
当今企业软件开发行业,低代码和无代码已经成为热门话题。它们的优势很明显:加速软件开发周期、减少代码开发时间、降低开发成本、易于维护等等。而 Oinone 作为一个低无一体的开发平台,更是在这些优势上做出了巨大的创新。
技术亮点
低代码-在不改变研发习惯的前提下,提升效率降低难度(如下图2-15所示)
一、提高专业开发人员效率
低代码开发模式大大降低了繁琐、重复的工作,模型定义完后,数据 API、数据管理器、基础管理的界面都不需要再进行开发。同时,低代码模式让分布式微服务架构的系统开发变得简单,研发人员不需要考虑分布式部署能力和大数据能力,也不需要去关心一些业务无关的通用能力,如权限、导入导出、国际化翻译、消息、审计等。这样,开发人员可以专注于业务研发,从而大幅提高开发效率。
二、提升系统扩展性
在研发标品的时候,低代码模式让开发人员不再需要关心系统的扩展性。与传统模式不同,低代码模式更加注重元数据的管理,这样就可以更好地保障系统扩展性。
三、保留研发人员习惯
Oinone 平台非常开放,满足开发人员的各种习惯,比如原有的 IDE 环境、熟悉的 Spring Boot 工程结构等。而且在 Oinone 的低代码模式下,研发人员还可以通过无代码方式,在线可视化地修改应用。这样,即使在使用低代码模式的情况下,开发人员也可以保留原有的习惯,提升开发效率。
四、提供更加开放的解决方案
Oinone 提供了非常开放的解决方案,让开发人员可以自由定制和组合各种功能。当行业出现特殊的功能需求时,开发人员可以整合成平台组件,并集成到应用中。Oinone的低代码模式具有高度的开放性和灵活性,这使得它在与其他低代码平台的比较中具有明显的优势。相比其他低代码平台,Oinone不会在无法满足特定需求的情况下限制开发人员的创造力(如下图2-16所示)。
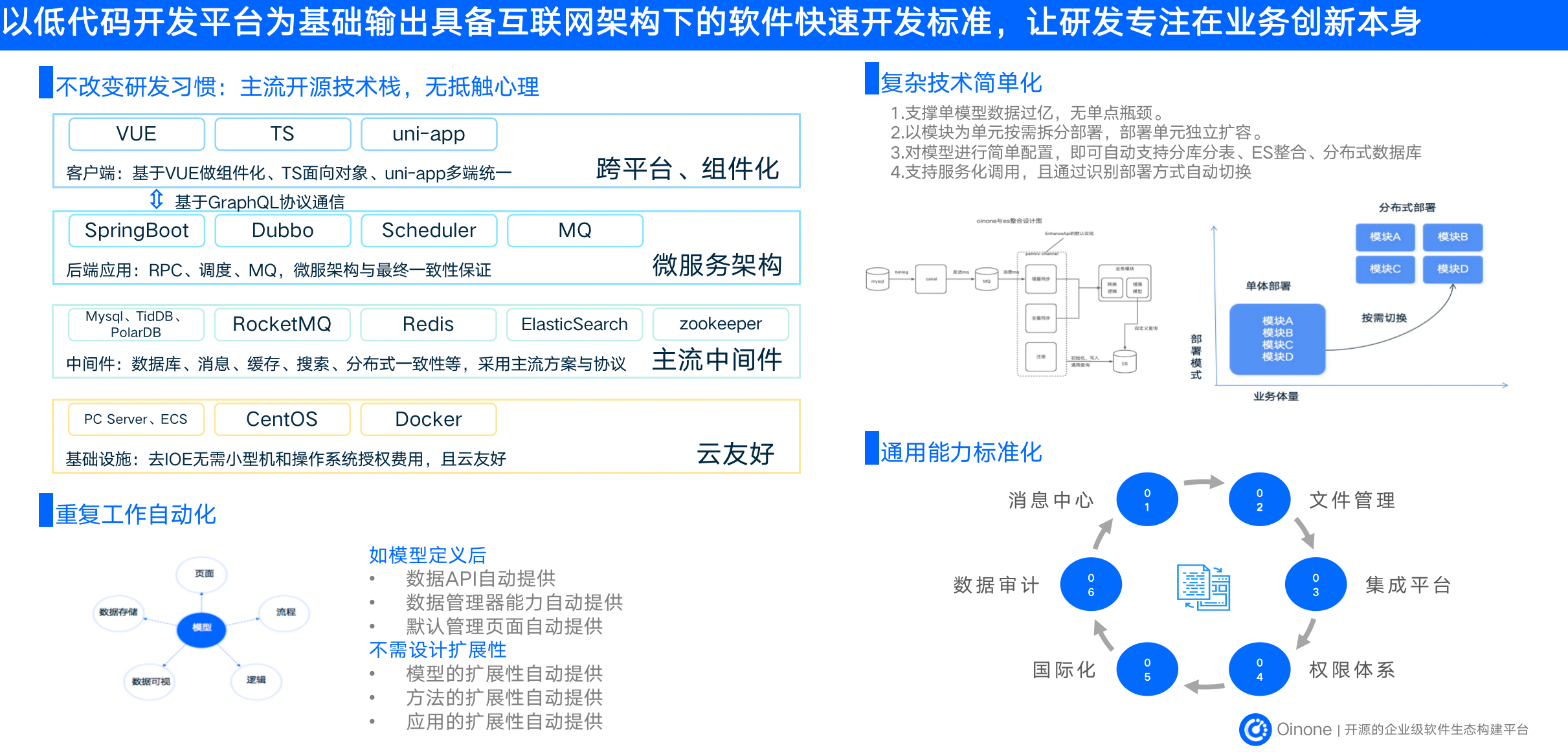

图2-15 Oinone低代码特性介绍
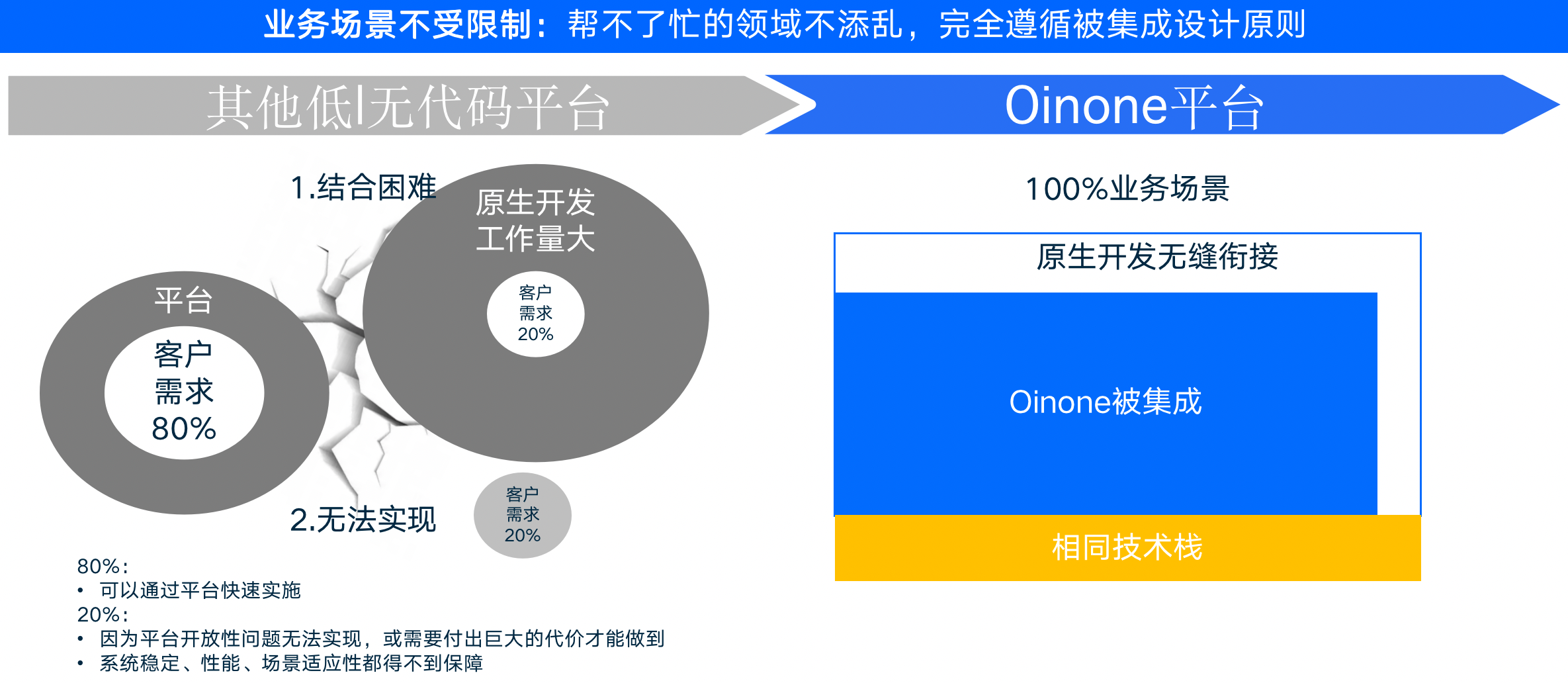
图2-16 Oinone低代码的被集成特性示意图
无代码-五大设计器覆盖研发方方面面,让业务、实施也能参与
它是LCDP的产品化呈现,是冰山露在外面大家看得到的,核心还是在LCDP本身。这部分实时在演进迭代,如您有想体验最新版本,可以在Oinone官网:https://www.oinone.top注册。
| 设计器 | 说明 | 产品展示 |
|---|---|---|
| 模型设计器 | 1.以模型为驱动,当有模型、数据字典、数据编码等设计功能,我们就可以完整地定义产品数据模型,模型设计器默认整体呈现区别于普通ER图,以当前模型为核心视角展开,可以点击关联模型切换主视角。2.多种模式可切换:专家与经典切换,图与表模式的切换 |  |
| 界面设计器 | 1.界面设计器旨在帮助用户快速搭建页面;2.所见即所得和根据不同视图类型设计契合的搭建交互就变得尤为重要;3.多端页面设计能力。 |  |
| 流程设计器 | 1.为业务流程和审批流程提供可自动执行的流程模型,通过定义流转过程中的各个动作、规则,以此实现流程自动化;2.流程可以跨应用设计,不同应用的模型之间可以通过同一流程执行。 |  |
| 逻辑设计器 | 1.组件化、可视化逻辑编排,逻辑动态变更、动态管理,实施验证。 |  |
| 数据可视化 | 1.从内部系统模型获取数据内容后,根据业务需求自定义图表,目的是为企业提供更高效的数据分析工具;2.可以智取业务系统模型,系统自动解析选择的模型、接口、表格中的字段后进行数据分析;3.降低对数据分析人员的研发能力要求,提升数据分析的效率 |  |
表2-3 Oinone无代码-五大设计器简述
真正的低无一体,体现在一体化的融合能力上
在开发核心产品时,我们主要采用低代码开发,辅以无代码的开发方式。你可以参考我们的低代码开发基础入门教程中3.5.5【设计器的结合】的文章。
而在实施或者处理临时需求时,我们主要采用无代码的开发方式,低代码作为辅助。这种模式比较特殊,只在SaaS模式下提供。如果你发现某个客户个性化部分无法通过无代码设计器完成,我们提供了一个“低无一体”模块,可以反向生成API代码,生成对应的扩展工程和API依赖包,再由专业研发人员基于扩展工程,利用API包进行开发并上传至平台,可以参考关于7.4【Oinone的低无一体】的文章。
| 场景 | 融合形式 | 具体操作 |
|---|---|---|
| 标准产品以低代码开发为主,以无代码为辅助 | 标品开发时结合无代码设计器来完成页面开发,可以把设计后的页面元数据装载为标准产品的一部分。详细教程见:3.5.5【设计器的结合】一文 |  |
| 项目交付以无代码为主,以低代码为辅助 | 当有特殊需求设计器无法支持时,则可以通过低无一体应用的代码模式来完成。支持了两种使用模式:上传jar包模式、源码托管模式。详细教程见:7.4【Oinone的低无一体】一文 | 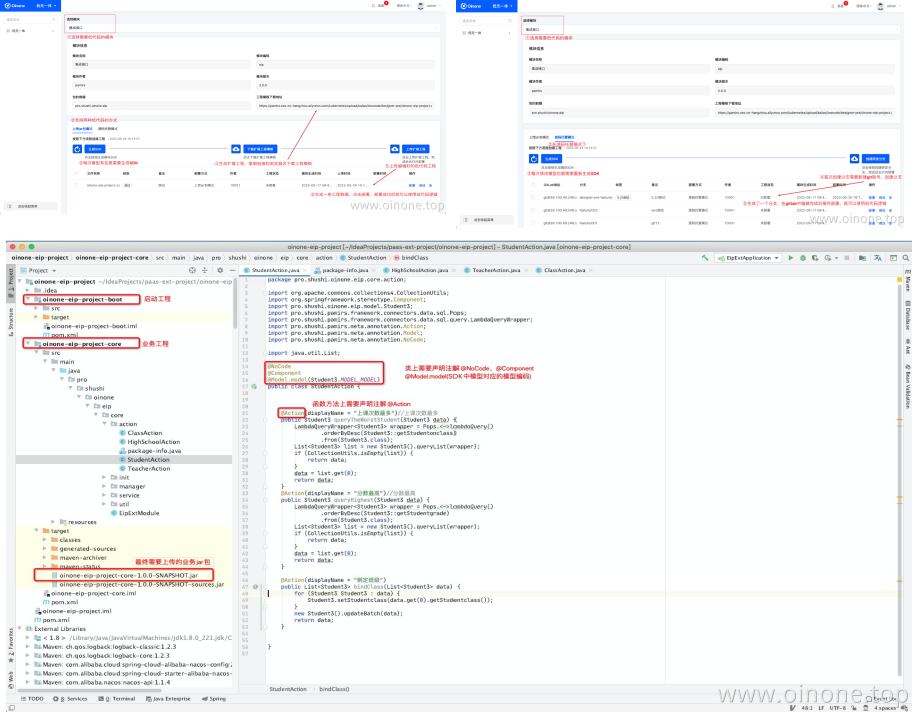 |
表2-4 不同场景适配方式说明
实现原理
本章节我们将从以下三个方面来解读Oinone的低无一体。
一:低无一体的设计原则及好处:真正的低无一体平台应该确保标准产品迭代与个性化保持独立,让软件企业具备为客户提供在线化的快速响应、个性化定制、持续更新等服务的能力,让企业客户能够真正自主做到敏捷响应和快速创新。所以Oinone的元数据融合方案跟其他平台有所区别(如下图2-17所示)。
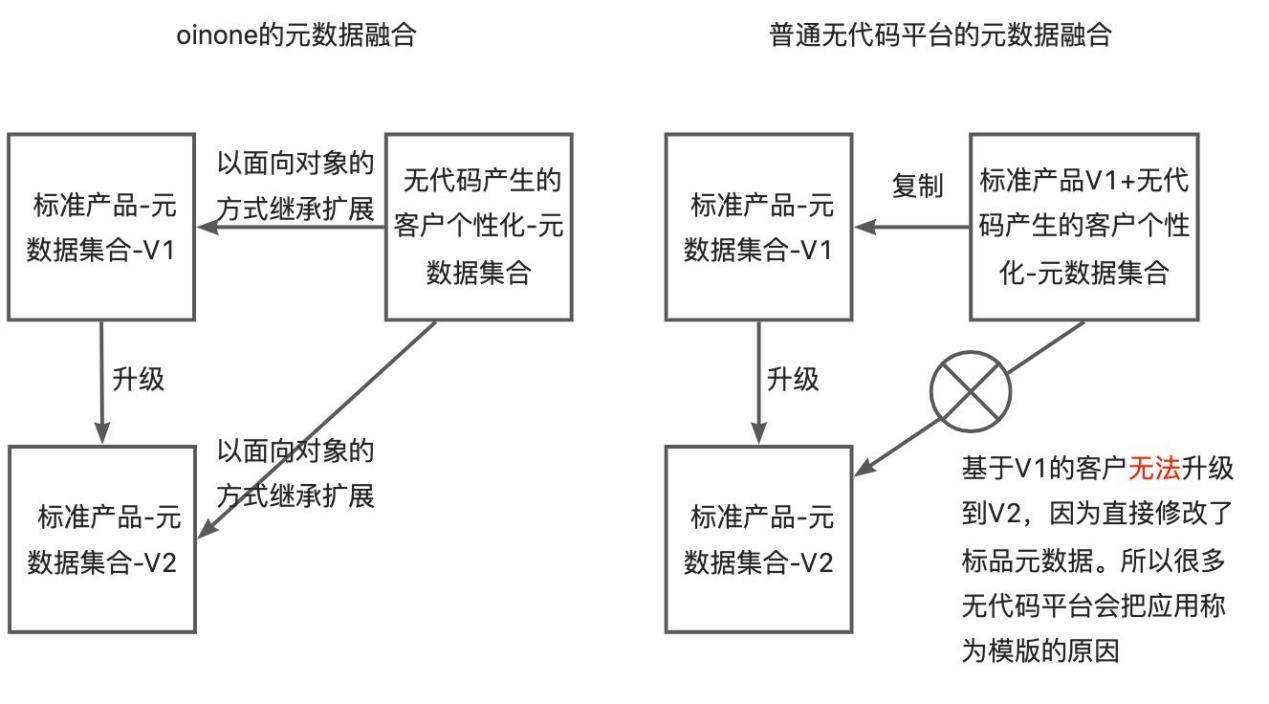
图2-17 Oinone与其他平台的元数据融合对比图
二:低无一体中低与无的关系:无代码是低代码平台的图形化呈现,是低代码的一个子集,它将无限接近低代码的能力,同时也将成为低代码平台的必备特征,是通过低代码开发的标准产品的二开配套工具。
三:低无一体中低与无的定位:通过表2-3可以看出,低代码和无代码在Oinone的体系中相互融合,共同构成了一个完整的低无一体模式,提供更加开放、灵活和可扩展的解决方案,让用户能够更加轻松地完成开发和实施。
| 低代码模式 | 无代码模式 | |
|---|---|---|
| 用户群体 | 专业研发 | 产品经理、需求分析师、直接业务人员 |
| 支撑场景 | 企业全场景软件以及二开 | 企业全场景软件以及二开,专业化场景比较高的则需低代码支持 |
| 核心能力 | 不改变研发习惯,提升研发效率 | 可视化编程无需专业编程语言知识 |
| 核心定位 | 开发标准模块 | 标准模块的二开无标品支撑场景的新模块开发 |
表2-3 Oinone低代码开发平台的两种开发模式对比
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9222.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验