
设计器转为非专业研发设计,在Oinone3.0版本中已经完成元数据完整在线化,真正做到低无一体。对于设计器的定位我们开篇就介绍过,它是LCDP的产品化呈现,是冰山露在外面大家看得到的,核心还是在LCDP本身。我们先目睹下设计器的一些产品页面,如您有想体验,可以在Oinone官网注册
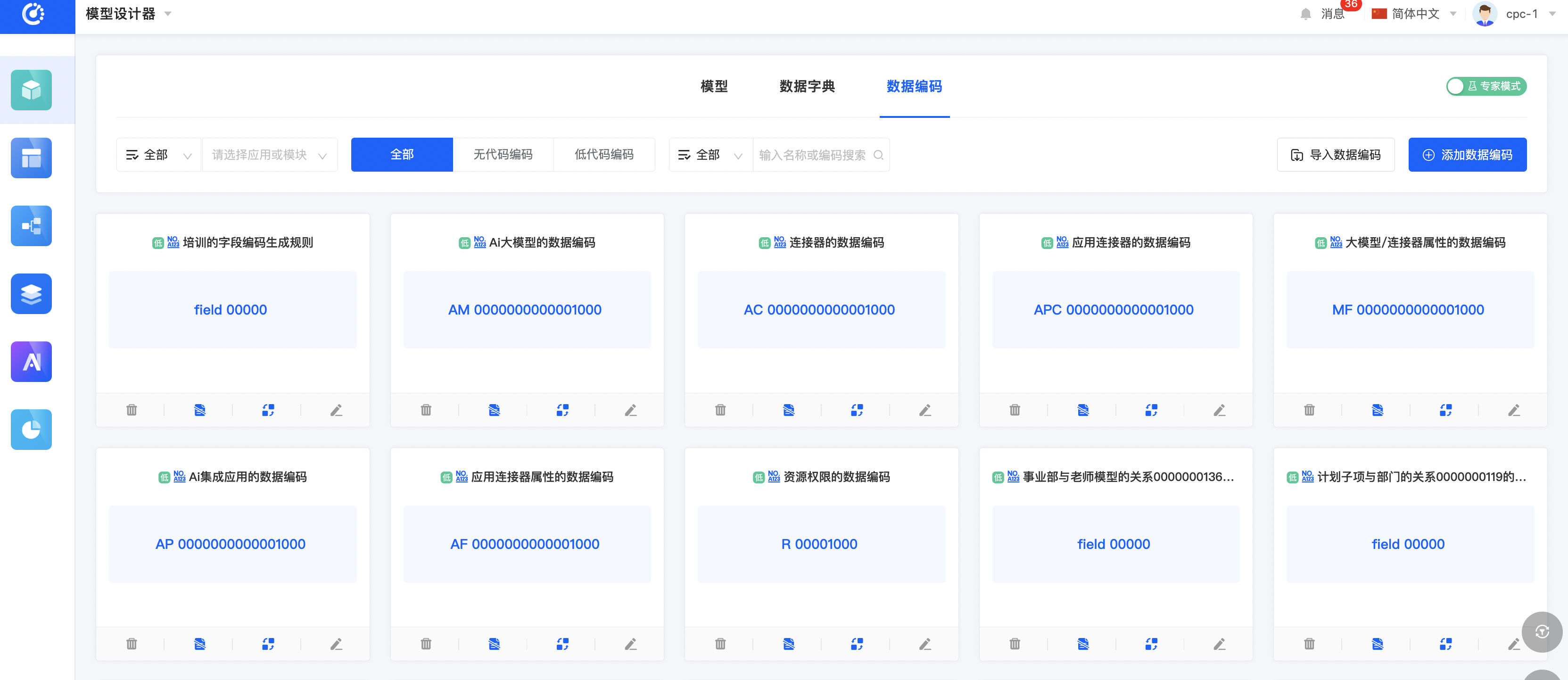
模型设计器
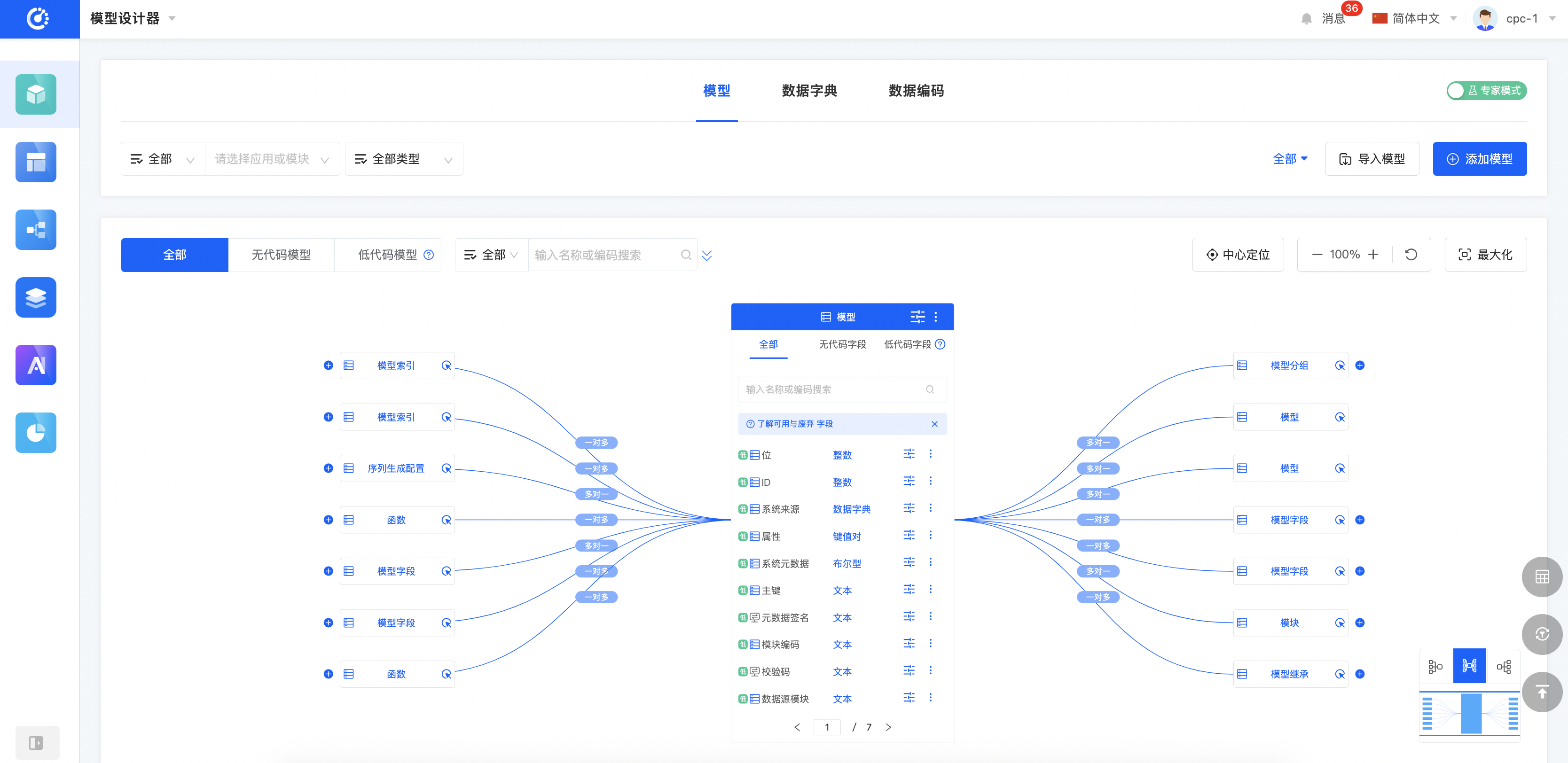
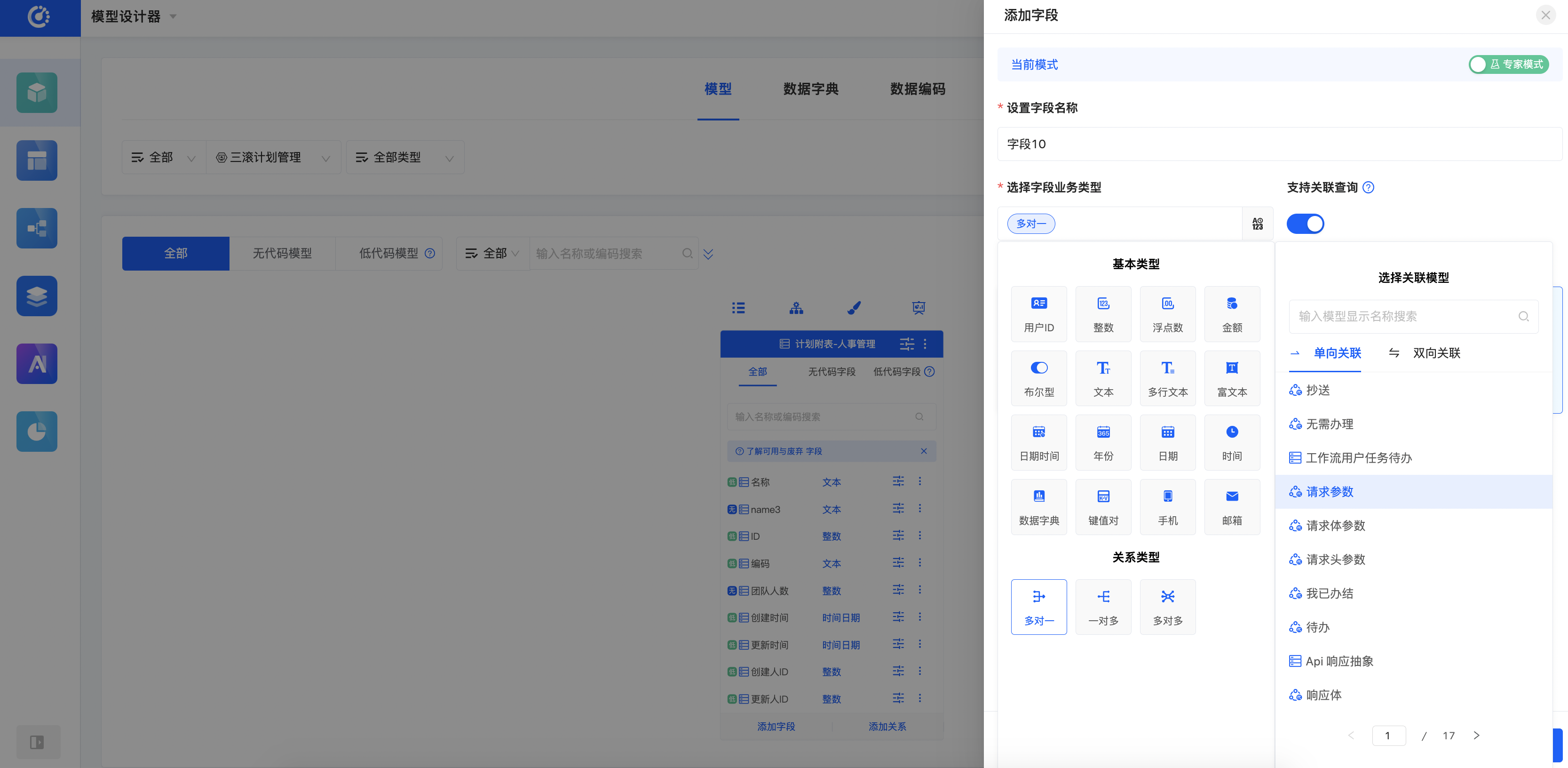
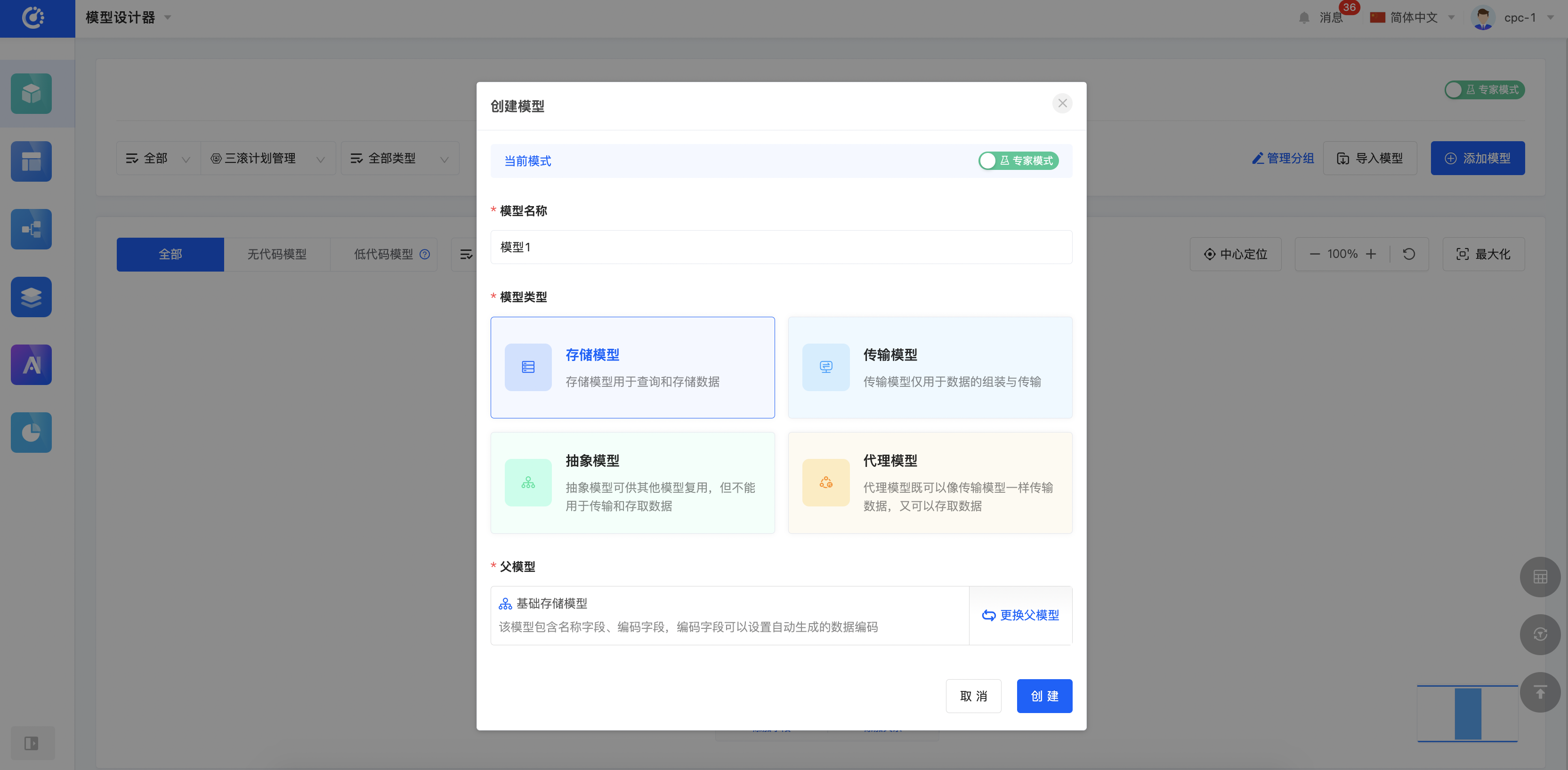
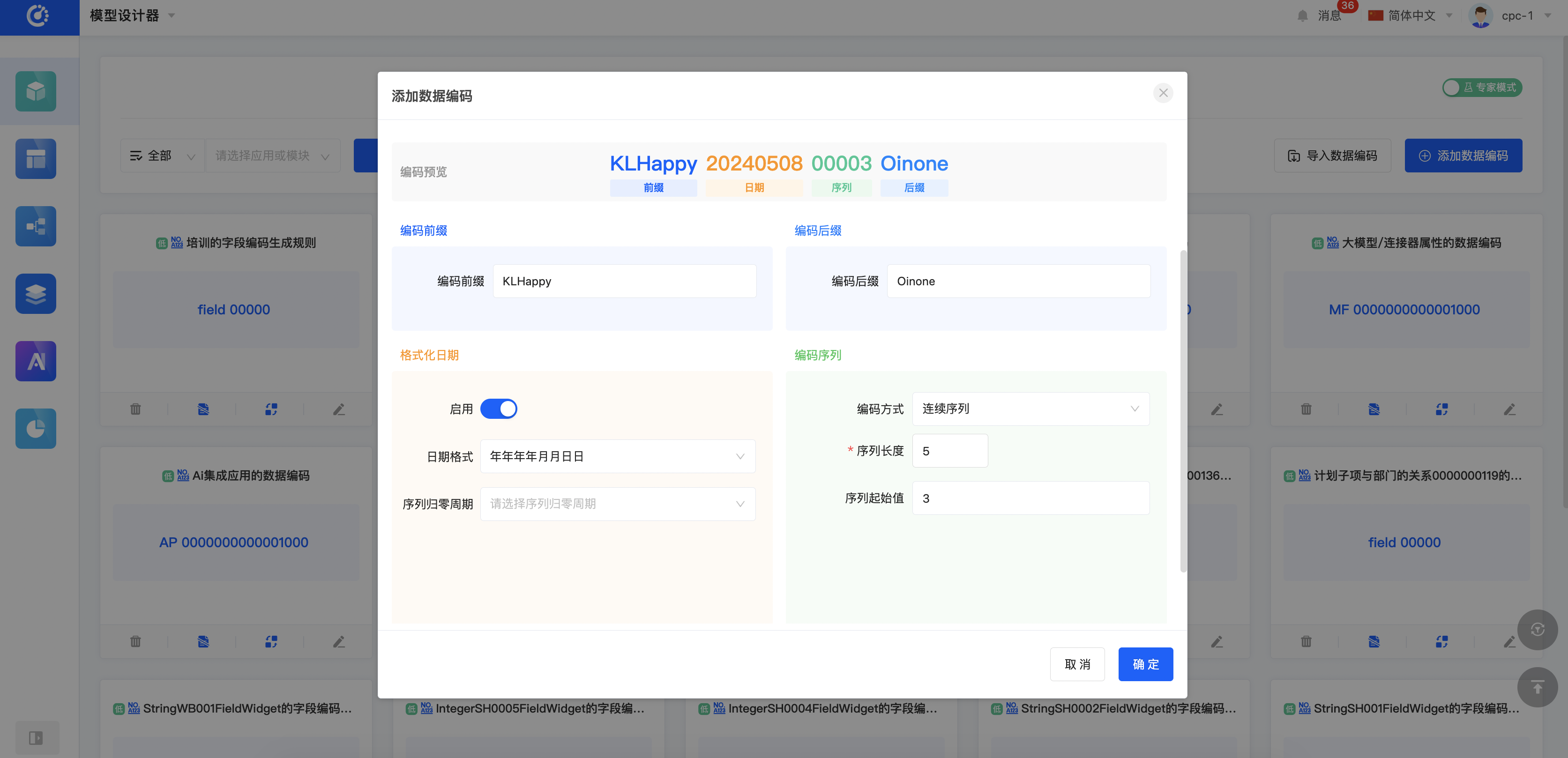
Oinone以模型为驱动,当有模型、数据字典、数据编码等设计功能,我们就可以完整地定义产品数据模型,模型设计器整体呈现区别于普通ER图,以当前模型为核心视角展开,可以点击关联模型切换主视角。这样的好处在于突出当前设计,聚焦设计本身。同时模型上预留了几个核心入口如:分类管理、继承拓扑图、页面设计、逻辑设计等。另外我们在体验上区分了专家模式和经典模式,顾名思义,专家模式的功能会更加丰富,对专业知识的要求也会更高。专家模式下一般会增加一些跟业务无关的配置如:索引设置等调优行为

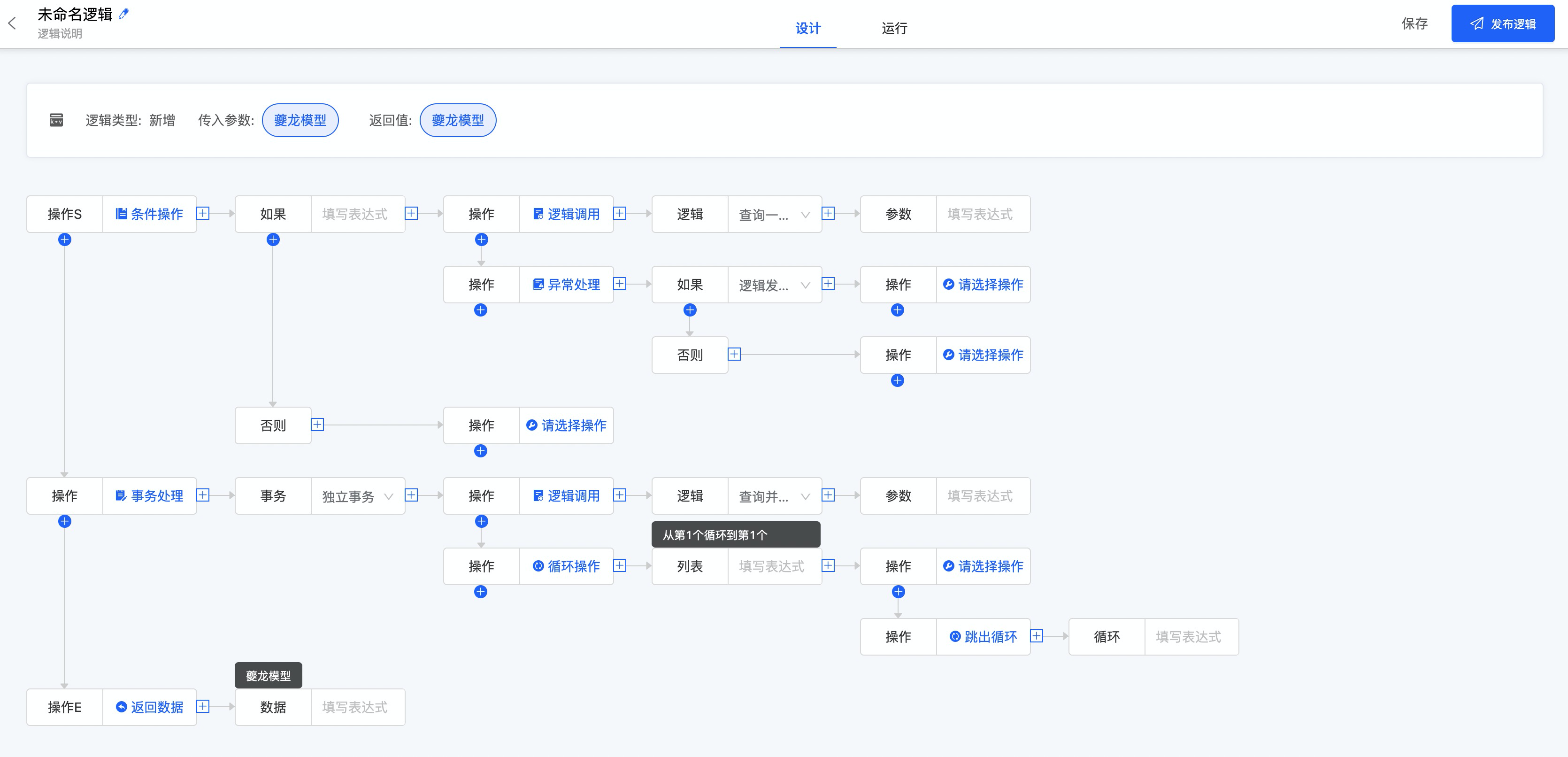
逻辑设计器
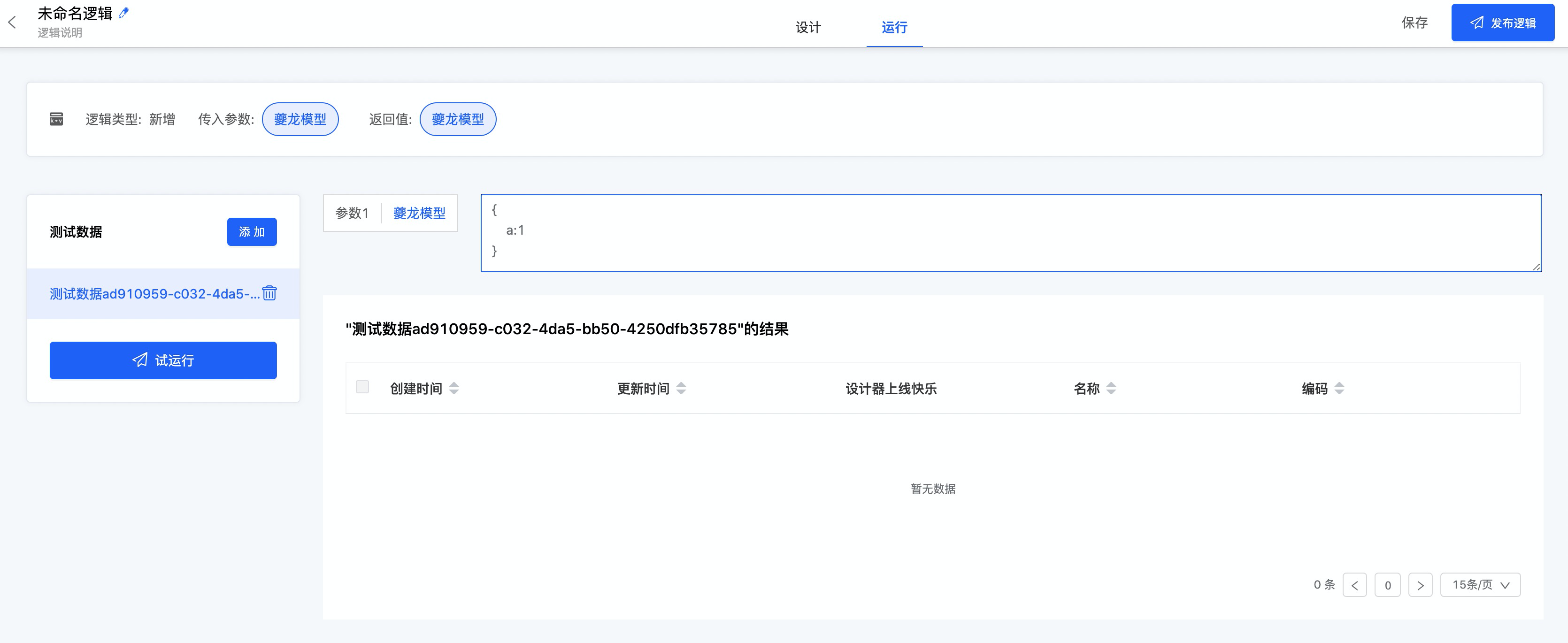
从图灵完备的角度上说,要支持功能越完备,使用越复杂。我们优先从图灵完备的角度出发,所以我们第一版逻辑设计器相对比较复杂,第二版本规划中会类似模型设计器推出专家版和经典版。
界面设计器
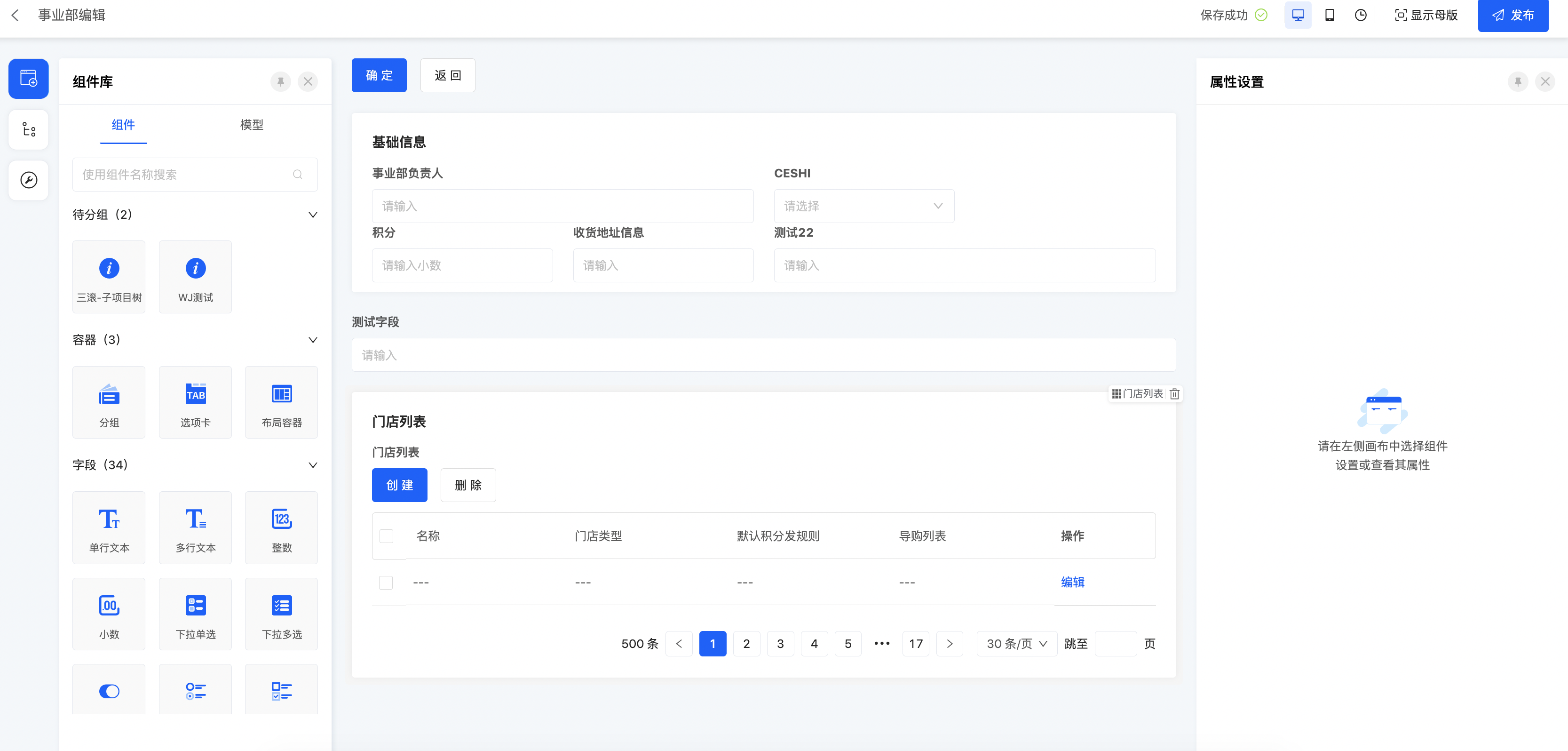
界面设计器第一版会先支撑后端页面在线自定义,后边将陆续推出前端页面、多端能力。为了支持多端和2C页面的设计,我们对前后端协议做了比较大的改造。目前设计器已经支持完全基于V3的前后端协议。
数据可视化
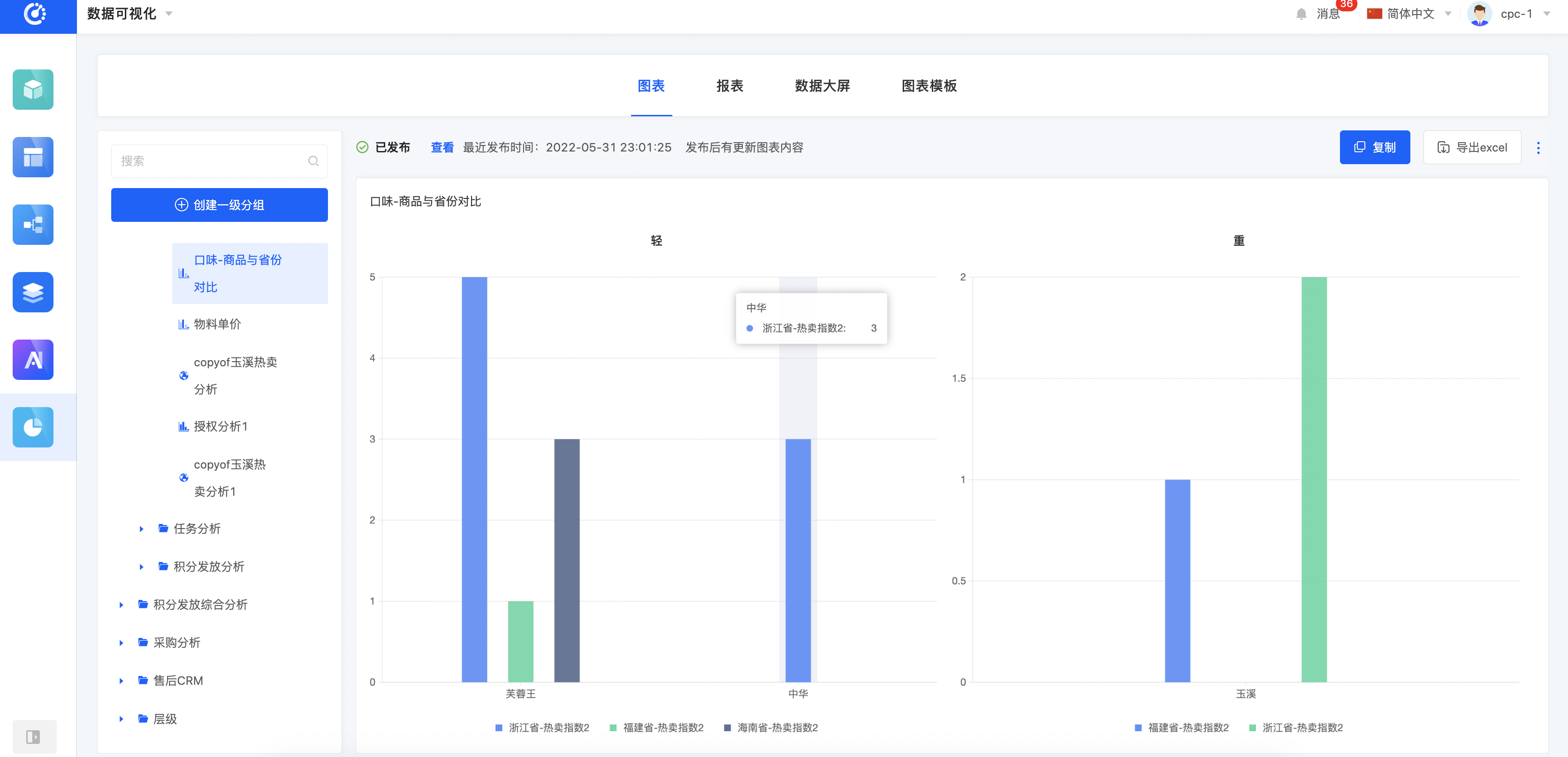
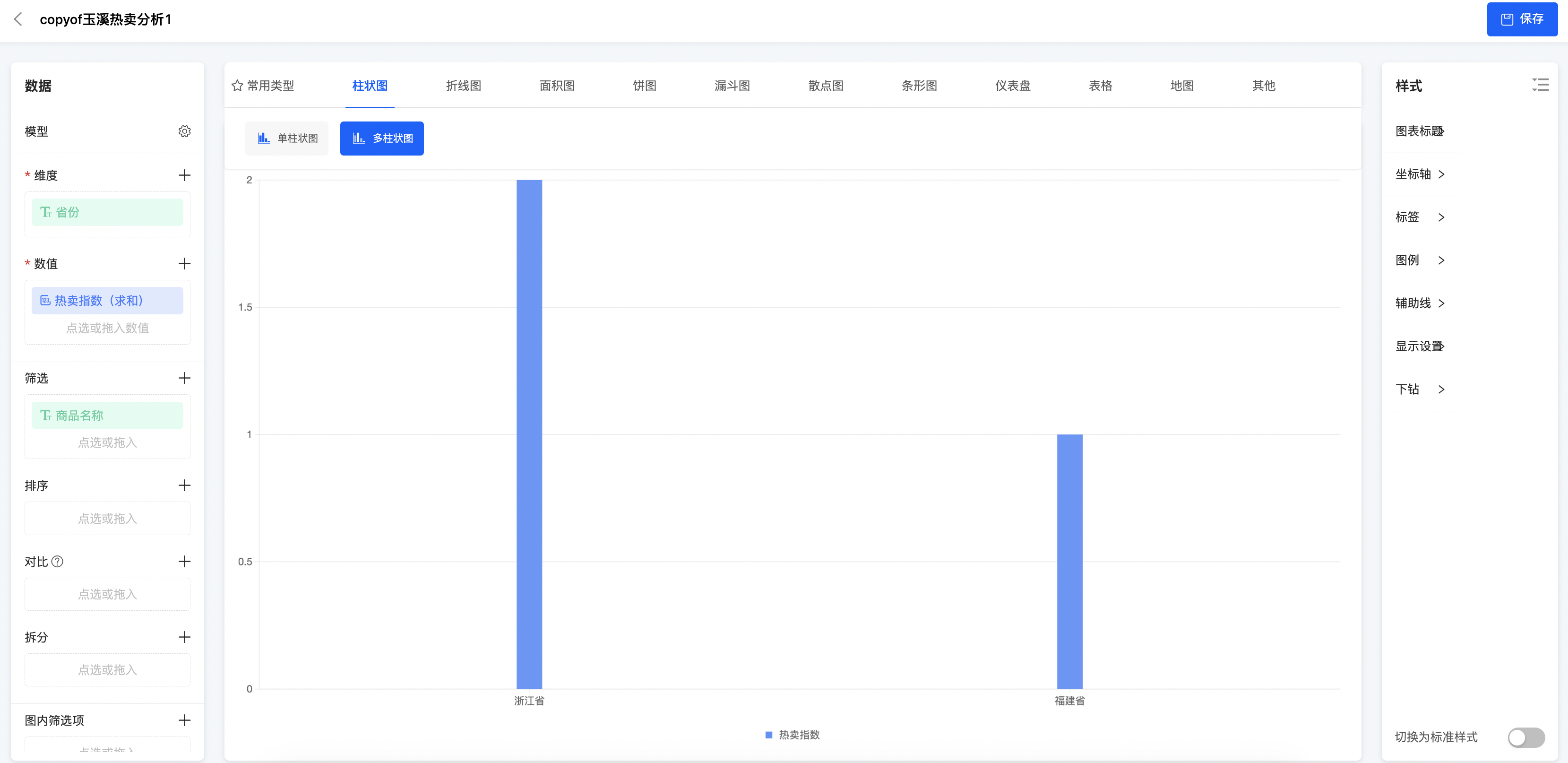
数据可视化支持从内部系统模型获取数据内容后,根据业务需求自定义图表,目的是为企业提供更高效的数据分析工具。
与市场同类产品相比,我们的数据可视化产品:不需要前置维护数据源、进行数据转换;可智取业务系统模型,系统自动解析选择的模型、接口、表格中的字段后进行数据分析;降低对数据分析人员研发能力要求的同时,也提升了数据分析的效率。
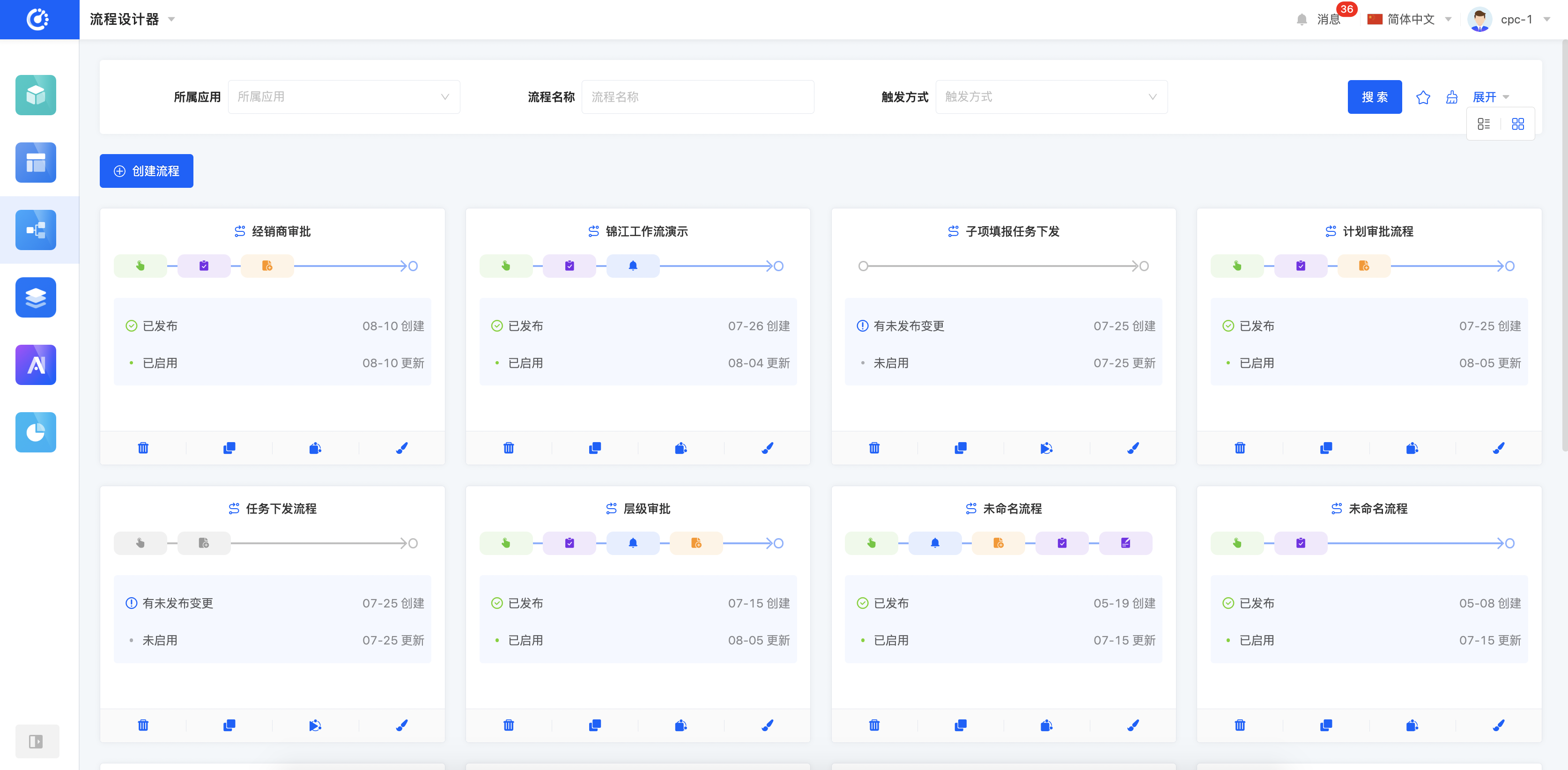
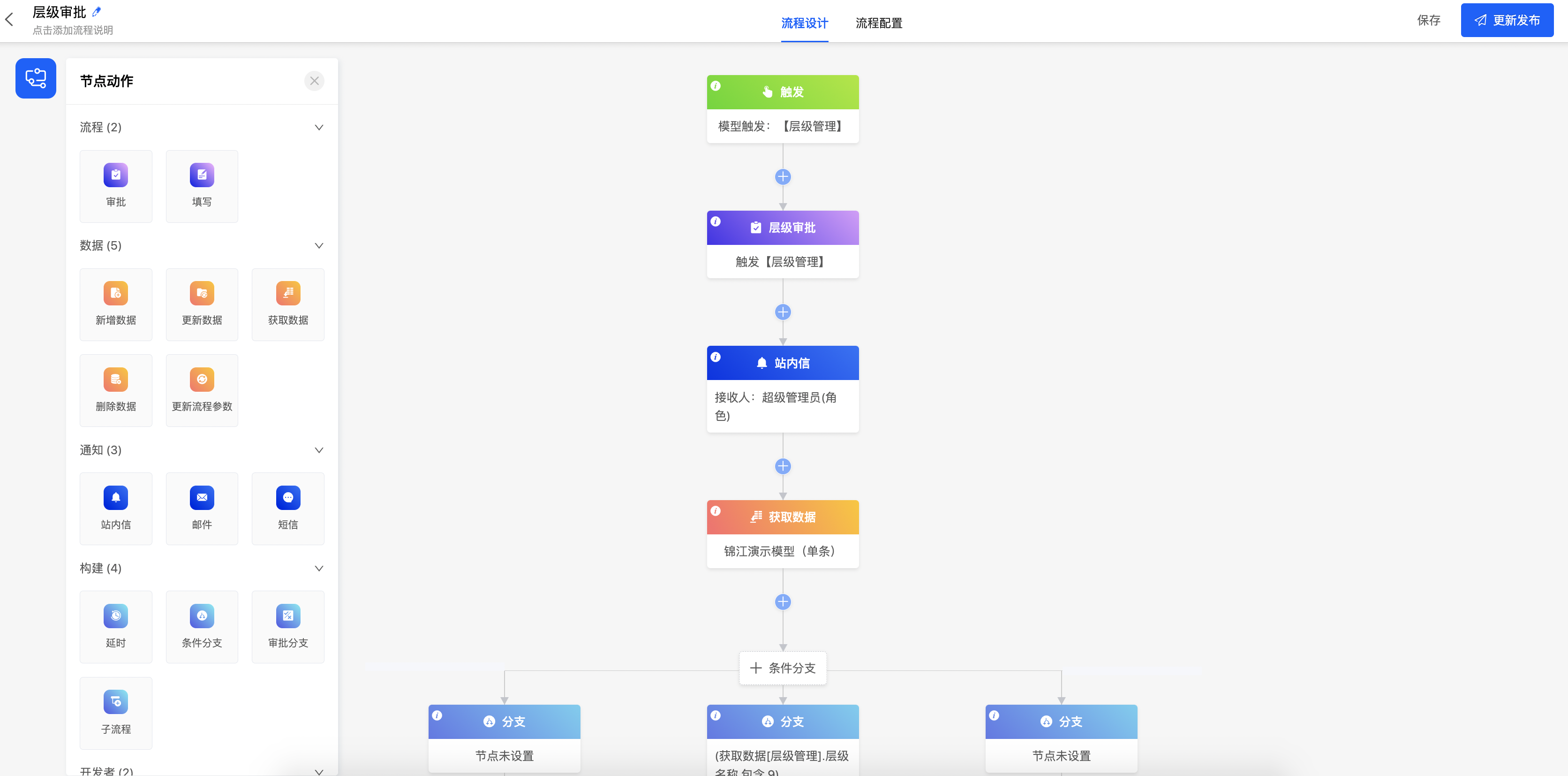
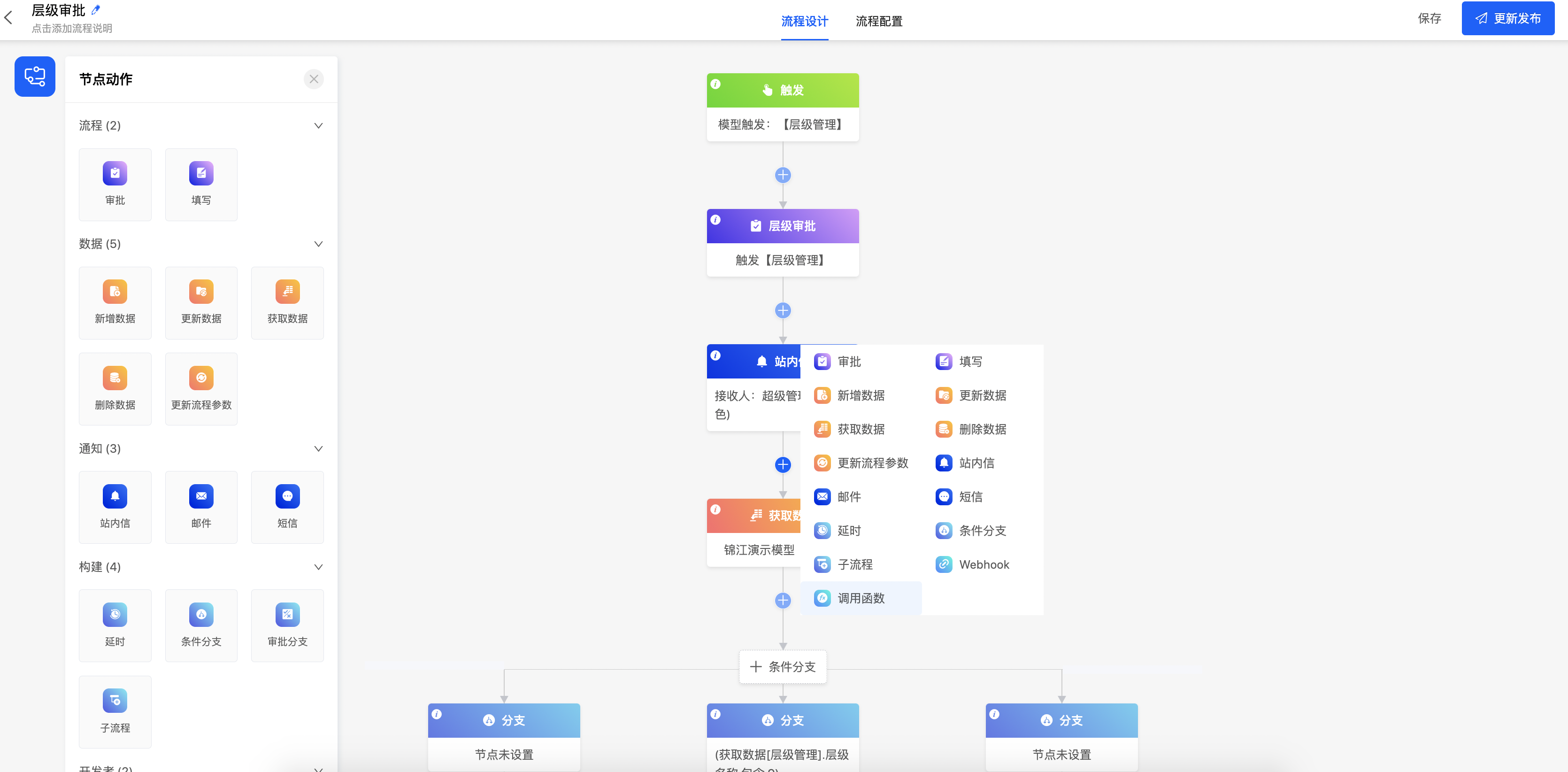
流程设计器
Oinone流程设计器为业务流程和审批流程提供了可自动执行的流程模型:通过定义流转过程中的各个动作、规则,以此实现流程自动化。在Oinone流程设计器中,流程可以跨应用设计,不同应用的模型之间可以通过同一流程执行。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9333.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验