
本篇主要结合业务场景介绍高级组件的使用方法。
级联选择/树选择
级联选择与树选择是同一类业务场景、不同的交互体验,在这里我们一起说明。
业务场景
行业分类、产品类目/分类等自关联场景,案例以行业分类说明。
操作步骤
Step1:搭建模型
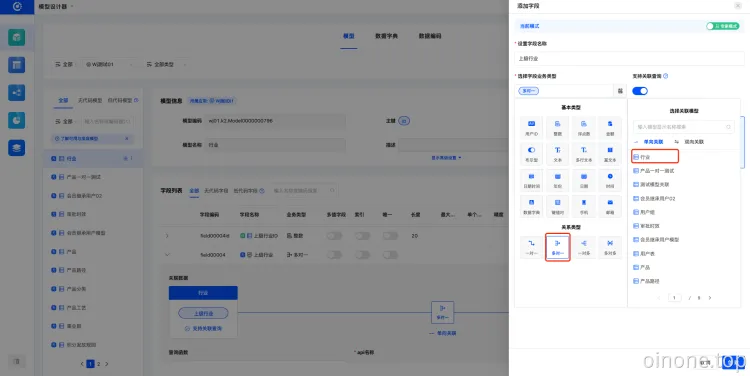
搭建行业模型,在行业模型中创建多对一字段“上级行业”,指多个子行业对应一个上级行业。如下图:

Step2:界面设计
- 创建行业的表格视图,绑定菜单,并且在此视图中增加“跳转动作 - 新增行业”;
- 创建新增行业表单,将“上级行业”拖进画布中,组件切换为“级联选择”,属性面板配置“选项字段、搜索字段、透出字段”,平台低代码为每个模型自动生成了名称、编码字段,如果不使用平台提供的名称、自建名称时,需要配置这三个字段;
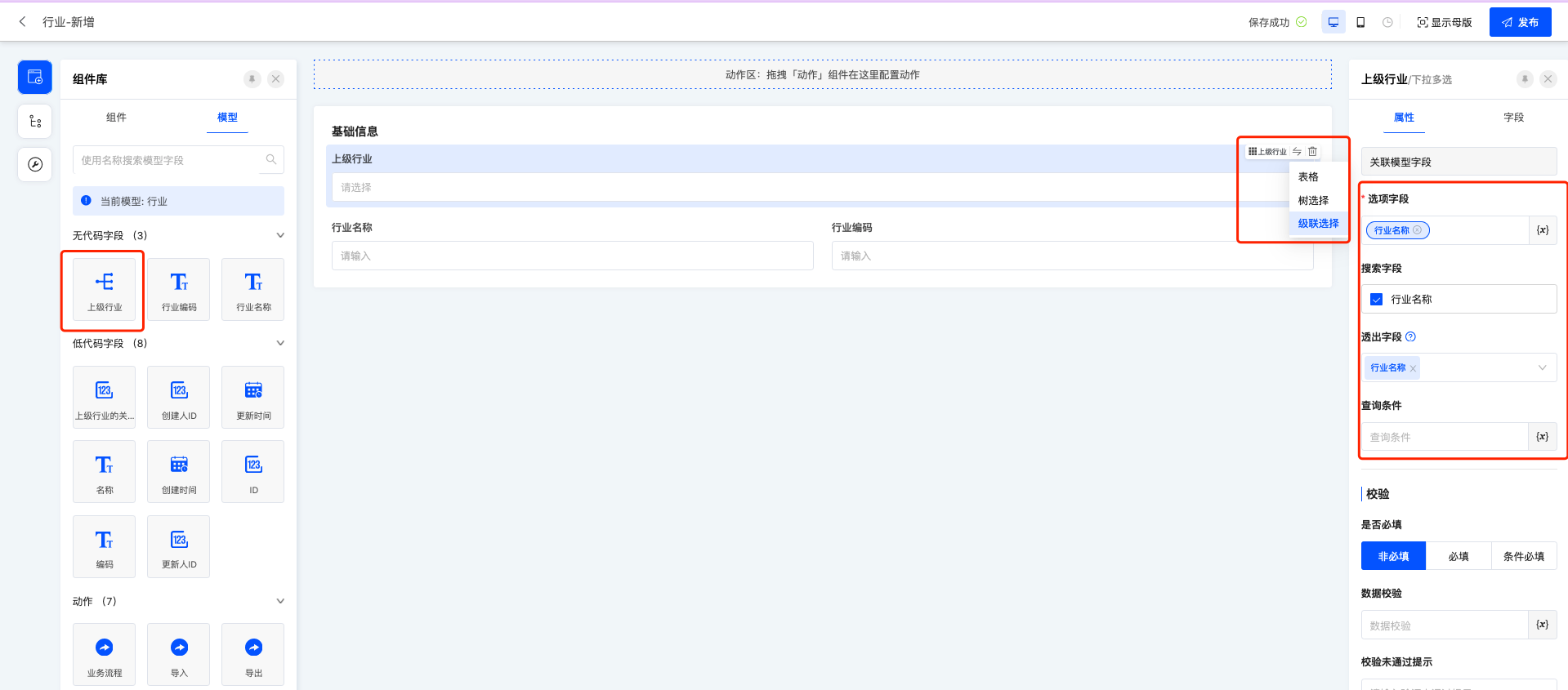
- 为“上级行业”设置联动关系,自关联默认选择行业、标题定义为行业名称、自关联的字段为上级行业。
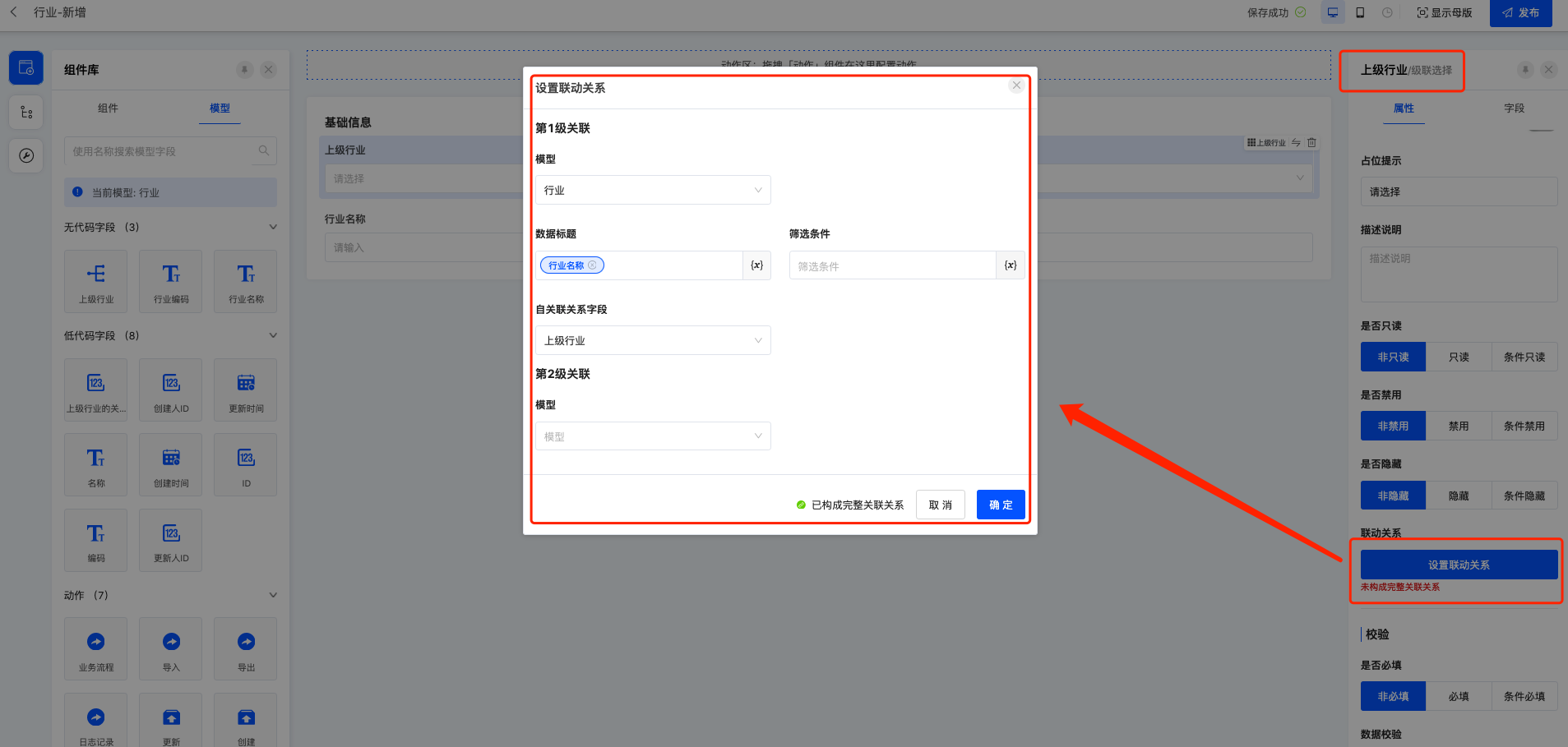
- 配置后发布表格、表单视图,即可获得级联选择效果。
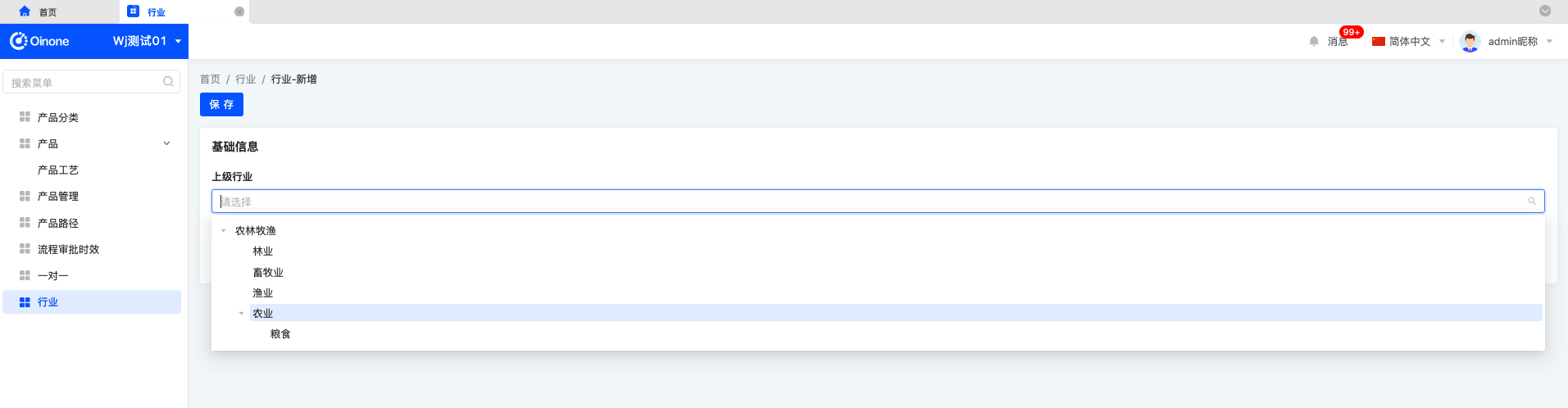
- 表单视图中将“上级行业”切换为“树选择”组件,在发布后,即可获得树选择效果。
Step3:效果展示
级联选择
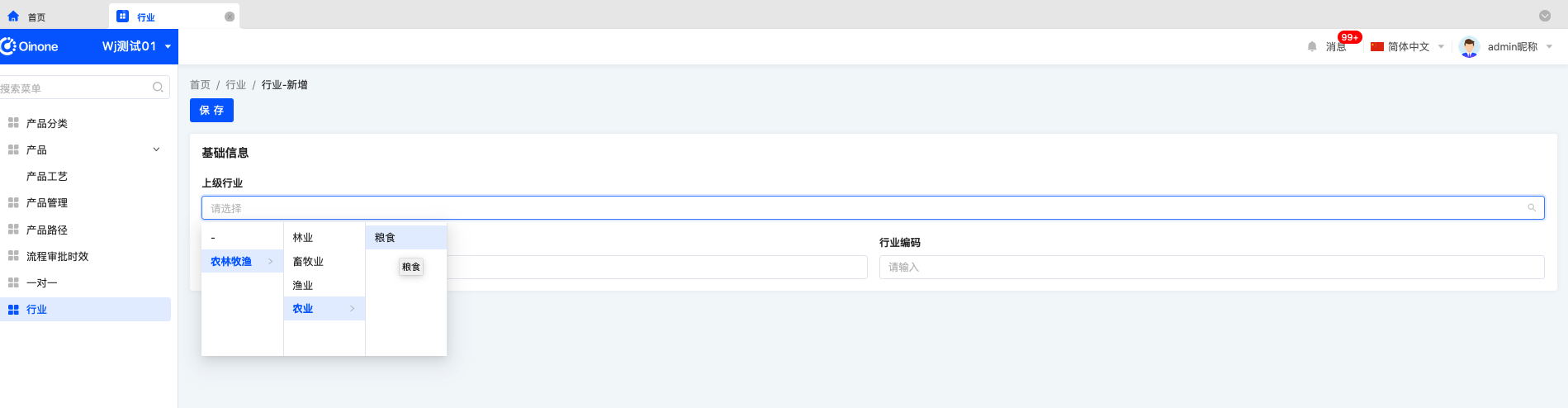
树选择
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9408.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验