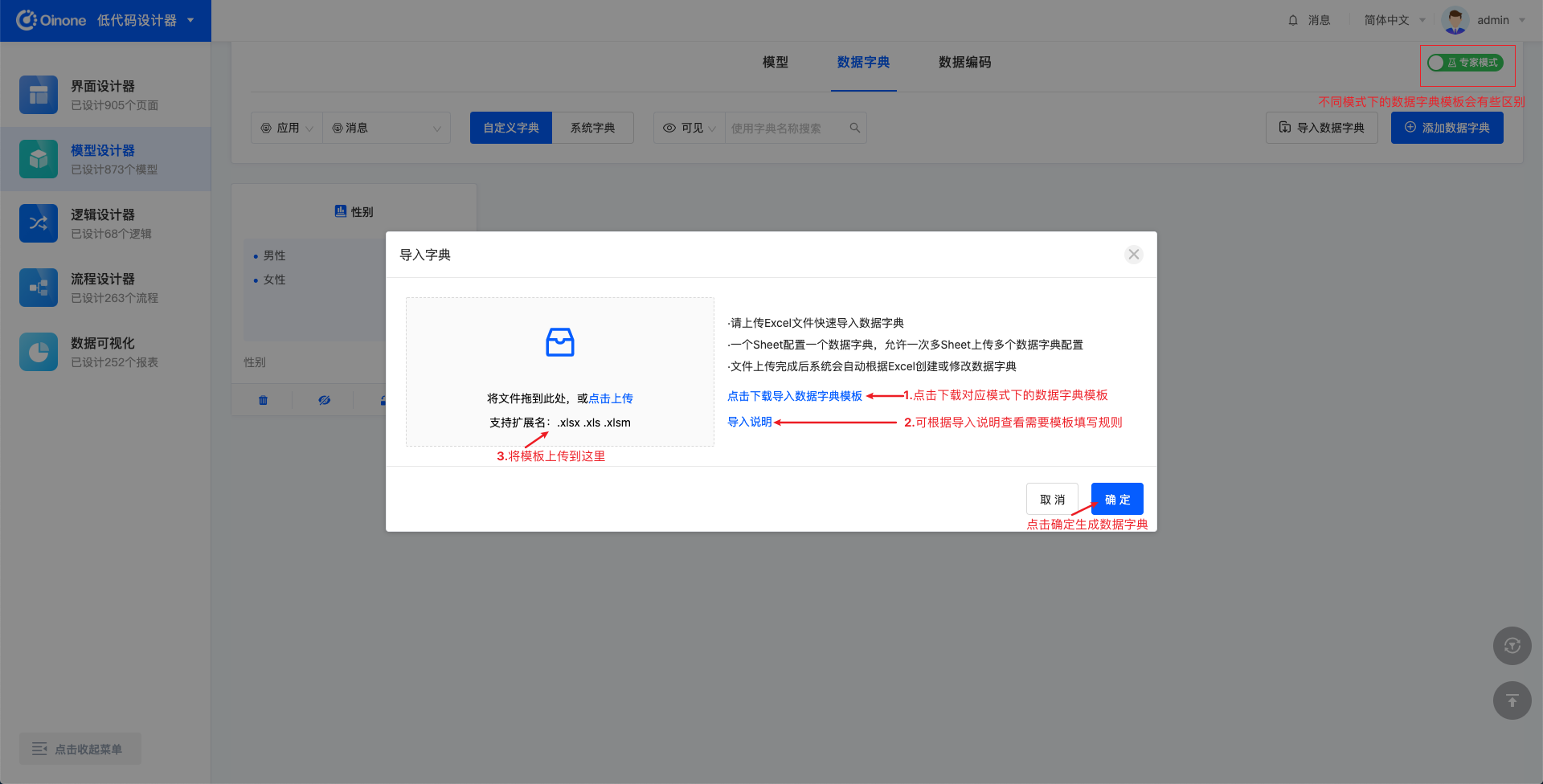
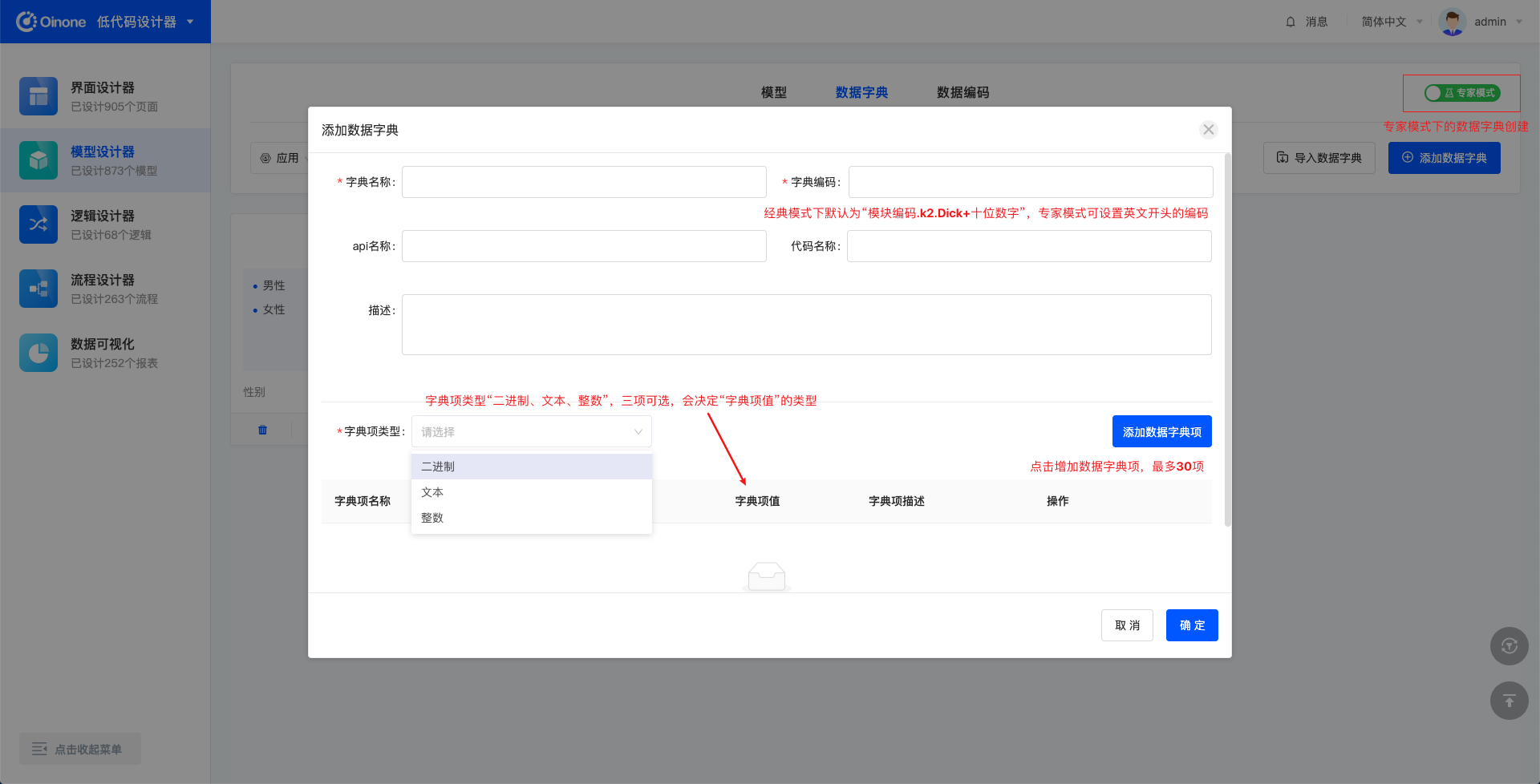
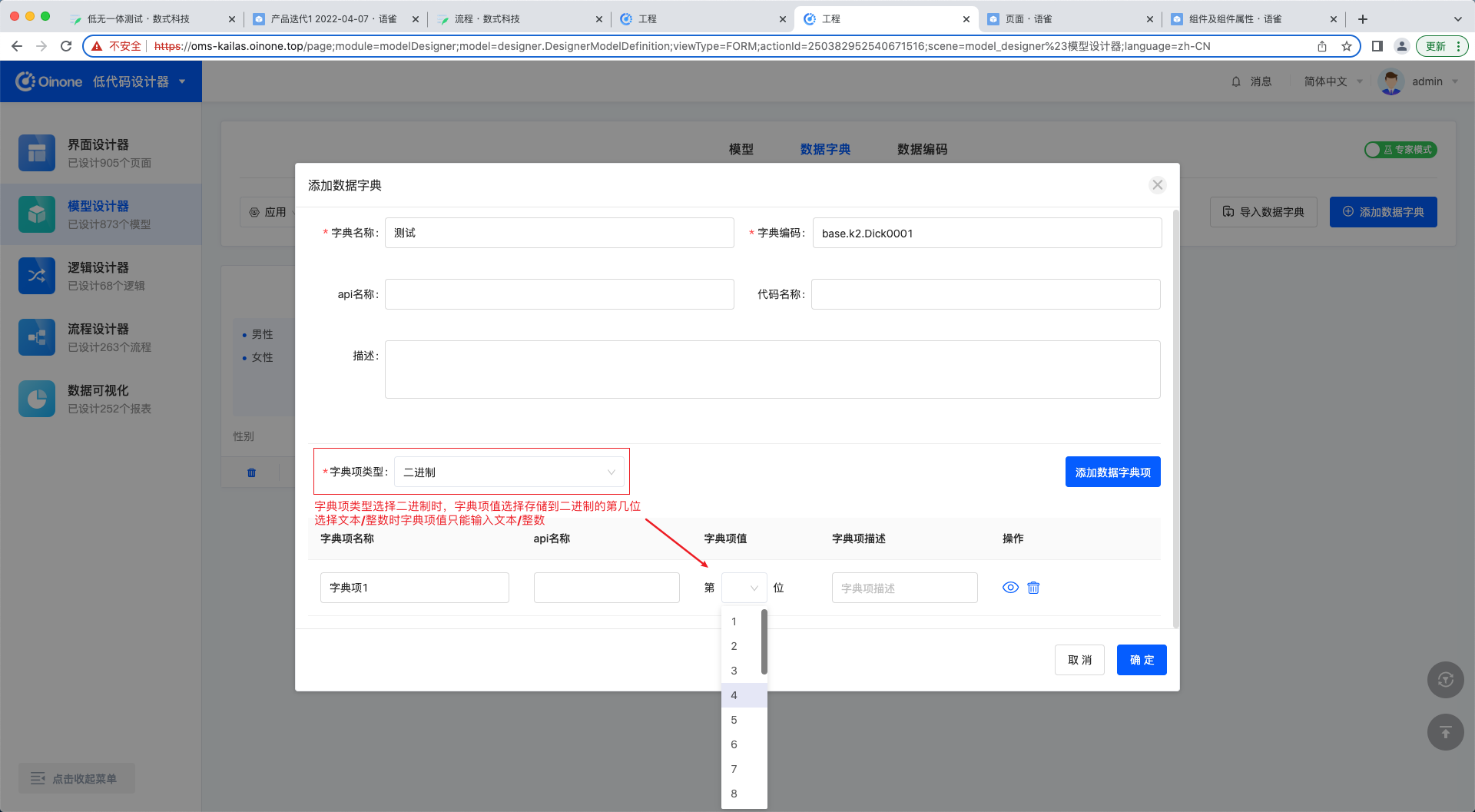
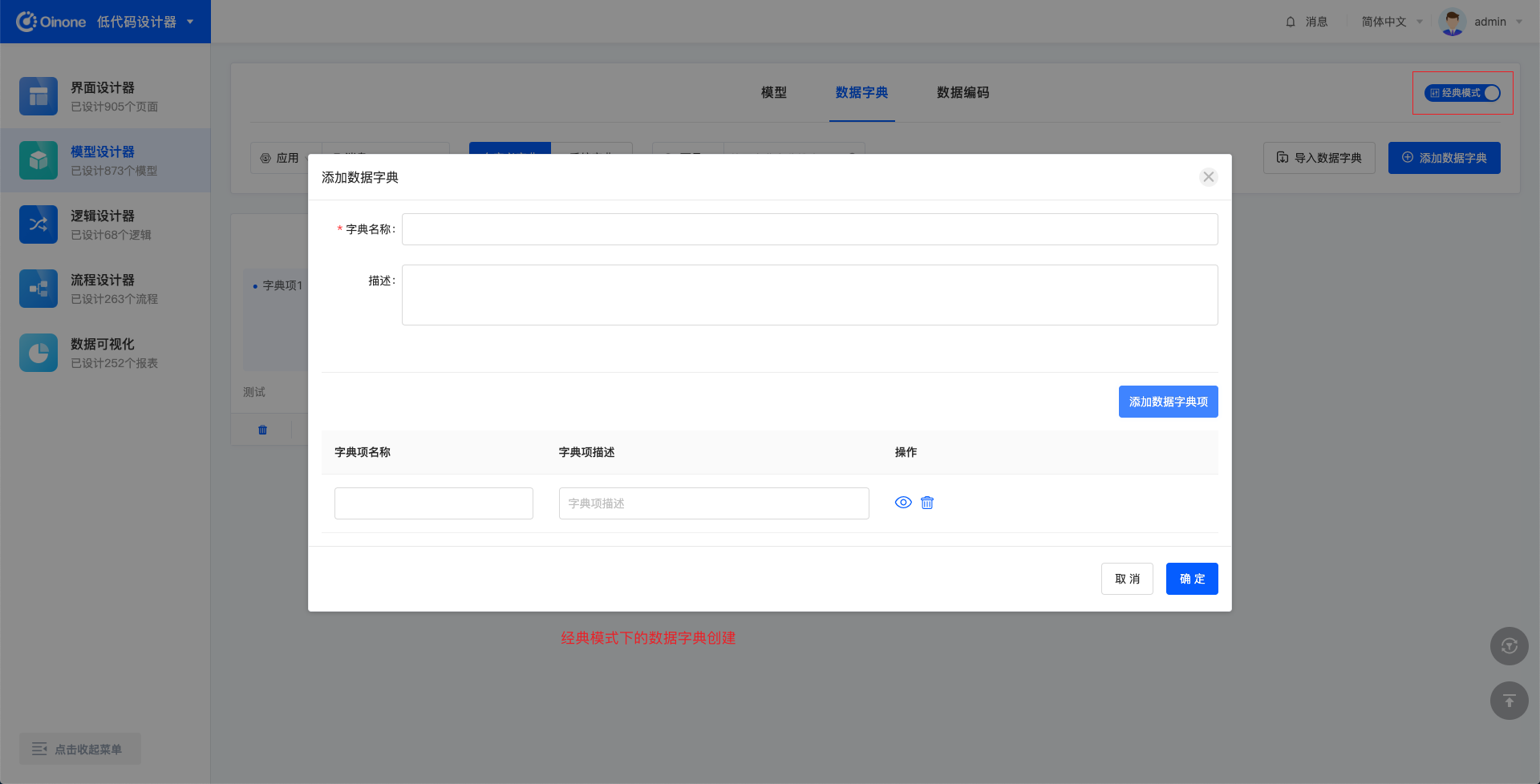
在中后台业务场景中,大部分的请求时候是可以被枚举的,比如创建、删除、更新、查询。在上文中,我们讲了httpClient如何自定义请求,来实现自己的业务诉求。本文中讲到的Request是离业务更近一步的封装,他提供了开箱即用的API,比如insertOne、updateOne,它是基于HttpClient做的二次封装,当你熟悉Request时,在中后台的业务场景中,所有的业务接口自定义将事半功倍。 一、Request详细介绍 元数据-model 获取模型实例 import { getModel } from '@kunlun/dependencies' getModel('modelName'); 图4-2-5-1 获取模型实例 清除所有缓存的模型 import { cleanModelCache } from '@kunlun/dependencies' cleanModelCache(); 图4-2-5-2 清除所有缓存的模型 元数据-module 获取应用实例,包含应用入口和菜单 import { queryModuleByName } from '@kunlun/dependencies' queryModuleByName('moduleName') 图4-2-5-3 获取应用实例 查询当前用户所有的应用 import { loadModules } from '@kunlun/dependencies' loadModules() 图4-2-5-4 查询当前用户所有的应用 query 分页查询 import { queryPage } from '@kunlun/dependencies' queryPage(modelName, { pageSize: 15, // 一次查询几条 currentPage, 1, // 当前页码 condition?: '' // 查询条件 maxDepth?: 1, // 查几层模型出来,如果有2,会把所有查询字段的关系字段都查出来 sort?: []; // 排序规则 }, fields, variables, context) 图4-2-5-5 分页查询 自定义分页查询-可自定义后端接口查询数据 import { customQueryPage } from '@kunlun/dependencies' customQueryPage(modelName, methodName, { pageSize: 15, // 一次查询几条 currentPage, 1, // 当前页码 condition?: '' // 查询条件 maxDepth?: 1, // 查几层模型出来,如果有2,会把所有查询字段的关系字段都查出来 sort?: []; // 排序规则 }, fields, variables, context) 图4-2-5-6 自定义分页查询 查询一条-根据params匹配出一条数据 import { queryOne } from '@kunlun/dependencies' customQueryPage(modelName, params, fields, variables, context) 图4-2-5-7 根据params匹配出一条数据 自定义查询 import { customQuery } from '@kunlun/dependencies' customQuery(methodName, modelName, record, fields, variables, context) 图4-2-5-8 自定义查询 update import { updateOne } from '@kunlun/dependencies' updateOne(modelName, record, fields, variables, context) 图4-2-5-9 update insert import { insertOne } from '@kunlun/dependencies' insertOne(modelName, record, fields, variables, context) 图4-2-5-10 insert delete import { deleteOne } from '@kunlun/dependencies'…