
随着数据库技术的发展如分区设计、分布式数据库等,业务层的分库分表的技术终将成老一辈程序员的回忆,谈笑间扯扯蛋既羡慕又自吹地说到“现在的研发真简单,连分库分表都不需要考虑了”。竟然这样为什么要写这篇文章呢?因为现今的数据库虽能解决大部分场景的数据量问题,但涉及核心业务数据真到过亿数据后性能加速降低,能给的方案都还有一定的局限性,或者说性价比不高。相对性价比比较高的分库分表,也会是现阶段一种不错的补充。言归正传oinone的分库分表方案是基于Sharding-JDBC的整合方案,所以大家得先具备一点Sharding-JDBC的知识。
一、分表(举例)
做分库分表前,大家要有一个明确注意的点就是分表字段的选择,它是非常重要的,与业务场景非常相关。在明确了分库分表字段以后,甚至在功能上都要做一些妥协。比如分库分表字段在查询管理中做为查询条件是必须带上的,不然效率只会更低。
Step1 新建ShardingModel模型
ShardingModel模型是用于分表测试的模型,我们选定userId作为分表字段。分表字段不允许更新,所以这里更新策略设置类永不更新,并在设置了在页面修改的时候为readonly
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.boot.base.ux.annotation.field.UxWidget;
import pro.shushi.pamirs.boot.base.ux.annotation.view.UxForm;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.FieldStrategyEnum;
@Model.model(ShardingModel.MODEL_MODEL)
@Model(displayName = "分表模型",summary="分表模型",labelFields ={"name"} )
public class ShardingModel extends AbstractDemoIdModel {
public static final String MODEL_MODEL="demo.ShardingModel";
@Field(displayName = "名称")
private String name;
@Field(displayName = "用户id",summary = "分表字段",immutable=true/* 不可修改 **/)
@UxForm.FieldWidget(@UxWidget(readonly = "scene == 'redirectUpdatePage'"/* 在编辑页面只读 **/ ))
@Field.Advanced(updateStrategy = FieldStrategyEnum.NEVER)
private Long userId;
}Step2 配置分表策略
-
配置ShardingModel模型走分库分表的数据源pamirsSharding
-
为pamirsSharding配置数据源以及sharding规则
a. pamirs.sharding.define用于oinone的数据库表创建用
b. pamirs.sharding.rule用于分表规则配置
pamirs:
load:
sessionMode: true
framework:
system:
system-ds-key: base
system-models:
- base.WorkerNode
data:
default-ds-key: pamirs
ds-map:
base: base
modelDsMap:
"[demo.ShardingModel]": pamirsSharding #配置模型对应的库pamirs:
sharding:
define:
data-sources:
ds: pamirs
pamirsSharding: pamirs #申明pamirsSharding库对应的pamirs数据源
models:
"[trigger.PamirsSchedule]":
tables: 0..13
"[demo.ShardingModel]":
tables: 0..7
table-separator: _
rule:
pamirsSharding: #配置pamirsSharding库的分库分表规则
actual-ds:
- pamirs #申明pamirsSharding库对应的pamirs数据源
sharding-rules:
# Configure sharding rule ,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model: #demo_core_sharding_model表规则配置
actualDataNodes: pamirs.demo_core_sharding_model_${0..7}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model_${(Long.valueOf(user_id) % 8)}
props:
sql.show: trueStep3 配置测试入口
修改DemoMenus类增加一行代码,为测试提供入口
@UxMenu("分表模型")@UxRoute(ShardingModel.MODEL_MODEL) class ShardingModelMenu{}Step4 重启看效果
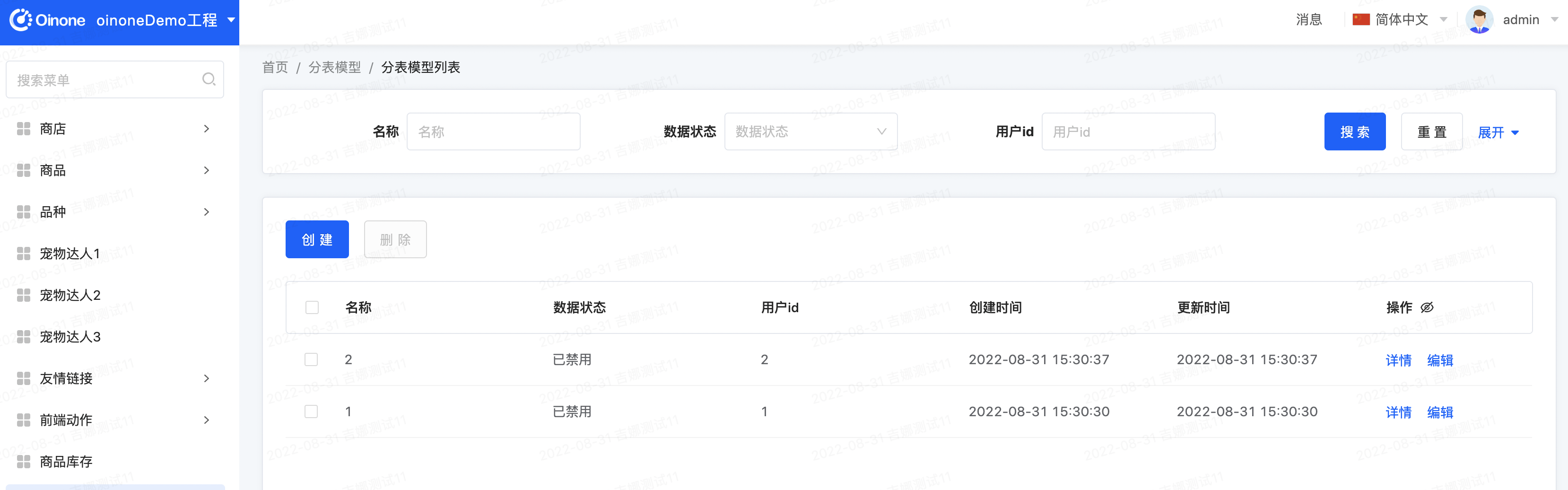
-
自行尝试增删改查
-
观察数据库表与数据分布


二、分库分表(举例)
Step1 新建ShardingModel2模型
ShardingModel2模型是用于分库分表测试的模型,我们选定userId作为分表字段。分库分表字段不允许更新,所以这里更新策略设置类永不更新,并在设置了在页面修改的时候为readonly
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.boot.base.ux.annotation.field.UxWidget;
import pro.shushi.pamirs.boot.base.ux.annotation.view.UxForm;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.FieldStrategyEnum;
@Model.model(ShardingModel2.MODEL_MODEL)
@Model(displayName = "分库分表模型",summary="分库分表模型",labelFields ={"name"} )
public class ShardingModel2 extends AbstractDemoIdModel {
public static final String MODEL_MODEL="demo.ShardingModel2";
@Field(displayName = "名称")
private String name;
@Field(displayName = "用户id",summary = "分库分表字段",immutable=true/* 不可修改 **/)
@UxForm.FieldWidget(@UxWidget(readonly = "scene == 'redirectUpdatePage'"/* 在编辑页面只读 **/ ))
@Field.Advanced(updateStrategy = FieldStrategyEnum.NEVER)
private Long userId;
}Step2 配置分库分表策略
-
配置ShardingModel2模型走分库分表的数据源testShardingDs
-
新增两个数据库配置:testShardingDs_0、testShardingDs_1
-
为testShardingDs配置数据源以及sharding规则
a. pamirs.sharding.define用于oinone的数据库表创建用
b. pamirs.sharding.rule 用于分库分表规则配置
pamirs:
load:
sessionMode: true
framework:
system:
system-ds-key: base
system-models:
- base.WorkerNode
data:
default-ds-key: pamirs
ds-map:
base: base
modelDsMap:
"[demo.ShardingModel]": pamirsSharding #配置模型对应的库
"[demo.ShardingModel2]": testShardingDs #配置模型对应的库pamirs:
datasource:
pamirs:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/demo2?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: true
base:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/demo2_base?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: true
testShardingDs_0:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/demo2_testShardingDs_0?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: true
testShardingDs_1:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/demo2_testShardingDs_1?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: truepamirs:
sharding:
define:
data-sources:
ds: pamirs
pamirsSharding: pamirs #申明pamirsSharding库对应的pamirs数据源
testShardingDs: #申明testShardingDs库对应的testShardingDs_0\1数据源
- testShardingDs_0
- testShardingDs_1
models:
"[trigger.PamirsSchedule]":
tables: 0..13
"[demo.ShardingModel]":
tables: 0..7
table-separator: _
"[demo.ShardingModel2]":
ds-nodes: 0..1 #申明testShardingDs库对应的建库规则
ds-separator: _
tables: 0..7
table-separator: _
rule:
pamirsSharding: #配置pamirsSharding库的分库分表规则
actual-ds:
- pamirs #申明pamirsSharding库对应的pamirs数据源
sharding-rules:
# Configure sharding rule,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model:
actualDataNodes: pamirs.demo_core_sharding_model_${0..7}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model_${(Long.valueOf(user_id) % 8)}
props:
sql.show: true
testShardingDs: #配置testShardingDs库的分库分表规则
actual-ds: #申明testShardingDs库对应的pamirs数据源
- testShardingDs_0
- testShardingDs_1
sharding-rules:
# Configure sharding rule,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model2:
actualDataNodes: testShardingDs_${0..1}.demo_core_sharding_model2_${0..7}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: ds_inline
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model2_${(Long.valueOf(user_id) % 8)}
ds_inline:
type: INLINE
props:
algorithm-expression: testShardingDs_${(Long.valueOf(user_id) % 2)}
props:
sql.show: trueStep3 配置测试入口
修改DemoMenus类增加一行代码,为测试提供入口
@UxMenu("分库分表模型")@UxRoute(ShardingModel2.MODEL_MODEL) class ShardingModel2Menu{}Step4 重启看效果
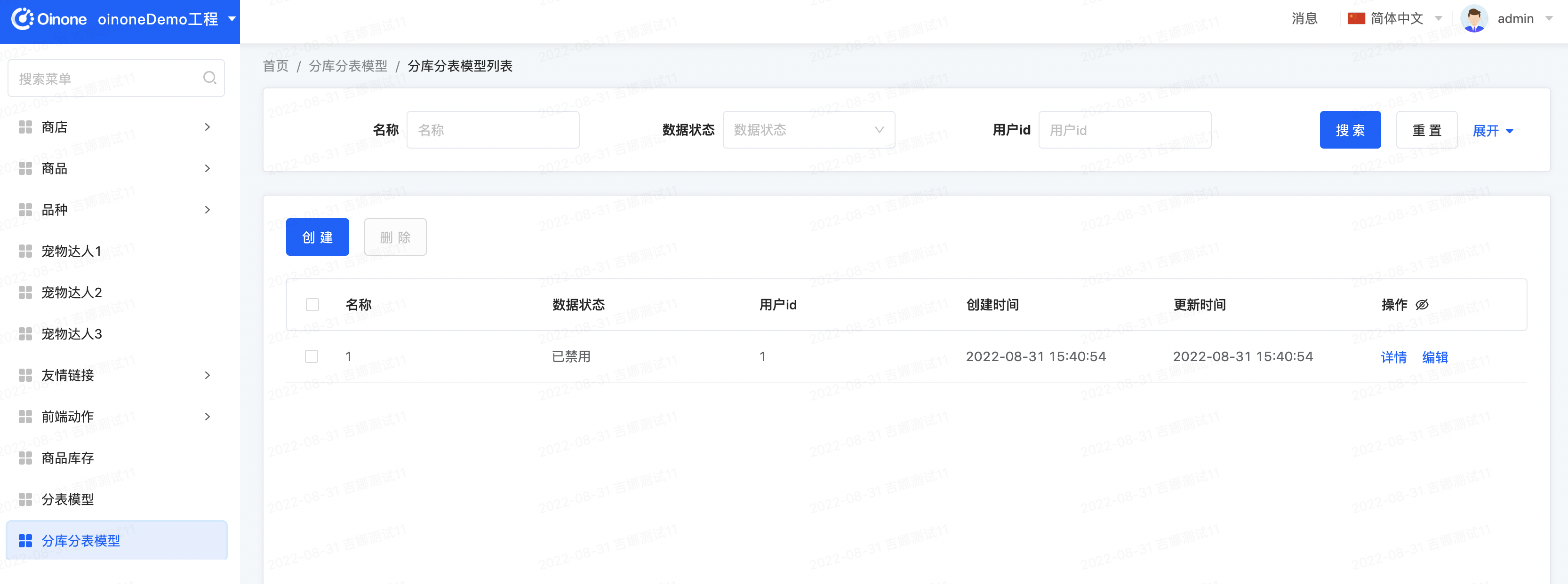
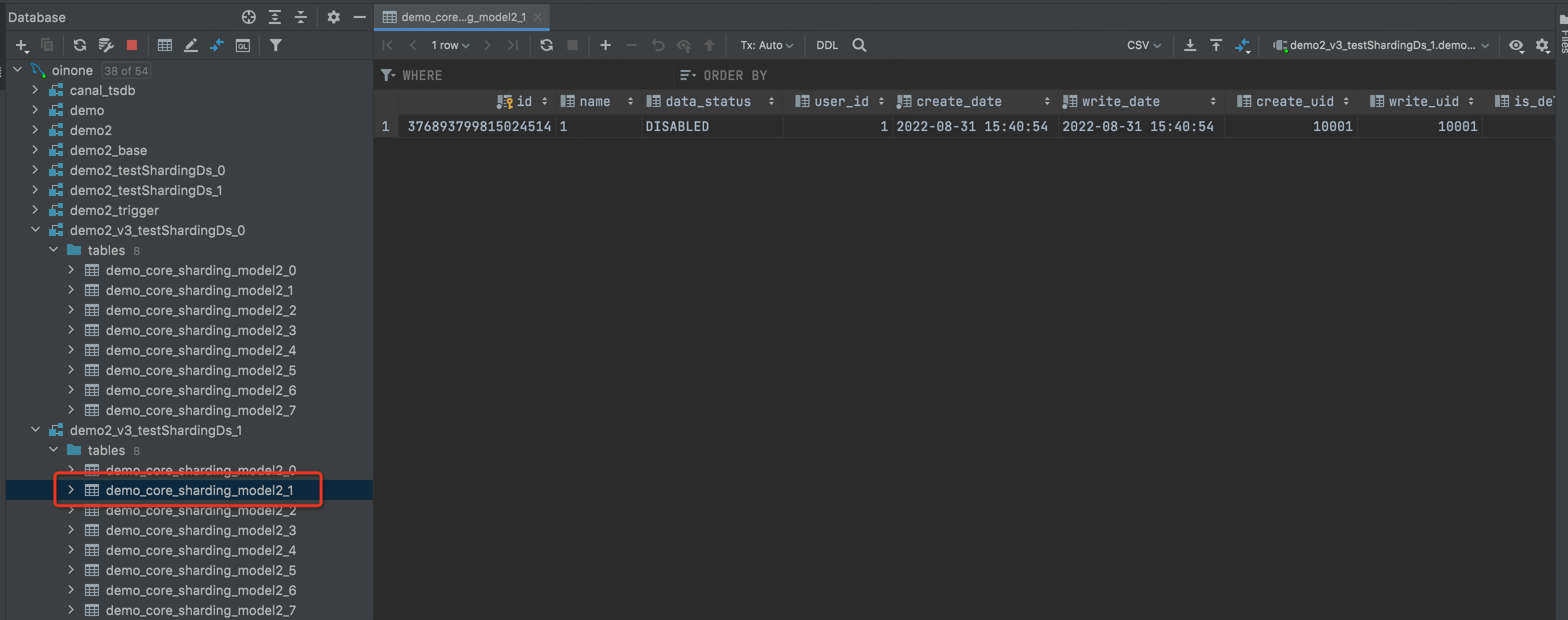
-
自行尝试增删改查
-
观察数据库表与数据分布
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9299.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验