
1.通知类
1.1 站内信
当流程节点需要向用户发送消息或提示时使用站内信这个节点动作。接收人的选取类似审批节点的审批人,通知内容必填,配置完成,保存即可。
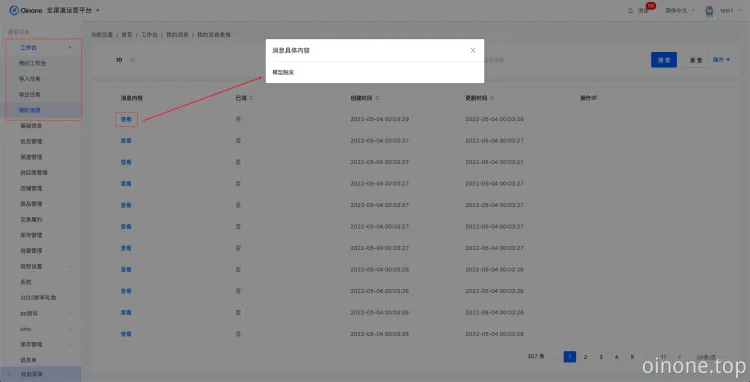
节点触发后,接收人会在全渠道运营平台-工作台-我的消息中查看到站内信。

1.2 邮件
当需要向指定邮箱发送邮件时使用邮件这个节点动作。可直接输入邮箱号,或者按照员工、部门、角色来选择,给接收人登记的邮箱发送邮件,也可以选择模型中的邮箱来发送邮件,若人员重复时只会发送一次邮件。填写主题,填写正文时可以调用当前流程中的一些模型字段的变量。
1.3 短信
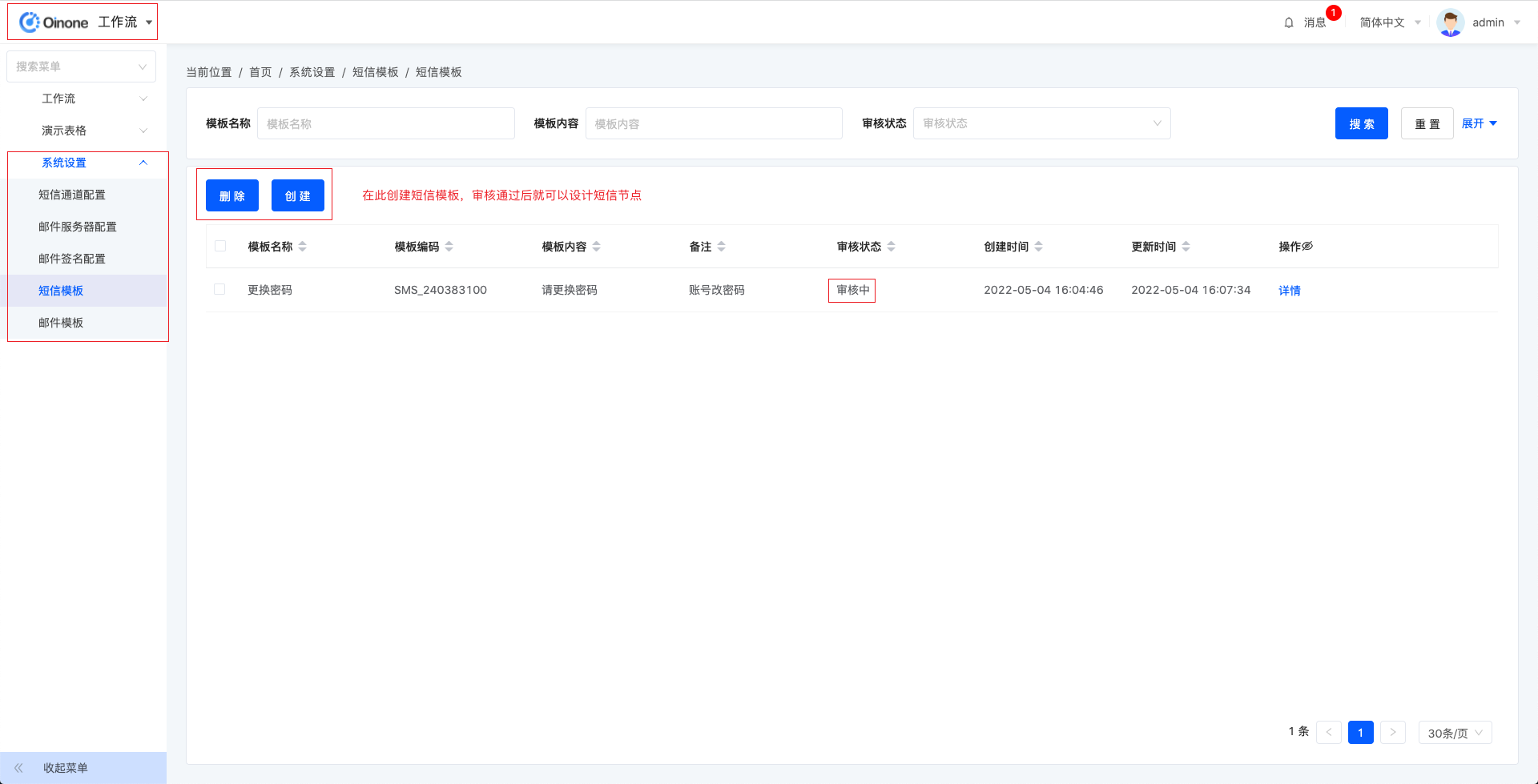
发送短信需要在工作流-系统设置-短信模板中创建一个短信模板,阿里云模版新增需要一段时间审核,审核通过后就可以正常使用短信节点。短信的接收人与邮件的操作方式一致,之后选择短信模板,并且确定好变量的对应关系即可。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9417.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验