
1. 定义组件介绍
平台提供了大多数的通用组件,面对企业个性话需求、复杂的业务场景,我们也提供了自定义组件的能力,帮助企业更快实施业务需求。
自定义组件包含“组件画廊”“组件排序”“元件画廊”“元件属性设计”四个页面。
1.1 组件与元件
在介绍如何自定义组件前,需要先了解以下概念:
组件:页面设计的组件库中看到的是组件。每个组件都有自己的属性面板,通过属性、字段决定组件逻辑,而自定义组件就是需要构建出组件自身的属性信息,再结合业务配置组件的属性、使用组件。
一个组件在不同的业务类型、视图类型、单值/多值,其属性面板是不同的,不同业务类型、视图类型、单值/多值的组合我们成为元件,多种组合即为多个元件,所以一个组件包括多个元件。
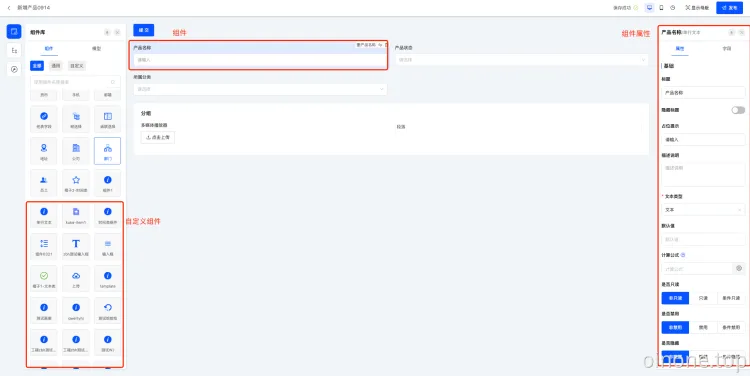

元件:一个组件可以对应多个元件。在创建时明确元件所适用的字段业务类型、单/多值、视图类型,在画布中切换元件时,会结合当前组件的字段业务类型、单/多值、所在视图类型确定可以使用哪一个元件。
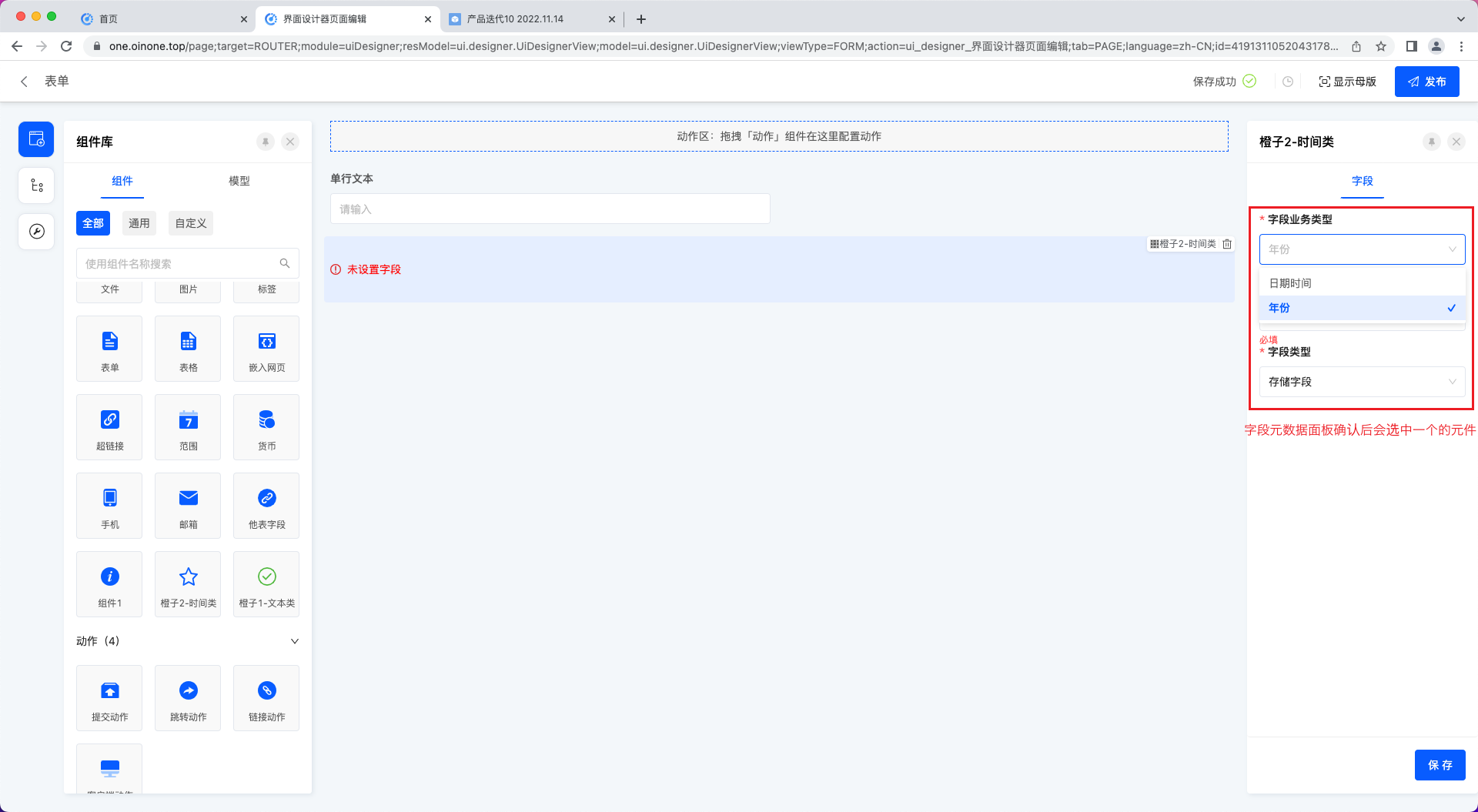
 此处切换的也是元件。
此处切换的也是元件。
示例:创建一个“下拉选”的组件,其中可以包含“下拉单选”“下拉多选”两个元件。“下拉选”组件从组件库中拖入时,设置单值时使用“下拉单选”元件,设置多值时使用“下拉多选”元件。
2. 组件管理
2.1 组件创建
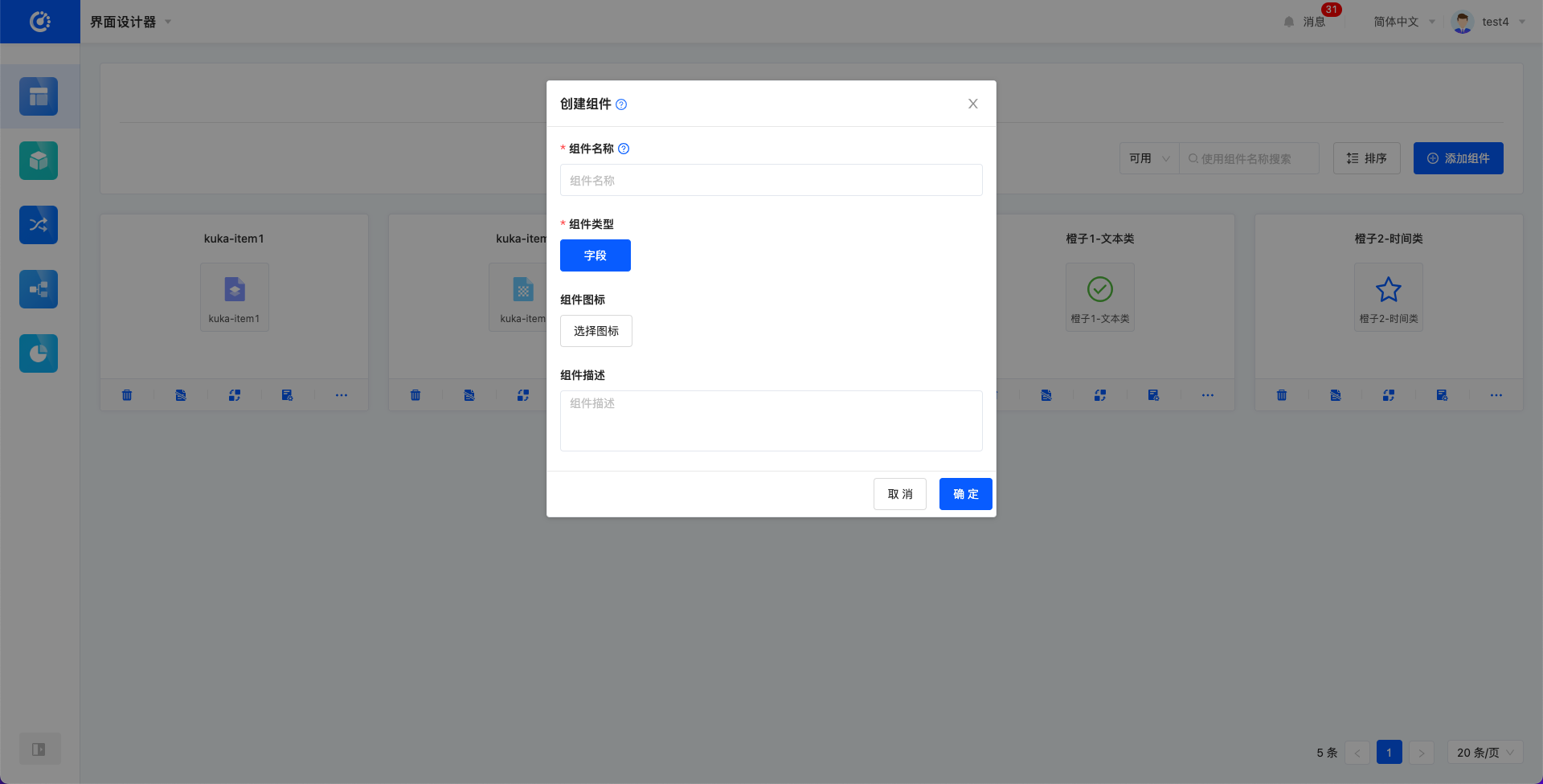
- 在组件画廊页面,点击添加组件,在弹窗中完善信息创建组件。
2.2 组件操作
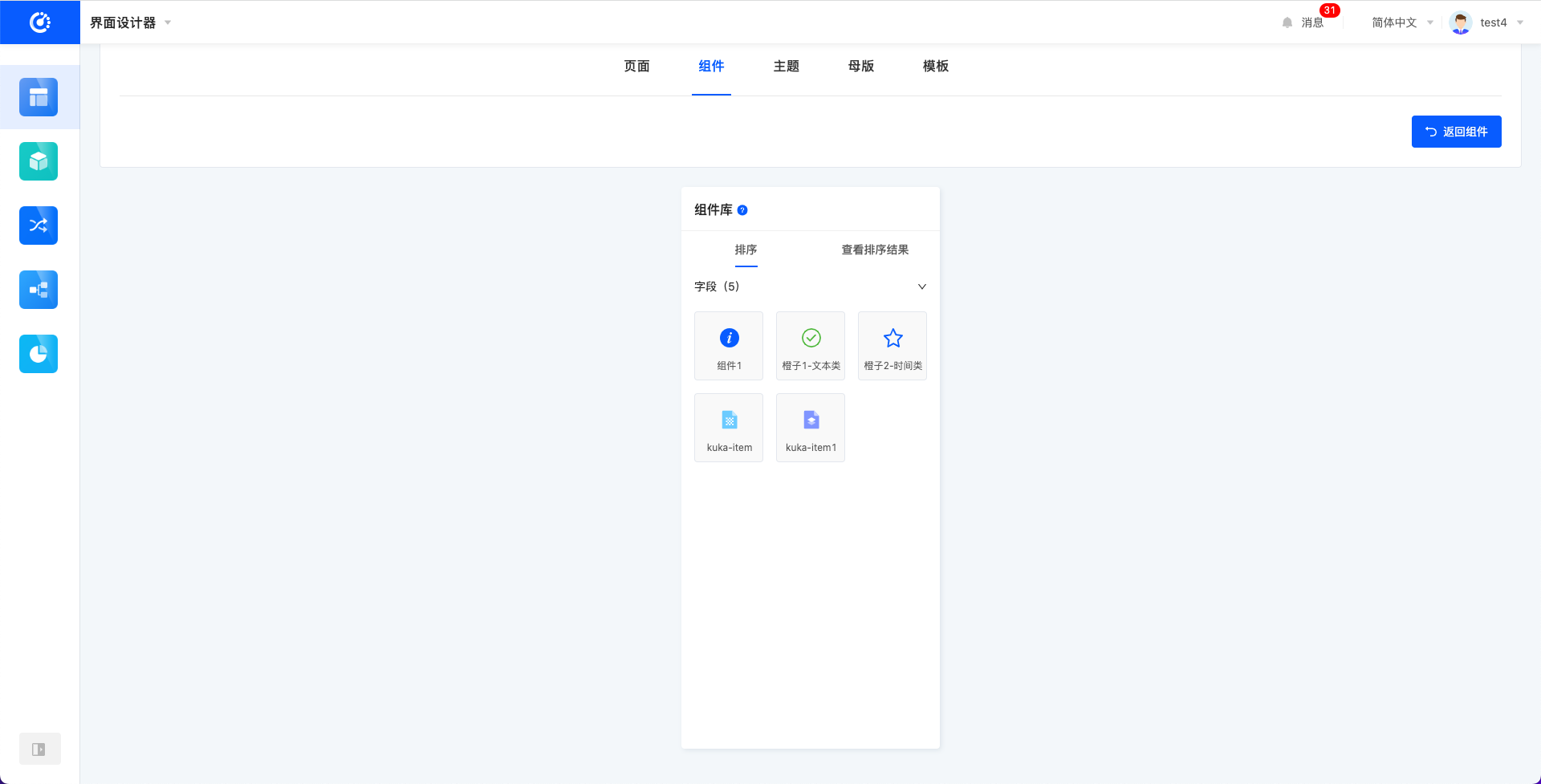
- 自定义组件支持“搜索、删除、作废、查看引用关系、管理元件、编辑、低无一体、排序”的操作。
- 搜索:默认搜索可见组件,可切换“全部、可用、废弃”搜索组件,也可使用组件名称搜索。
- 删除:若组件未被引用,则可以直接删除。
- 作废:组件作废后,不可在画布中展示,不可在组件切换时使用,但已使用的数据不影响。
- 查看引用关系:可以查看存在引用关系的页面,支持点击跳转到对应页面的设计页面。仅当组件无引用关系时才支持删除。
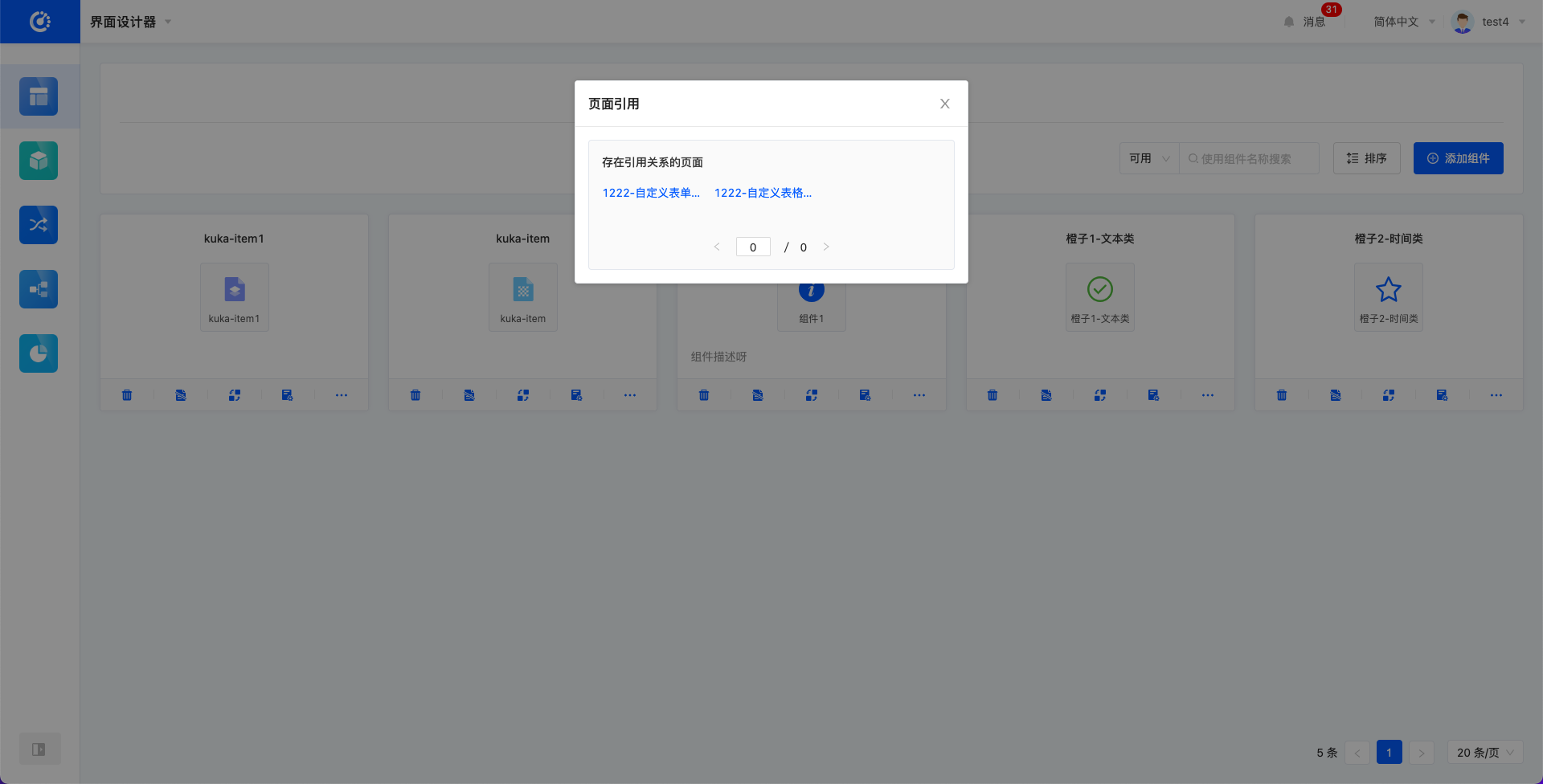
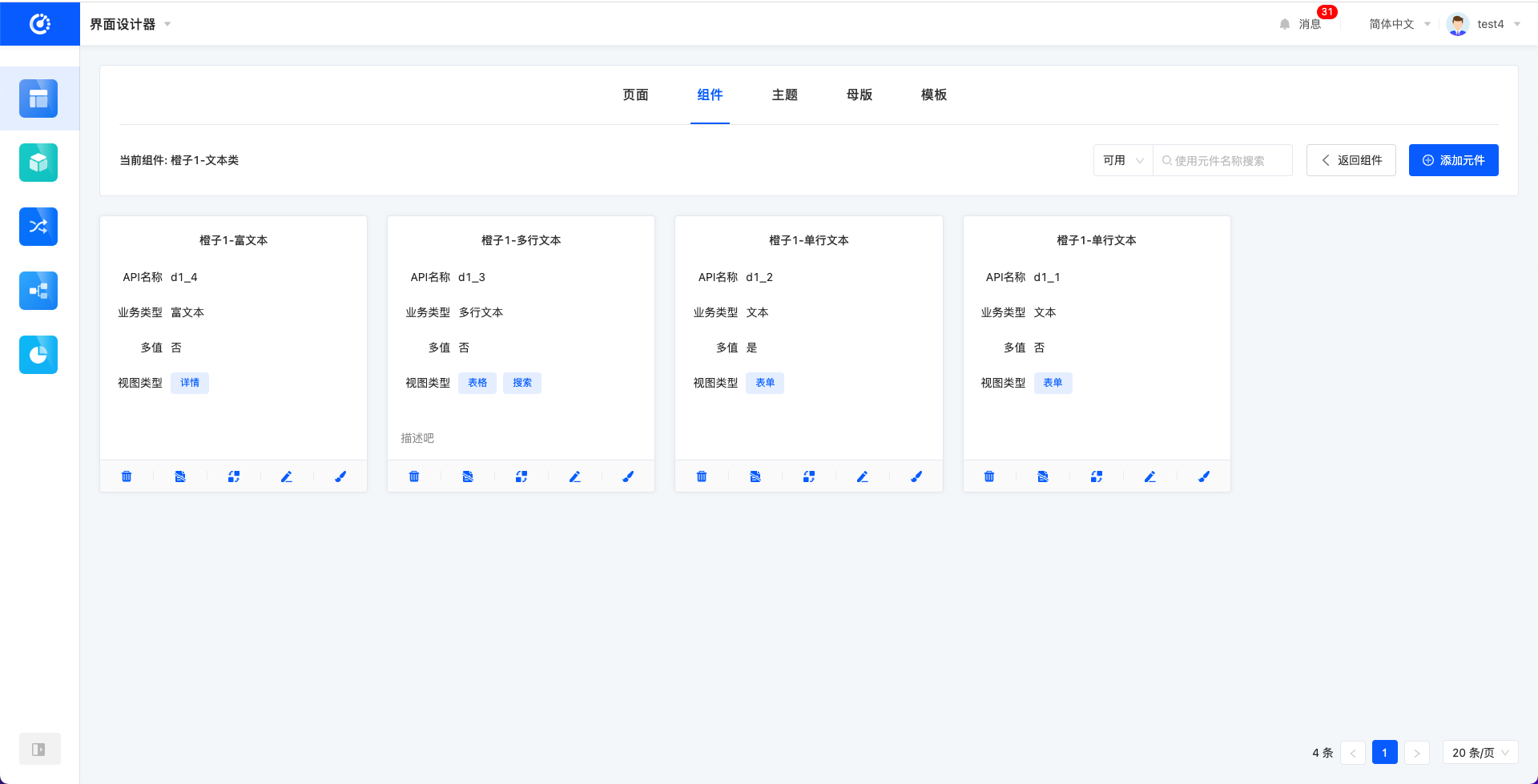
- 管理元件:点击进入元件的管理页面。
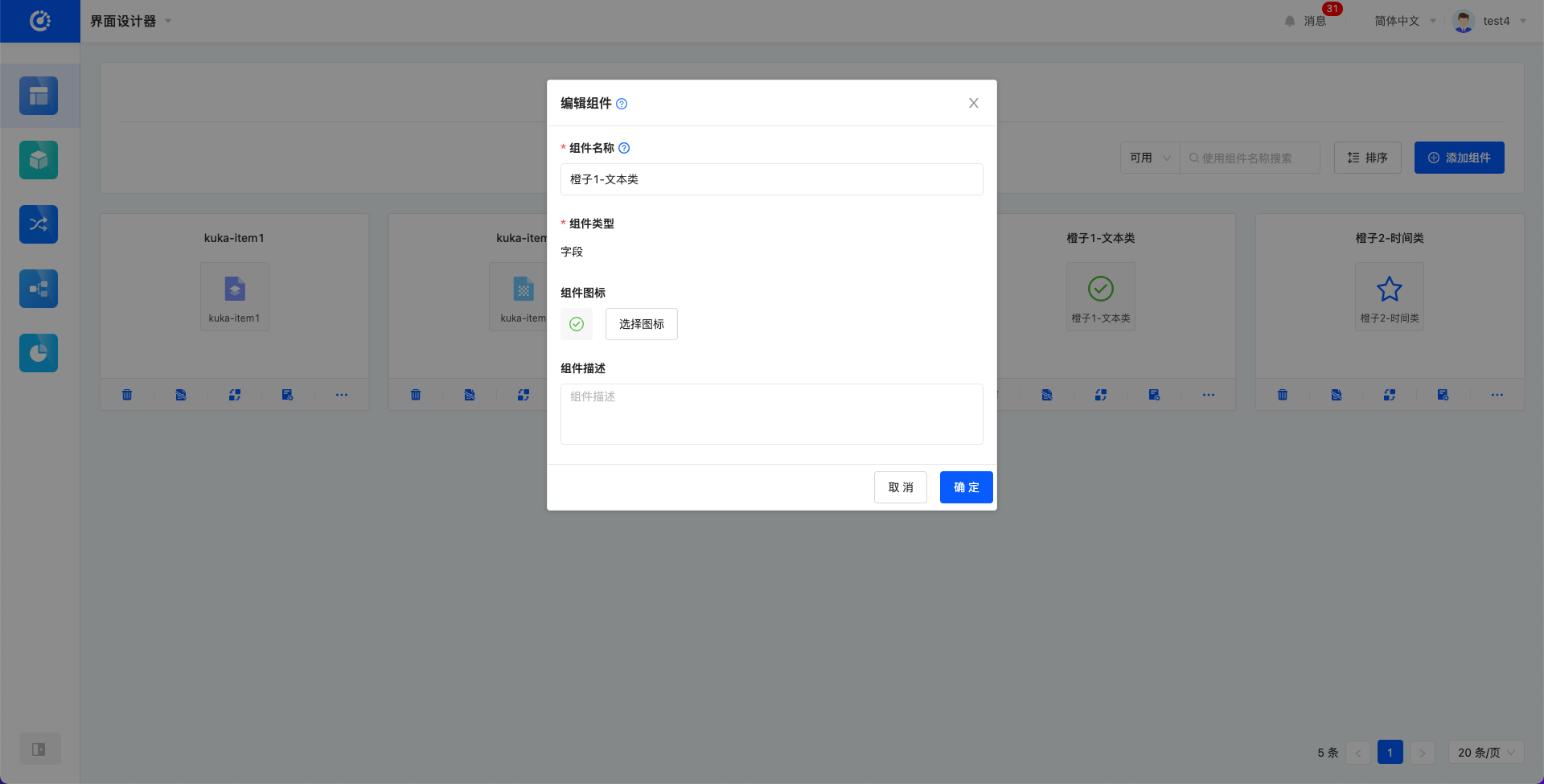
- 编辑:可修改组件名称、组件图表、组件描述。
- 低无一体:比较复杂,在第5章中单独讲解。
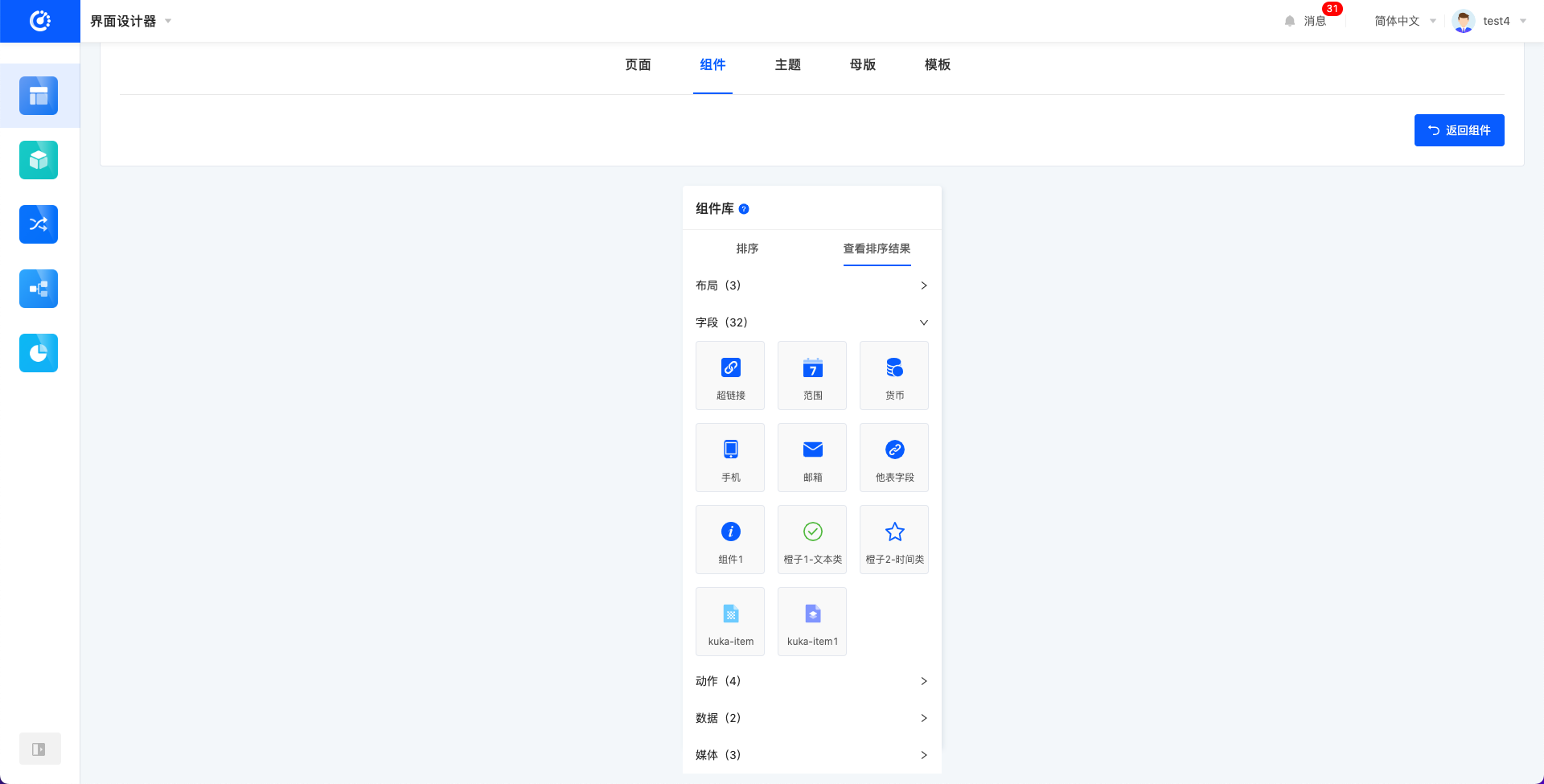
- 排序:进入排序页,可拖动排序自定义组件。自定义组件会插在系统组件之后。可以点击“查看排序结果”选项页查看最终排序结果。排序同样会更新画布中的组件库顺序。
3. 元件管理
3.1 元件创建
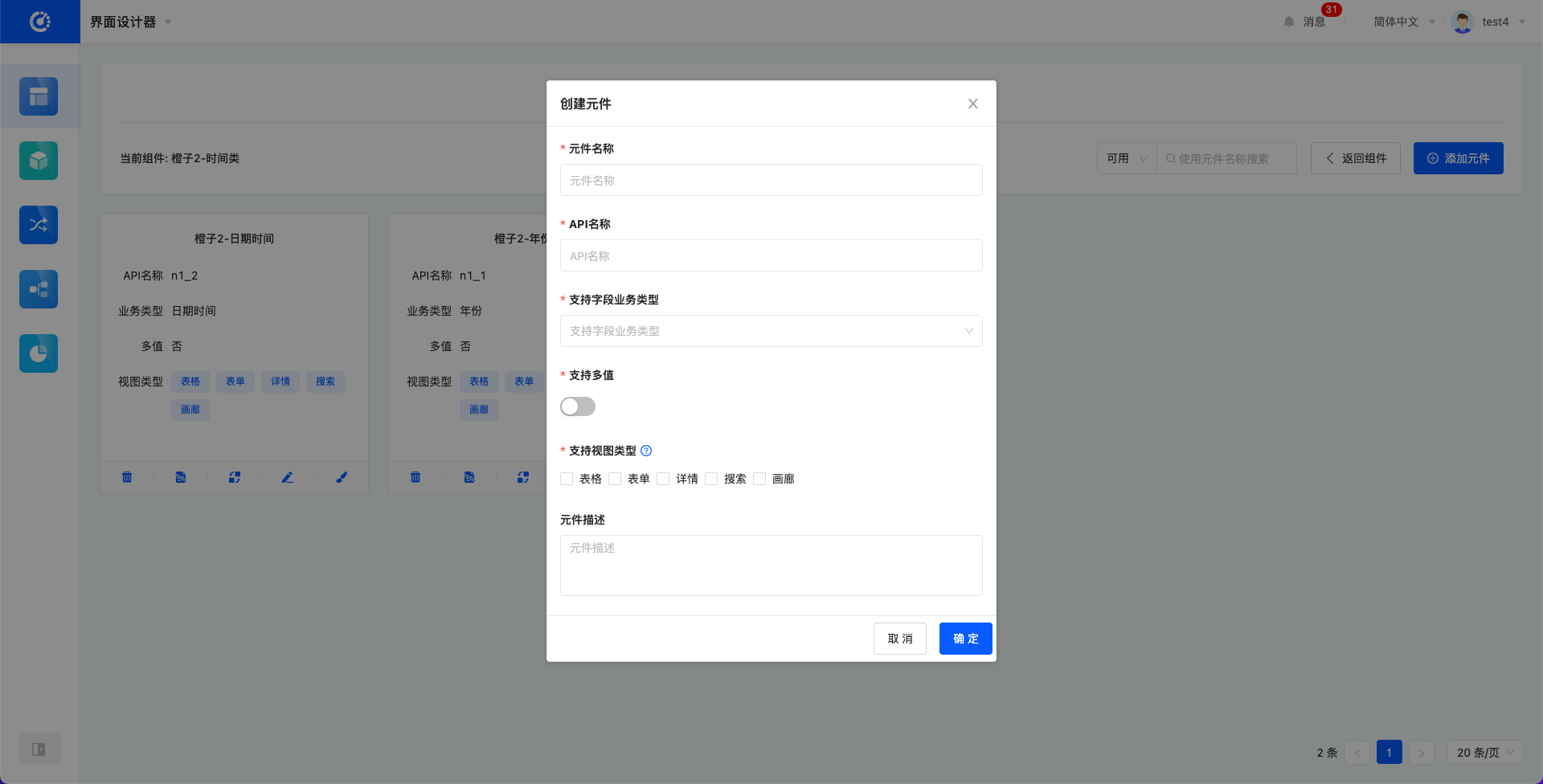
- 在元件画廊页面,点击添加元件,在弹窗中完善信息创建一个元件。
3.2 元件操作
- 元件支持“删除、作废、查看引用关系、编辑、设计元件属性”的操作。
- 删除:若元件未被引用,则可以直接删除。
- 作废:元件作废后,不影响原来已使用的元件,无法新添加、使用该元件。
- 查看引用关系:可以查看存在引用关系的页面,支持点击跳转到对应页面的设计页面。仅当元件无引用关系时才支持删除。此处的引用关系数量会小于等于组件引用关系的数量。
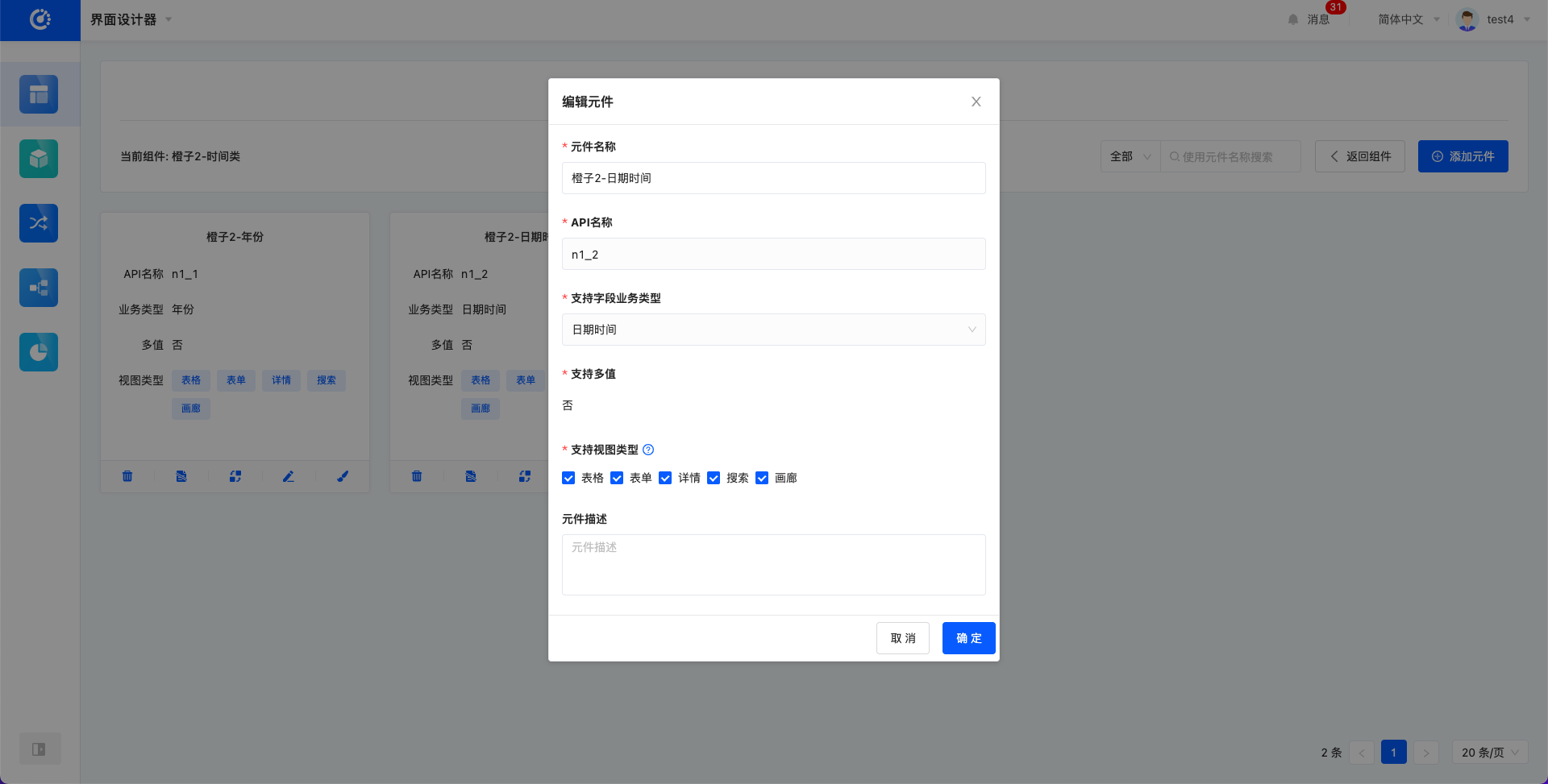
- 编辑:可修改元件名称、支持视图类型、元件描述。
- 设计元件属性:比较复杂,将在第4章中单独讲解。
4. 设计元件属性
- 元件属性设计页面主要操作集中在这三部分,分别是①视图切换②属性面板设计区③复制功能
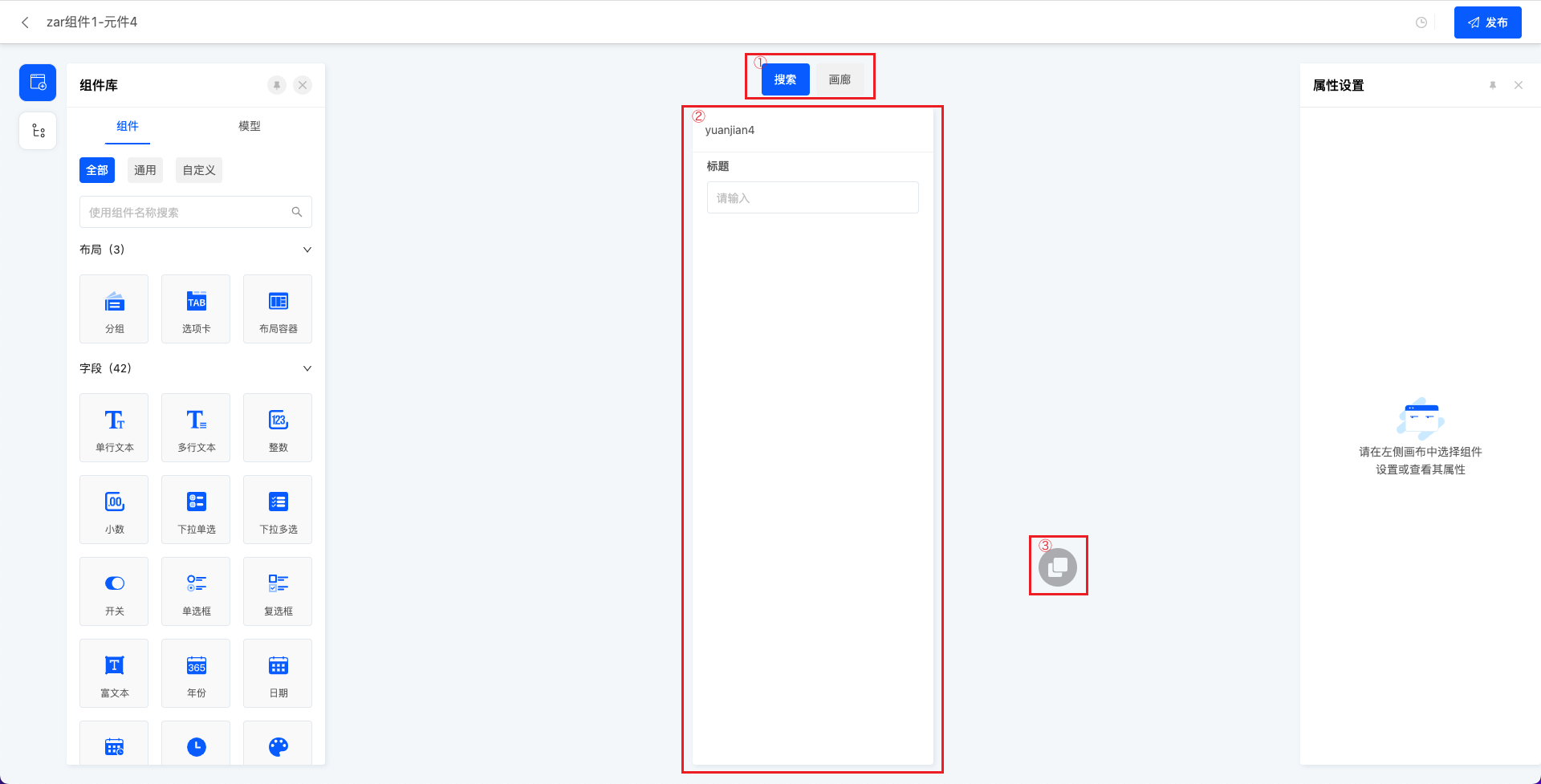
- 视图切换:元件创建时选择的支持视图类型,在①区域平铺可切换对应视图的属性面板进行设计。
- 属性面板设计区:可将组件拖入属性面板设计区进行设计,设计的是自定义组件的属性面板,左侧组件库和页面设计的组件库相同,仍然支持创建字段或使用模型字段,右侧进行元数据面板、属性面板设置。
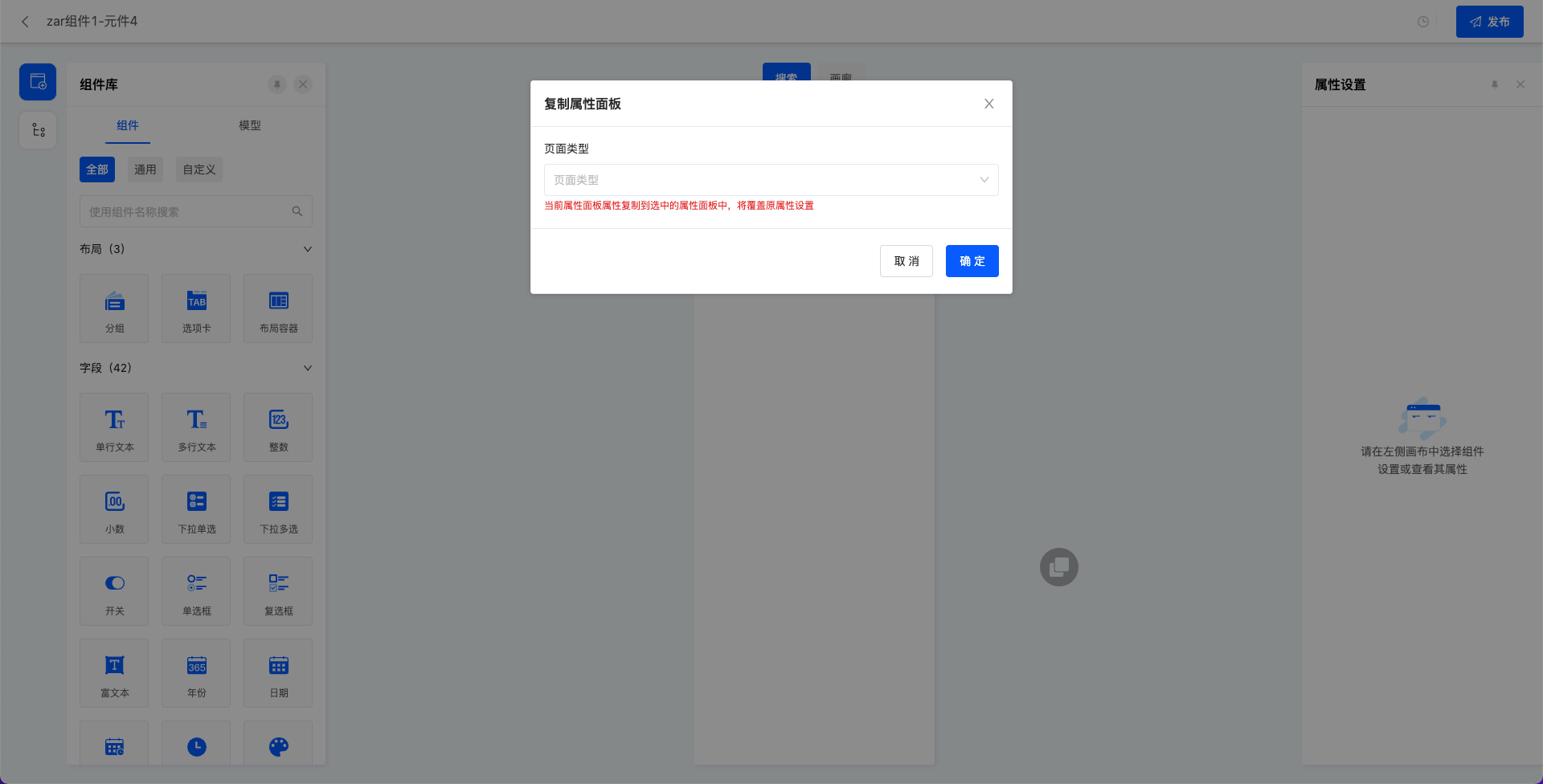
- 复制功能:可将已设置好的属性面板复制到其他视图,提高设计效率。
5. 低无一体
- 低无一体简单讲就是组件代码上传,通过载入代码使组件在设计页面和实现页面可见和交互。
- 系统内置的属性不满足需求时,要用低无一体写代码,定制属性,比如从模型中拖拽设计就是内置的属性,从组件库中设置,就要配合低无一体,否则无效。
- 首次进入组件设计或组件中的元件变更时需要生成SDK。
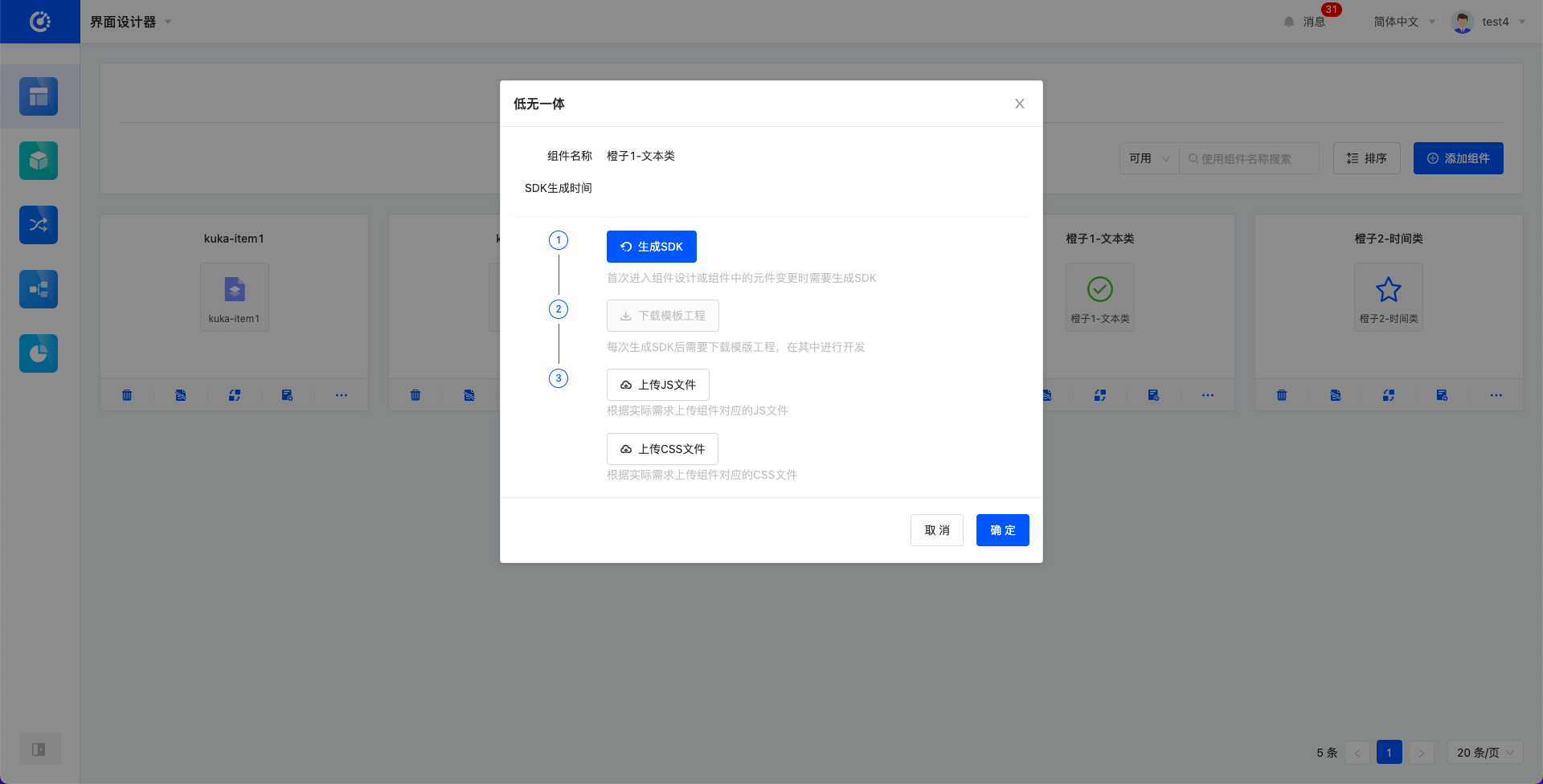
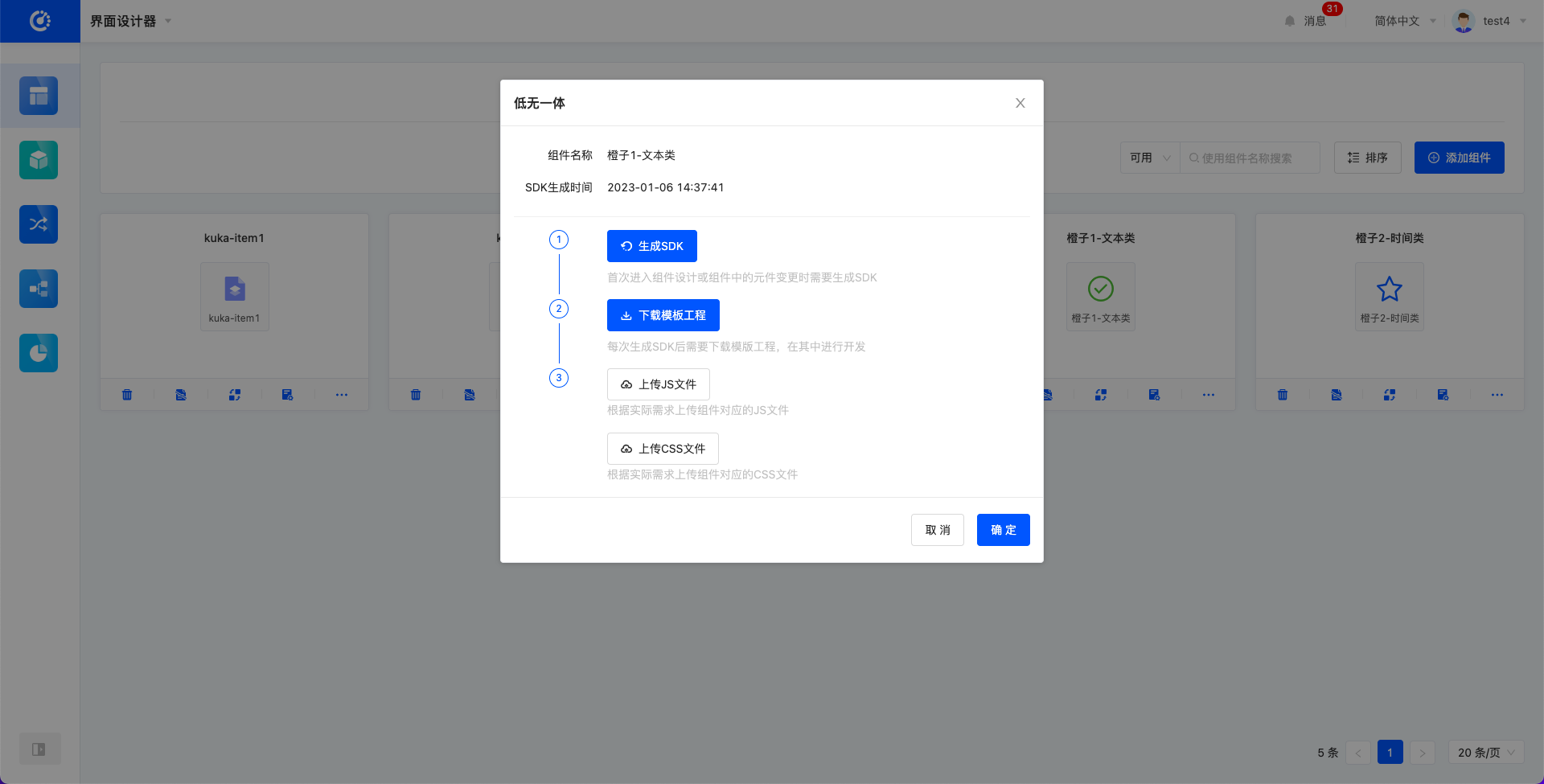
- 生成结束后展示SDK生成时间,并且“下载模版工程”按钮可用。
-
点击下载模版工程,会自动下载模板工程。
-
在模版工程中编写前端代码。
-
根据实际需求上传JS、CSS文件后提交即可。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9409.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验