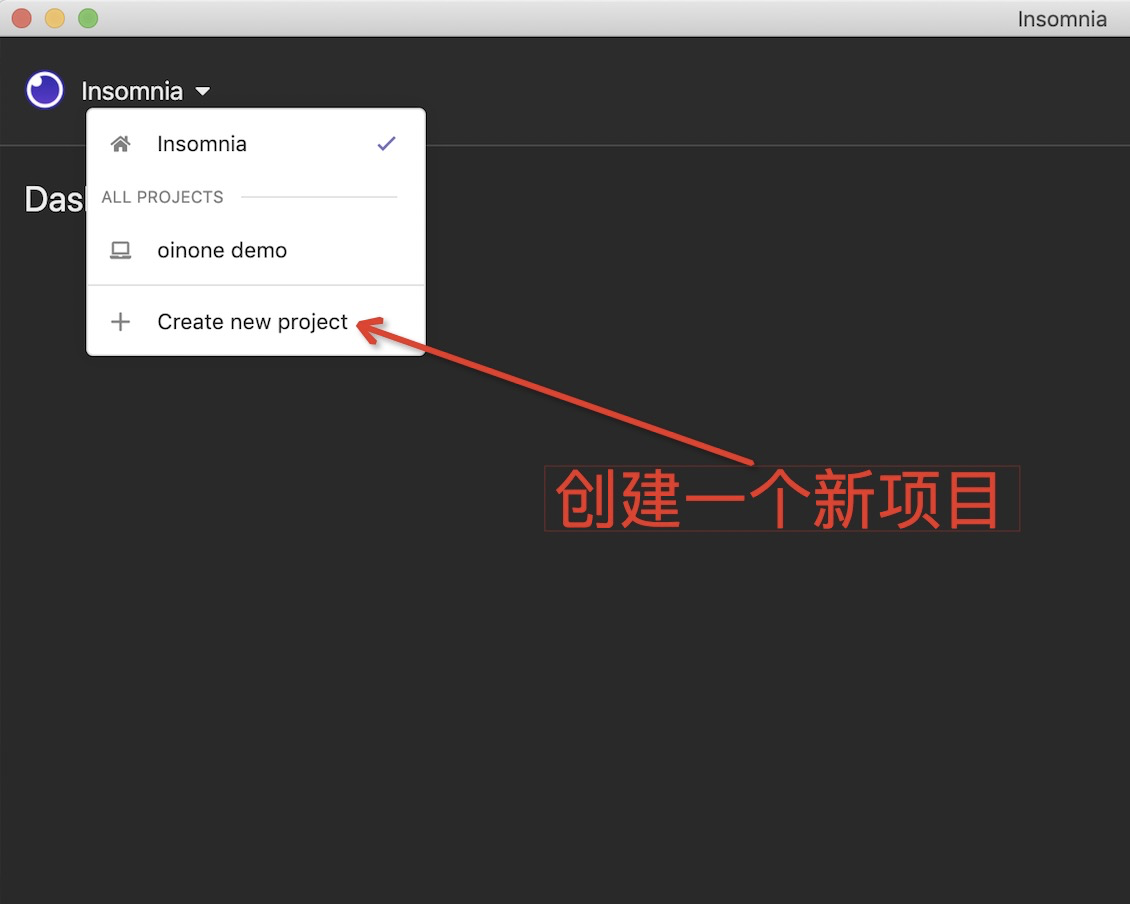
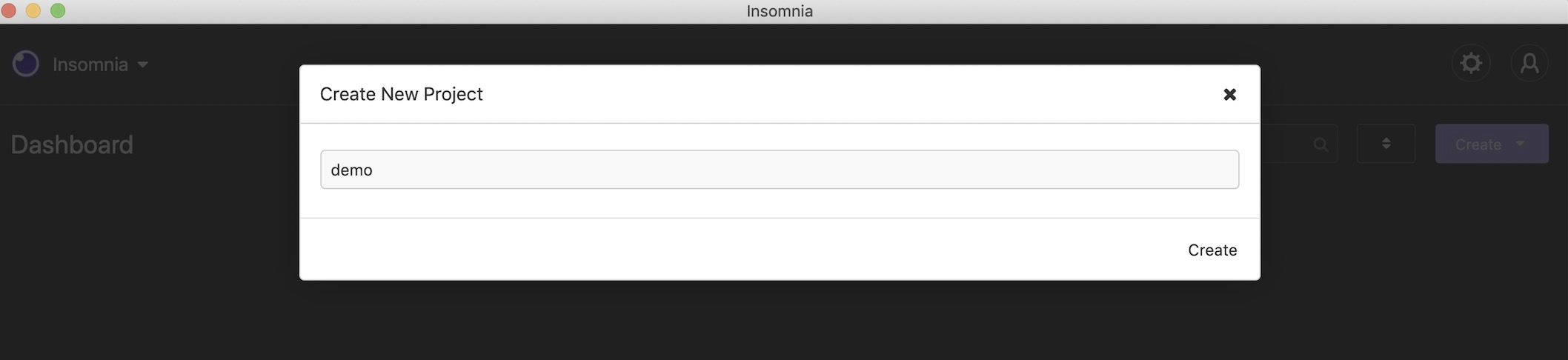
a. 创建一个demo项目
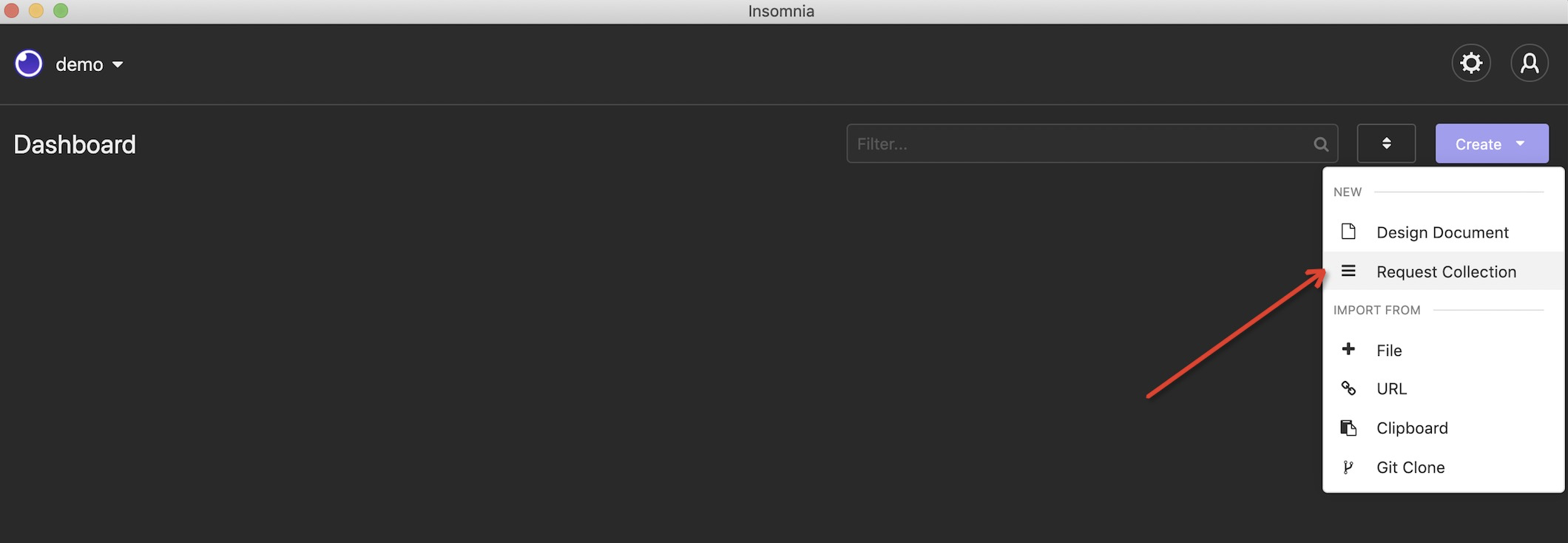
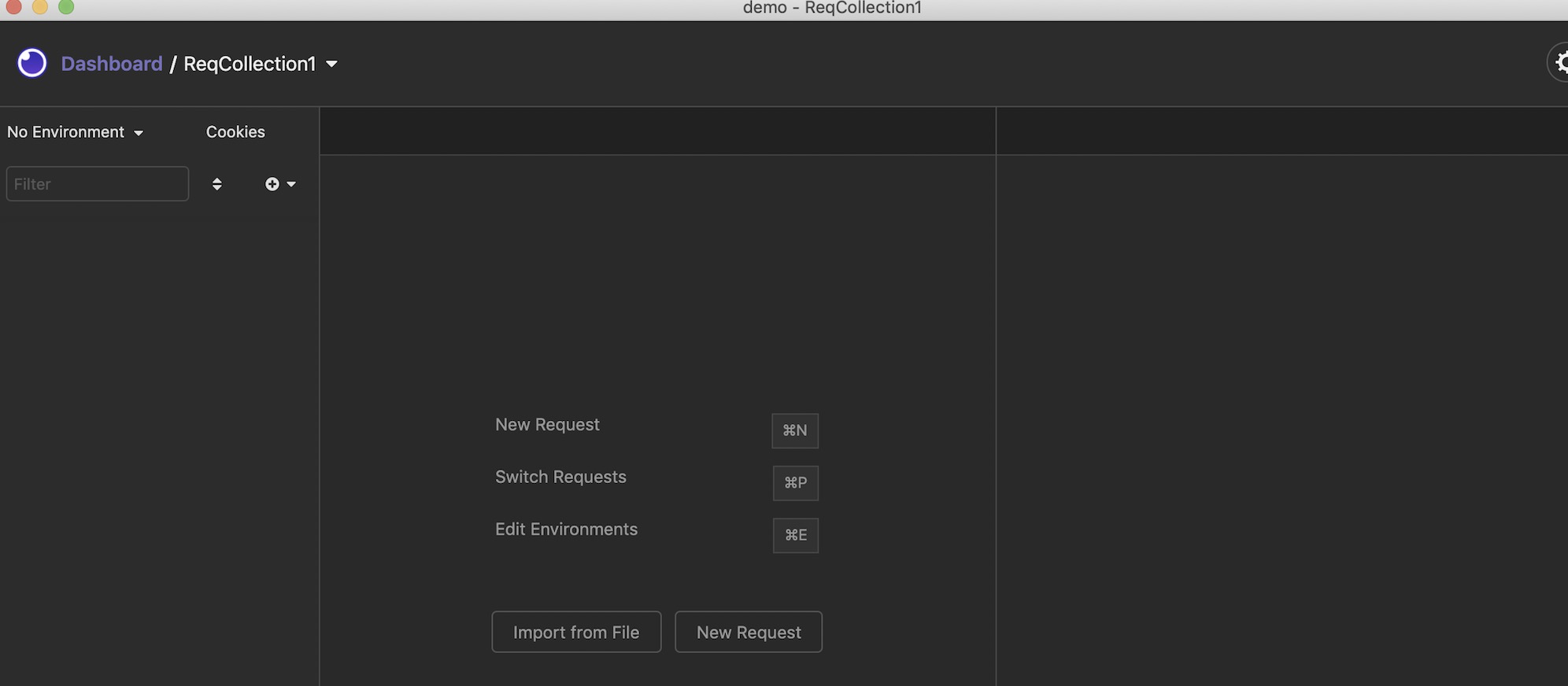
b. 为demo项目创建一个请求集合

c. 创建一个请求 command+N

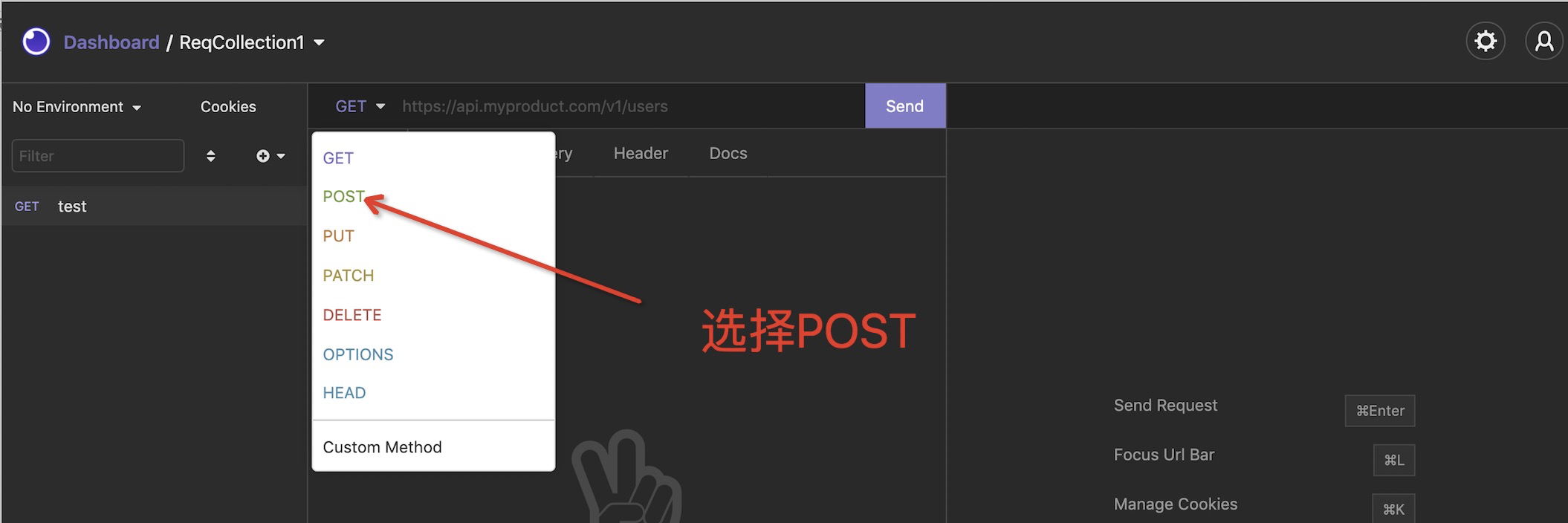
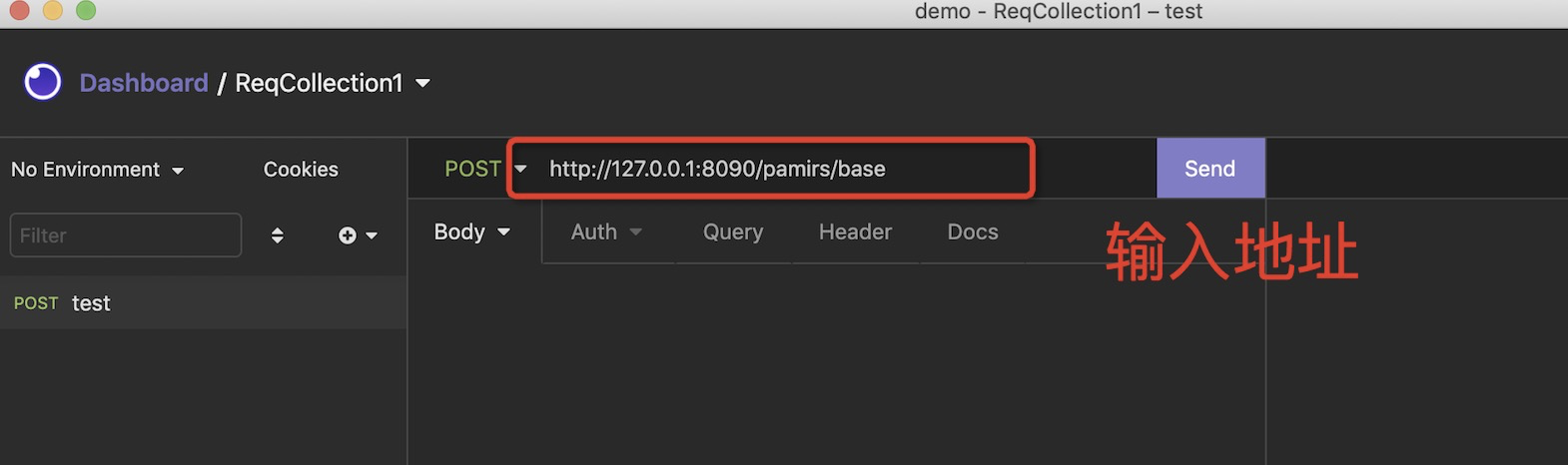
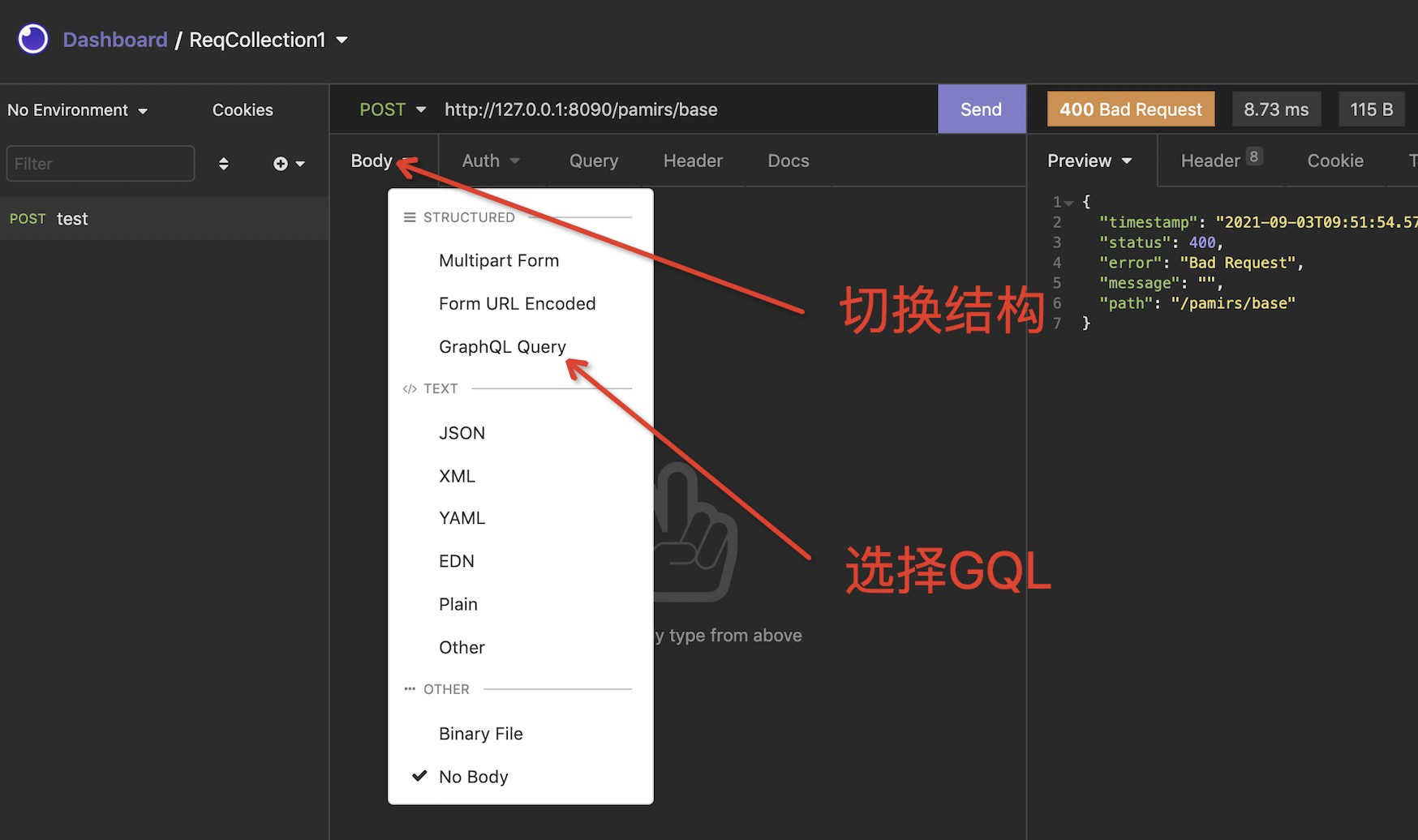
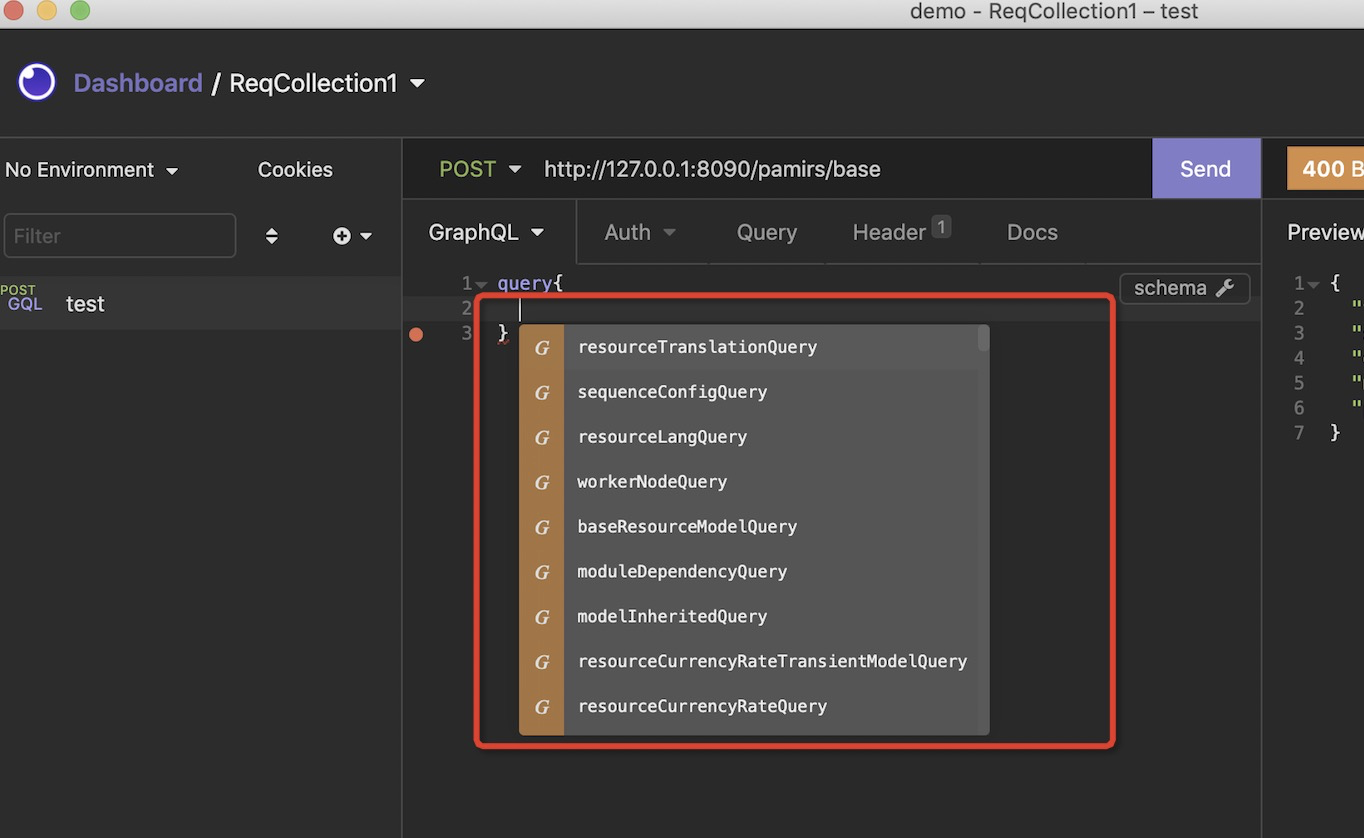
d. 检验结果,对应后端提供的服务已经有提示了
e. 查看schema 文档

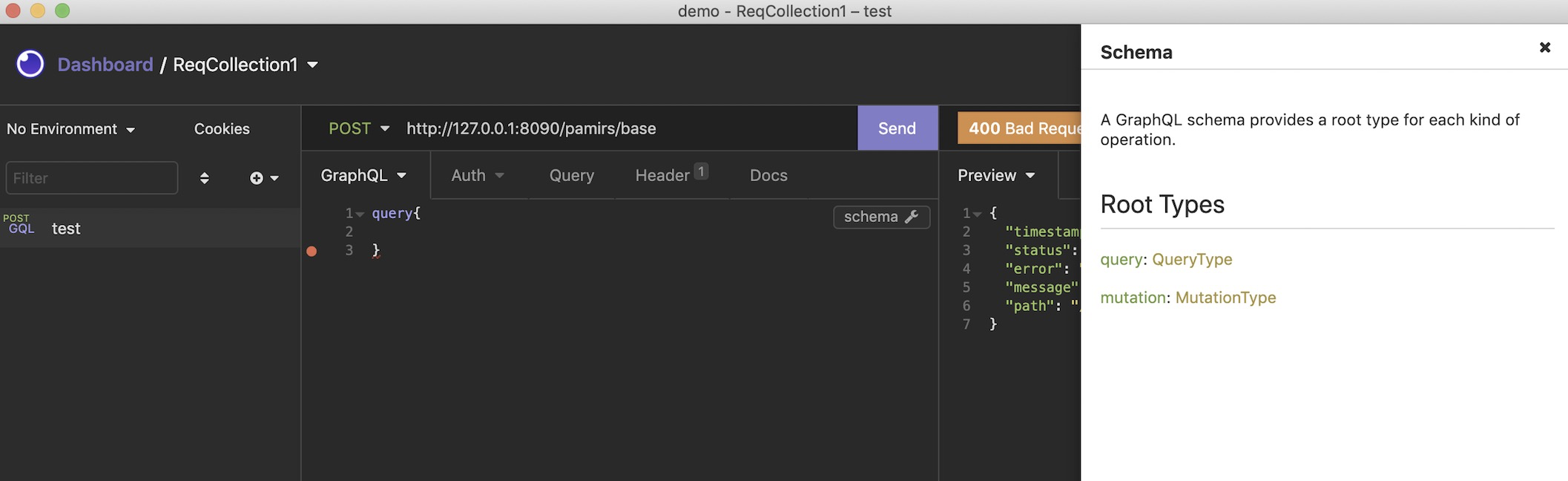
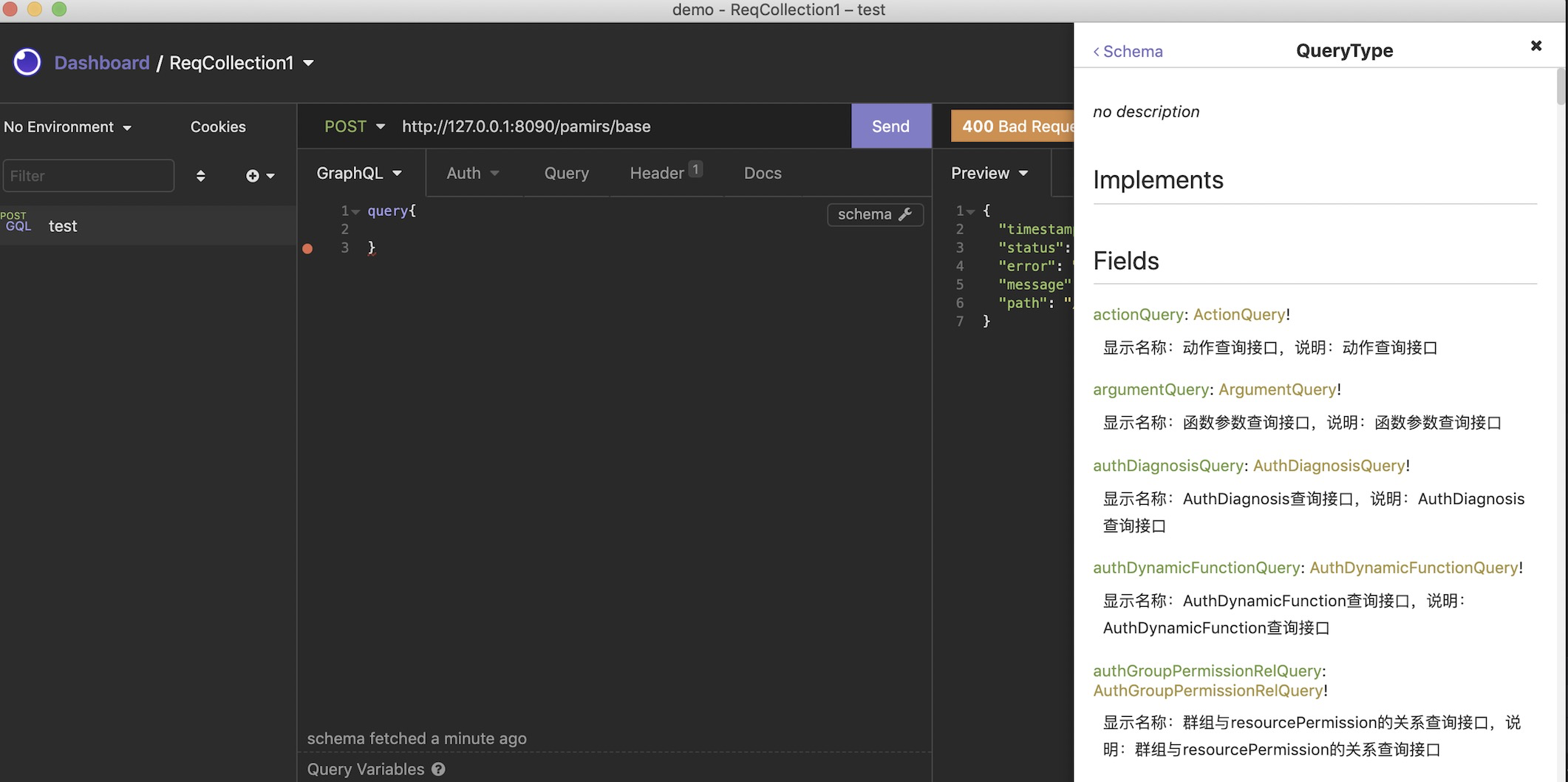
恭喜第一个oinone的模块已经启动完成,在下一文中我们通过页面来看看oinone的系统的庐山真面目。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9228.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验