
在信息化时代,中国并没有涌现出一家世界知名的软件公司。这是因为像SAP、Oracle、IBM、Salesforce、NetSuite、Odoo等西方巨头所拥有的最佳实践在业务、技术和模式方面,给予了它们在企业信息化建设中高额利润的优势。中国软件业在这个时代的角色是学习和追随者,而最优秀的追随者是金蝶和用友,它们能在国家推行会计电算化的机遇中占据领先地位。但是,追随者始终只是追随者,没有真正的突破。
我自己进入软件行业的经历可以追溯到2015年。当时资本市场非常热门,大家都在创业。我认为这是一个时代的机会,就像国家改革开放一样。于是,我和很多同事一起开始了创业之旅。在数式之前,我加入并创办了三家公司:500mi、数列和端点。整个过程给了我宝贵的经验和启示,帮助我找到了最终想要的方向。
在500mi公司时,我从技术岗位转型为业务经营,起步并不顺利。然而,我从这份经历中获得了一堂重要的课:做自己擅长的事情,有助于渡过创业启动期最艰难的阶段。同时,市场调研为我提供了一个信号:传统企业对于IT的需求正逐渐向互联网靠拢。这个信号像注入了一剂强心剂,激励我继续前行。
2016年,我和三个曾在阿里工作的同事一起创办了一家新公司——数列,我们决定专注于我们最擅长的领域,即软件服务商。在没有任何商务资源的情况下,我们第一年就完成了1000多万的合同,这相较之前是一个非常成功的开端。然而,对于公司未来的发展方向,我们花费了长达大半年的时间进行思考:应该坚持做底层的PaaS还是专注于企业可见的上层应用和业务产品?我倾向于后者。尽管我们持续存在分歧,但凭借着多年的革命友情,最终我们友好地分道扬镳。数列此前的成功让我更加坚信:在数字化时代,软件需求将会有井喷式的增长,数字化软件服务将是未来5-10年的重要方向。而在这个领域,专业的技能将是应对未来不确定性的真正力量。
提到数字化,就不得不提阿里巴巴提出的中台理念。中台理念在15年前被阿里巴巴提出,当时引起了广泛的关注和讨论。企业之所以认同中台理念,是因为他们的核心需求已经从内部转向外部:从关注管理、流程、效率的提升,转向关注外部协同、运营、创新。他们已经不再只担心企业的效率和成本,而是担心自己是否有能力跟上时代的快速变化。现今做生意的渠道已经不再是单一的线下渠道,而是包括淘宝、天猫、京东、拼多多、抖音、快手等多个线上渠道,以及海外市场,这种变化速度非常快。而中台的核心理念是敏捷响应、低成本快速创新,正好解决了企业主的核心焦虑。
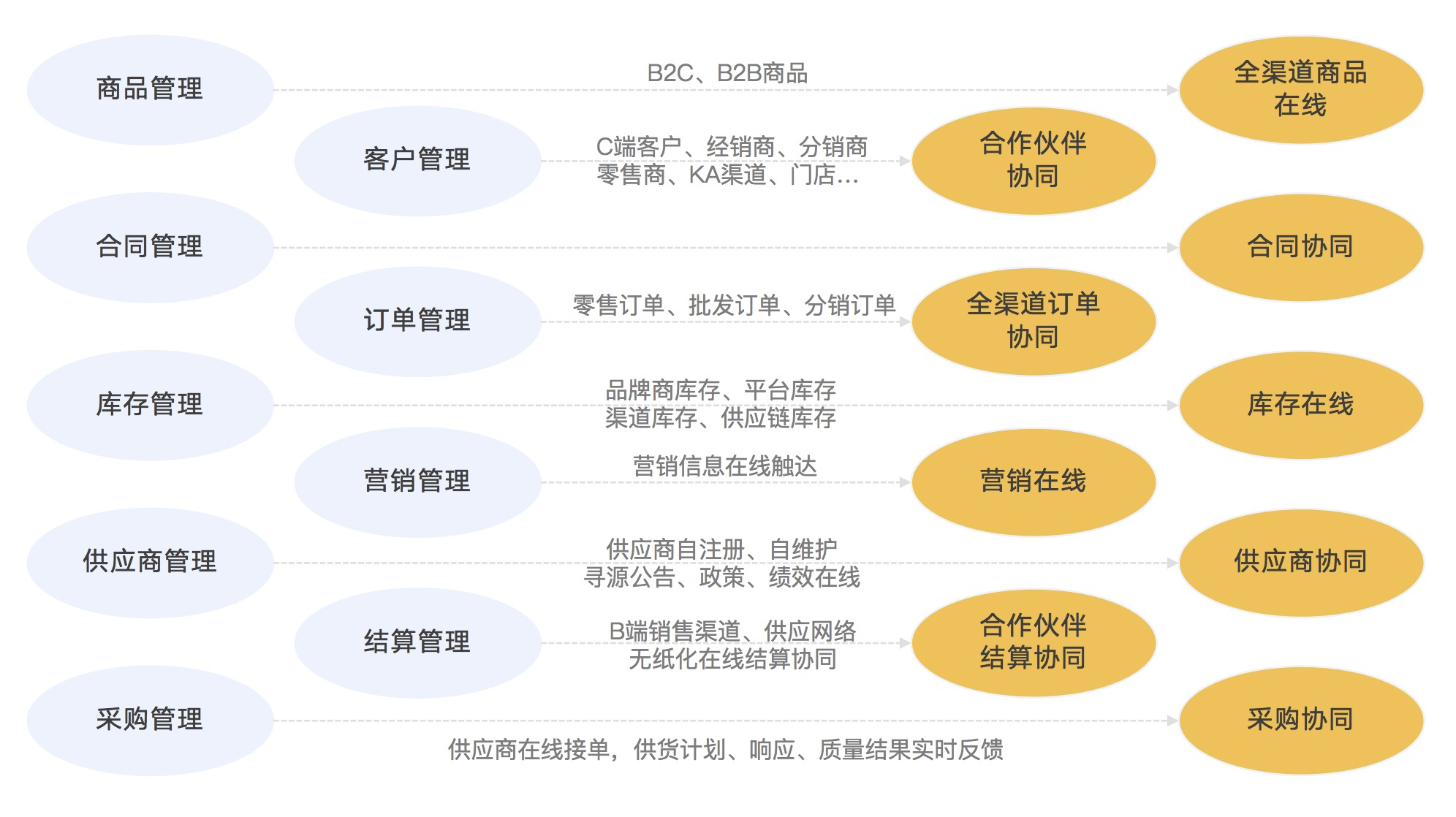
企业的视角正在从内部管理向业务在线和生态在线(协同)转变,这种转变带来了一系列新的需求(如下图1-1所示)。这种转变不仅是为了支持现有业务的发展,也为企业未来的业务发展和创新提供了支持,并将变化实时反映到上下游合作伙伴中。

在2017年下半年,阿里云收购了端点科技,打算重启阿里软件。那个时候,市场上涌现出一批中台厂商,整个行业也比较混乱,很多人对互联网架构本身的理解不够深入,快速学习拿到阿里云认证后就开始做定制化的中台架构开发,但最终的效果无法达到预期。因此,阿里云和端点科技的联姻是为了弥补阿里云没有向外输出上层应用产品能力的缺陷。多年来,软件市场一直被国外厂商掌控,中国一直缺乏一个强大的本土软件公司。阿里收购端点,承载着无数中国人的软件梦想。在这种背景下,我回到了阿里体系,加入了端点科技。后来,我参与了许多中台项目,深刻地认识到搭建中台技术架构和一些基础能力,为上层应用场景落地并不难。但是,当客户接手扩展中台能力和新的上层应用场景时,效果往往不尽如人意,这并不是中台架构理念的问题,而是因为传统企业客户的IT能力大多较弱,这是一个硬伤。许多文章都在讲述中台战略,长篇大论地描述组织中台、技术中台、业务中台、数据中台,我们不去评论这些方法论的对错,从技术角度回到初衷,我们只关注一个问题:技术是为商业服务的,中台如何快速满足企业业务多变的需求?
我们经历了多个行业的中台建设,每次都向客户强调第一阶段是打好基础,因此需要较长的周期,并且每个项目都需要顶级架构师来把控整体项目。如何找到互联网架构与传统软件良好结合点,降低对组织的要求,实现中台架构的标准化输出?这是我回归阿里后致力于解决的问题。然而,随着阿里云对端点战略发展思路的变化,阿里不再提供SaaS服务,而只愿意做平台被其他企业集成。因此,我离开了端点,并决定把自己的技术思考转化为现实,于是数式科技诞生了。
在数字化时代,无论是业务、技术还是商业模式的最佳实践,都源自中国。中国已经从追随者转变为互联网领域的全面引领者。我们有理由相信,中国一定会崛起一家世界级的软件公司,而Oinone将始终以此为愿景。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9210.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验