
本节核心是带大家直观的感受下我们上节构建的demo模块,并搭建前端环境为后续学习打下基础
一、使用vue-cli构建工程
##demo-front是项目名,可以替换成自己的
vue create --preset http://ss.gitlab.pamirs.top/:qilian/pamirs-archetype-front4 --clone demo-front --registry http://nexus.shushi.pro/repository/kunlun/如果启动报错,清除node_modules后重新npm i
mac清除命令:npm run cleanOs
windows清除命令: npm run clean
若安装失败,检查本地node、npm、vue对应的版本


或者下载前端工程本地运行[oinone-front.zip](oinone-front)(575 KB)
二、启动前端工程
找到README.MD文件,根据文件一步一步操作就行。
- 找到vue.config.js文件,修改devServer.proxy.pamirs.target为后端服务的地址和端口
const WidgetLoaderPlugin = require('@kunlun/widget-loader/dist/plugin.js').default;
const Dotenv = require('dotenv-webpack');
module.exports = {
lintOnSave: false,
runtimeCompiler: true,
configureWebpack: {
module: {
rules: [
{
test: /\.widget$/,
loader: '@kunlun/widget-loader'
}
]
},
plugins: [new WidgetLoaderPlugin(), new Dotenv()],
resolveLoader: {
alias: {
'@kunlun/widget-loader': require.resolve('@kunlun/widget-loader')
}
}
},
devServer: {
port: 8080,
disableHostCheck: true,
progress: false,
proxy: {
pamirs: {
// 支持跨域
changeOrigin: true,
target: 'http://127.0.0.1:8090'
}
}
}
};注:要用localhost域名访问,.env文件这里也要改成localhost。如果开发中一定要出现前后端域名不一致,老版本Chrome会有问题,修改可以请参考https://www.cnblogs.com/willingtolove/p/12350429.html 。或者下载新版本Chrome
- 进入前端工程demo-front文件目录下,执行 npm run dev,最后出现下图就代表启动成功

- 使用 http://127.0.0.1:8081/login 进行访问,并用admin账号登陆,默认密码为admin

- 点击左上角进行应用切换,会进入App Finder页面,可以看到所有已经安装的应用,可以对照boot的yml配置文件看。但细心的小伙伴应该注意到了,在App Finder页面出现的应用跟我们启动工程yml配置文件中加载的启动模块数不是一一对应的,同时也没有看到我们demo模块。
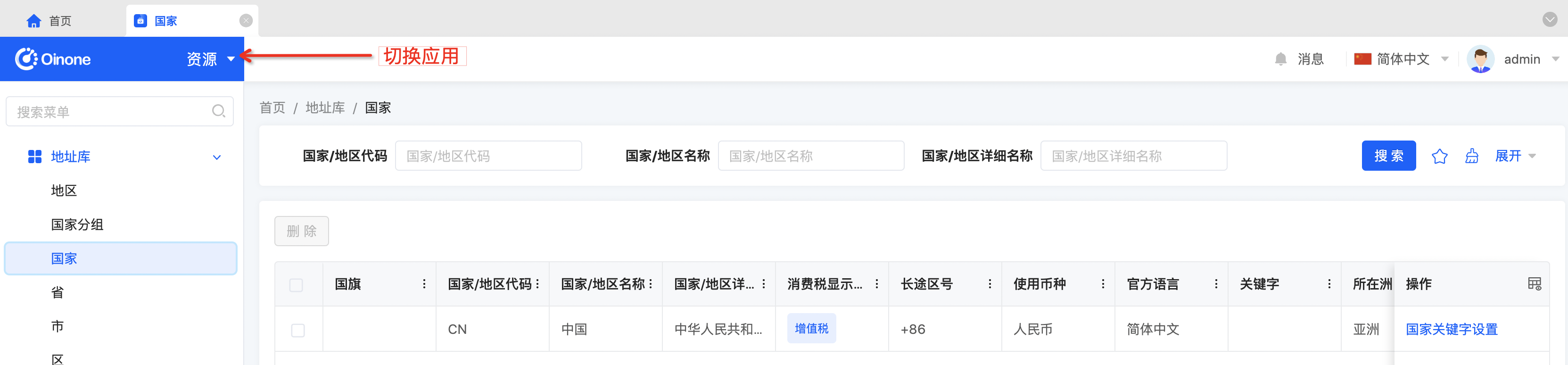

| boot工作的yml文件中加载模块 | App Finder的应用 | 说明 |
|---|---|---|
| - base- common- sequence- expression | 无 | 模块的application = false,为非应用类的模块 |
| - resource - user - auth - business- message - apps- my_center(show=INACTIVE )- sys_setting (show=INACTIVE ) | 有 | 模块的application = true,为应用类的模块但show=INACTIVE 的则不展示,通过以下方式定义:@Module(show = ActiveEnum.INACTIVE) |
| - demo_core | 无 | 刚建的oinoneDemo工程,默认为false |
| 设计器:无 | 设计器:无 | 因为boot中没有加载设计器模块,所以App Finder中的设计器tab选项卡下没有应用 |
- 只需要修改oinoneDemo工程的模块定义如下图,那么就可以在App Finder页面看见“oinoneDemo工程”。
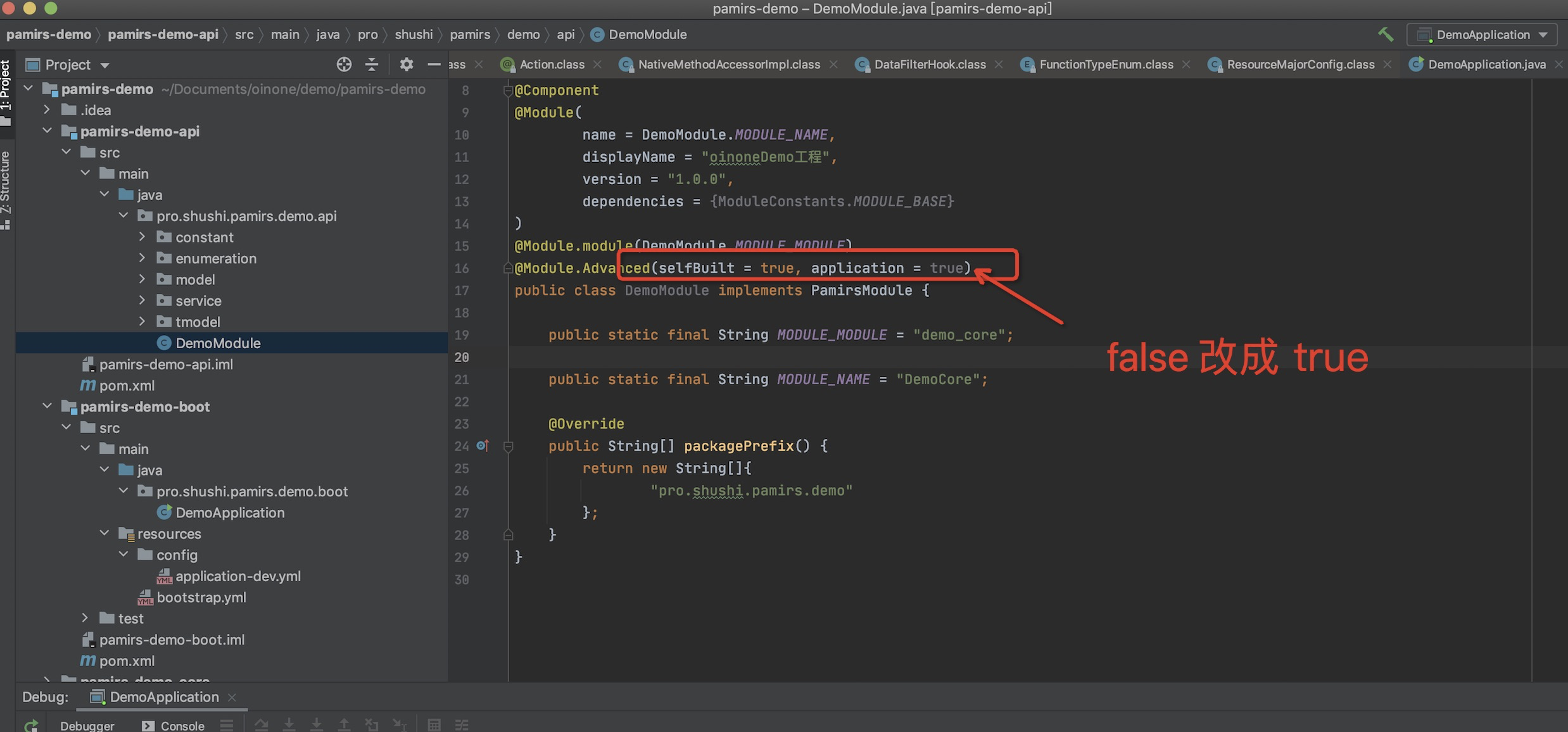

目前oinone的Demo模块还是一个全空的模块,所以我们点击后会进入一个空白页面。在后续的学习过程中我们会不断完善该模块。
至此恭喜您,前端工程已经启动完成。
三、前端工程结构介绍
├── public 发布用的目录,index.html入口文件将在这里
│
├── src 源代码
│ ├── action 扩展动作的目录
│ ├── field 模型字段对应控件目录
│ ├── layout 布局控件目录
│ ├── mask 母版控件目录
│ ├── view 自定义视图目录
│ └── main.ts 应用入口文件 这里会注册providers/application.ts
│ └── theme.ts 定义主题文件
├── .env.example 启动的环境变量,后端api的请求地址在这里
├── package.json 包描述文件
├── tsconfig.json ts配置文件,可配置语法校验
└── vue.config.js vue的配置文件,里面可以配置webpack参数和开发模式的后端api请求地址Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9229.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验