
库存的差异会反馈到企业的整个价值链上,所以对库存的设计是至关重要的
一、基础介绍
我们先抛开仓库中对库存的实操管理和整个流通领域的库存,只围绕企业自身一级的采销链路上我们可以从管理和销售两个角度去看。
从管理角度上我们会关心:实物库存、在途库存、在产库存、库存批次等等,也就是企业有多少库存分布在哪里在什么环节。
从销售角度上我们会关心:可售库存、安全库存等等,也就是企业在特定渠道销售中库存分配规则。
在商业场景中库存管理一头对接仓库、生成、采购,另一头对接多个销售渠道。它的挑战在于不同行业不同特征商品都有比较大的差异。比如家具行业卖的是生产能力,家电区域化销售,生鲜拼车销售,服饰一仓销全国。热销的要分配提升体验防止超卖,滞销的要活动拉流量,普通的要渠道共享最大化可售。库存管理的差异会反馈到企业的整个价值链上,所以对库存的设计是至关重要的。
库存设计挑战在于:
-
技术上:库存类似账户账本的设计,需要能追溯库存变化的过程,且库存操作都能可追溯业务单据。热点数据的并发控制
-
业务上:在管理角度上游能跟仓库、采购、生产等进行对接、对账、并为其设置可售规则,下游能为各个销售渠道设置库存分配与同步规则
二、模型介绍
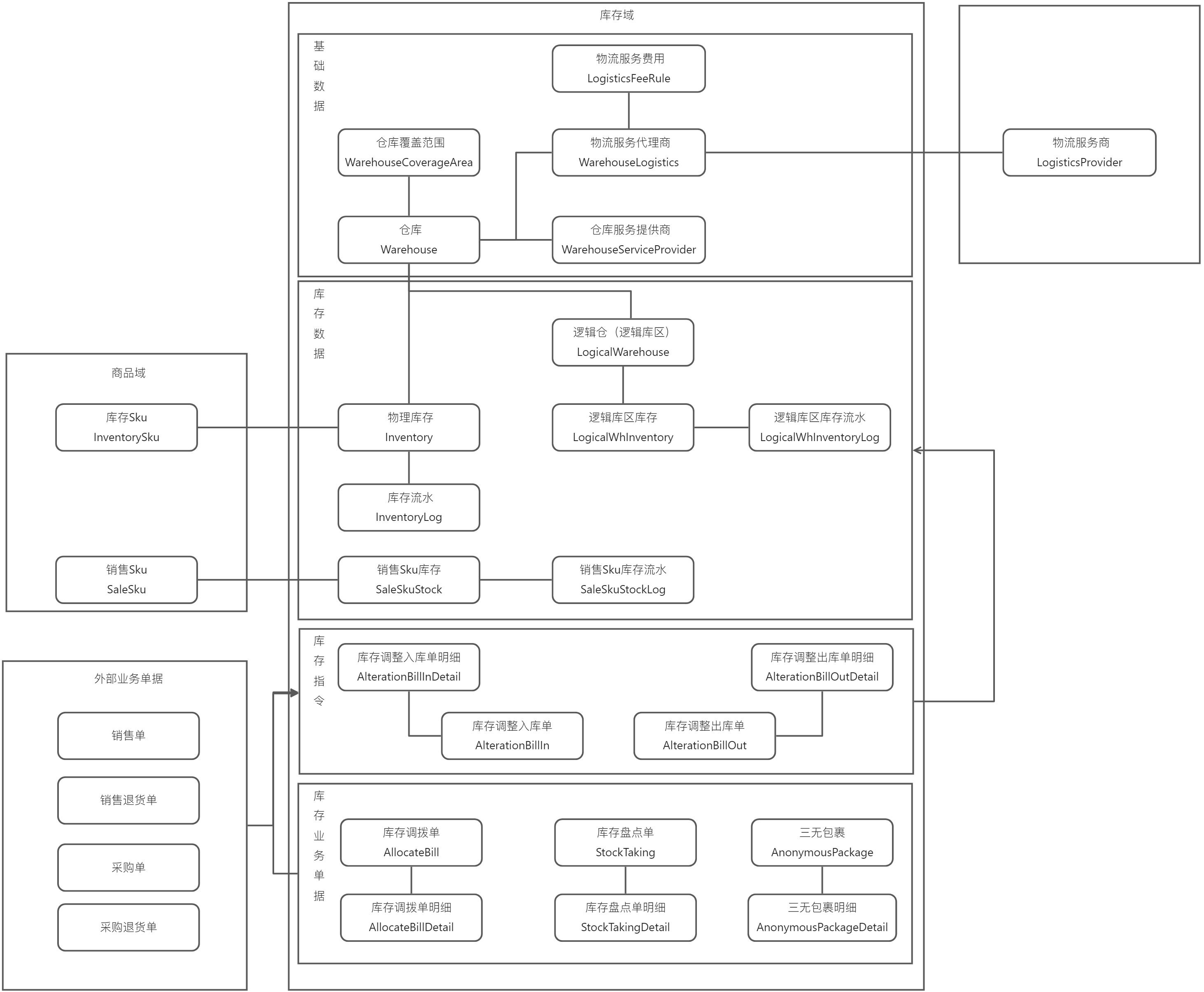

核心设计逻辑:
-
单据链路:业务单据(外部业务单据+库存业务单据)产生库存指令(库存调整入\出库单),再由库存指令操作库存并记录库存流水。
-
管理链路:基础数据维护仓库、供应商、服务范围与费用。这些数据是订单履约路由和可售库存同步的基础
-
库存数据:对外跟商品域,通过库存指令进行操作。不同库存各自维护自身库存与流水记录,确保可追溯。
-
如果跟销售渠道对接,还需要扩展可售库存逻辑规则以及同步规则。比如oms类似的应用
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9322.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验