
1. 查看、处理流程
1.1 流程查看
流程管理页面共同点:
-
选项分类筛选
-
标签筛选
-
应用下拉选筛选
-
根据流程名称搜索
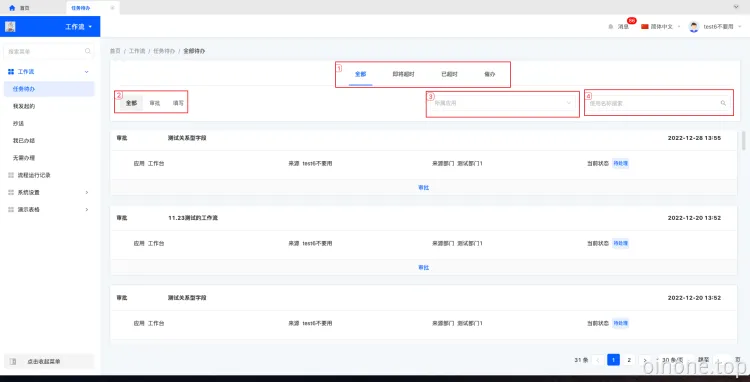

- 流程管理页面名词解释:
-
任务待办:当前登录用户未处理的流程节点
-
我发起的:当前登录用户人为触发的流程(模型触发)
-
抄送:抄送给当前登录用户的节点(审批/填写)
-
我已办结:由当前登录用户完成人工/自动同意、人工拒绝或人工填写的节点
-
无需办理:当前登录用户转交的任务/被退回、被撤销、被或签、被其他分支任务拒绝的还未办理的任务
1.2 流程处理
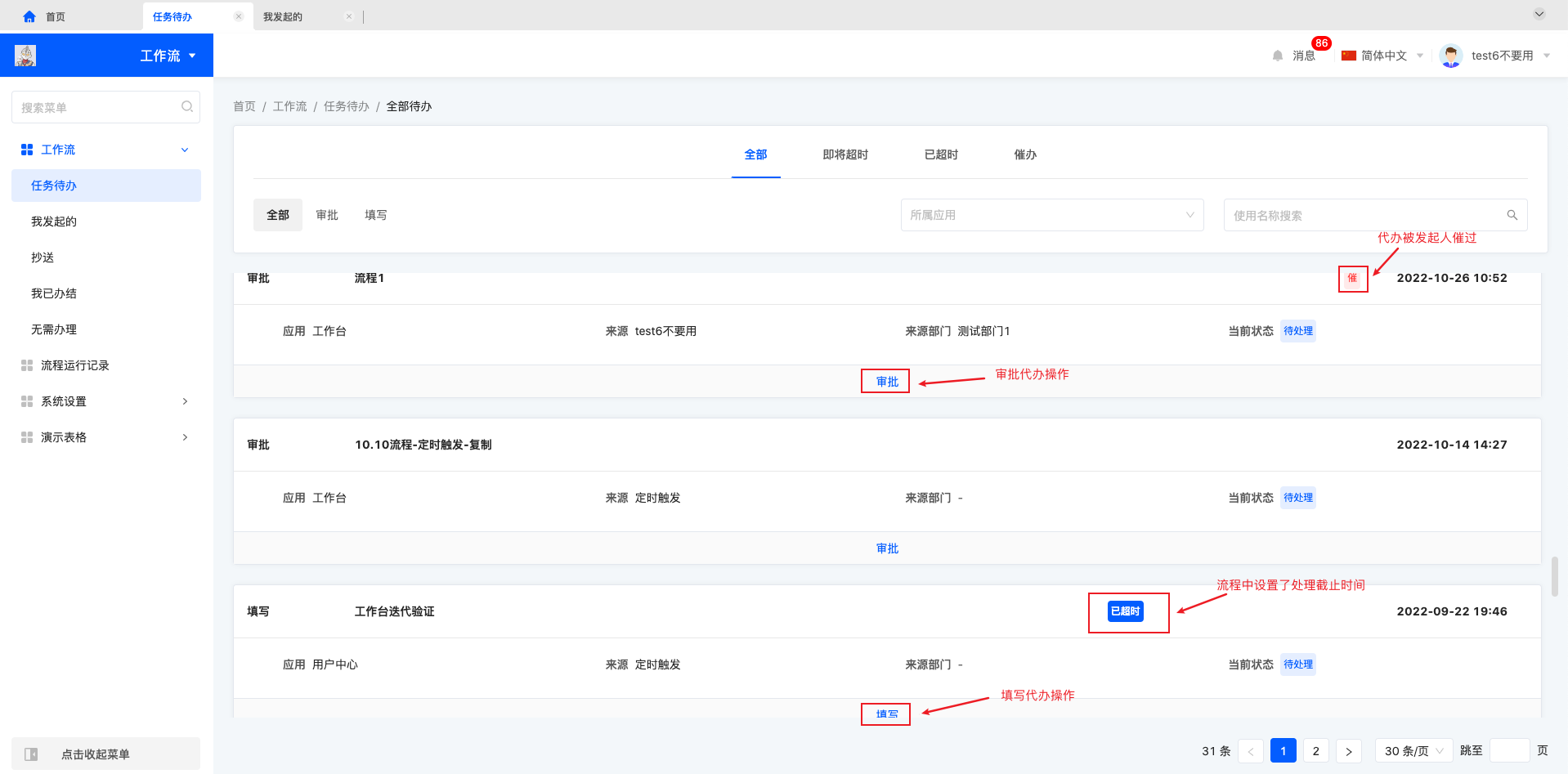
1.2.1 任务待办
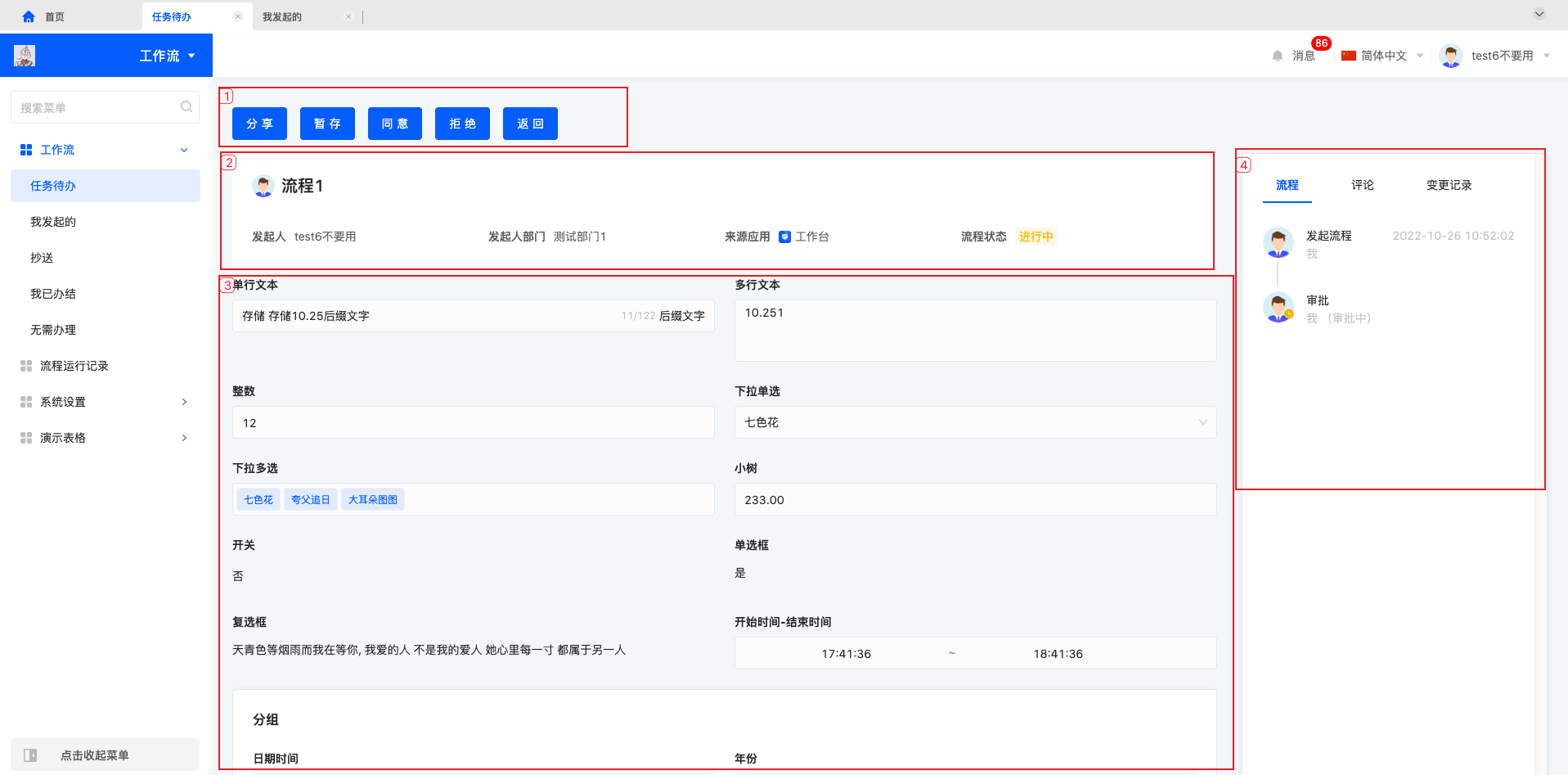
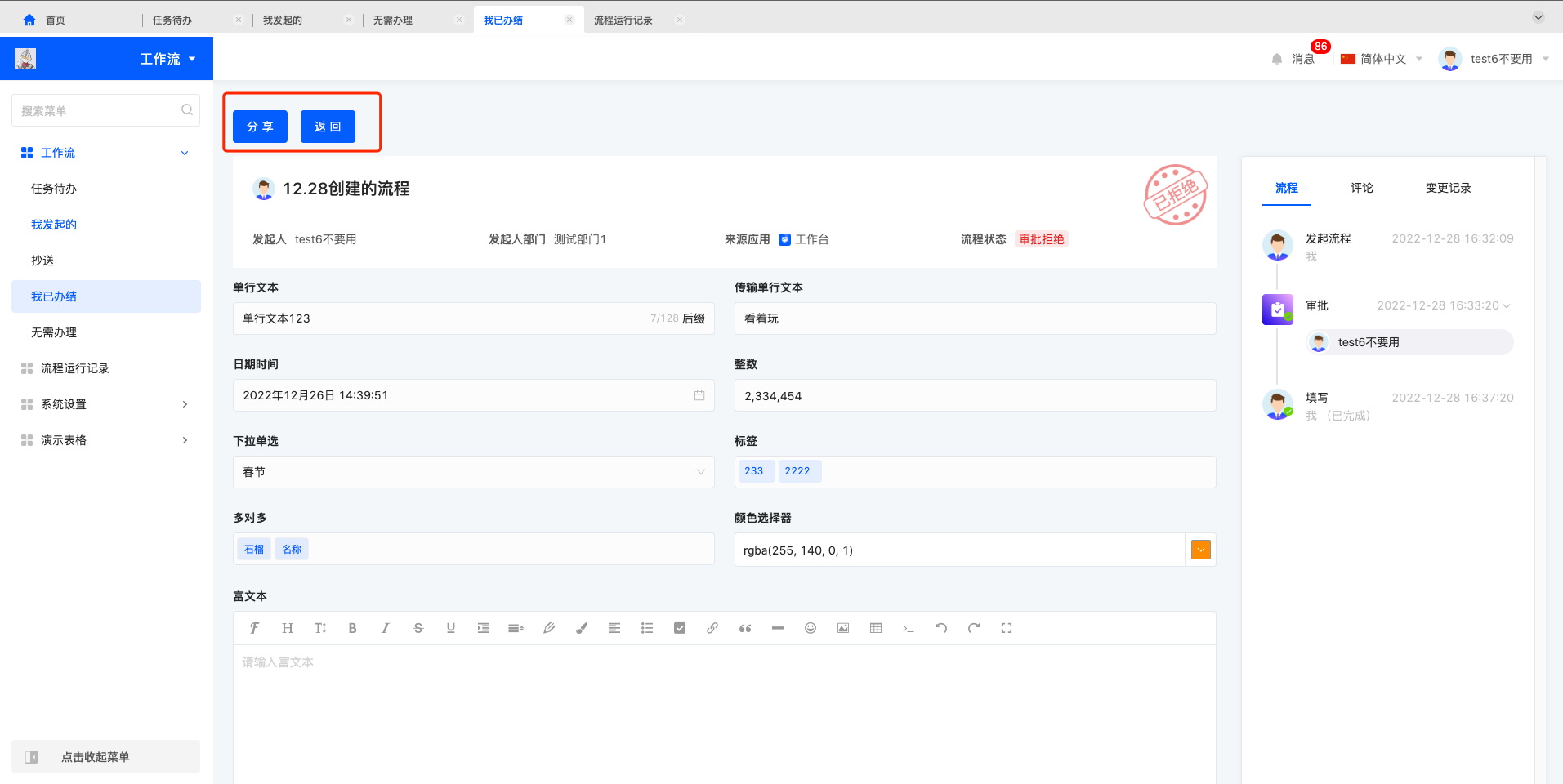
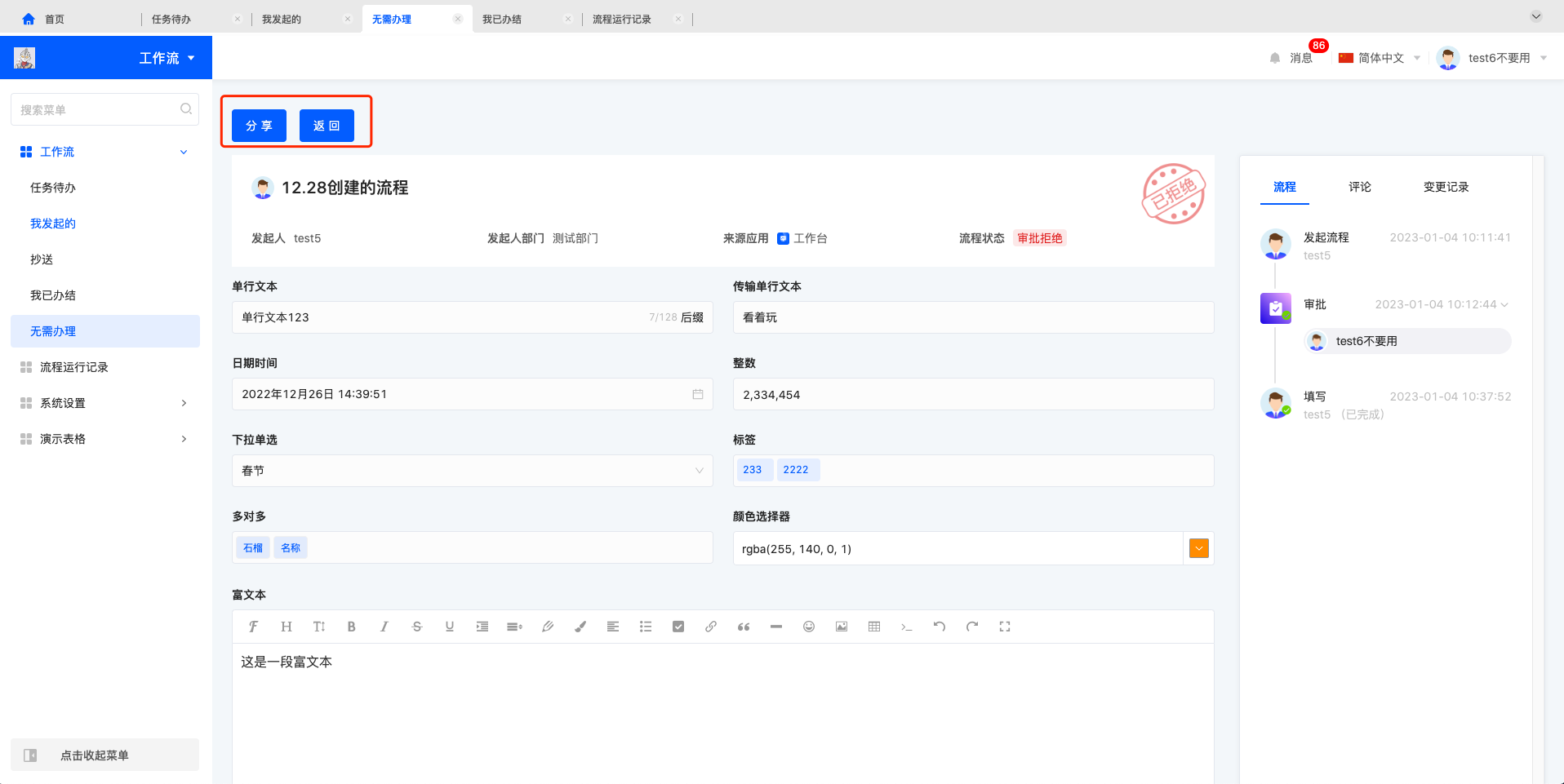
任务待办中点击“审批/填写”会进入流程详情处理页面,主要展示 1. 操作区 2. 流程发起人及状态 3. 模型视图内容 4. 流程时间线及其他记录。
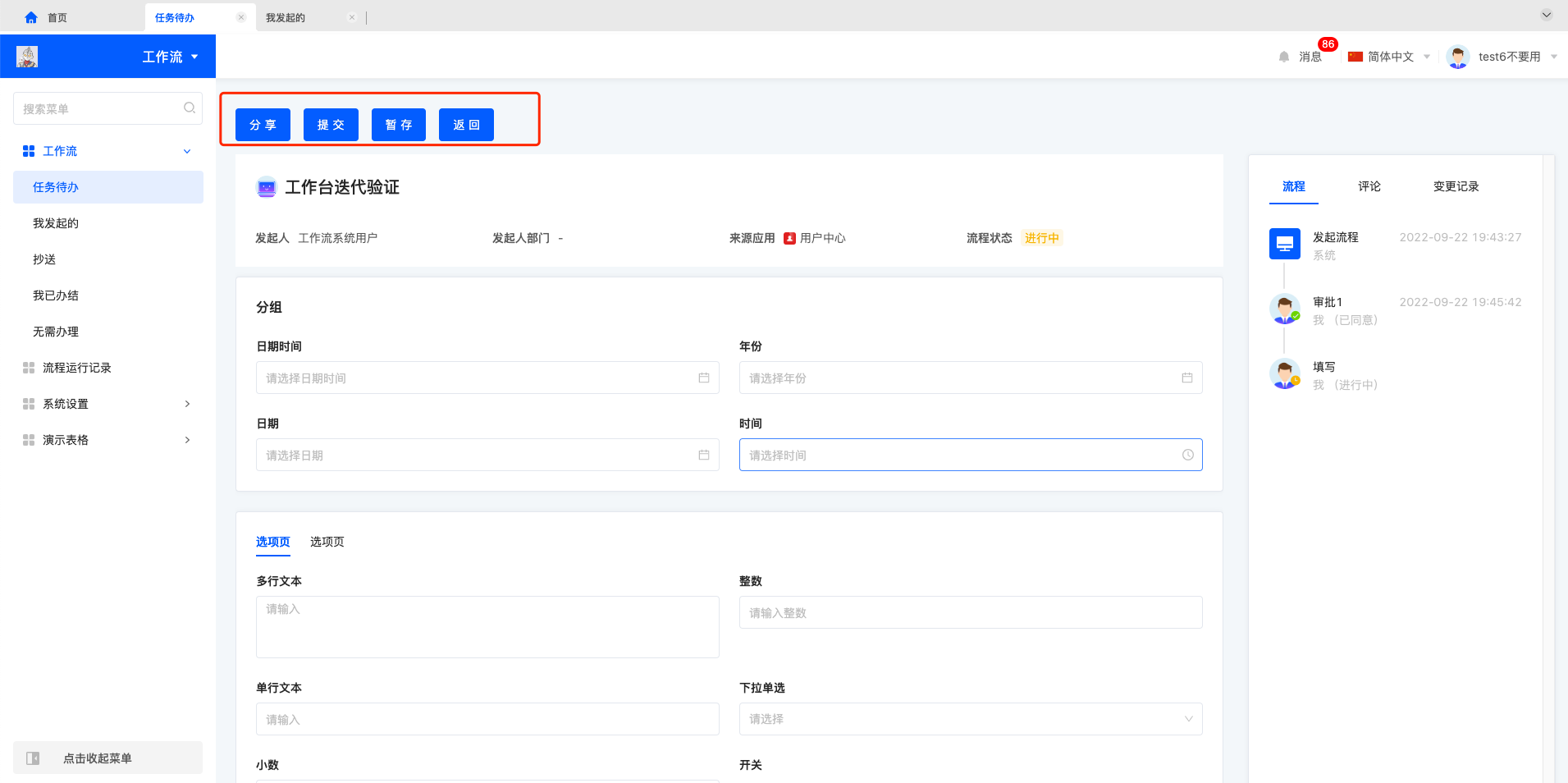
审批代办操作区可能包含“分享、同意、拒绝、退回、加签、转交、返回”,填写代办操作区可能包含“分享、转交、提交、暂存、返回”,审批/填写操作区包含哪些动作由流程设计决定。
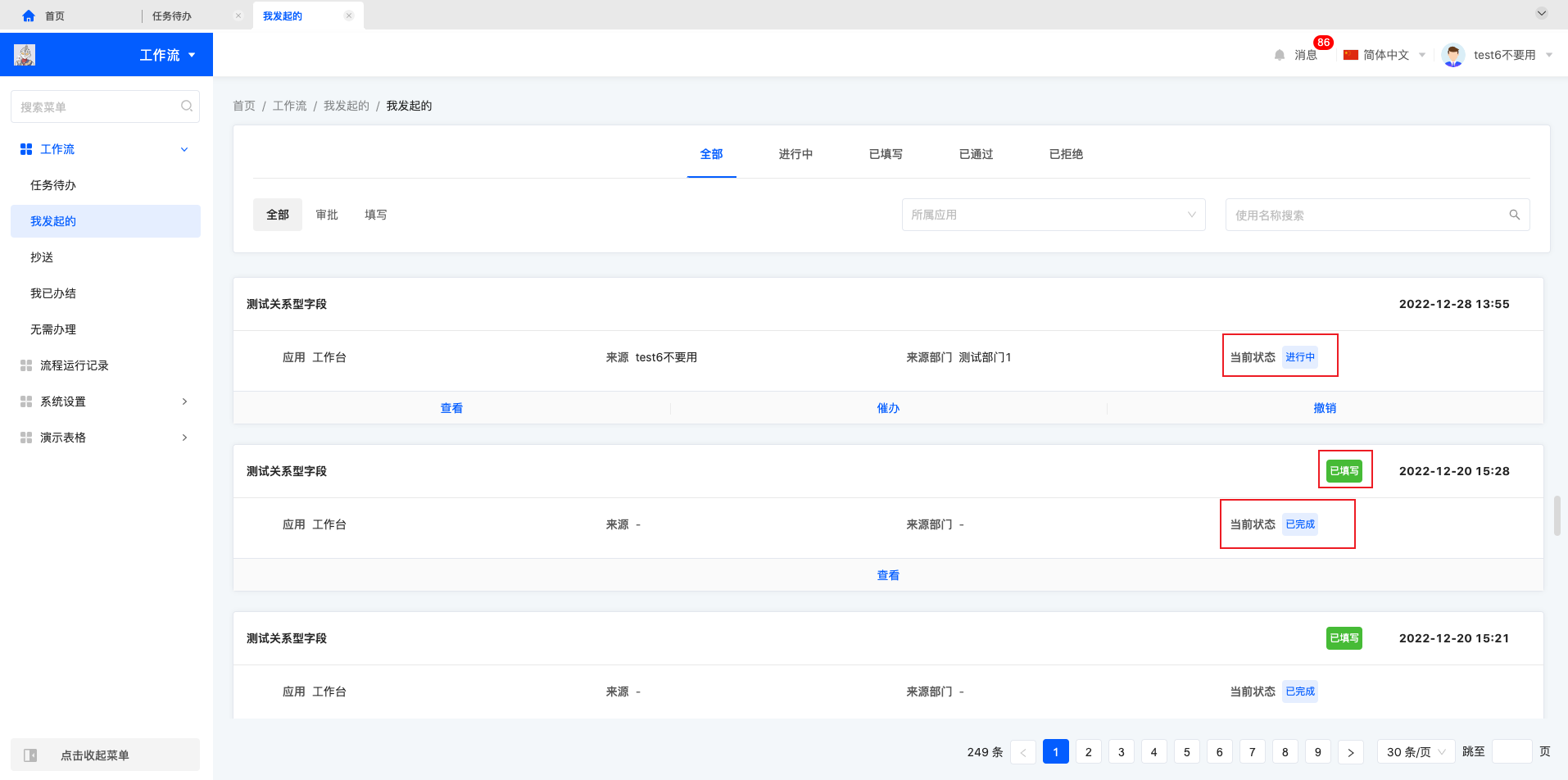
1.2.2 我发起的
我发起的流程列表中主要分为进行中和已完成的流程。进行中的流程可以进行查看、催办、撤销的操作,已完成的流程可以进行查看操作。
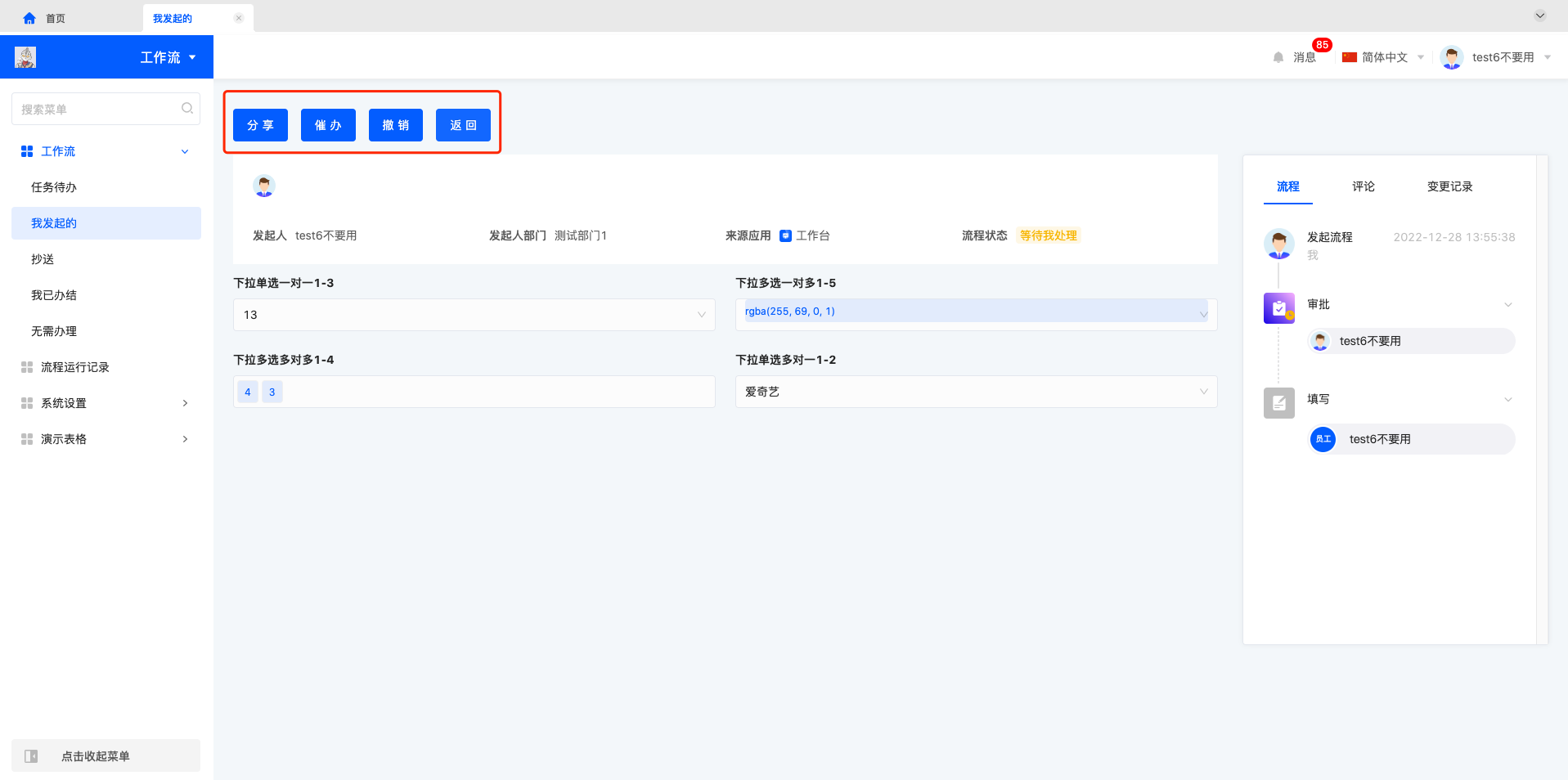
查看我发起的流程,进入流程详情页面,也是根据流程状态展示对应操作功能,进行中的流程有分享、催办、撤销、返回按钮,已完成的流程有分享、返回按钮。

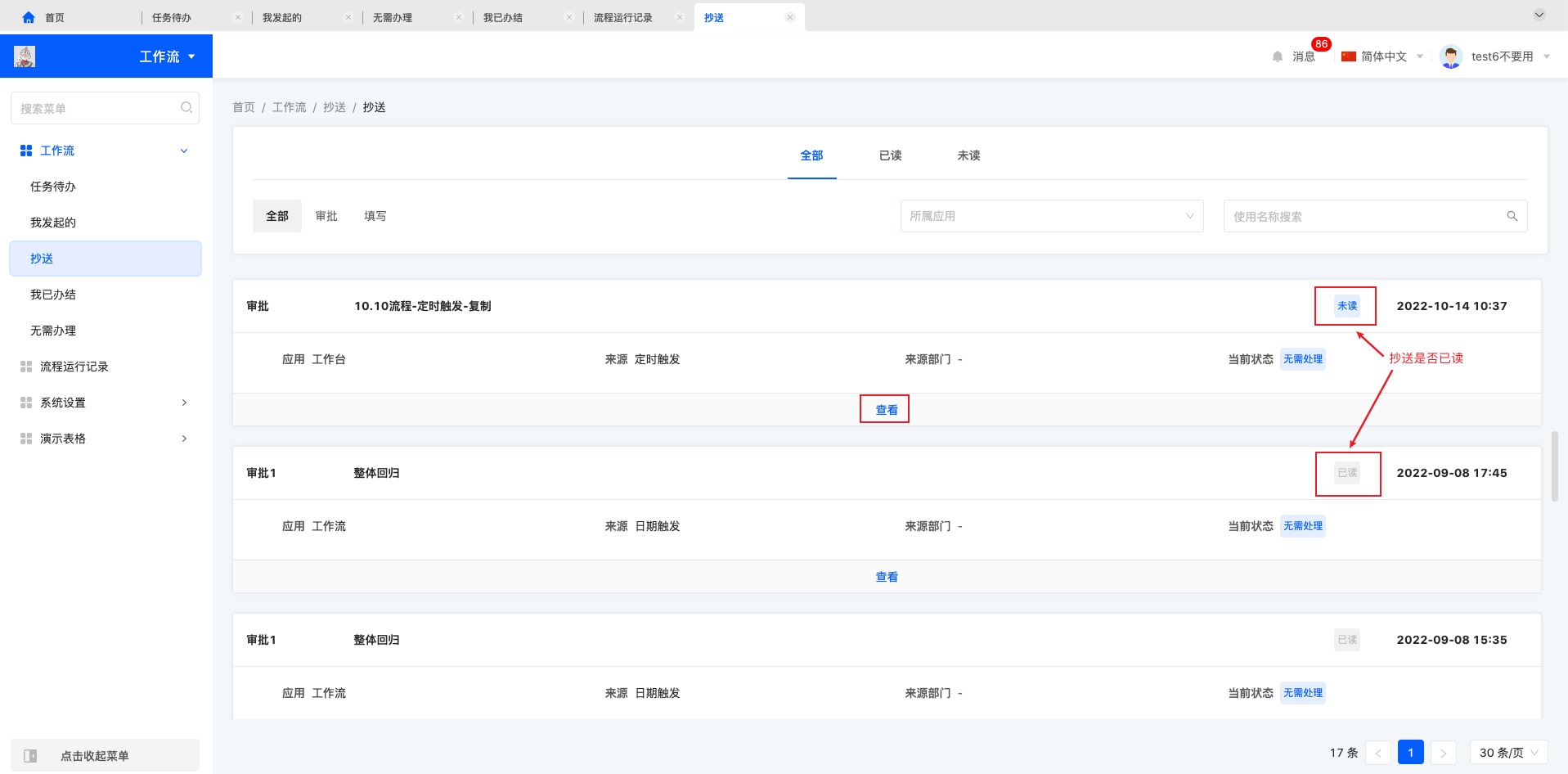
1.2.3 抄送
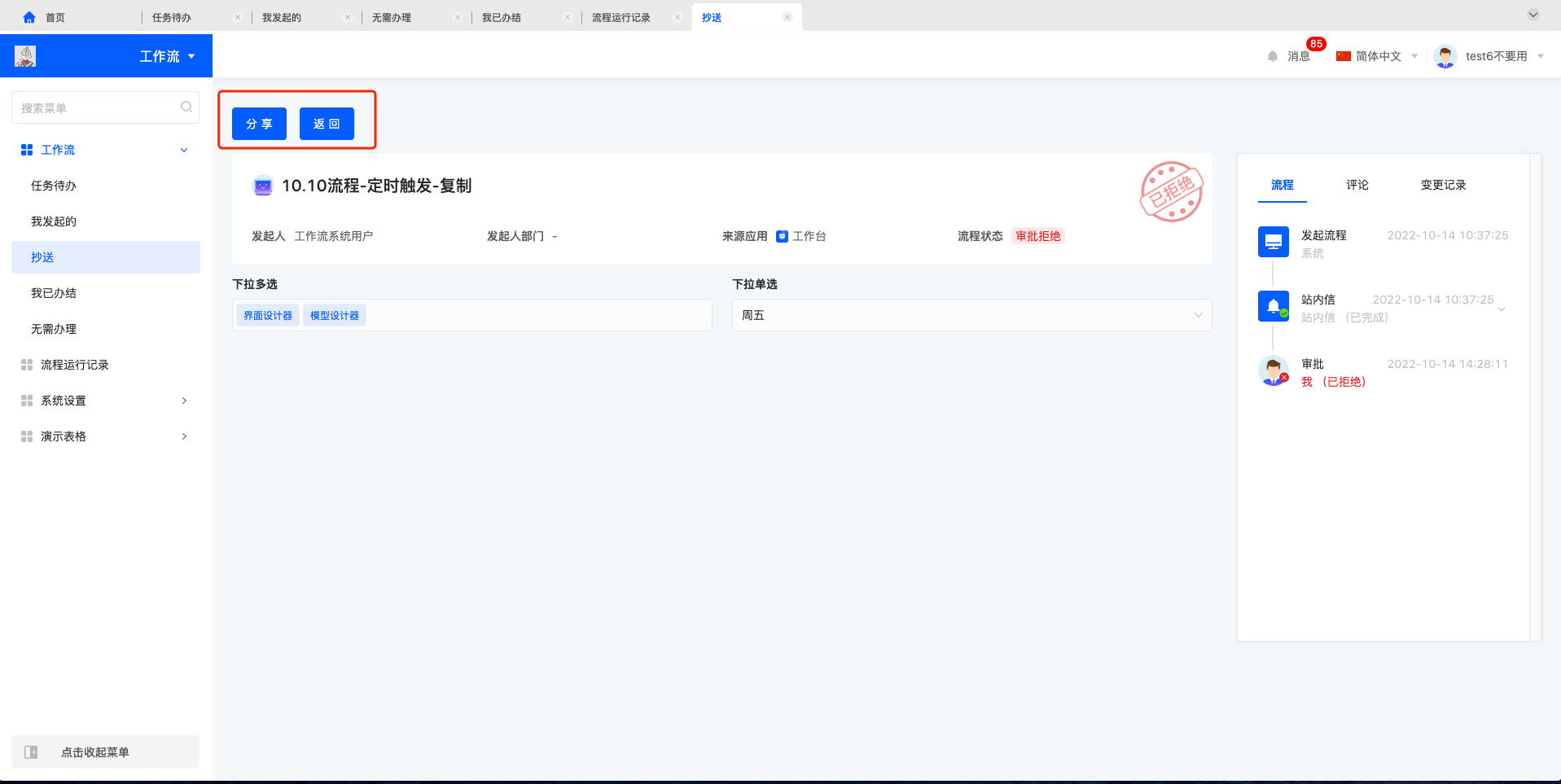
抄送列表中每条抄送只可以进行查看操作,查看进入流程的详情页面,有分享和返回的操作。
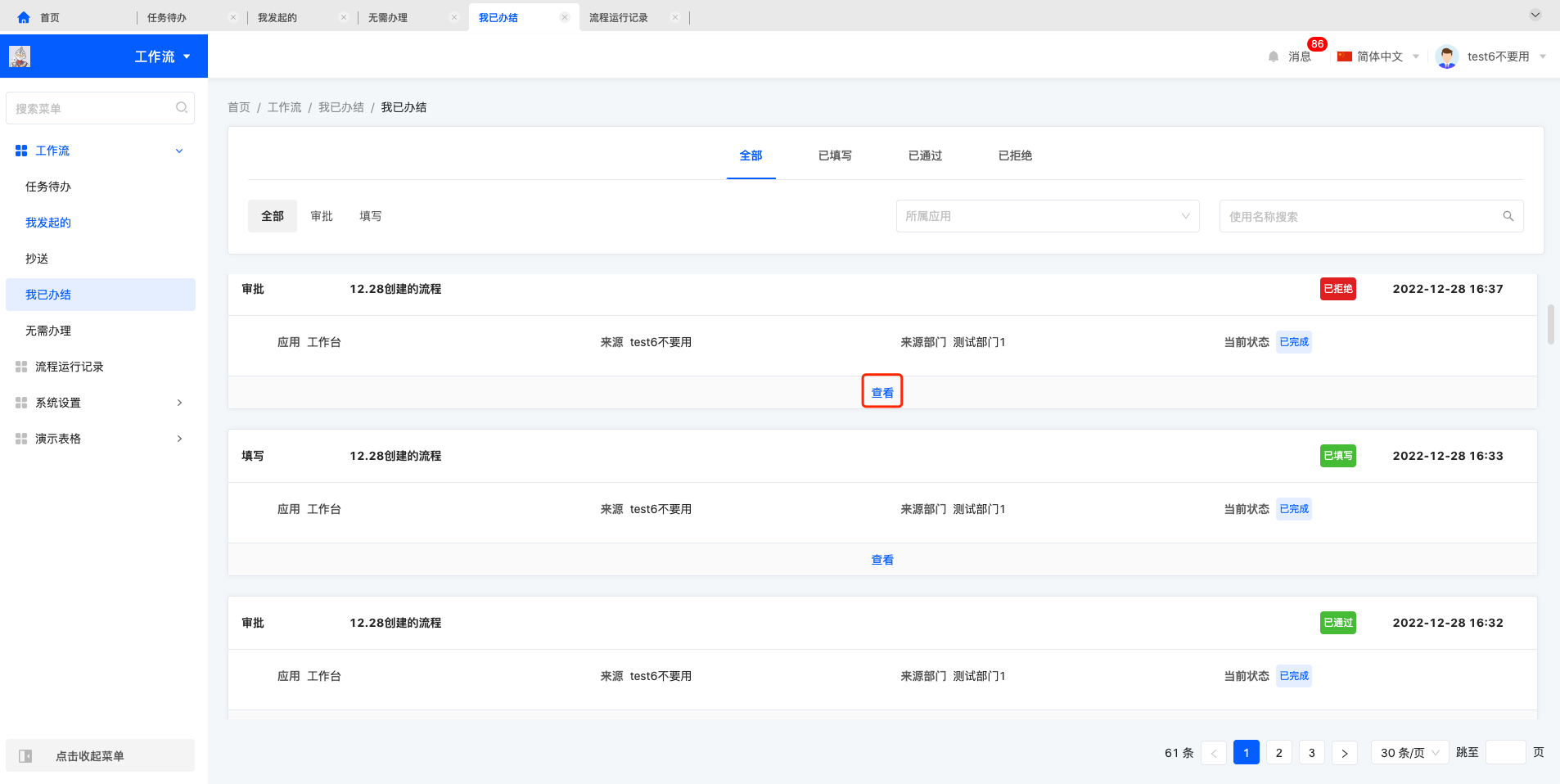
1.2.4 我已办结
我已办结列表中可以进行查看操作,查看进入代办的详情页面,可以进行分享和返回的操作。
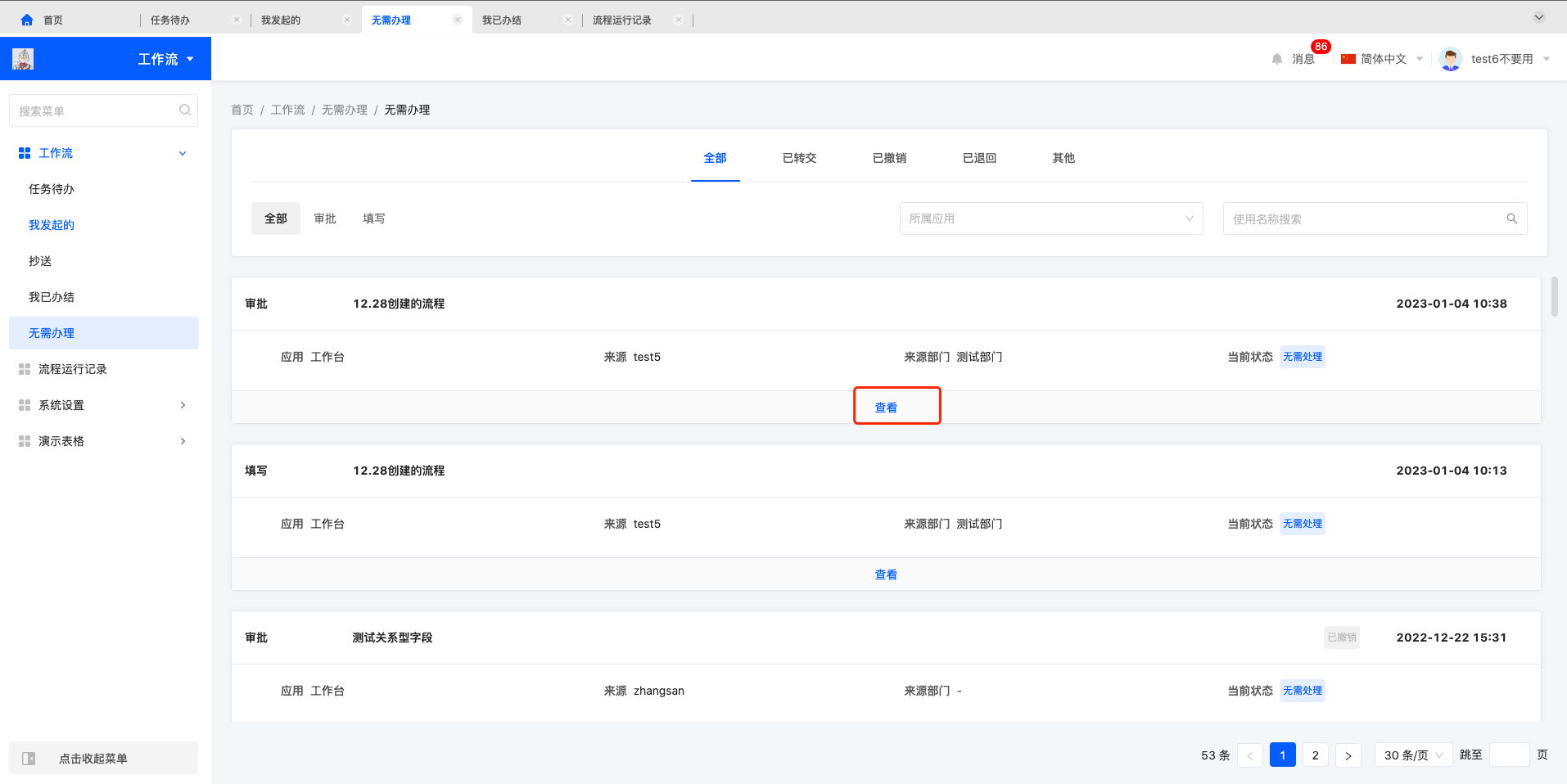
1.2.5 无需办理
无需办理列表中可以进行查看操作,查看进入代办的详情页面,可以进行分享和返回的操作。
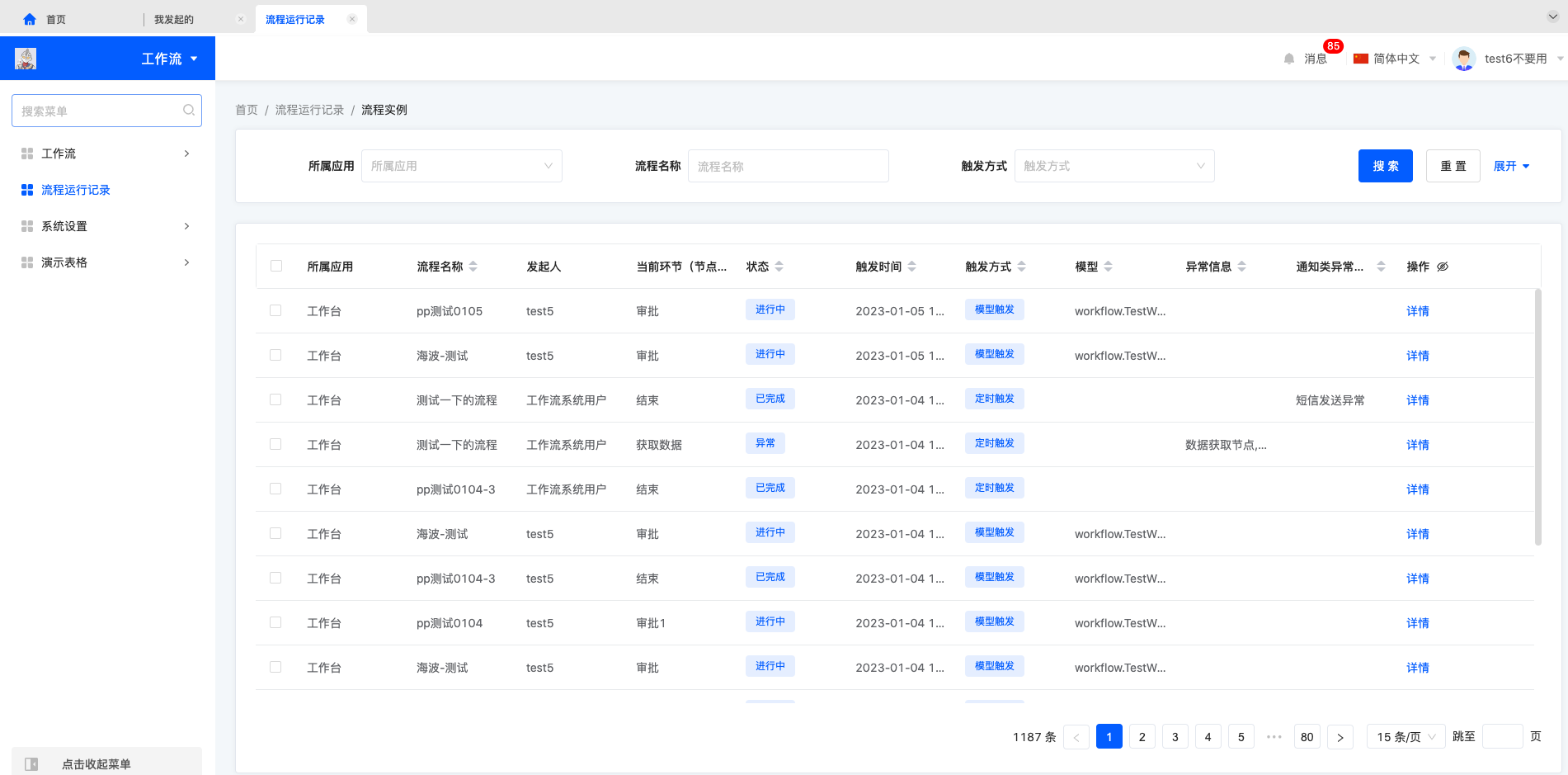
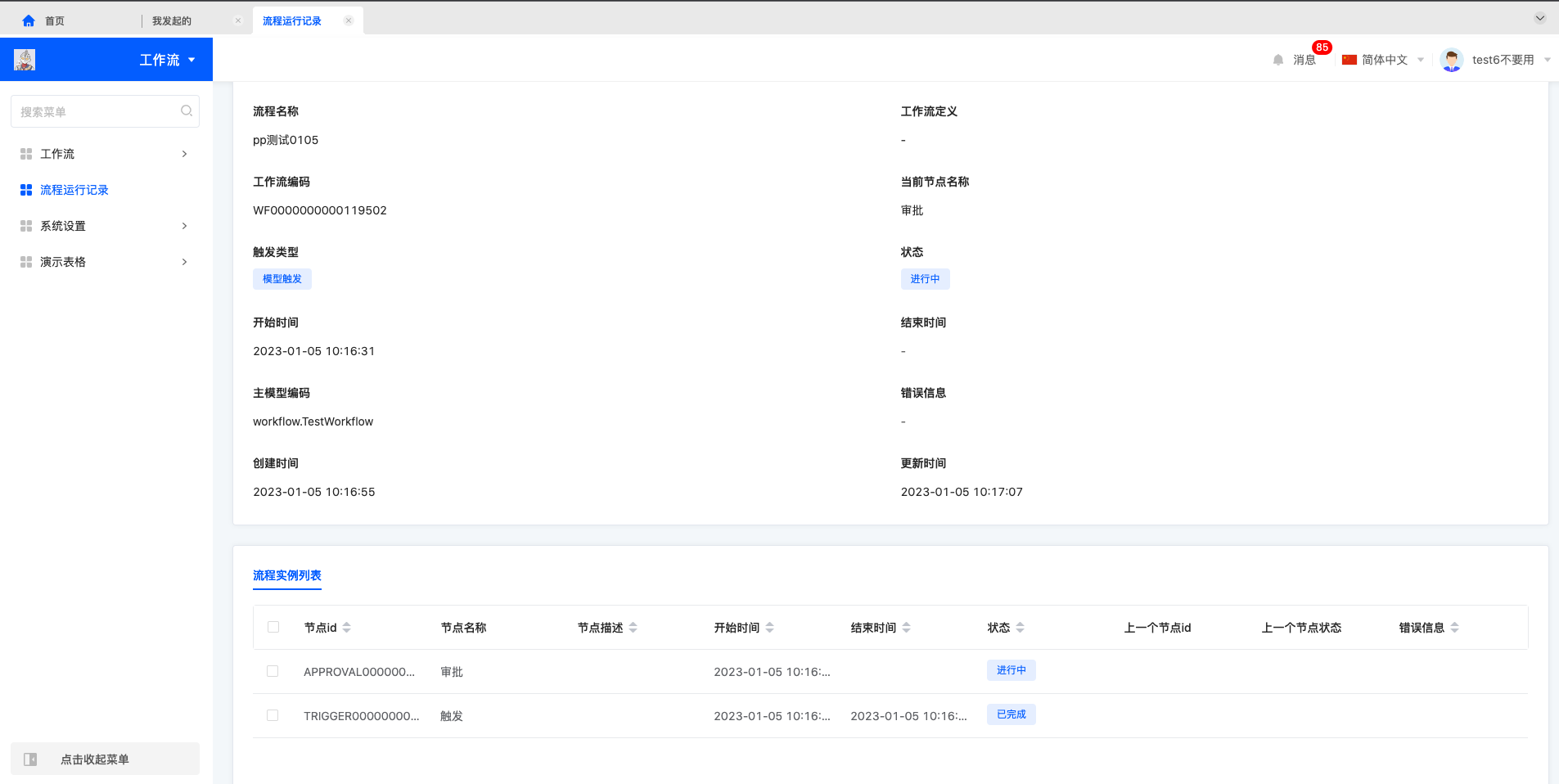
2. 流程运行记录查看
所有运行流程都会记录在流程运行记录中,可以根据流程的所属应用,流程名称,触发方式和状态进行搜索,流程运行记录详情中展示流程运行的具体节点,运行时间,当前运行节点,异常信息等。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9388.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验