
以“企业级软件生态”的方式去帮助企业建立“一站式的商业智能软件”。
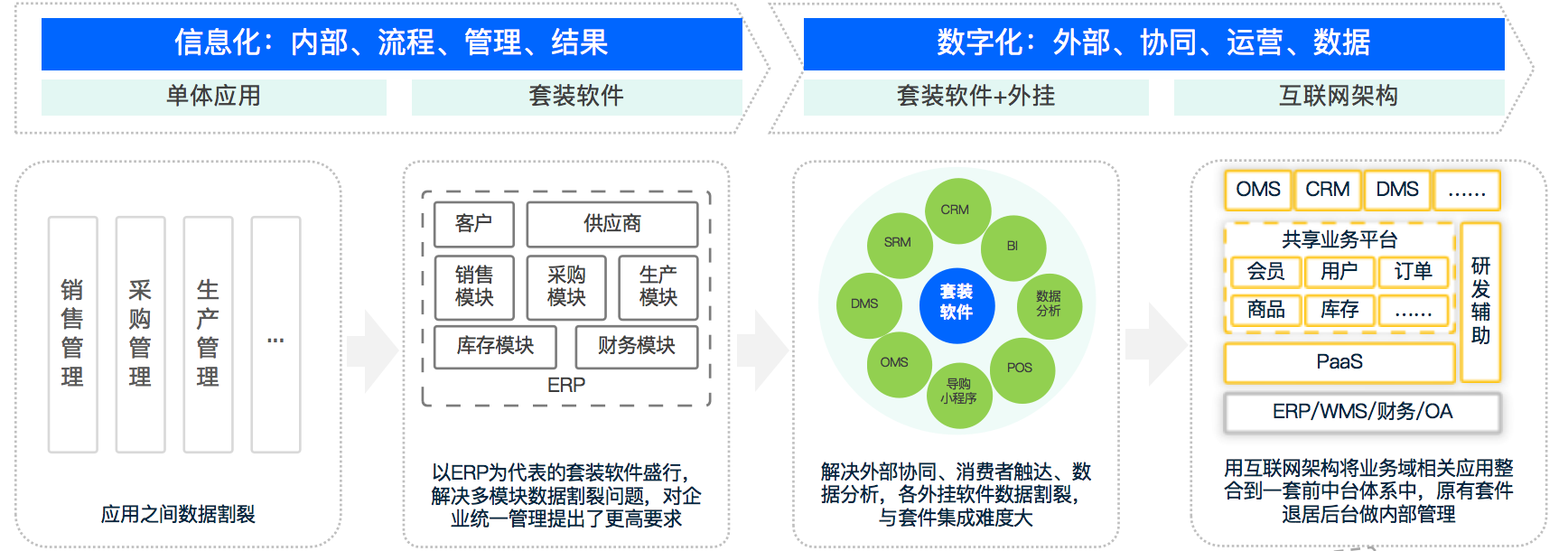
通过观察信息化到数字化的软件行业发展历程(如下图1-3所示),我们可以发现,企业真正需要的是一站式的软件产品。然而,一站式的软件产品往往都是从单个领域的需求满足开始,这在信息化时代和数字化时代都是如此。在信息化时代,以ERP为终点的一站式趋势逐渐形成;而在数字化时代,中台概念的提出则标志着一站式的趋势重新开始。本文将从企业数字化转型所面临的困境出发,探讨Oinone的生态思考。

1.3.1 与中台的渊源
中台概念的提出标志着企业数字化改造进入了一个新的时代。随着数字化转型不断深入,企业面临着严重的数据割裂、系统隔离等问题。在这样的背景下,“敏捷响应,低成本地快速创新”成为了推动一站式商业智能软件的内在诉求。需要澄清的是,互联网中台架构只是一种企业解决数据割裂、系统隔离,建立一站式商业智能软件的技术概念之一,并不是技术标准。而且这种方式只适用于企业自建模式。在多供应商环境下,则会适得其反,导致建立更复杂的烟囱系统。
阿里于15年提出中台架构概念,抓住了企业数字化转型的核心诉求,即“敏捷响应,低成本快速创新”。然而,阿里作为一家生态公司,在16年时基本上是带着合作伙伴来给企业交付,但由于伙伴对互联网技术的理解和能力的限制,基本上都做得不好,甚至失败。在2017年,阿里成立了原生交付团队,希望能够树立一些标杆案例。我和公司的核心成员也都来自于这个团队。在做完几个客户后,我发现阿里也做不好,但这次做不好的原因不是技术不行或项目上不了线,而是上线以后预期的效果没有达到,其本质是企业的IT组织能力无法驾驭复杂的互联网中台架构。当无法驾驭的时候,所谓的目标“敏捷响应,快速创新”就无从说起了。结果客户会反馈以下三类问题:
-
不是说敏捷响应吗?为什么改个需求这么慢,不但时间更长,付出的成本也更高了?是因为中台架构需要一定的技术能力和经验才能有效地应用,就像一个只会骑自行车的人给他一辆汽车或者飞机,他也不能驾驭它们,更不用说是手动挡的。
-
不是说能力中心吗?当引入新供应商或有新场景开发的时候,为什么前期做的能力中心不能支撑了?是因为能力中心是一种面向业务的能力组织方式,它将不同的业务能力抽象出来,以服务的形式对内提供。然而,由于业务场景的差异,不同的业务需要的能力也会不同,因此能力中心需要不断迭代和升级。对于新引入的供应商或新场景开发,需要根据实际情况对能力中心进行定制化和扩展化,但谁来负责呢?新项目的供应商还是客户自己?
-
不是说性能好吗?为什么我投入的物理资源更多了?是因为中台架构采用微服务来解决单点瓶颈问题,提高系统性能和可用性,但是在初始阶段,投入的资源可能会更多。每个模块至少需要两个实例来保障高可用性,因此物理资源的投入量可能会比以前更多。
1.3.2 找解决方案
在考虑解决方案之前,我们需要思考企业数字化软件的最终状态将是什么样子。目前有两种主要的方案(如下图1-4所示):
第一种是以自建研发团队为核心。中国的大型企业已经开始尝试这种模式,看起来似乎是一个时下比较流行的可行性方案。然而,绝大多数企业由于成本、人才团队等原因而难以坚持下去,只能与供应商合作开发。
第二种是以供应商为核心。由于大多数企业无法选择第一种路径,他们必须接受目前分散的情况,并通过系统集成尽可能拉通各个系统。尽管如此,在数字化时代中,真正意义上的一站式商业智能软件供应商还未出现。
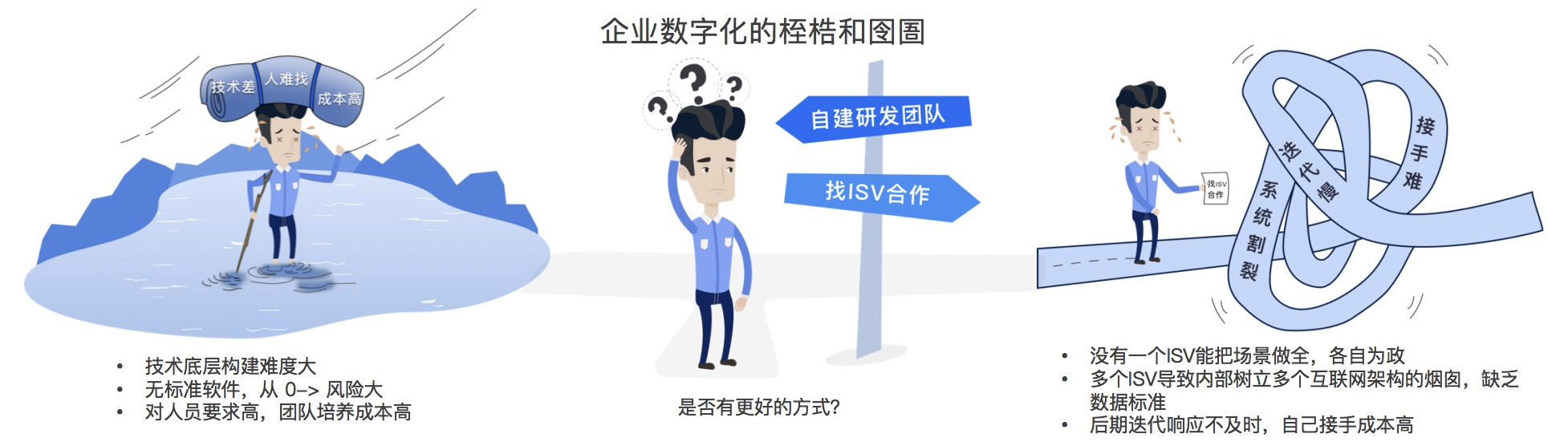
对企业来说,这两种方案都非常艰难,但在大规模数字化历程中又不得不做出选择。此外,我们还能清晰看到以下几点:
-
"敏捷响应,低成本地快速创新"成为企业推动一站式商业智能软件的内在诉求
-
目前没有一家软件供应商能满足企业所有外围商业场景,也不可能有这样的供应商
-
绝大部分企业需要软件供应商,而不是自建
如何突破这种局面也成为中国软件行业发展的一个机遇。因此,我的思考是:
-
我们的目标不是依托于提升研发人员的能力,而是降低互联网架构的门槛,让更多企业真正拥有“敏捷响应,低成本快速创新”的能力。
-
我们的目标不是输出中台方法论,而是提供中台建设的技术平台。
-
我们的目标不是只服务大企业,而是真正赋能不同IT组织能力的企业,让它们都具备持续创新的能力。
今天,许多中台软件公司告诉企业:“中台是持续演进和快速迭代的过程,因此企业需要组建中台架构团队来实现,而他们则通过中台项目落地将中台建设方法论传授给企业。”这句话的前半部分是正确的,因为我们之前提到企业需要具备敏捷响应业务的能力,即应变能力,因为应变是不断变化的。然而,后半部分是不正确的,因为今天的企业已经有能力组建团队,那么这些中台软件公司到底有什么用呢?企业真的缺少方法论吗?在19年,我就提出了自己的看法:没有低代码能力的中台公司都在收取智商税,都在欺诈,因为很多企业根本找不到足够懂互联网架构的人才。明白流氓在哪里了吗?这些流氓公司赚了很多钱,最后责怪企业无法招到人才,这是企业的责任。因此,仍然认为“最好的赋能是降低门槛,而不是让客户提高技术水平”。
最终,我们得出了一个服务模式的想法:构建企业级的软件生态。企业级软件生态的确切定义是:通过开放的方式,让企业本身以及不同的软件供应商共同参与,遵循相同的技术和数据规范,打造一体化、无需集成的各类企业级软件。如果要打造企业级软件生态,我们列出了六个要点(如下图1-5所示)。

我很幸运地有机会通过“企业级软件生态”的方式,为企业建立“一站式的商业支持平台”提供帮助。我们的Oinone平台结合了低代码开发、通用数据模型和业务产品的优势(如下图1-6所示)。
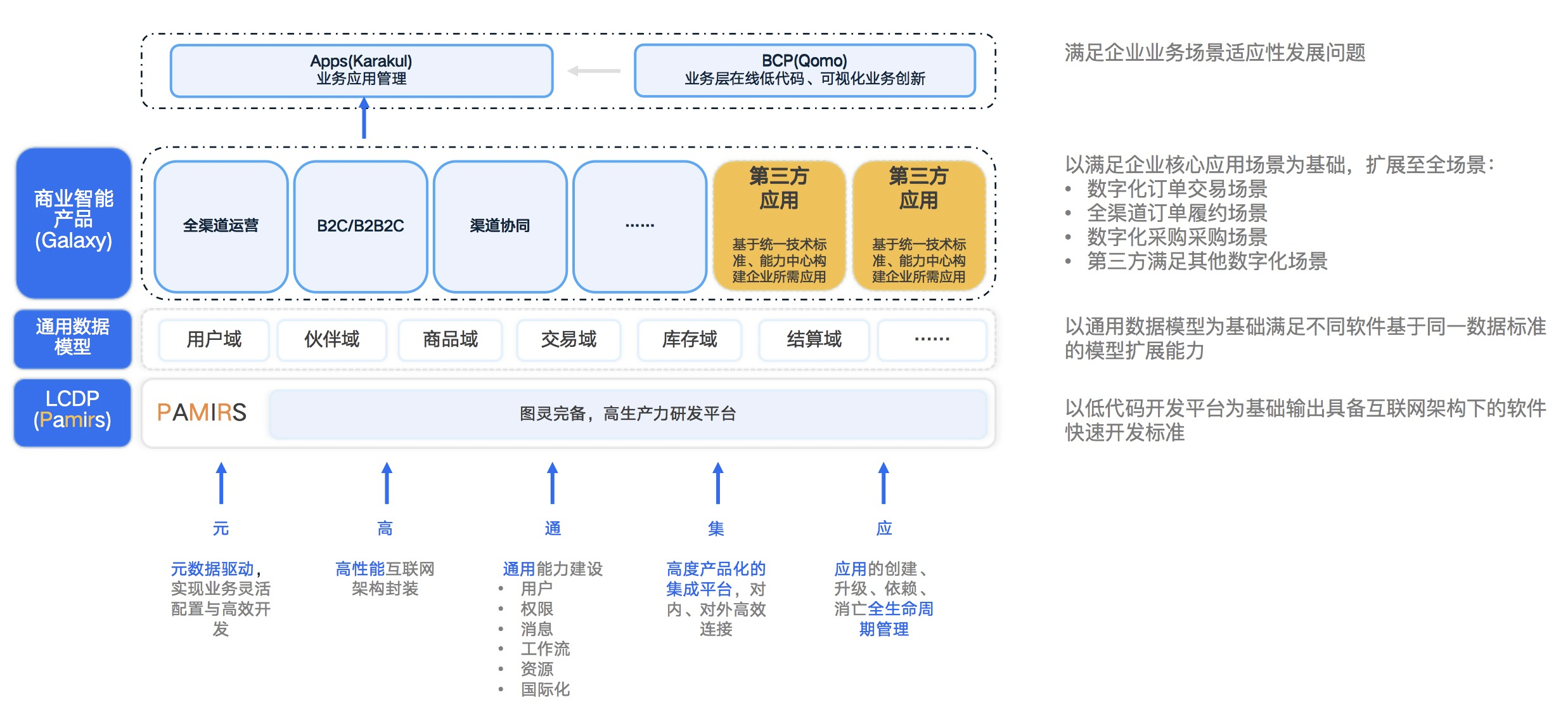
我们对Oinone一站式低代码商业支撑平台展开介绍,它大致分为4部分:
-
以低代码开发平台为基础,输出具备互联网架构下的软件快速开发标准。这可以帮助企业快速构建符合互联网架构标准的应用程序,从而实现快速响应和低成本创新。
-
以通用数据模型为基础,满足不同软件基于同一套数据标准的扩展能力。这可以确保不同软件系统之间的数据兼容性和互操作性,避免数据孤岛和信息隔离。
-
在业务产品层面上,企业和伙伴基于相同的技术标准和数据标准共同提供解决方案。这可以帮助企业和伙伴共同开发出符合标准的商业支撑平台,以提高业务效率和创新能力。
-
最后是无代码设计器,用于满足项目开展中,超出业务标品范围之外的需求,或者针对标品的临时需求。这可以帮助业务人员在不需要专业软件支持的情况下,自主解决业务需求,并支持部门间的协同工作。
1.3.3 生态建设
Oinone致力于打造全球最大的无需集成的商业应用程序及其生态系统,通过开源内核、汇集数千名开发人员和业务专家,为企业提供成本效益、一体化、模块化的解决方案,解决所有商业需求,让不同技术之间的合作变得简单易行,摆脱烦恼的集成问题。
在客户和场景领域,我们严格限定了自身的专注领域。针对超大型头部企业,我们专注于树立标杆,而对于大、中、小型企业,则交由我们的伙伴来支持。小微企业可以通过我们的开源社区版获得覆盖。在企业数字化转型的核心领域中,我们的解决方案涵盖了数字化交易场景、全渠道订单履约场景、数字化采购场景、数字化营销等产品。在其他领域,我们完全交由伙伴来建设。由于我们自身在企业协同商务领域拥有深厚的背景,因此在该领域提供的产品拥有特别的优势。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9212.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验