
随着企业数字化转型的推进,软件公司获得了许多机会。尽管竞争日趋激烈,但由于需求旺盛,各种模式仍在不断涌现。因此,当前市场上存在各种各样的数字化转型解决方案,围绕企业的各个方面展开。每种解决方案都有其优点和缺点。本文将从定位、技术和产品等方面简单比较,帮助您从不同的视角了解Oinone的差异。
1.4.1 整体视角对比
一、与对标公司Odoo的对比
| Odoo | Oinone | |
|---|---|---|
| 定位 | 一站式全业务链管理平台:赋能企业信息化升级 | 一站式低代码商业支撑平台:赋能企业数字化升级 |
| 需求变化 | 关注单一企业的管理、流程、效率的提升 | 关注企业价值链的网络竞争,围绕外部协同、运营、数据、商业展开 |
| 技术更替 | 关注稳定、安全、功能丰富度 | 除了稳定、安全、功能丰富度以外,更强调需求响应速度、用户体验、系统承载极限与弹性扩展、智能化 |
二、与国内低代码或无代码公司对比
| 低代码或无代码公司 | Oinone | |
|---|---|---|
| 定位 | 低代码开发工具:提供各类系统模版,基于模版快速搭建和个性化配置。但系统模版无法再升级 | 平台型SaaS:提供各类系统产品,产品安装后客户可以根据需求进行个性化调整,同时产品永远在线可升级 |
| 场景差异 | 只能支持企业内部人员使用,以完成部门级边缘系统为主,一般多为没有专业软件厂商支撑和强临时性特性 | 从内外部协同的商业场景出发,关注企业核心业务场景,适应【企业业务在线化后,所有的业务变化与创新都需要通过系统来触达上下游】的时代背景,以敏捷响应业务的变化与创新为目标 |
| 技术代差 | 单表支撑100万数据已是业内天花板 | 支撑单模型数据过亿,无单点瓶颈。封装互联网架构并且做到单体与分布式的灵活部署,为不同大小公司提供不同技术支撑 |
1.4.2 从技术角度对比
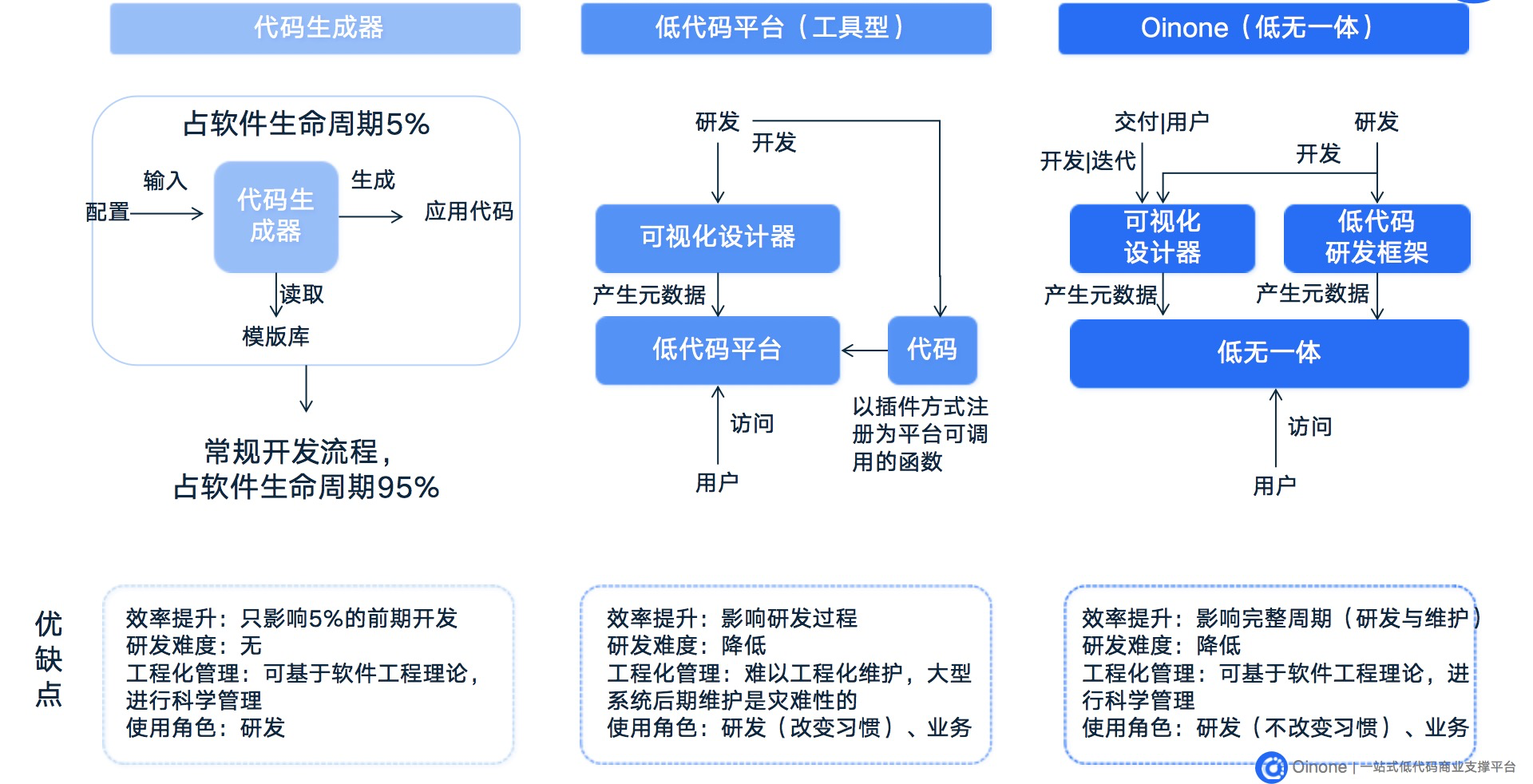
我们不会与其他无代码平台进行比较,因为它们不能解决业务复杂性的问题。相反,我们将重点介绍三种不同的低代码平台模式(如下图1-8所示)。
第一种模式是最基础的低代码平台,也被称为代码生成器。它通过预定义应用程序模板和必要的配置生成代码,简化了工程搭建并提供了一些基础逻辑。虽然在信息化时代内部流程标准化方面较为适合,但在数字化时代外部协同业务在线的情况下就不那么合适了。因为这种模式不能减少研发难度和提高效率,也无法体现敏捷迭代快速创新的优势。
第二种模式是经典的低代码平台,以元数据为基础,以模型为驱动。当无法满足需要时,通过特定方式将代码以插件的形式注入平台,作为低代码平台的内置逻辑,供设计器使用。它的优点在于降低了研发门槛,当无法满足需求时才需要编写代码。它可以实现企业内部的复杂流程和复杂逻辑,但其性能和工程管理存在局限性。性能问题使其不适合处理互联网化的在线业务,而工程管理问题则使其不适合处理快速变化的业务。这也是许多研发人员反对低代码的核心原因之一,因为研发人员变成了辅助角色,而软件工程是一门需要技术能力的学科,让没有技术能力的人主导是违反常理的。对于软件产品公司来说,产品需要迭代规划,需要多人协作,需要工程化管理。
第三种模式是oinone提出的基于互联网架构的低代码平台,它采用低无一体的设计。首先,oinone屏蔽了互联网架构带来的复杂性。其次,同样以元数据为基础,以模型为驱动,但是元数据的生成方式有两种:一种是使用无代码设计器(与经典低代码相同),另一种是通过代码来描述元数据。通过使用代码来描述元数据,可以无缝地与代码衔接,并在不改变研发习惯的情况下降低门槛、提高效率,并进行工程化管理。
最后总结来说:低无一体不仅仅是指两种模式的结合,还包括两种模式的融合应用方式。具体来说,这种融合应用方式可以分为两种情况:
-
当开发核心产品时,主要采用低代码开发,无代码设计器作为辅助。这种方式可以提高开发效率和代码质量,同时保证产品的快速迭代和升级。
-
当需要满足个性化或非产品支持的需求时,主要采用无代码设计器,低代码作为辅助。这种方式可以快速地满足客户需求,并且避免对产品的核心代码产生影响。
简单来说,低代码模式适用于产品的迭代升级,而无代码设计器则适用于满足个性化和非产品支撑的额外需求。低代码和无代码模式在整个软件生命周期中都有各自的价值,在不同场景下可以相互融合,发挥最大的优势。

1.4.3 从产品角度对比
产品上的对比,从客户、场景满足度、再次销售三个方面来做简易的对比
一、Oinone vs 数字化软件服务商
| 客户 | 满足度 | 销售 | |
|---|---|---|---|
| Oinone | 一站式商业智能软件,更高性价比、用户体验客户范围:5000万~5亿、5亿~100亿、标杆:100亿~1000亿、1000亿以上 | 满足企业核心业务需求,并联合伙伴一起满足企业所有需求,无需集成提供统一工作台、数据接口、底层协议,无论基于Oinone的开源框架还是增加其他应用都有很好的扩展性 | 支持OP+SaaS两种模式,收费方式不同:OP按买断方式进行,SaaS按效果付费跟账号数无关新的模块进行二次销售 |
| 数字化软件服务商 | 针对成熟的大型企业需投入巨大资源和成本客户范围:100亿~1000亿、1000亿以上 | 满足企业部分需求,无法输出技术标准,无法解决多供应商一起开发的问题,只能通过集成实现对接 | OP模式进行销售,通过设置权限来进行来实现二次销售或无法进行二次销售 |
二、Oinone vs 低代码或无代码行业
| 客户 | 满足度 | 销售 | |
|---|---|---|---|
| Oinone | 一站式商业智能软件客户范围:5000万~5亿、5亿~100亿、标杆:100亿~1000亿、1000亿以上 | 从外部商业场景出发,强业务场景驱动,符合企业从信息化管理到业务创新的数字化转变的趋势。提供统一工作台、数据接口、底层协议,无论基于oinone的开源框架还是增加其他应用都有很好的扩展性 | 支持OP+SaaS两种模式,收费方式不同:OP按买断方式进行,SaaS按效果付费跟账号数无关新的模块进行二次销售 |
| 低代码或无代码公司 | 针对小微企业内部信息化管理诉求,以表单流程为主客户范围:5亿以下 | 满足企业部门级信息化的适应性需求,无法满足企业核心业务管理与业务创新诉求 | 按应用模块进行收费,新的模块进行二次销售 |
三、Oinone vs 国外对标公司Odoo
| 客户 | 满足度 | 销售 | |
|---|---|---|---|
| Oinone | 一站式商业智能软件客户范围:5000万~5亿、5亿~100亿、标杆:100亿~1000亿、1000亿以上 | 从外部商业场景出发,强业务场景驱动,符合企业从信息化管理到业务创新的数字化转变的趋势。基线产品覆盖:采购、营销、服务、销售、交易等企业商业领域。主要涉及行业:零售品牌。其他领域或行业靠合作伙伴共建方式进行 | 支持OP+SaaS两种模式,收费方式不同:OP按买断方式进行,SaaS按效果付费跟账号数无关新的模块进行二次销售 |
| Odoo | 一站式企业管理软件客户范围:5000万~5亿、5亿~100亿、标杆:100亿~1000亿、1000亿以上 | 从企业内部管理需求出发,逐渐拥有互联网相关应用组件,但还是属于强内部管理、弱外部场景。基线产品覆盖:业务财务一体化、人财务、进销存。主要涉及行业:建造业。其他领域或行业靠合作伙伴共建方式进行 | 支持OP+SaaS两种模式,收费方式相同:按用户数+应用模块进行收费新的模块进行二次销售 |
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9214.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验
Comments(2)
bug反馈:采用无一体设计 -> 采用低无一体设计
@xinf:感谢反馈,已修正