
1.流程类
1.1 审批
审批节点配置步骤:
- 添加审批节点
- 选择审批的模型和视图
- 设置审批人和通过方式
- 设置审批人在审批时的操作权限和数据权限
1.1.1 审批节点
审批节点只能放置在有数据可审批的流程链路上,审批分支只能放置在审批节点后。
1.1.2 审批模型和视图
可选的审批模型包含添加的审批节点之前的所有能获取到数据的模型。可选视图为该选择的数据模型关联的界面设计器中视图类型为表单的页面。
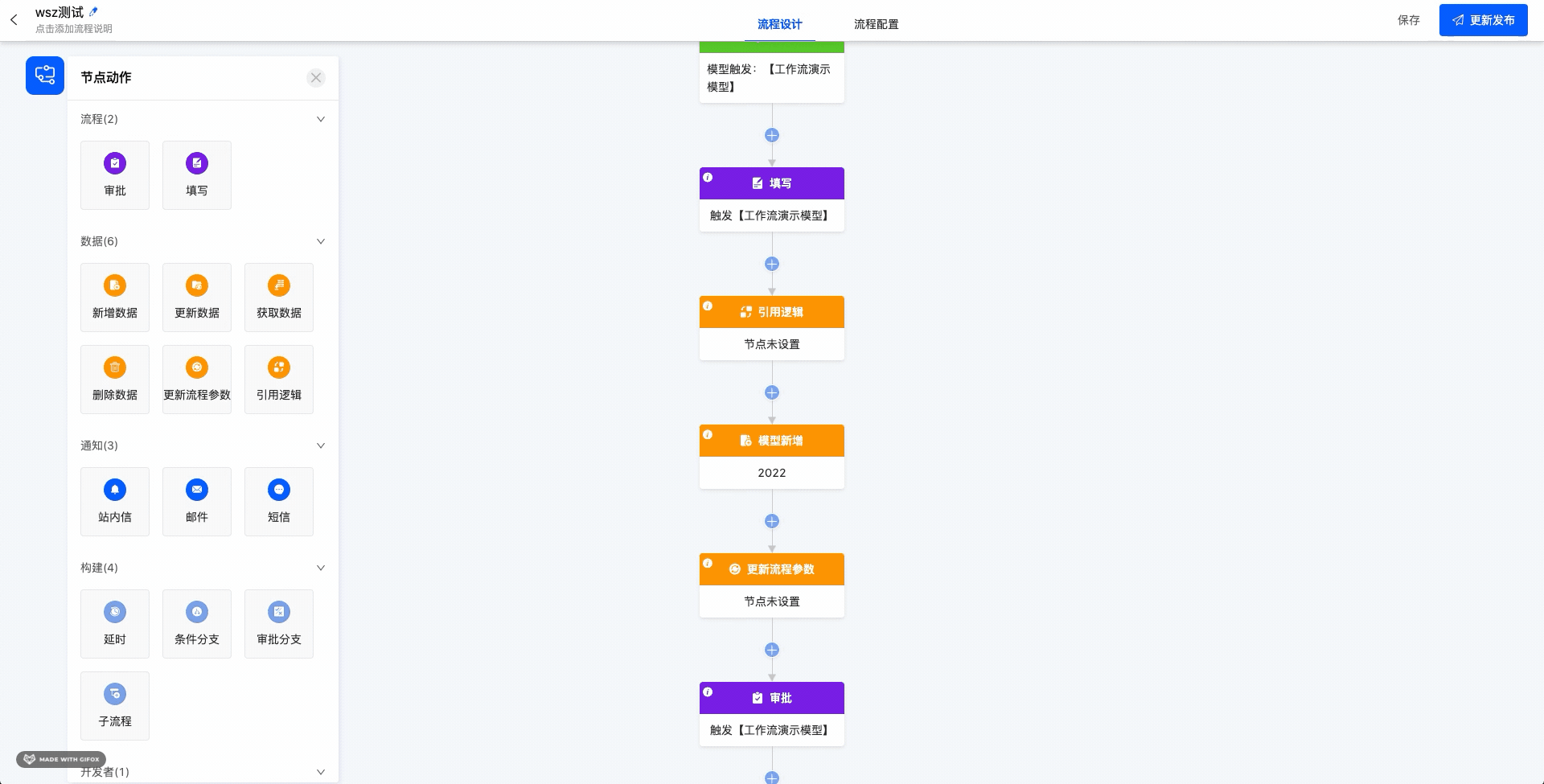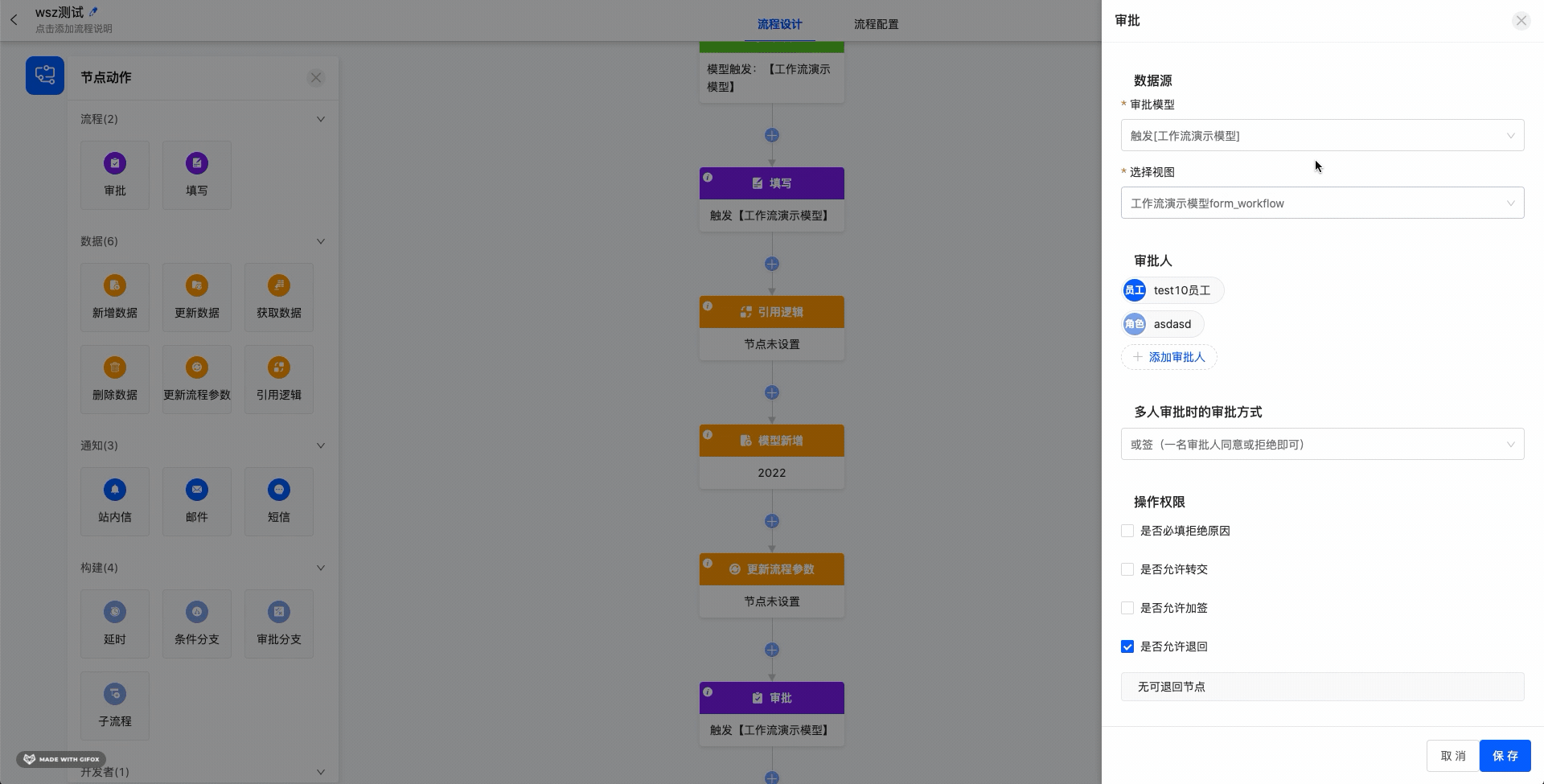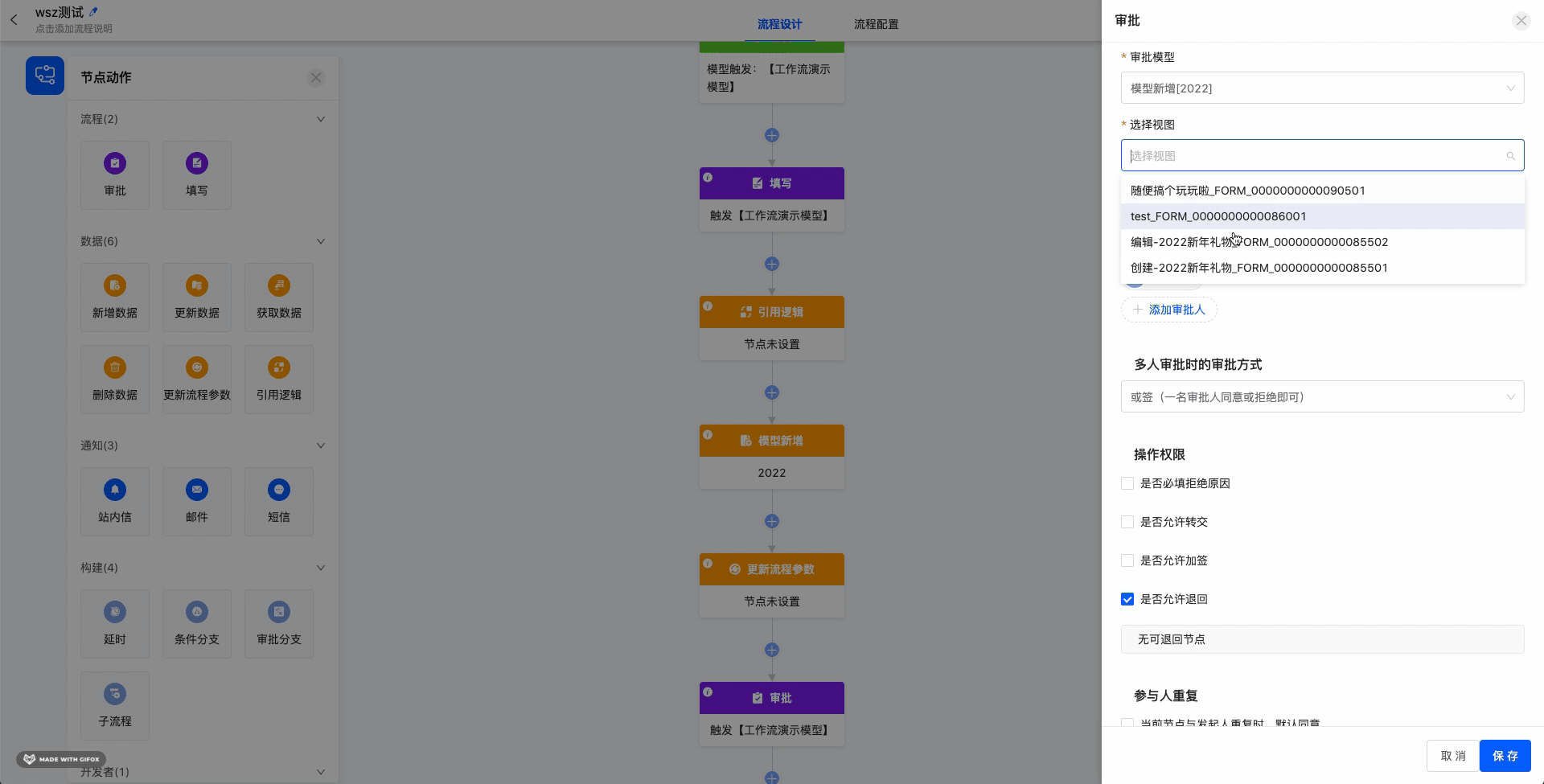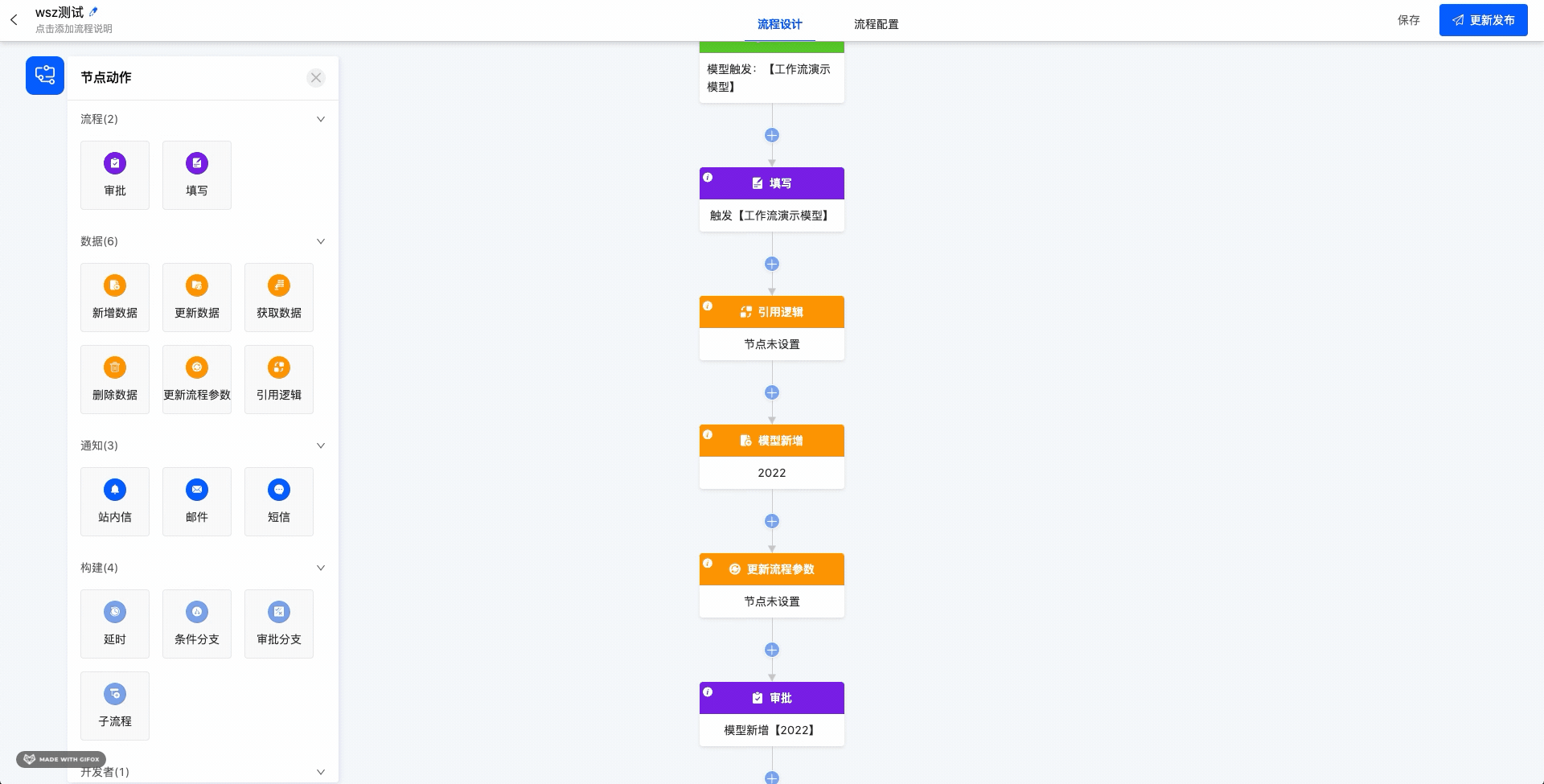

1.1.3 审批人和通过方式
审批人可在个人、部门、角色和模型中的字段里复选。当某人在不同类型人员选择中被重复选中,只会收到一次审批的代办。若为多人审批,审批是同步进行的。
- 单人审批:
- 通过方式:唯一通过方式,同意通过,拒绝否决
- 多人审批:
- 通过方式:或签/会签(默认或签)
a. 或签(一名审批人同意或拒绝即可)
任意一位审批人操作通过或否决后流程就结束,其他审批人无法进入审批操作,但是会弹出消息提示审批结果。
场景:紧急且影响不大的审批可以由任意一位领导层或签。
b. 会签(需所有审批人同意才为同意,一名审批人拒绝即为拒绝)
场景:影响比较重大的审批,一票否决的形式决定是否通过。
c. 会签(一名审批人同意即为同意,需所有审批人拒绝才为拒绝)
场景:需要评估项目可操作性时,若有领导觉得有意义就通过,进入下一步评估,全员否决就否决项目。
1.1.4 操作&数据权限
- 操作权限
可设置是否必填拒绝原因、是否允许转交、是否允许加签、是否允许退回。
选择允许转交或允许加签之后,可选择添加人员的候选名单,不填默认所有人都可选。
选择允许退回后,可以选择退回到该审批节点之前的任意审批节点。ps:需所有审批人拒绝才为拒绝的会签不允许退回。
- 数据权限
选择视图后自动显示该视图下的数据字段,可选择的权限为查看、编辑、隐藏数据字段,默认可查看全部字段。
1.1.5 参与人重复
勾选参与人重复的场景时,满足场景的审批流程会由系统自动审批通过。
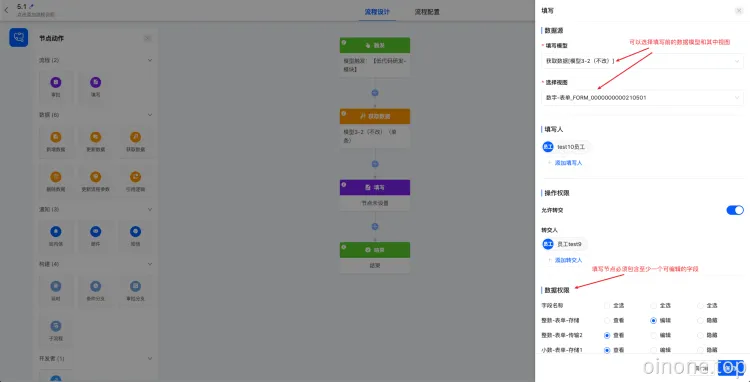
1.2 填写
当流程需要某些人提交数据才能继续时,可以使用填写这个动作。区别于数据类中的操作,填写这个动作只能修改当前触发模型中关联的视图表单,而数据类中的更新数据可以修改其他模型中的数据。
和审批动作相似,填写动作需要选择填写的模型和视图表单,需要选择填写人,可以选择添加转交权限。另外,填写动作必须包含一个及以上的可编辑的数据权限供操作人填写。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9415.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验