
主题是什么
Oinone框架提供了强大的主题定制功能,使得平台可以轻松适应和遵循公司的品牌和UI规范。通过自定义主题,你可以调整颜色、间距、圆角等视觉元素,从而使Oinone更好地融入到特定行业的需求和公司标准中。以下是关于如何定制主题的关键点和步骤:
关键点
-
使用CSS变量:
- Oinone使用CSS变量 (Css Var) 来实现主题定制。
- CSS变量提供了一种高效且灵活的方式来定义和使用样式。
-
全面定制:
- 可以定制的范围广泛,包括颜色、字体、间距、边框、圆角等。
- 通过调整这些元素,可以确保UI符合公司的视觉标准。
定制步骤
-
了解CSS变量:
- 首先,了解如何在CSS中使用变量。
- 查看Oinone现有的CSS变量列表,以了解哪些样式可以被定制。
-
定义公司的UI规范:
- 根据公司的品牌指南,定义一套UI规范。
- 包括颜色方案、字体样式、元素尺寸等。
-
应用自定义样式:
- 在Oinone的样式表中,使用定义的CSS变量来覆盖默认样式。
- 确保在适当的地方应用这些自定义样式。
作用场景
Oinone平台提供了灵活的主题定制选项,包括内置的六套主题样式,涵盖深色和浅色模式以及不同的尺寸选项(大、中、小)。这些主题可以适应不同的业务需求和项目特性,同时提供了定制工具,方便用户根据公司的UI规范进行调整。下面是主题作用场景的详细说明:
主题选项
-
内置主题:
- 六套主题:包括深色和浅色模式,以及大、中、小尺寸。
- 用户可以通过系统设置功能轻松切换不同的主题。
-
可定制性:
- 提供CSS变量的JSON文件,方便用户下载和修改。
- 允许用户根据具体需求定制颜色、字体、间距等样式变量。
应用场景
-
公司UI规范对齐:
- 首先根据公司的UI规范调整一份基础主题。
- 这有助于确保平台的外观与公司品牌一致。
-
项目和业务适应性:
- 在不同项目或业务场景中,可以基于公司UI规范进行微调。
- 这提供了项目特定的灵活性,同时保持整体的品牌一致性。
实施建议
-
初始设置:
-
初始时,选择一个接近公司标准的内置主题作为起点。
-
通过系统设置功能体验不同的主题效果。
-
定制和微调:
-
下载并修改CSS变量的JSON文件,以符合公司的UI标准。
-
对于特定项目或业务场景,根据需要进行进一步的微调。
自定义主题
自定义主题功能允许在Oinone平台上创建和应用独特的视觉风格,以适应特定的业务需求和品牌标准。以下是自定义主题的步骤和示例,用于指导如何在Oinone平台上实现这一功能。
示例工程目录
以下是需关注的工程目录示例,main.ts更新导入./theme:
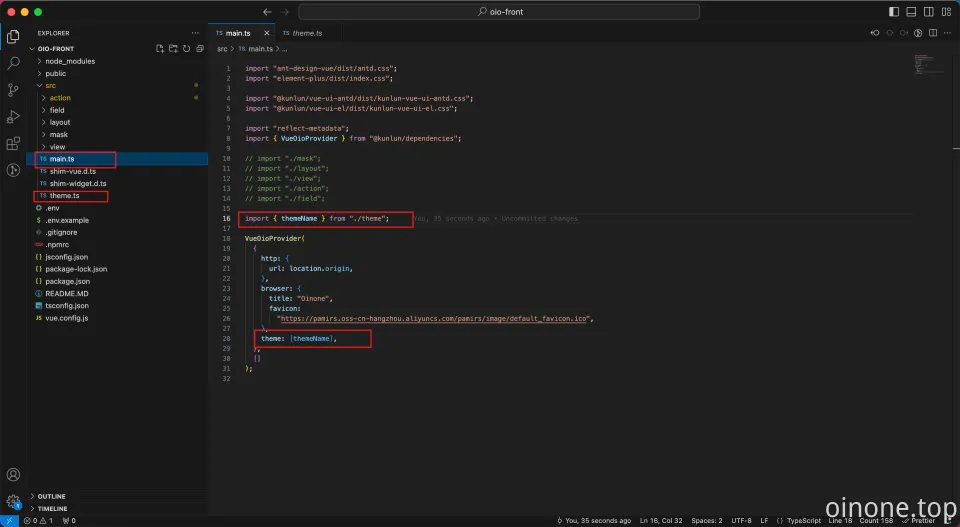

步骤 1: 创建主题
- 定义主题变量: 创建一个包含主题样式变量的JavaScript文件。例如,可以定义一个名为OinoneTheme的新主题,并设置相应的CSS变量。
- 注册主题: 使用registerTheme函数注册自定义主题。这个函数将新主题添加到可用主题列表中。
步骤 2: 应用主题
- 在主入口文件中引用: 在main.ts文件中引入自定义主题,并在VueOioProvider配置中指定。
效果
- 主题叠加: Oinone支持多个主题变量同时存在,后导入的主题变量会覆盖前面导入的。
内置主题
Oinone平台内置了以下六个主题变量,你可以在自定义主题时参考或扩展它们:
- 'default - large'
- 'default - medium'
- 'default - small'
- 'dark - large'
- 'dark - medium'
- 'dark - small'
扩展变量
- 在定义主题变量时,根据业务需求可以添加不存在的变量,作为变量的扩展。
示例
{
"custom-color": "#新的辅助颜色",
"button-padding": "10px 20px",
// ...其他自定义变量
}查找主题变量
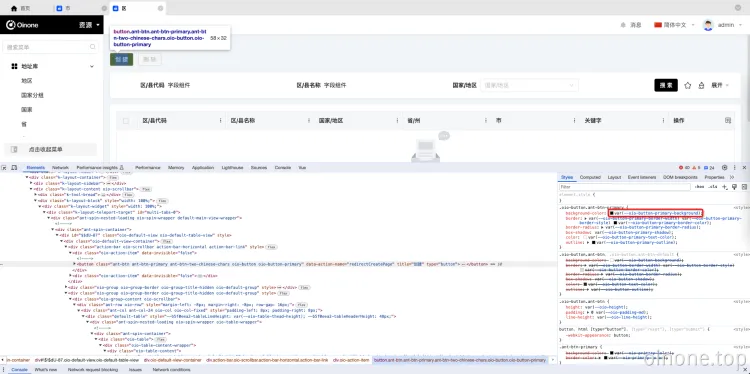
在Oinone平台上,通过DOM调试器查找主题变量是一种有效的方式,允许用户定位并获取相应组件的主题变量。以下是执行这一步骤的详细说明:
步骤:
-
使用DOM调试器:
- 在浏览器中打开Oinone平台,进入需要查找主题变量的页面。
- 使用浏览器的开发者工具或DOM调试器(通常可通过右键点击页面元素并选择“检查”打开)。
-
选择目标组件:
- 在DOM调试器中,通过选择器工具或直接点击页面上的组件,选中你想要查找主题变量的目标组件。
-
查看样式和主题变量:
- 在选中的组件上,浏览开发者工具中的“样式”或“计算”选项卡。
- 可以通过查看样式表中的相关样式规则,找到组件所使用的主题变量。
4标识主题变量:
- 主题变量通常以 --oio 为前缀。标识出你感兴趣的主题变量,记录下变量名和当前的取值。
示例:
假设你想查找某个按钮组件的主题变量,可以通过以下步骤:
-
在DOM调试器中选中按钮组件。
-
在“样式”或“计算”选项卡中查看相关样式规则。
-
找到以 --oio 为前缀的主题变量,如 --oio-button-pirmary-background。
-
记录该主题变量的取值,例如 #3498db。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9270.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验