
字段是什么
字段的基本概念
-
定义:字段通常指的是数据的一个单独项,它可以是一个文本框、下拉菜单、复选框等,用于在用户界面上收集或展示数据。
-
用途:在表单中,字段用于收集用户输入;在表格或列表中,字段用于显示数据。
-
类型:字段可以有不同的类型,如文本、数字、日期等,这些类型通常由数据模型定义。
Oinone框架中的字段
在Oinone框架中,字段的设计和实现遵循以下原则:
-
后端模型驱动:前端的字段直接由后端的数据模型决定。这意味着后端定义了哪些数据应该展示,以及如何展示。
-
减少前后端联调:由于字段的定义和行为是由后端控制的,前后端的联调需求大大减少。前端开发者主要关注于如何呈现这些字段,而后端则负责数据的逻辑和结构。
-
灵活性与规范性:虽然Oinone推荐所有场景都遵循后端模型驱动字段的原则,以保持前后端的一致性和减少沟通成本,但它也为高度定制化的前端页面提供了灵活性。
-
元数据使用:Oinone可能还使用元数据来进一步定义字段的行为,例如它们是否可见、如何验证用户输入等。
结合前后端
在使用Oinone时,理解前后端如何合作来定义和展示字段是很重要的。这种方法不仅提高了开发效率,而且有助于确保数据的一致性和应用程序的可维护性。同时,对于那些需要特定定制或特殊处理的场景,开发团队能够灵活地适应这些需求,在遵守总体架构原则的同时进行一些特定的调整和优化。
作用场景
在Oinone框架中,字段扮演着连接后端数据模型和前端用户界面的重要角色。其作用场景包括但不限于以下几点:
-
业务组件的核心: Oinone集成了AntdDesignVue的全部UI组件,将它们转化为业务组件。这些业务组件以字段的形式存在,使得前端开发变得简单高效。开发人员可以直接使用这些现成的业务组件来构建用户界面,大大减少了开发工作量。
-
无代码开发支持: 字段的设计使得Oinone支持无代码开发。开发者可以通过拖拉拽的方式在前端快速构建界面,而后端模型的定义直接决定了这些界面的生成。这种模式简化了传统的前端开发流程,提升了开发效率。
-
个性化定制: 虽然标准的UI组件可以满足大部分需求,但复杂多变的业务场景往往需要更多个性化的处理。在Oinone中,开发者可以根据具体业务需求和公司的UI指南,定义专门针对特定行业或客户的定制化字段和组件。
-
与无代码平台的结合: Oinone允许将个性化的字段和组件与无代码平台相结合。这意味着即使在进行个性化定制时,也能保持使用无代码工具的便利性,实现更灵活、更高效的前端开发。
-
适应多维度业务需求: 由于字段在Oinone中的灵活性和可定制性,它们能够适应多维度的业务需求,无论是从UI设计、用户体验还是业务逻辑的角度,字段都能提供合适的解决方案
自定义字段
示例工程目录
以下是需关注的工程目录示例,main.ts更新导入./field:
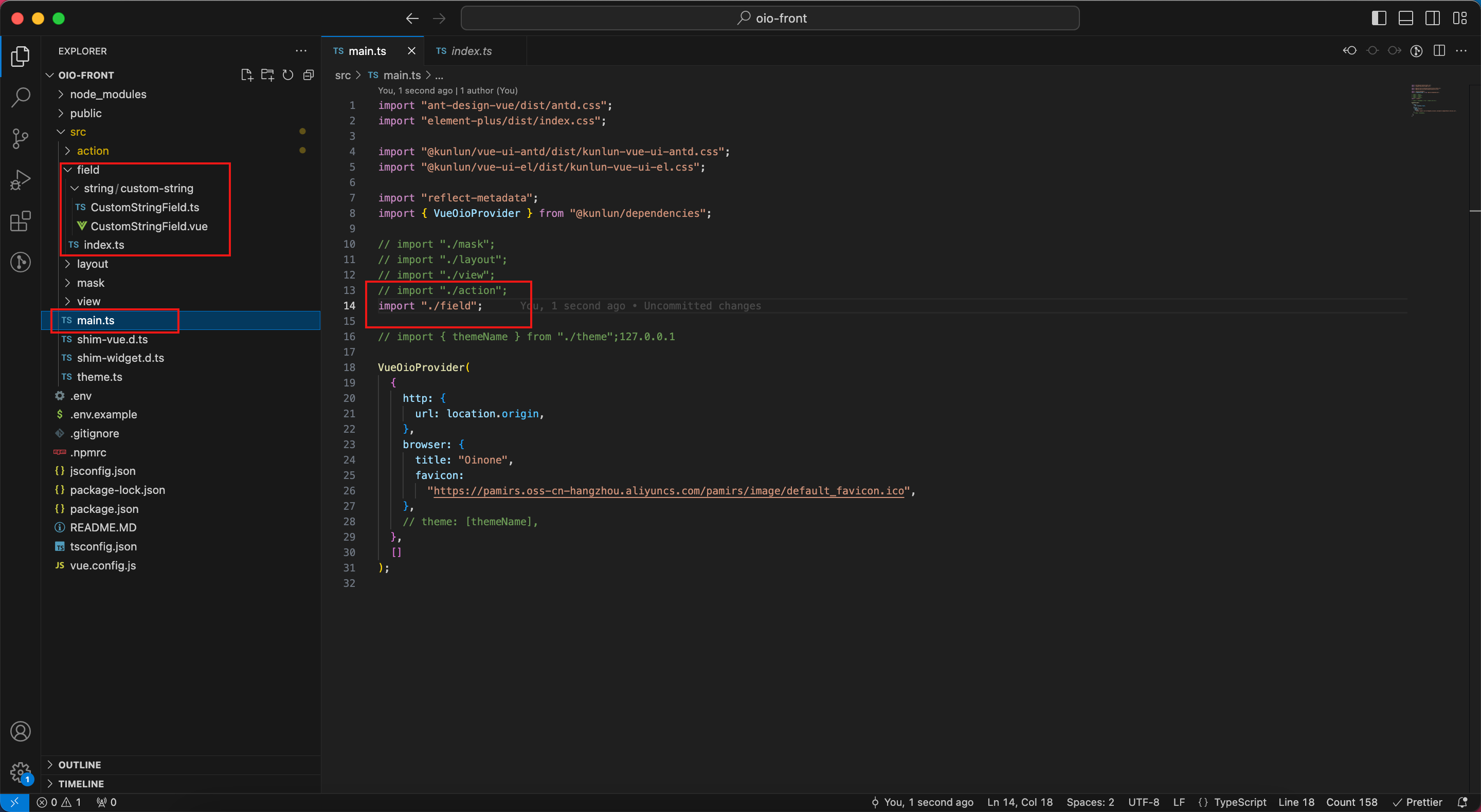

示例代码
-
创建自定义字段组件:
- 使用Vue框架创建一个新的组件(例如 CustomStringFieldVue),并定义其模板、脚本和样式。
- 在模板中定义字段的HTML结构。
- 在脚本中使用 defineComponent 来定义Vue组件。
-
字段类的定义:
- 导入必要的模块,如 FormFieldWidget, ModelFieldType, SPI, ViewType 等。
- 使用 @SPI.ClassFactory 装饰器来注册自定义字段。
- 在类内部初始化并设置组件。
-
SPI注册参数解释:
- viewType: 指定视图类型,如表单视图或搜索视图。
- widget: 可以指定组件名称。
- ttype: 字段的业务类型,例如字符串、数字等。
- multi: 指明字段是否支持多值。
- model: 定义字段所属的模型。
- viewName: 指定视图名称。
- name: 定义所属字段的名称。
import {FormFieldWidget, ModelFieldType, SPI, ViewType} from '@kunlun/dependencies';
import CustomStringFieldVue from './CustomStringField.vue';
@SPI.ClassFactory(
FormFieldWidget.Token({ viewType: [ViewType.Form, ViewType.Search], ttype: ModelFieldType.String })
)
export class CustomStringField extends FormFieldWidget {
public initialize(props) {
super.initialize(props);
this.setComponent(CustomStringFieldVue);
return this;
}
}图3-5-7-24 自定义字段组件(TS)示例
<template>
<div class="custom-string-filed-wrapper">
字段组件
</div>
</template>
<script lang="ts">
import { defineComponent } from 'vue'
export default defineComponent({
inheritAttrs: false,
name: 'CustomStringFieldVue'
})
</script>
<style lang="scss">
.custom-string-filed-wrapper {
}
</style>效果
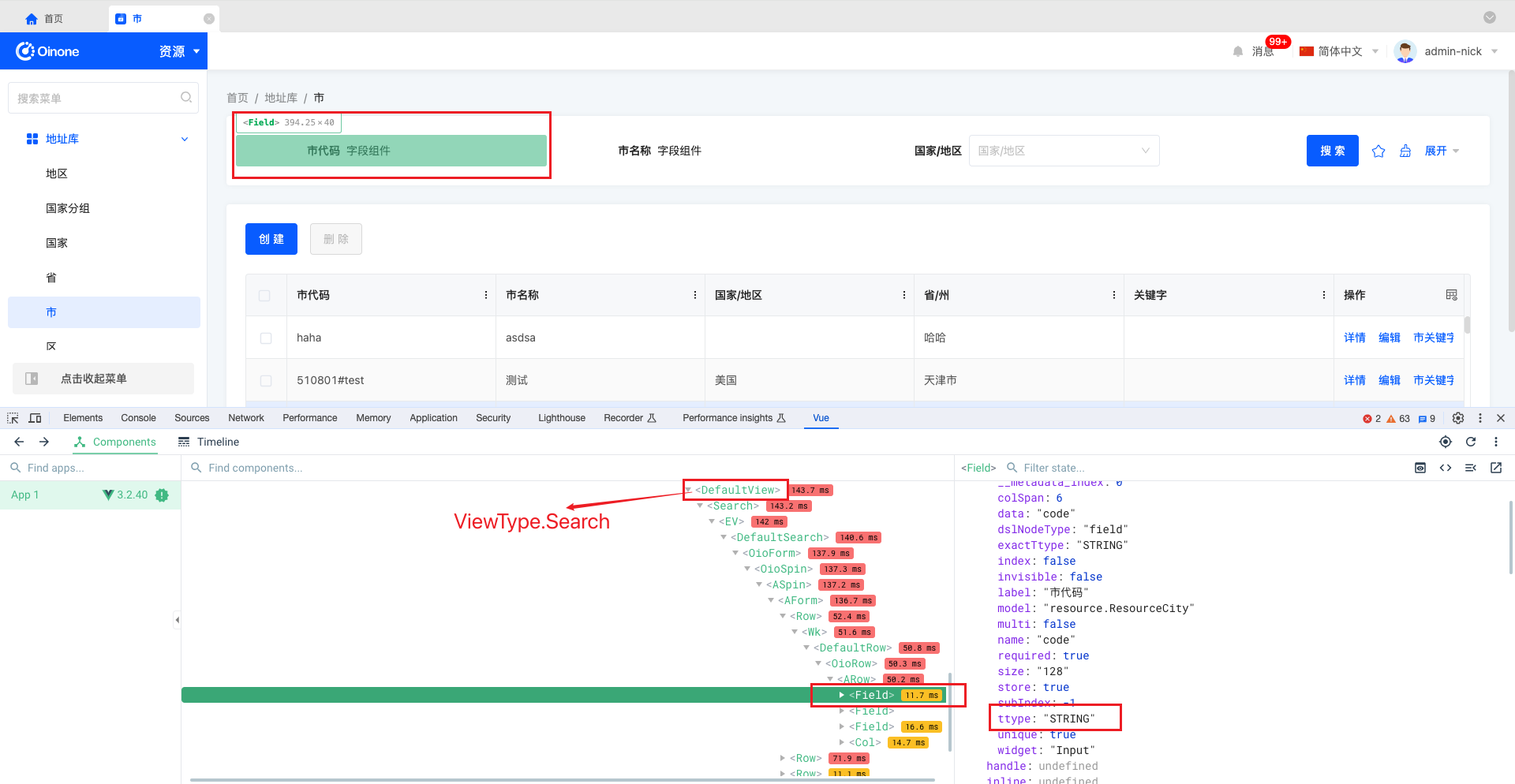
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9269.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验