
一、使用场景
在碰到大数据量并且需要全文检索的场景,我们在分布式架构中基本会架设ElasticSearch来作为一个常规解决方案。在oinone体系中增强模型就是应对这类场景,其背后也是整合了ElasticSearch。
二、整体介绍
oinone与es整合设计图
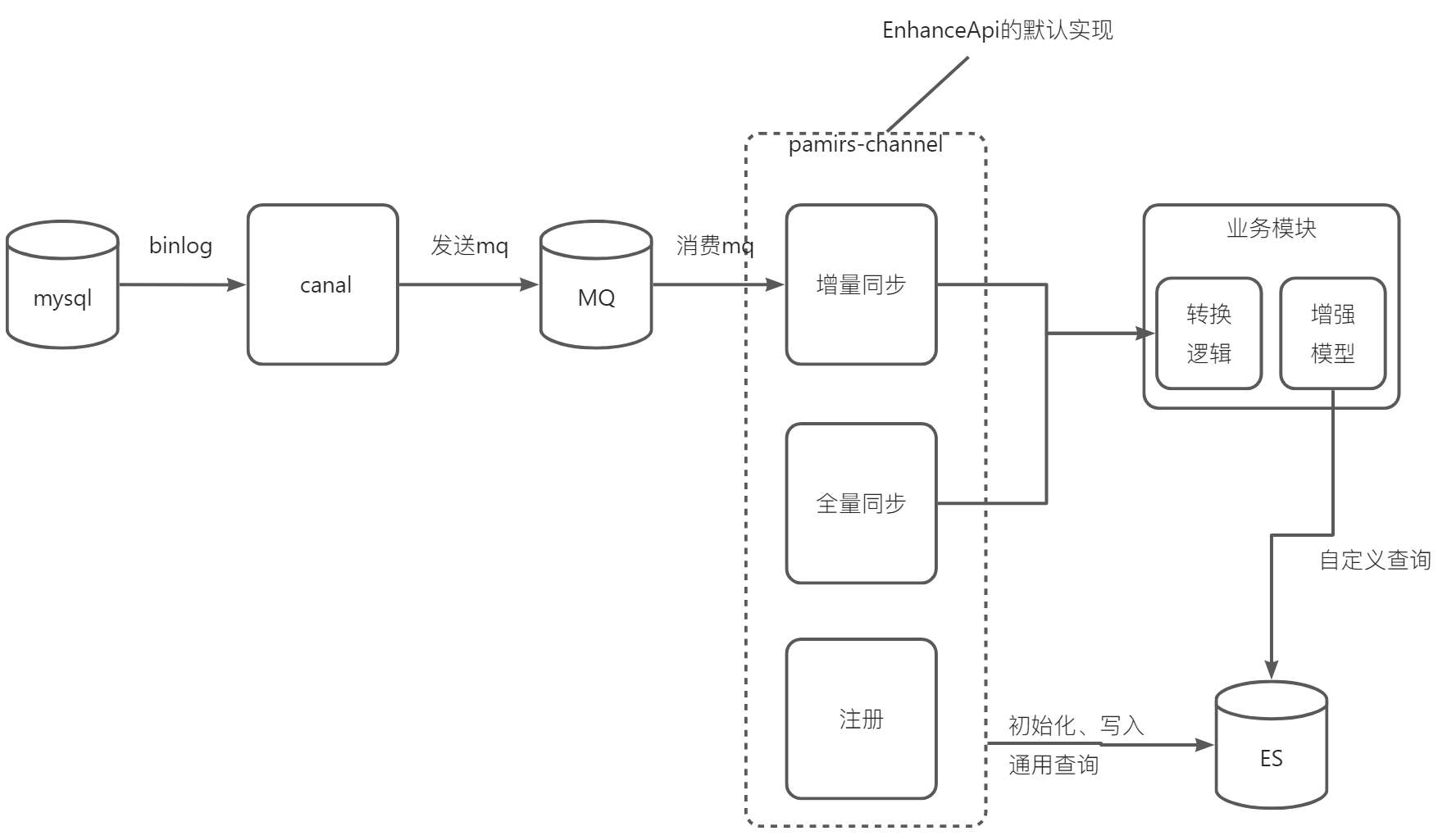

基础环境安装
Canal安装
详见4.1.10【函数之触发与定时】一文
修改Canal配置并重启
新增Canal的实例【destinaion: pamirs】,监听分表模型的binlog【filter: demo.demo_core_sharding_model……】用于增量同步
pamirs:
middleware:
data-source:
jdbc-url: jdbc:mysql://localhost:3306/canal_tsdb?useUnicode=true&characterEncoding=utf-8&verifyServerCertificate=false&useSSL=false&requireSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: oinone
canal:
ip: 127.0.0.1
port: 1111
metricsPort: 1112
zkClusters:
- 127.0.0.1:2181
destinations:
- destinaion: pamirschangedata
name: pamirschangedata
desc: pamirschangedata
slaveId: 1235
filter: demo\.demo_core_pet_talent
dbUserName: root
dbPassword: oinone
memoryStorageBufferSize: 65536
topic: CHANGE_DATA_EVENT_TOPIC
dynamicTopic: false
dbs:
- { address: 127.0.0.1, port: 3306 }
- destinaion: pamirs
id: 1234
name: pamirs
desc: pamirs
slaveId: 1234
filter: demo\.demo_core_sharding_model_0,demo\.demo_core_sharding_model_1,demo\.demo_core_sharding_model_2,demo\.demo_core_sharding_model_3,demo\.demo_core_sharding_model_4,demo\.demo_core_sharding_model_5,demo\.demo_core_sharding_model_6,demo\.demo_core_sharding_model_7
dbUserName: root
dbPassword: oinone
memoryStorageBufferSize: 65536
topic: BINLOG_EVENT_TOPIC
dynamicTopic: false
dbs:
- { address: 127.0.0.1, port: 3306 }
tsdb:
enable: true
jdbcUrl: "jdbc:mysql://127.0.0.1:3306/canal_tsdb"
userName: root
password: oinone
mq: rocketmq
rocketmq:
namesrv: 127.0.0.1:9876
retryTimesWhenSendFailed: 5
dubbo:
application:
name: canal-server
version: 1.0.0
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
port: 20881
scan:
base-packages: pro.shushi
server:
address: 0.0.0.0
port: 10010
sessionTimeout: 3600ES安装
-
下载安装包官方下载地址,也可以直接下载elasticsearch-8.4.1-darwin-x86_64.tar.gz.txt(361.7 MB),下载后去除后缀.txt,然后解压文件
-
替换安装目录/config下的[elasticsearch.yml](elasticsearch)(1 KB),主要是文件中追加了三个配置
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false- 启动
a. 导入环境变量(ES运行时需要JDK18及以上版本JDK运行环境, ES安装包中包含了一个JDK18版本)
# export JAVA_HOME=/Users/oinone/Documents/oinone/es/elasticsearch-8.4.1/jdk.app/Contents/Home/
export JAVA_HOME=ES解压安装目录/jdk.app/Contents/Home/b. 运行ES
## nohup /Users/oinone/Documents/oinone/es/elasticsearch-8.4.1/bin/elasticsearch >> $TMPDIR/elastic.log 2>&1 &
nohup ES安装目录/bin/elasticsearch >> $TMPDIR/elastic.log 2>&1 & - 停止ES
lsof -nP -iTCP:9300 -sTCP:LISTEN | grep java | awk '{print $2;}' | xargs killES控制台安装
-
下载cerebro-0.9.4.tgz.txt(54.6 MB)文件,下载后去除后缀.txt,然后解压文件,解压之后执行 bin/cerebro 或者 bin/cerebro.bat (windows)
-
进入cerebro-0.9.4/bin目录下执行以下命令
./cerebro- 启动后访问地址: http://localhost:9000
- Node address 填入es服务地址
http://127.0.0.1:9200
恭喜es环境搭建完毕,我们开始进入学习
三、第一个增强模型(举例)
Step1 相关依赖包引入boot工程
-
boot工程需要指定ES客户端包版本,不指定版本会隐性依赖顶层spring-boot依赖管理指定的低版本
-
boot工程加入pamris-channel的工程依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.4.1</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-channel-core</artifactId>
</dependency>Step2 在pamirs-demo-api中增加入pamirs-channel-api的依赖
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-channel-api</artifactId>
</dependency>Step3 修改application-dev.yml
在pamirs-demo-boot的application-dev.yml文件中增加配置pamirs.boot.modules增加channel,即在启动模块中增加channel模块。同时注意es的配置,是否跟es的服务一致
pamirs:
boot:
modules:
- channel
elastic:
url: 127.0.0.1:9200Step4 DemoModule增加对ChannelModule的依赖
@Module(dependencies = {ChannelModule.MODULE_MODULE})Step5 为ShardingModel新建一个增强模型
在大数据量的情况下,我们经常会通过ES来提升查询速度
package pro.shushi.pamirs.demo.api.enhance;
import pro.shushi.pamirs.channel.enmu.IncrementEnum;
import pro.shushi.pamirs.channel.meta.Enhance;
import pro.shushi.pamirs.channel.meta.EnhanceModel;
import pro.shushi.pamirs.demo.api.model.ShardingModel;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.ModelTypeEnum;
@Model(displayName = "测试EnhanceModel")
@Model.model(ShardingModelEnhance.MODEL_MODEL)
@Model.Advanced(type = ModelTypeEnum.PROXY, inherited = {EnhanceModel.MODEL_MODEL})
@Enhance(shards = "3", replicas = "1", reAlias = true,increment= IncrementEnum.OPEN)
public class ShardingModelEnhance extends ShardingModel {
public static final String MODEL_MODEL="demo.ShardingModelEnhance";
}
Step6 为增强模型增加菜单入口
@UxMenu("增强模型")@UxRoute(ShardingModelEnhance.MODEL_MODEL) class ShardingModelEnhanceMenu{}Step7 重启系统看效果
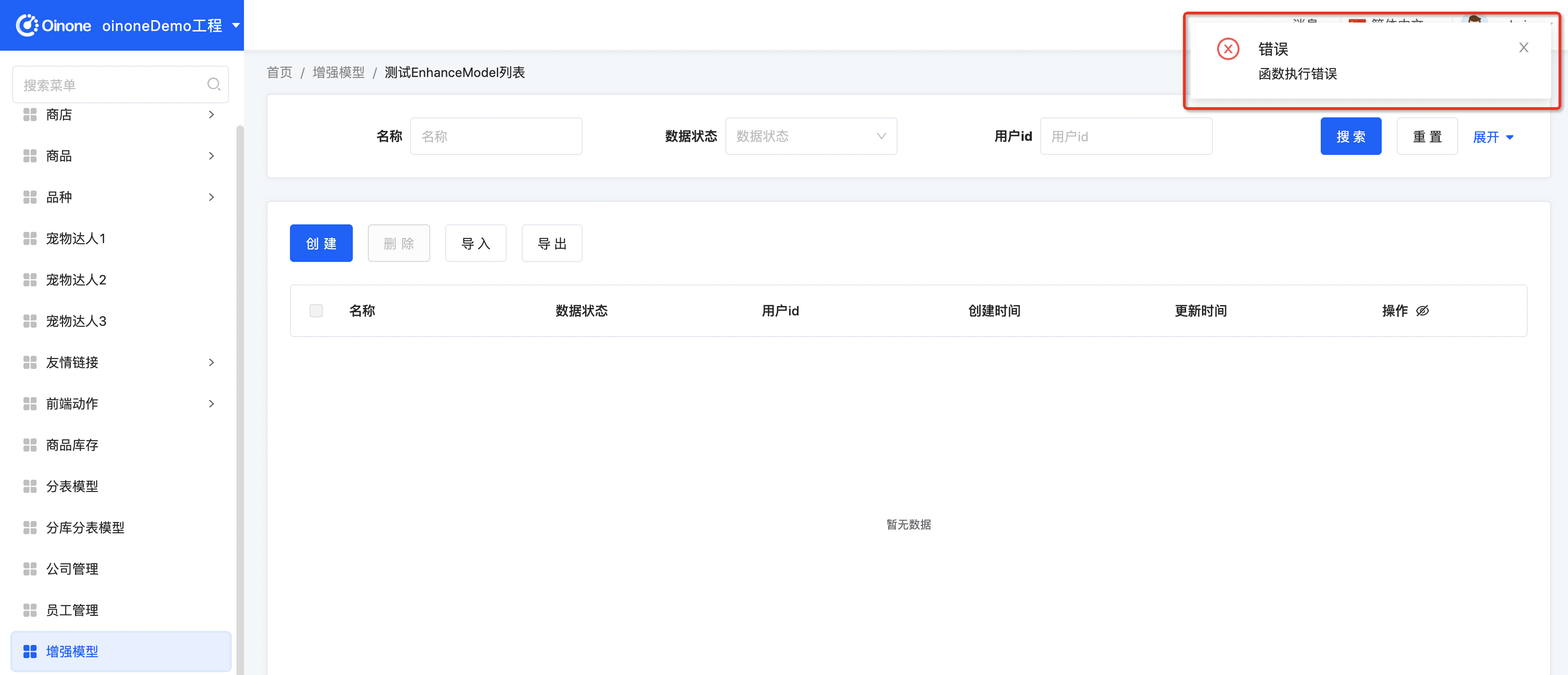
- 第一次访问页面会报错,因为针对该增强模型的相关初始化工作还未完成
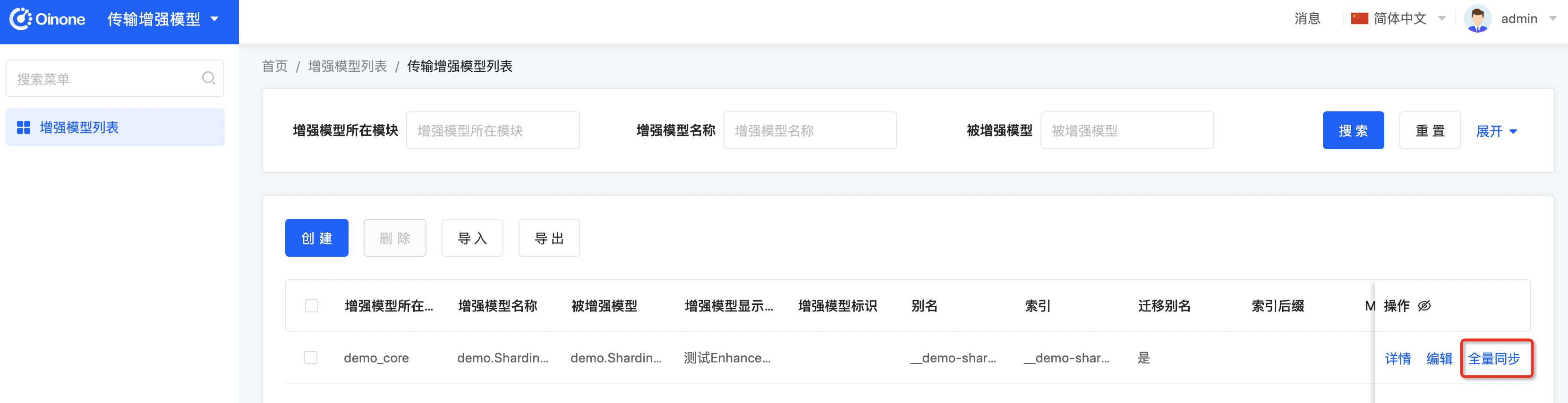
- 进入【传输增强模型】应用,访问增强模型列表我们会发现一条记录,并点击【全量同步】初始化ES,并全量dump数据
- 再次回到Demo应用,进入增强模型页面,可以正常访问并进增删改查操作
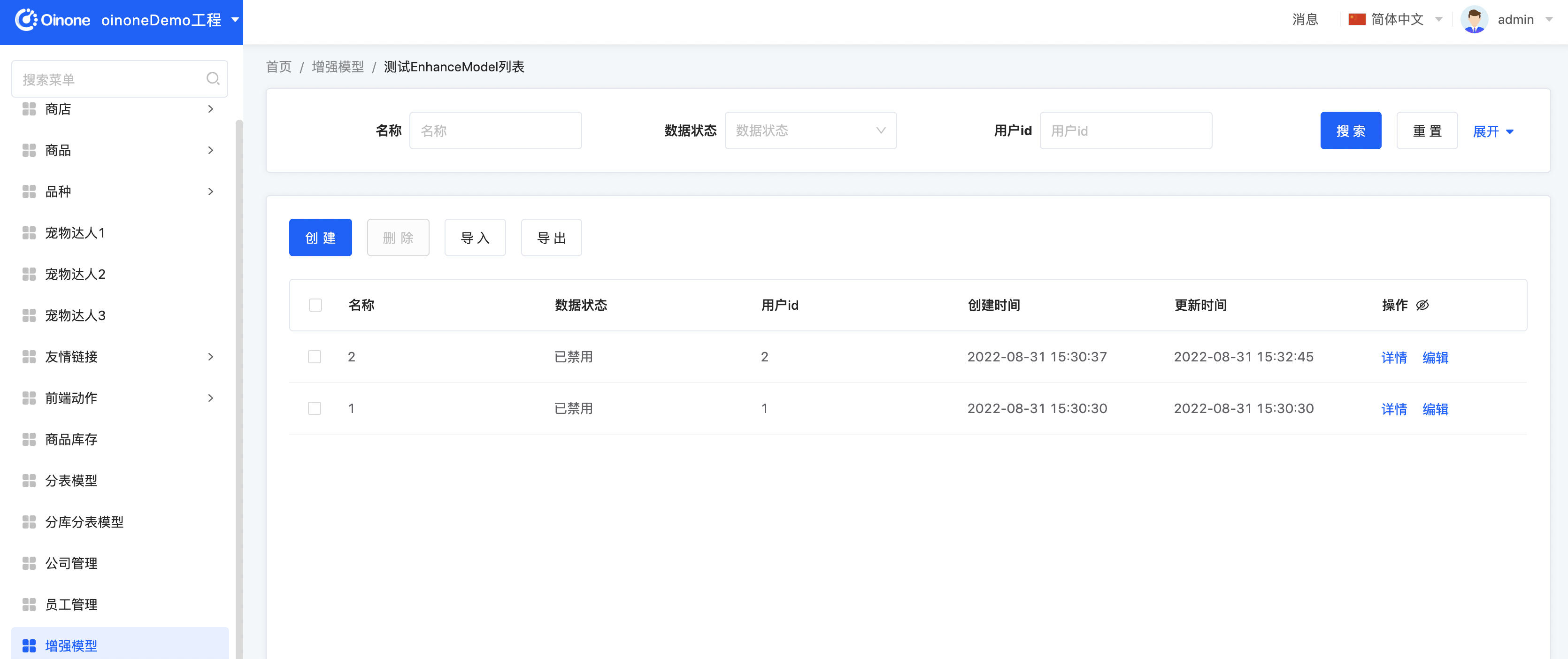
对数据进行修改,我们可以看到以下日志

四、个性化dump逻辑
有时候我们dump逻辑是有个性化需求,那么我们可以重写模型的synchronize方法,函数重写特性我们在3.4.3【函数的相关特性】一文中的“面向对象-继承与多态”部分中已经有详细介绍。
Step1 重写ShardingModelEnhance模型的synchronize方法
下面例子中我们给ShardingModelEnhance模型增加一个nick字段,在同步搜索引擎的时候把name赋值给nick字段。
package pro.shushi.pamirs.demo.api.enhance;
import pro.shushi.pamirs.channel.enmu.IncrementEnum;
import pro.shushi.pamirs.channel.meta.Enhance;
import pro.shushi.pamirs.channel.meta.EnhanceModel;
import pro.shushi.pamirs.demo.api.model.ShardingModel;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum;
import pro.shushi.pamirs.meta.enmu.ModelTypeEnum;
import java.util.List;
@Model(displayName = "测试EnhanceModel")
@Model.model(ShardingModelEnhance.MODEL_MODEL)
@Model.Advanced(type = ModelTypeEnum.PROXY, inherited = {EnhanceModel.MODEL_MODEL})
@Enhance(shards = "3", replicas = "1", reAlias = true,increment= IncrementEnum.OPEN)
public class ShardingModelEnhance extends ShardingModel {
public static final String MODEL_MODEL="demo.ShardingModelEnhance";
@Field(displayName = "nick")
private String nick;
@Function.Advanced(displayName = "同步数据", type = FunctionTypeEnum.UPDATE)
@Function(summary = "数据同步函数")
public List<ShardingModelEnhance> synchronize(List<ShardingModelEnhance> data) {
for(ShardingModelEnhance shardingModelEnhance:data){
shardingModelEnhance.setNick(shardingModelEnhance.getName());
}
return data;
}
}
Step2 重启应用看效果
我们修改记录数据,可以看到nick字段也自动赋值了。如果针对老数据记录,我们需要把新增的字段都自动填充,可以进入【传输增强模型】应用,访问增强模型列表,找到对应的记录并点击【全量同步】
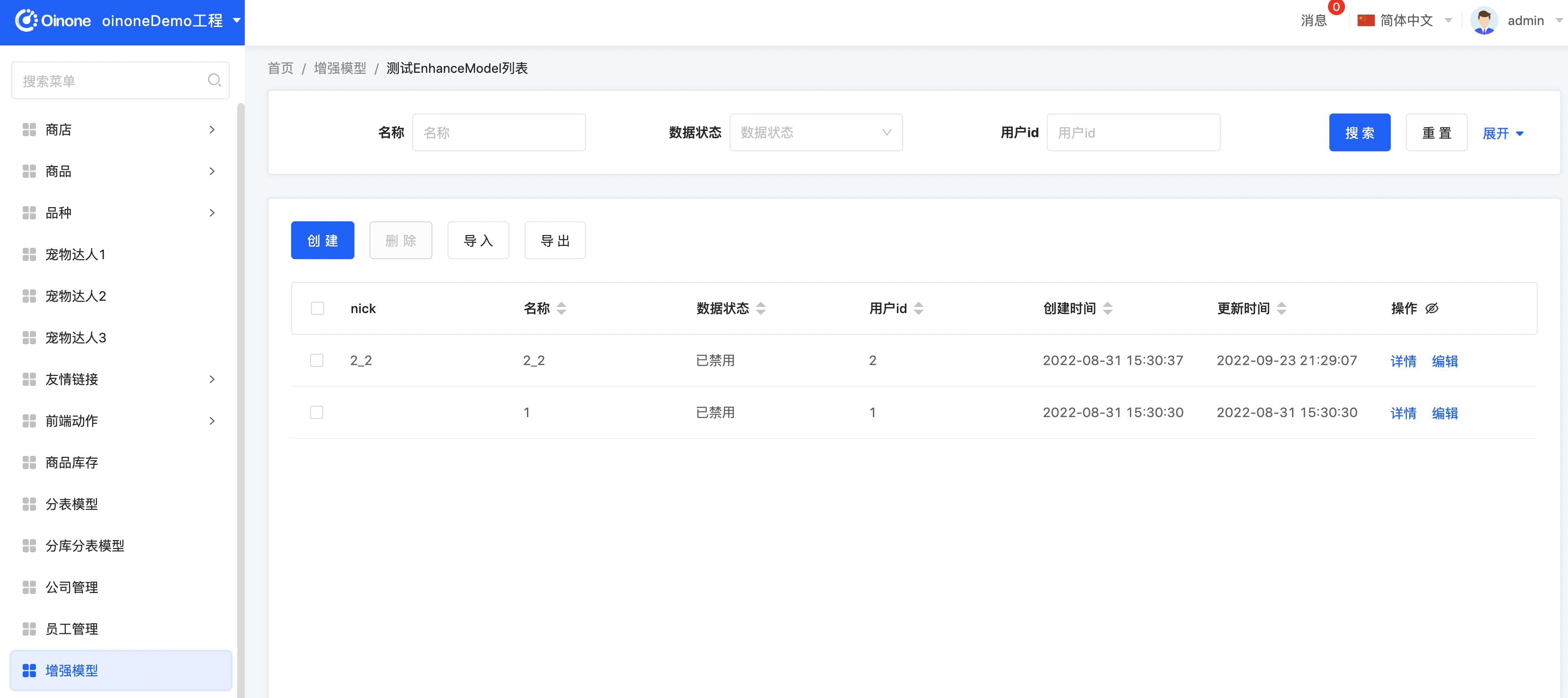
五、给搜索增加个性化逻辑
如果我们需要在查询方法中增加逻辑,在前面的教程中一般是重写queryPage函数,但对于增强模型我们需要重写的是search函数。
Step1 重写ShardingModelEnhance模型的search方法
@Function(
summary = "搜索函数",
openLevel = {FunctionOpenEnum.LOCAL, FunctionOpenEnum.REMOTE, FunctionOpenEnum.API}
)
@pro.shushi.pamirs.meta.annotation.Function.Advanced(
type = {FunctionTypeEnum.QUERY},
category = FunctionCategoryEnum.QUERY_PAGE,
managed = true
)
public Pagination<ShardingModelEnhance> search(Pagination<ShardingModelEnhance> page, IWrapper<ShardingModelEnhance> queryWrapper) {
System.out.println("您的个性化搜索逻辑");
return ((IElasticRetrieve) CommonApiFactory.getApi(IElasticRetrieve.class)).search(page, queryWrapper);
}Step2 重启应用看效果

Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9300.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验