
基础介绍
前面我们学习了基于低代码开发平台进行快速开发,以及通过oinone的设计器进行零代码开发两种模式。当然低无一体不是简单地说两种模式还指:低无两种模式可以融合。
-
在做核心产品的时候以低代码开发为主,以无代码为辅助。见低代码开发的基础入门篇中设计器的结合一文
-
在做实施或临时性需求则是以无代码为主,以低代码为辅助
本文主要介绍第二种模式,它是www.oinone.top官网在SaaS模式下的专有特性。满足客户安装标品后通过设计器进行适应性修改后,但对于一些特殊场景还是需要通过代码进行完善或开发
在该模式下,我们提供了jar模式和代码托管两种模式,客户只要选择需要进行代码开发的模块,点击生产SDK,下载扩展工程模版,按Oinone低代码开发平台规范进行研发,后上传扩展工程即可。
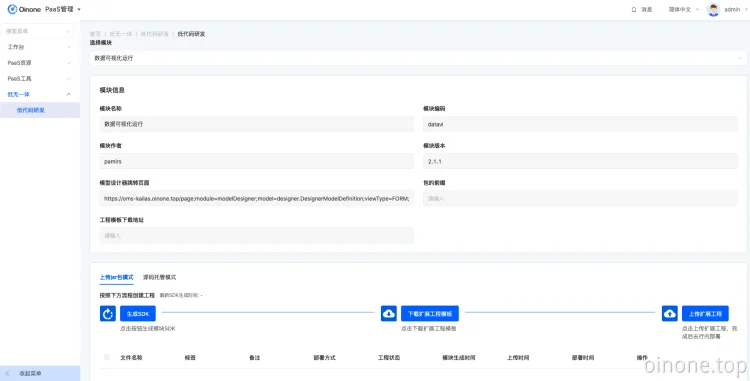

操作手册
低无一体这个模块是连接无代码设计器的桥梁,可以为一个模块或应用设计低代码的逻辑,可以在界面设计器或流程设计器中使用低代码的逻辑。
1.选择模块
首先需要在下拉单选中选择需要低代码的模块或应用。
-
下拉选中只展示在「应用中心」中已安装的模块或应用,可前往「应用中心」安装后继续低代码操作。
-
选择模块中不展示系统的基础模块或应用,因为这些模块或应用无法自定义模型。
2.模块信息
模块信息展示的是选择模块的基础信息:模块名称、模块编码、模块作者、模块版本、包的前缀、工程模板下载地址,下载地址仅在上传jar包模式时候用到。
3.低无一体操作
低无一体支持了两种使用模式:上传jar包模式、源码托管模式。
- 上传控制工程或创建研发分支动作完成会生成一条数据,可以对单条数据进行部署、卸载、修改、删除。
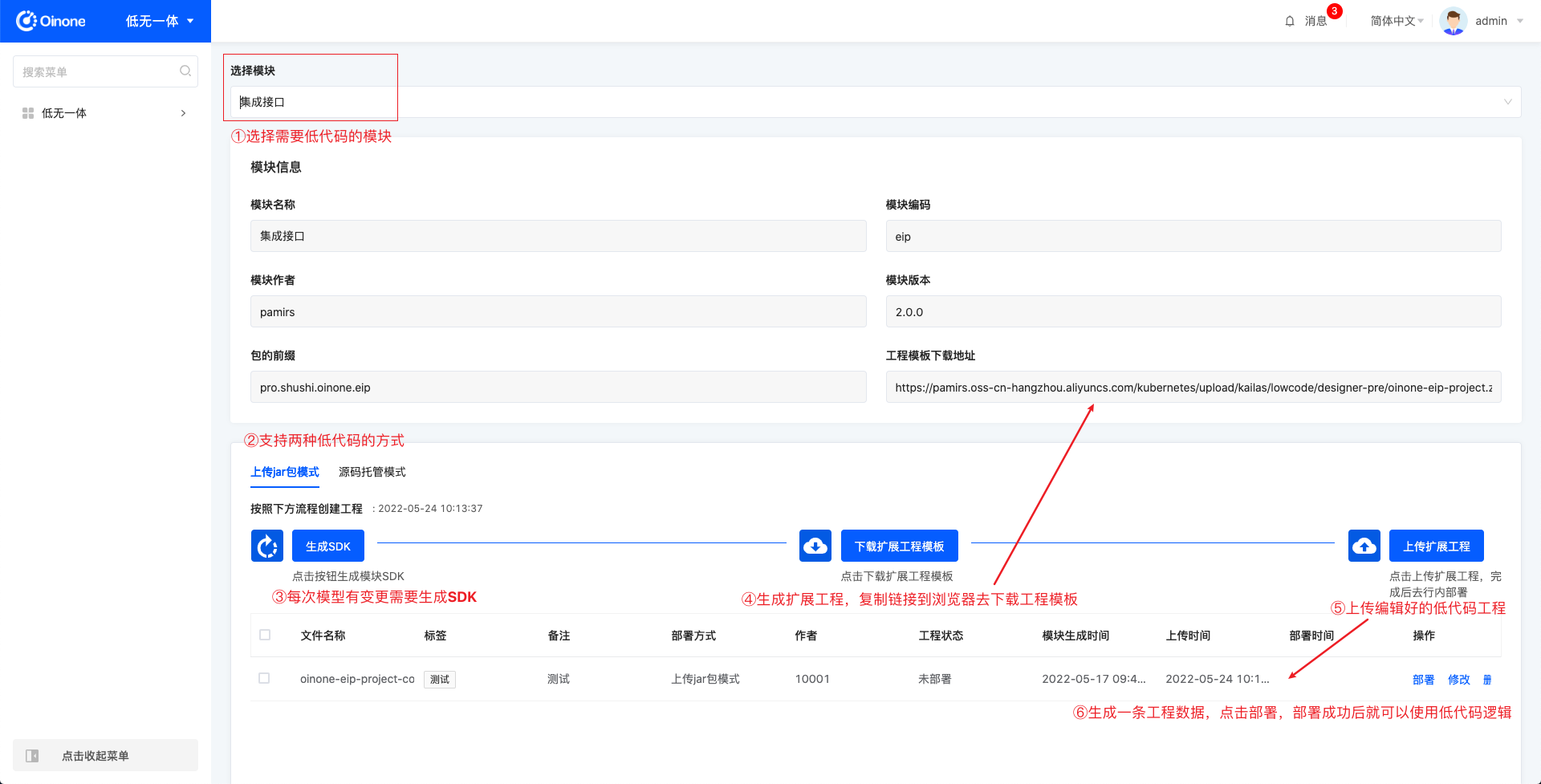
3.1 上传jar包模式
在这个模式下,需要做四步动作。
-
生成SDK,点击按钮之后,会把模块的当前模型状态打成一个SDK包,SDK最新生成时间更新。当模型变更但未生成SDK时,使用低无一体就会出错,请重新生成SDK并修改扩展工程。生成SDK通常需要1分钟左右,若第一次使用低无一体模块,可能需要更长时间,请耐心等待。
-
下载扩展工程模板,点击按钮之后,会将SDK包和工程模板生成一个下载链接,复制模块信息中的卸载地址打开即可下载。
-
技术人员在工程模板的基础上写低代码逻辑。
-
上传扩展工程,点击按钮展开弹窗,在弹窗中设置标签、备注,并将最终的jar包上传,完成上传之后表格中就会新增一条数据。
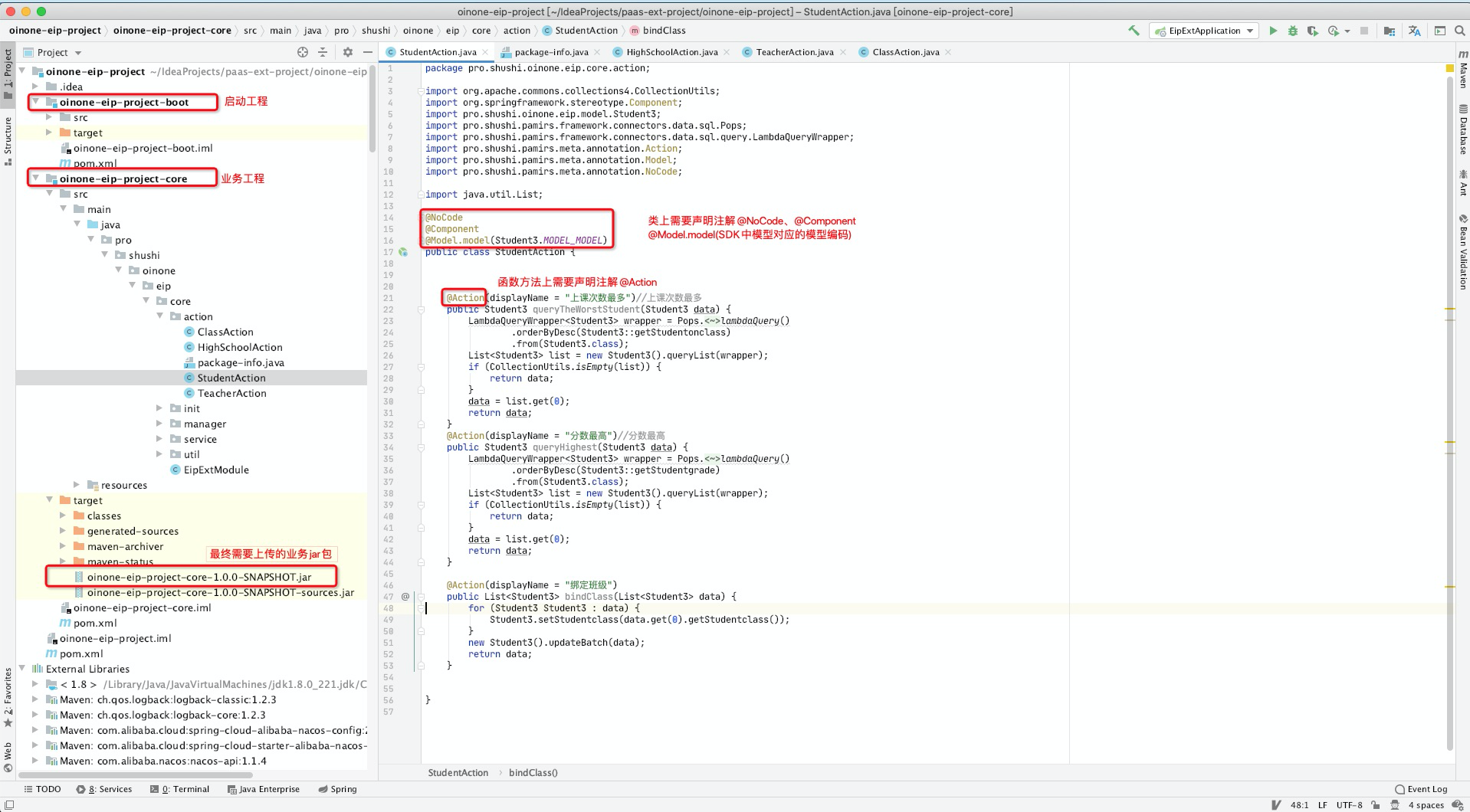
- 上传jar包模式下,模板工程中代码需要注意的点参考下图:
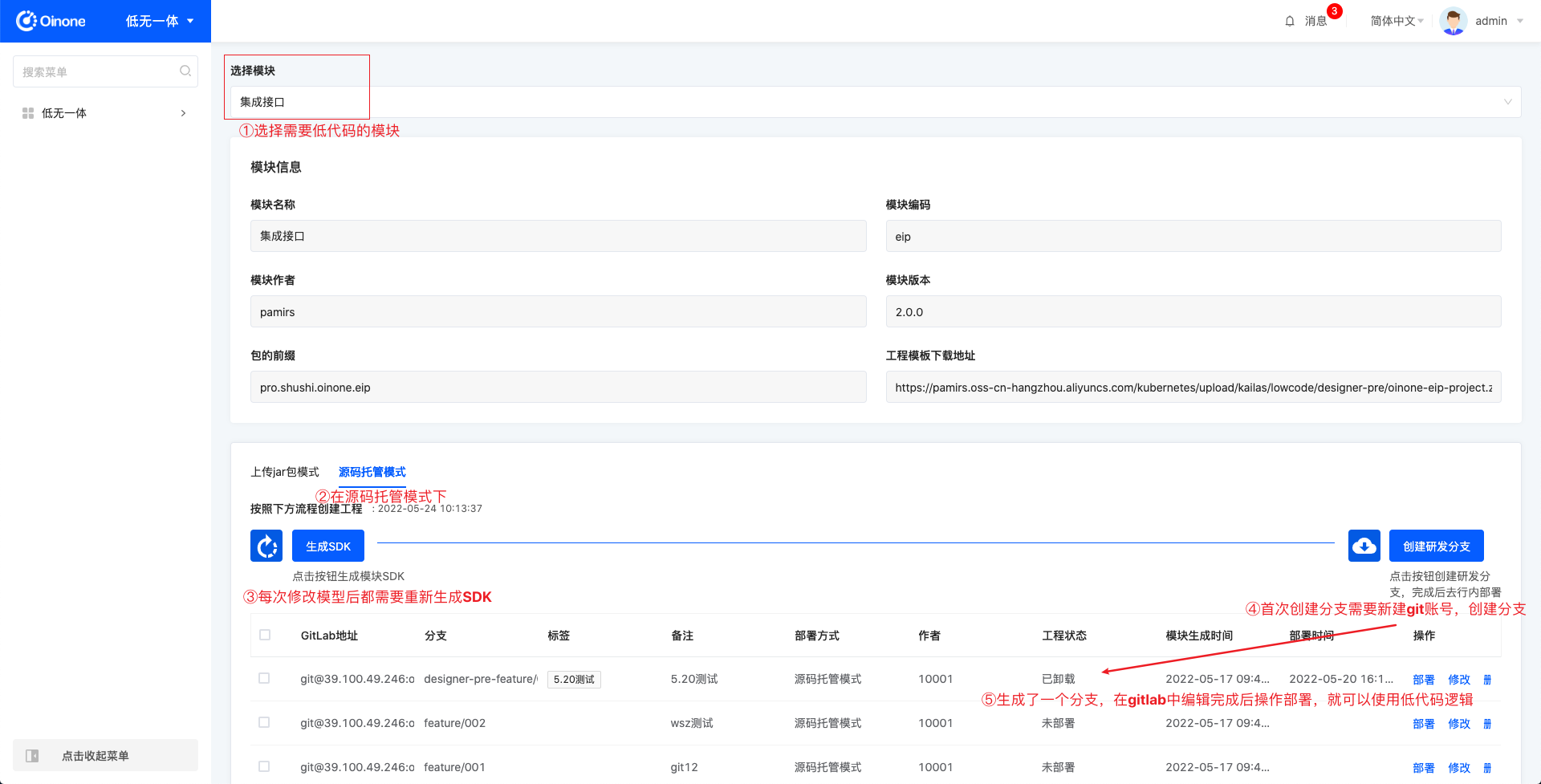
3.2 源码托管模式
在这个模式下,需要做三步动作。
-
生成SDK,点击按钮之后,会把模块的当前模型状态打成一个SDK包,SDK最新生成时间更新。当模型变更但未生成SDK时,使用低无一体就会出错,请重新生成SDK并修改扩展工程。生成SDK通常需要1分钟左右,若第一次使用低无一体模块,可能需要更长时间,请耐心等待。
-
创建研发分支,点击按钮展开弹窗。首次创建时需要设置git账号名称、git账号邮箱来创建一个账号,另外在弹窗中设置分支名称、标签、备注,完成创建后表格中就会新增一条数据。
-
通过表格中的Gitlab地址,技术人员写低代码逻辑。
3.3 行内操作
-
部署:工程状态为未部署、部署失败、已卸载时展示行内的部署按钮,点击之后进行部署,工程状态变为部署中。部署过程大致需要5-10分钟,请耐心等待。部署完成之后,会生成一个新的模块:“原模块名称”扩展工程。
-
卸载:工程状态为已部署时展示行内的卸载按钮,点击之后会卸载这个已部署的工程,工程状态变为已卸载。同一模块只能有一个已部署的工程(与选择的模式无关),若需要使用新的工程请先卸载已部署的工程。
-
修改:行内操作修改按钮始终展示,只允许修改标签、备注。
-
删除:工程状态为未部署、部署失败、已卸载时展示行内的删除按钮,点击之后删除这一条工程记录。
3.4 部署效果
低无一体部署成功之后,可以进入对应模块的模型页面中使用提交动作来使用低代码逻辑,也可以在流程设计器中的引用逻辑节点中使用低代码逻辑。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9338.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验