
针对不同启动指令的组合可以满足不同场景需求,下面列举了几个常规组合方式,小伙伴们务必把这几种模式都尝试一遍,会更有体感
本节为小伙伴讲解oinone模块的几种启动方式,它是为能灵活地应对企业市场的不同场景需求,为op(本地化部署)、saas和研发提供个性化支撑。也为oinone独特性之单体与分布式的灵活切换提供基础支撑
一、部署参数
| 参数 | 名称 | 默认值 | 说明 |
|---|---|---|---|
| -Plifecycle | 生命周期部署指令 | RELOAD | 可选项:无/INSTALL/PACKAGE/RELOAD/DDL安装-install为AUTO;upgrade为FORCE打包-install为AUTO;upgrade为FORCE;profile为PACKAGE重启-install、upgrade、profile为READONLY打印变更DDL-install为AUTO;upgrade为FORCE;profile为DDL |
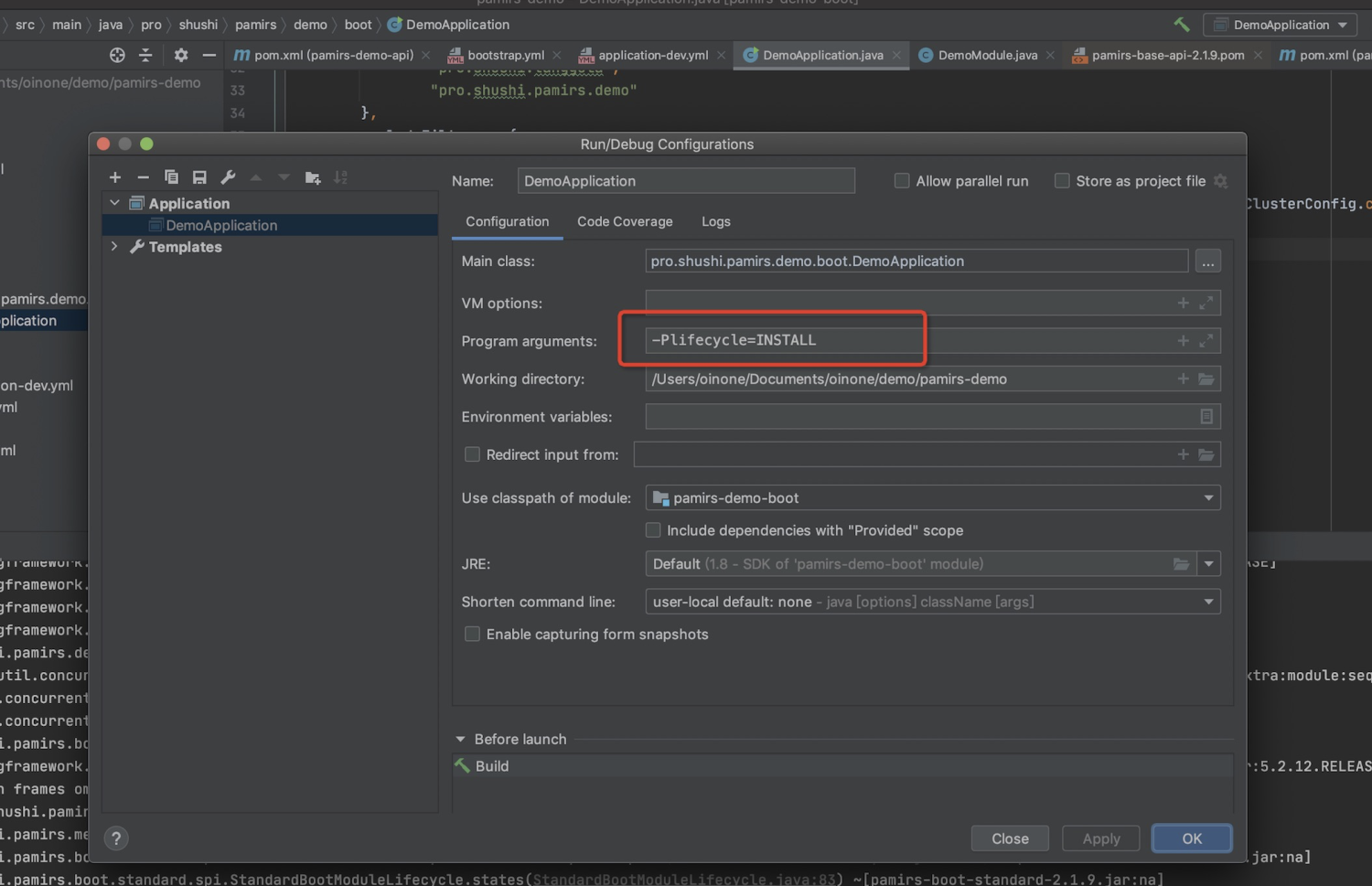
如果在启动命令中配置了部署参数,可不再设置服务参数和可选项参数。下图为在启动命令中添加部署参数的示例。

二、使用场景
针对不同启动指令的组合可以满足不同场景需求,下面列举了几个常规组合方式,小伙伴们务必把这几种模式都尝试一遍,会更有体感。
场景一:DDL(1)+RELOAD(N)应对专有DBA
因为很多公司数据库是由专门的DBA来管理的,不允许应用直接变更数据库相关配置、表结构、初始化数据。而oinone是基于元数据驱动的,任何模型、行为的变化都会自动转化成对物理存储的改变与元数据变化。
oinone为了适用企业op场景,特别增加了DDL模式。把发布上线分为两个步骤。
一:用DDL模式把涉及到数据库的变更与元数据初始化的脚本进行输出,交由客户公司DBA审批,并执行
二:用RELOAD模式,进行正常的应用重启工作,不进行安装、升级、以及数据库物理变革等操作。
#应用启动关闭自动DDL配置
pamirs.boot.profile: CUSTOMIZE
pamirs.boot.options.rebuildTable: false
pamirs.persistence.global.auto-create-database: false
pamirs.persistence.global.auto-create-table: false场景二:PACKAGE(1)+RELOAD(N)应对提升多机器实例效率
在机器规模相对大的场景中我们会碰到以下问题:
-
元数据差量计算、数据库变更、元数据变化保存都非常费时,如果每台机器都来一遍是非常费时费力的
-
分布式下多机器如果并发进行INSTALL,会导致数据库修改表结构、元数据变化保存锁死
所以我们可以选择一台机器用PACKAGE,其他机器采用RELOAD模式,做到合理规避问题,提升应用发布效率
场景三:INSTALL应对开发模式
研发在本地开发模式下INSTALL是最有效率的,把所需依赖模块一把启动和调试。
上线如果要用INSTALL需要注意,要逐台进行。当然也可以改进成INSTALL(1)+RELOAD(N)模式
三、启动命令解读
查看启动命令
可以在启动日志中查看当前所用启动命令。
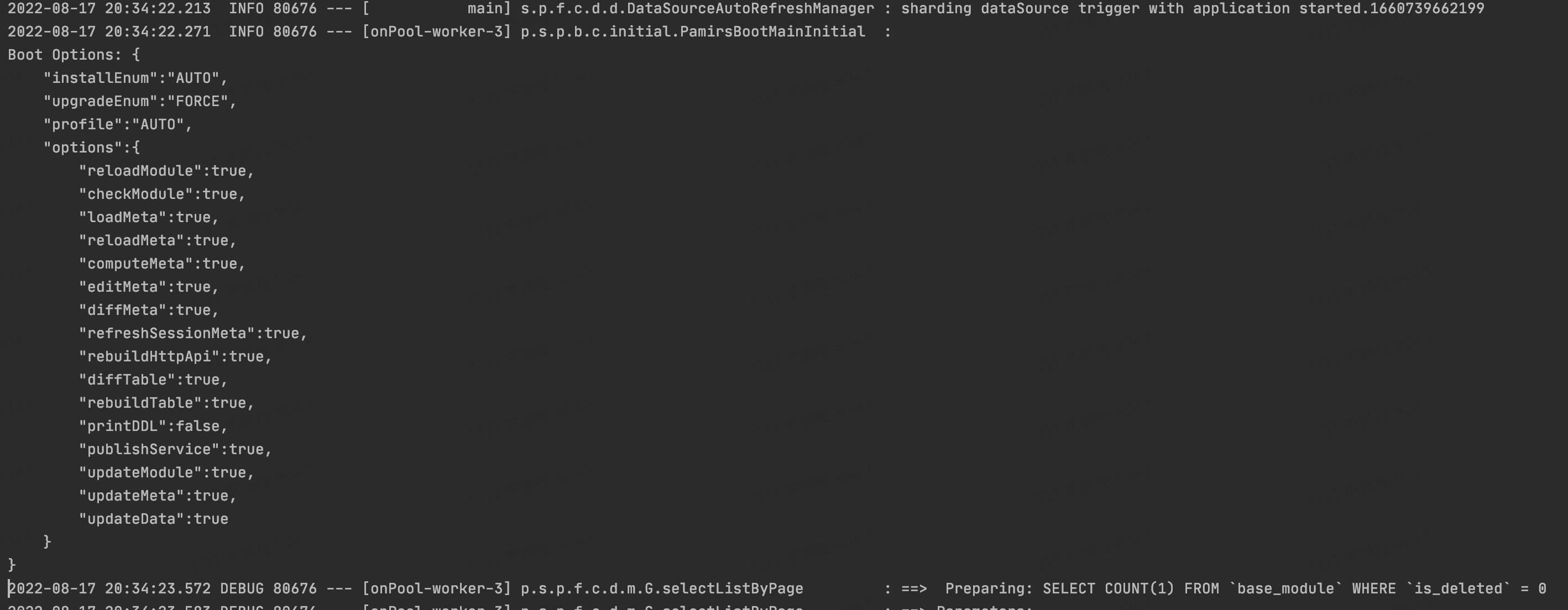 图4-1-2-3 在启动日志中查看当前所用启动命令
图4-1-2-3 在启动日志中查看当前所用启动命令
生命周期管理-Plifecycle
除了通过启动YAML中pamirs.boot属性来设置启动参数,你还可以在应用启动命令中使用-Plifecycle参数来快捷控制模块生命周期的管理方式。该参数的可选项为RELOAD、INSTALL、CUSTOM_INSTALL、PACKAGE、DDL。
java -jar <your jar name>.jar -Plifecycle=RELOAD
启动命令优先级高于YAML中pamirs.boot属性中的install、upgrade和profile属性。如果不使用-Plifecycle参数,则使用YAML中pamirs.boot属性中的install、upgrade和profile属性配置。若YAML中未配置,则采用默认值。
| 启动配置项 | 默认值 | RELOAD | INSTALL | CUSTOM_INSTALL | PACKAGE | DDL |
|---|---|---|---|---|---|---|
| install | AUTO | READONLY | AUTO | AUTO | AUTO | AUTO |
| upgrade | AUTO | READONLY | FORCE | FORCE | FORCE | FORCE |
| profile | CUSTOMIZE | READONLY | AUTO | CUSTOMIZE | PACKAGE | DDL |
profile属性请参考4.1.1【服务启动可选项】一文。只有pamirs.boot.profile=CUSTOMIZE时,在pamirs.boot.options中自定义的可选项才生效。
自动建表-PbuildTable
java -jar <your jar name>.jar -PbuildTable=NEVER
- PbuildTable参数用于设置自动构建表结构的方式。如果不使用该参数,则options属性的默认值请参考4.1.1【服务启动可选项】一文。-PbuildTable参数可选项为:
- NEVER - 不自动构建表结构,会将pamirs.boot.options中的diffTable和rebuildTable属性设置为false
- EXTEND - 增量构建表结构,会将pamirs.boot.options中的diffTable属性设置为false,rebuildTable属性设置为true
- DIFF - 差量构建表结构,会将pamirs.boot.options中的diffTable和rebuildTable属性设置为true
模块在线 -PmoduleOnline
java -jar <your jar name>.jar -PmoduleOnline=CHECK
- PmoduleOnline参数用于设置模块在线的方式。如果不使用该参数,则profile属性的默认值请参考4.1.1【服务启动可选项】一文。-PmoduleOnline参数可选项为:
- NEVER - 不读取存储在数据库中的模块信息,会将pamirs.boot.options中的reloadModule和checkModule属性设置为false
- READ - 读取存储在数据库中的模块信息,会将pamirs.boot.options中的checkModule属性设置为false,reloadModule属性设置为true
- CHECK - 读取存储在数据库中的模块信息并校验依赖模块是否已安装,会将pamirs.boot.options中的reloadModule和checkModule属性设置为true
元数据在线-PmetaOnline
java -jar <your jar name>.jar -PmetaOnline=MODULE
- PmetaOnline参数用于设置元数据在线的方式,如果不使用该参数,则profile属性的默认值请参考4.1.1【服务启动可选项】一文。-PmetaOnline参数可选项为:
- NEVER - 不持久化元数据,会将pamirs.boot.options中的updateModule、reloadMeta和updateMeta属性设置为false
- MODULE - 只注册模块信息,会将pamirs.boot.options中的updateModule属性设置为true,reloadMeta和updateMeta属性设置为false
- ALL - 注册持久化所有元数据,会将pamirs.boot.options中的updateModule、reloadMeta和updateMeta属性设置为true
开放远程服务-PenableRpc
- PenableRpc参数用于设置是否开启远程服务。如果不使用该参数,则profile属性的默认值请参考4.1.1【服务启动可选项】一文。-PenableRpc参数可选项为true和false。该参数会将参数值设置到pamirs.boot.options中的publishService属性。
开启API服务-PopenApi
- PopenApi参数用于设置是否开启HTTP API服务。如果不使用该参数,则profile属性的默认值请参考4.1.1【服务启动可选项】一文。-PopenApi参数可选项为true和false。该参数会将参数值设置到pamirs.boot.options中的rebuildHttpApi属性。
开启字段校验-PcheckField
- PcheckField参数用于设置是否开启字段校验。-PcheckField参数可选项为true和false。由于通常应用的字段数量非常多,会延长系统启动时长,所以默认不会开启字段校验。
启用数据初始化服务-PinitData
- PinitData参数用于设置是否开启数据初始化服务。如果不使用该参数,则profile属性的默认值请参考4.1.1【服务启动可选项】一文。-PinitData参数可选项为true和false。该参数会将参数值设置到pamirs.boot.options中的updateData属性。
四、不使用自动构建数据库表功能
Oinone LCDP默认提供框架的所有服务,所以会自动构建数据库表。如果不需要使用Oinone的存储构建服务,可以设置YAML文件中关于自动建表的配置。这样就不会动态构建数据库表,你可以手动搭建数据库表。
通过配置启动YAML中pamirs.boot.options.rebuildTable为false彻底关闭自动建表功能。
pamirs:
boot:
options:
rebuildTable: false也可以按需配置启动YAML中pamirs.persistence配置来关闭部分数据源的自动建表功能。persistence配置既可以针对全局也可以分数据源进行配置。
pamirs:
persistence:
global:
# 是否自动创建数据库的全局配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的全局配置,默认为true
autoCreateTable: true
<your ds key>:
# 是否自动创建数据库的数据源配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的数据源配置,默认为true
autoCreateTable: trueOinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9277.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验