
1.构件类
1.1 延时
当下一个节点动作需要一段时间之后再发生时,可以使用延时节点。延时节点包含两种延时方式:1、延至指定日期,2、延时一段时间。
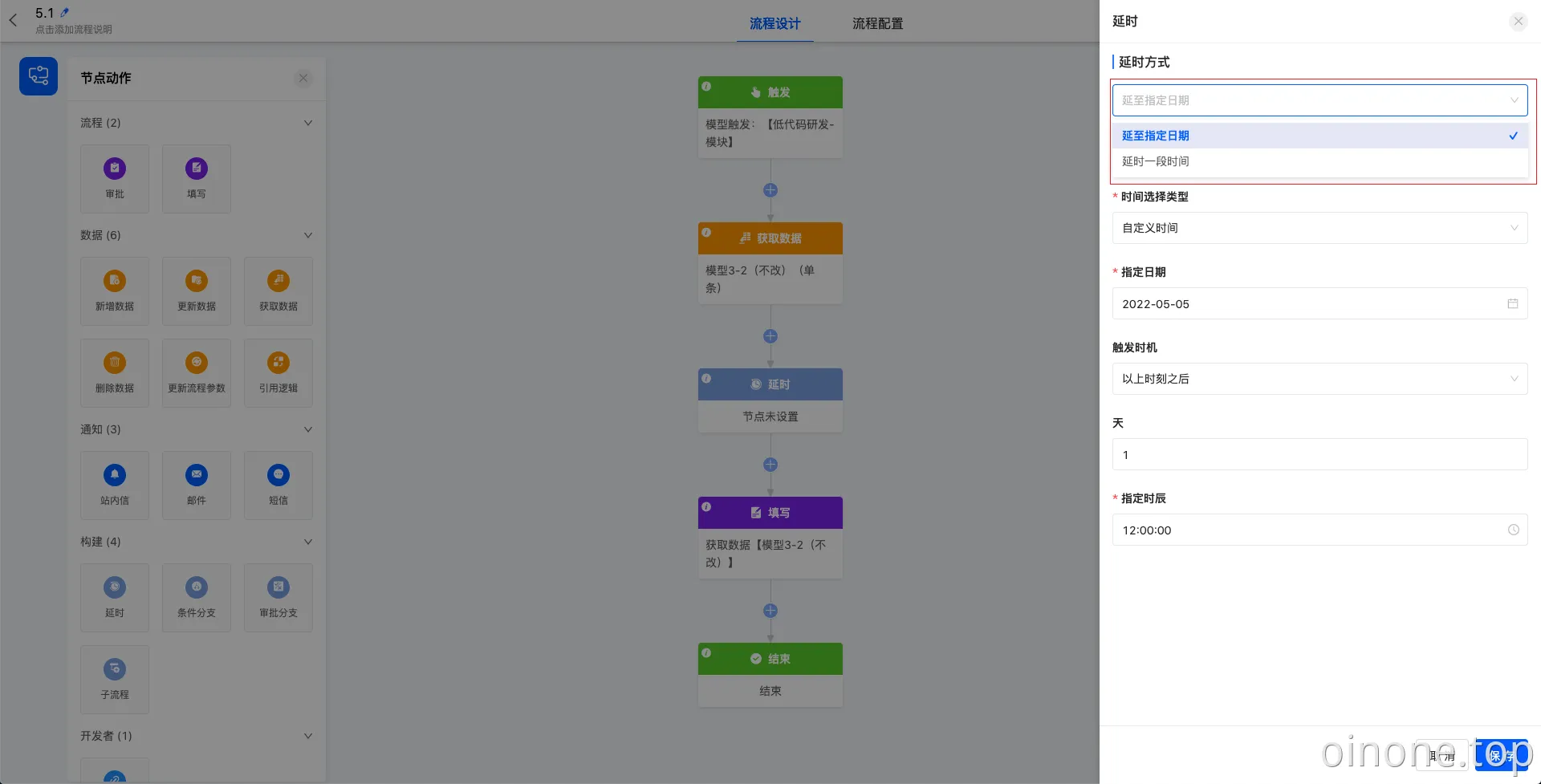

选择延至指定日期时,可以选择延至模型字段的时间或自定义时间,如果模型字段只包含日期则必填指定时辰。如果选择自定义则需要分别指定日期和时辰。
选择延时一段时间时,至少需要填“天、小时、分钟”中的一项。
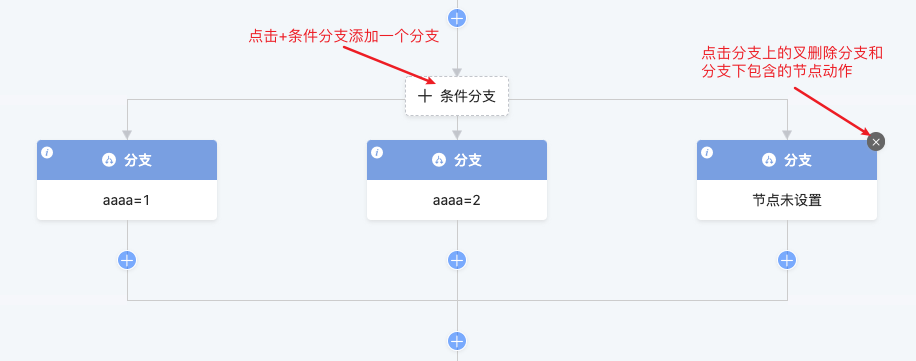
1.2 条件分支
使不同条件的数据执行不同的分支流程。需要设置分支条件、添加满足条件的动作、也可以增删条件分支。
必须将分支条件填写完整流程才能正常进行。当只有两个分支时点击删除任一分支会删除整个条件分支。
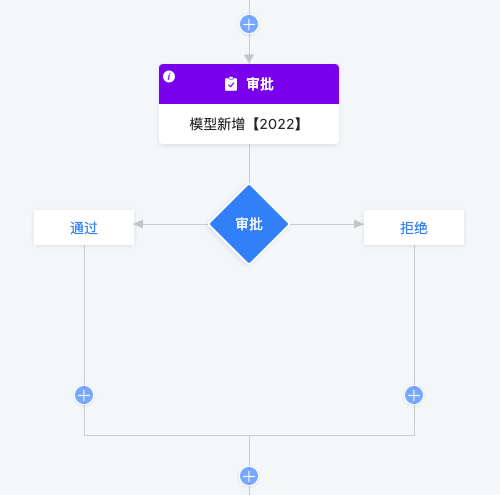
1.3 审批分支
审批分支是一种特殊的条件分支。审批分支只能添加在审批节点下方。因为审批只存在通过和拒绝两种条件,所以无法添加其他条件,并且点击任意条件的叉都会删除整个条件分支。同时若审批节点被删除,审批分支也会同时删除。
1.4 子流程
一些高度重复的流程节点可以创建成子流程,在主流程中引用子流程,减少流程的重复配置。选择子流程时只能选择当前流程中有用到的模型下并且在启用状态的子流程,也可以在创建子流程节点处设置新增子流程。子流程的执行方式有两种:子流程可以和后续节点同时执行,也可以设置子流程执行完后再执行后续节点。
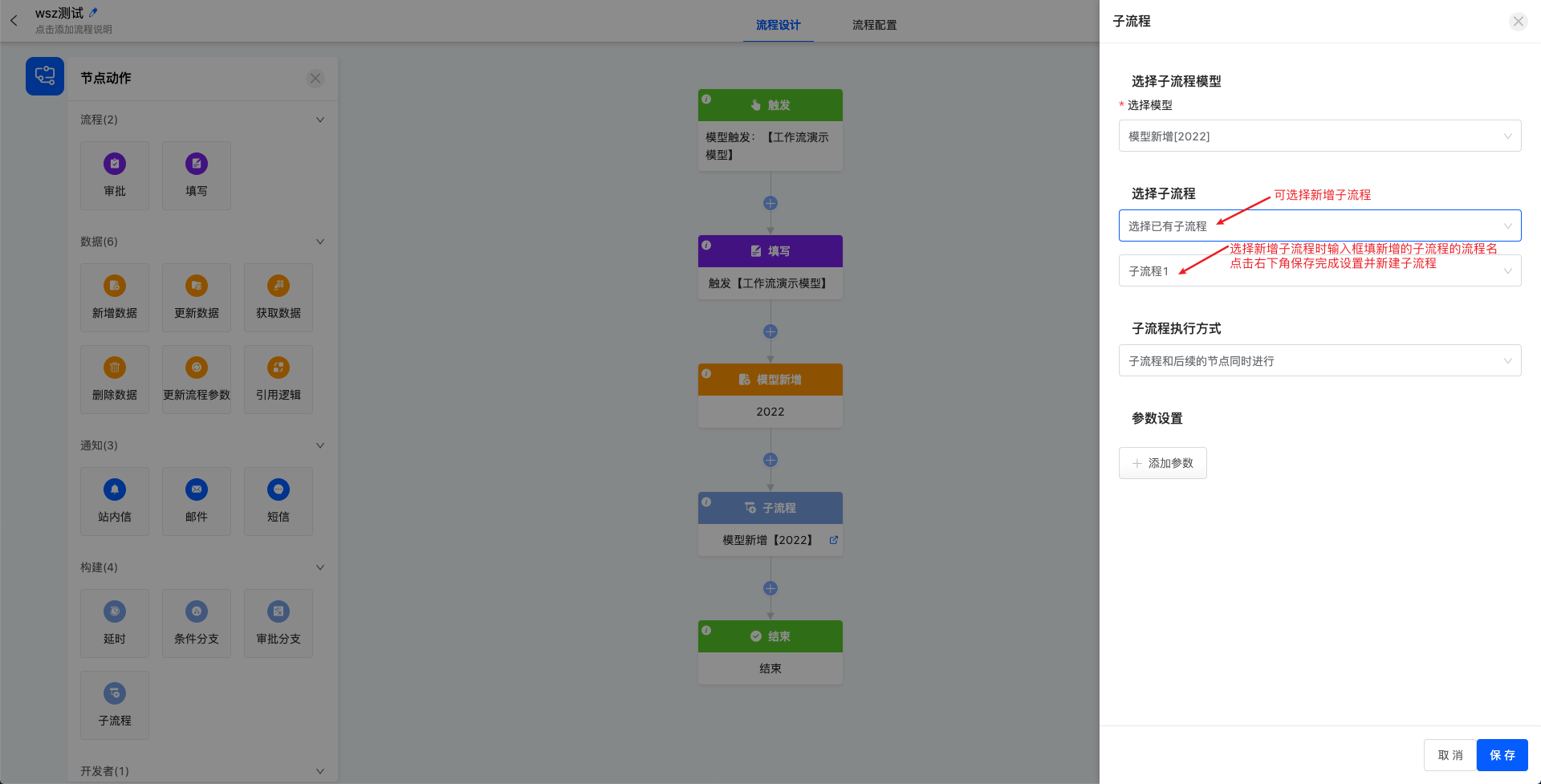
子流程与普通正常流程不同,不包含触发方式,普通流程流转到子流程节点即为子流程的触发条件,添加完节点动作之后发布即可。在不新增数据的情况下,子流程中只能使用该子流程对应模型的字段数据。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9418.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验