
本文核心是带大家全面了解oinone的序列方式,包括支持的序列化类型、注意点、如果新增客户化序列化方式以及字段默认值的反序列化。
一、数据存储的序列化 (举例)
使用@Field注解的serialize属性来配置非字符串类型属性的序列化与反序列化方式,最终会以序列化后的字符串持久化到存储中。 ### Step1 新建PetItemDetail模型、并为PetItem添加两个字段
- PetItemDetail继承TransientModel,增加两个字段,分别为备注和备注人
package pro.shushi.pamirs.demo.api.tmodel;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.base.TransientModel;
import pro.shushi.pamirs.user.api.model.PamirsUser;
@Model.model(PetItemDetail.MODEL_MODEL)
@Model(displayName = "商品详情",summary = "商品详情",labelFields = {"remark"})
public class PetItemDetail extends TransientModel {
public static final String MODEL_MODEL="demo.PetItemDetail";
@Field.String(min = "2",max = "20")
@Field(displayName = "备注",required = true)
private String remark;
@Field(displayName = "备注人",required = true)
private PamirsUser user;
}- 修改PetItem,增加两个字段petItemDetails类型为List和tags类型为List,并设置为不同的序列化方式,petItemDetails为JSON(缺省就是JSON,可不配),tags为COMMA。同时设置 @Field.Advanced(columnDefinition = varchar(1024)),防止序列化后存储过长
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.demo.api.tmodel.PetItemDetail;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.NullableBoolEnum;
import java.math.BigDecimal;
import java.util.List;
@Model.model(PetItem.MODEL_MODEL)
@Model(displayName = "宠物商品",summary="宠物商品",labelFields = {"itemName"})
public class PetItem extends AbstractDemoCodeModel{
public static final String MODEL_MODEL="demo.PetItem";
@Field(displayName = "商品名称",required = true)
private String itemName;
@Field(displayName = "商品价格",required = true)
private BigDecimal price;
@Field(displayName = "店铺",required = true)
@Field.Relation(relationFields = {"shopId"},referenceFields = {"id"})
private PetShop shop;
@Field(displayName = "店铺Id",invisible = true)
private Long shopId;
@Field(displayName = "品种")
@Field.many2one
@Field.Relation(relationFields = {"typeId"},referenceFields = {"id"})
private PetType type;
@Field(displayName = "品种类型",invisible = true)
private Long typeId;
@Field(displayName = "详情", serialize = Field.serialize.JSON, store = NullableBoolEnum.TRUE)
@Field.Advanced(columnDefinition = "varchar(1024)")
private List<PetItemDetail> petItemDetails;
@Field(displayName = "商品标签",serialize = Field.serialize.COMMA,store = NullableBoolEnum.TRUE,multi = true)
@Field.Advanced(columnDefinition = "varchar(1024)")
private List<String> tags;
}Step2 重启系统看效果
- 准备用户,因为admin用户在系统中默认是不可选择的,所以我们先到用户中心去新增用户

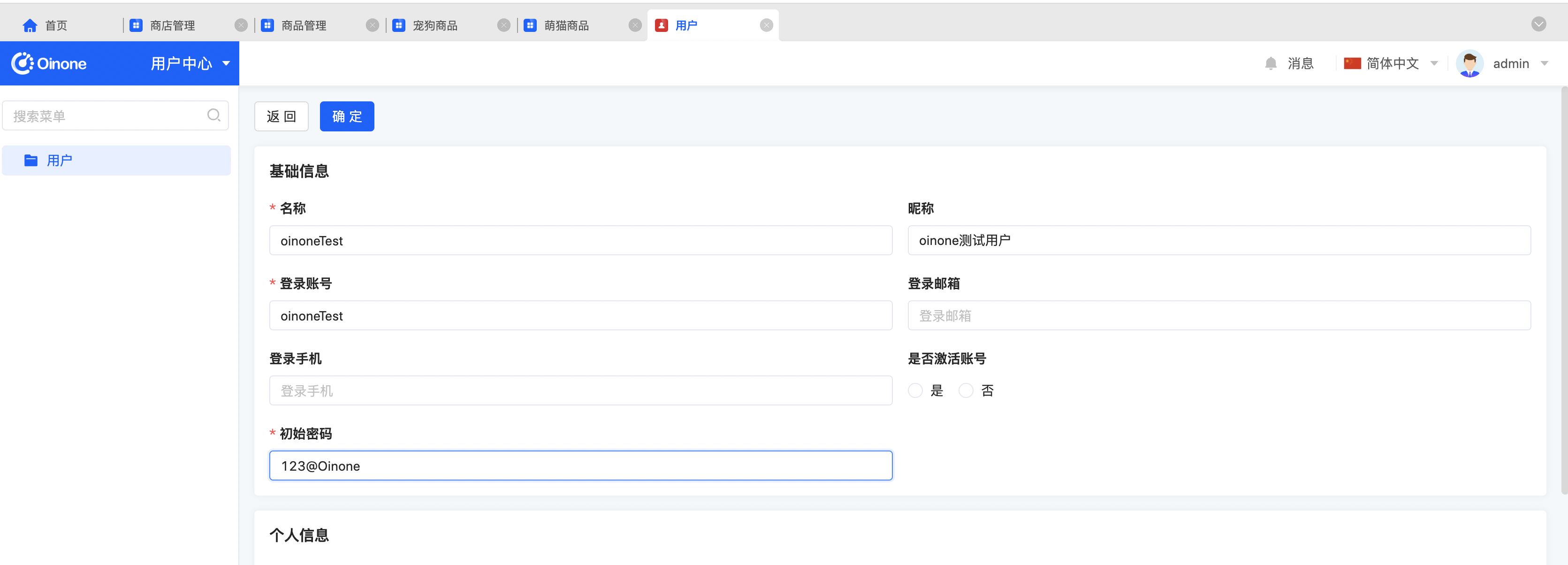
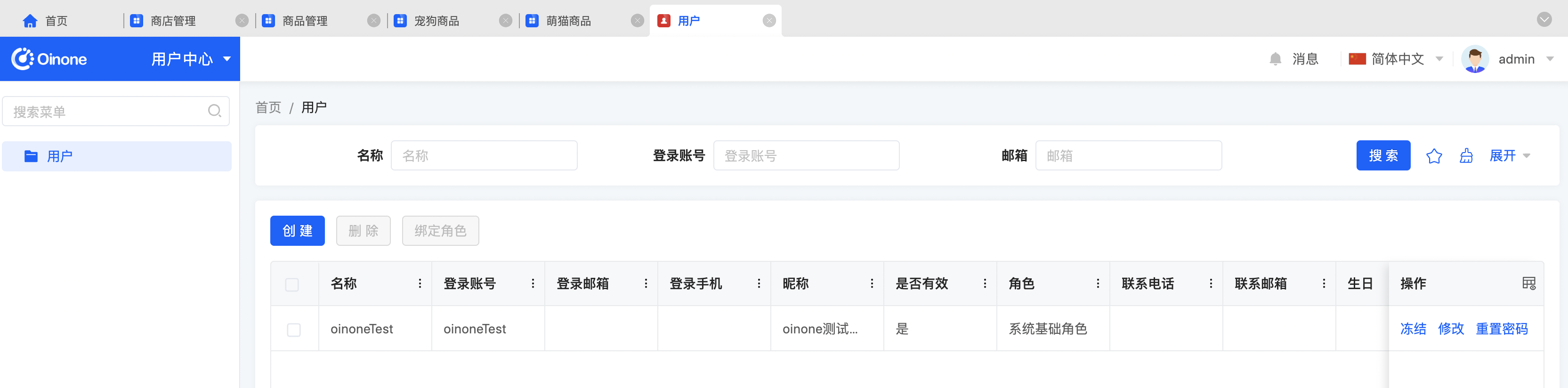
- 模型宠狗商品的编辑页面可以看到详情字段和商品标签字段,用新增按钮添加详情记录,直接在商品标签的input框输入,回车可以输入多值;
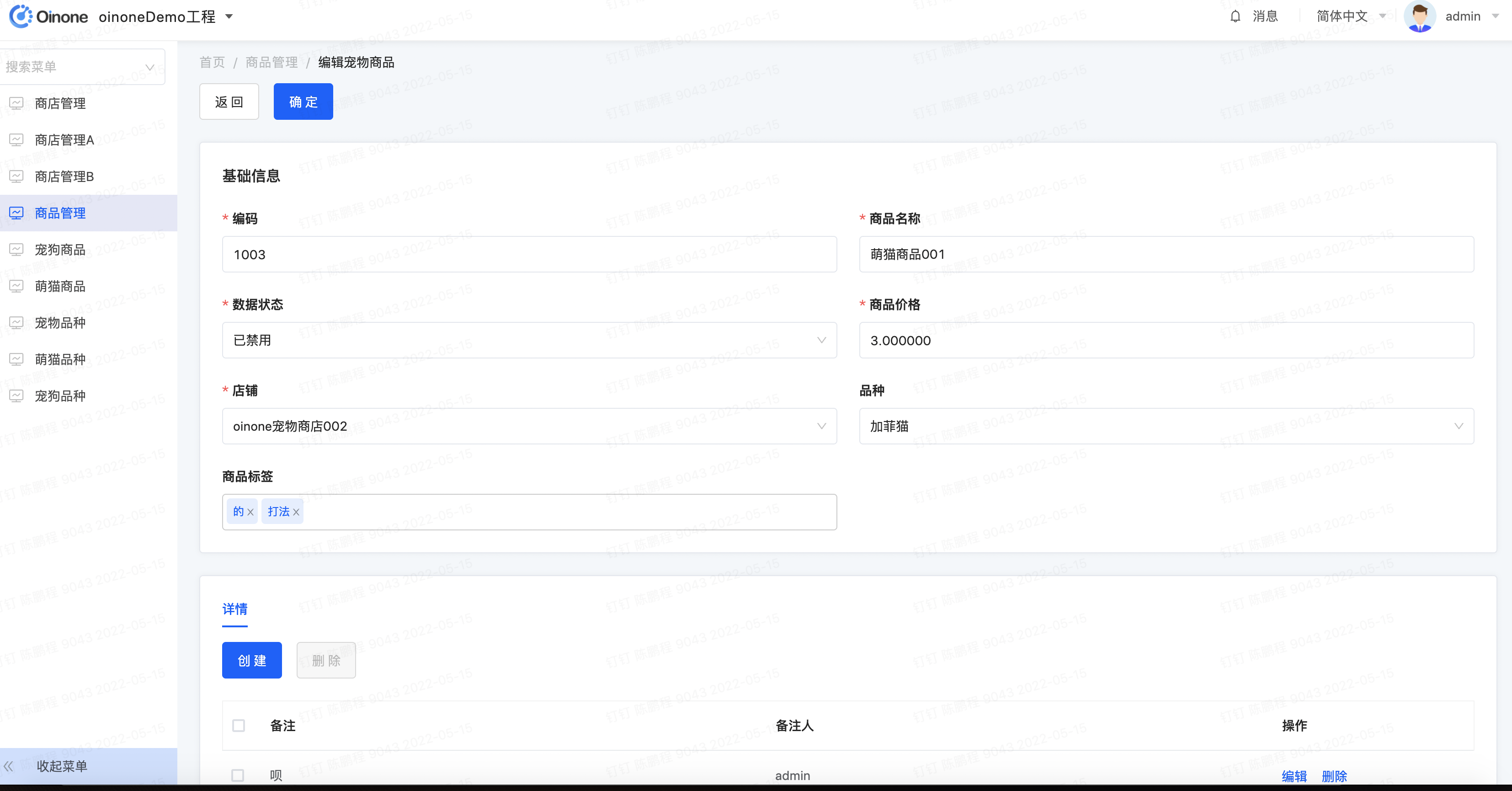
- 模型宠狗商品的列表页面可以看到详情字段和商品标签字段
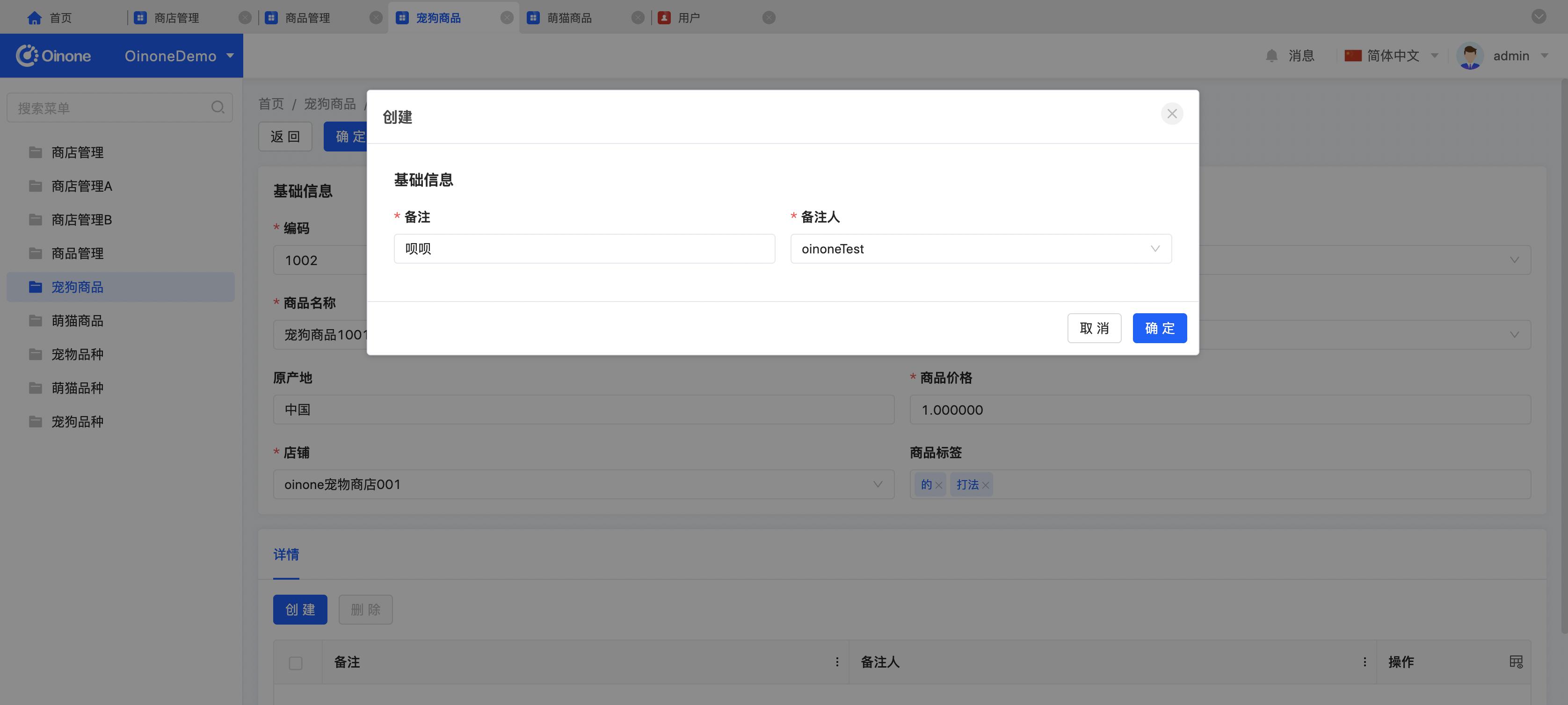
- 查看商品数据表,我们可以看到【详情】字段和【商品标签】字段,按指定序列化方式进行存储

Step3 字段序列化注意点
- 必须使用Field#store属性将字段存储设置为NullableBoolEnum.TRUE。
- 使用Field#serialize属性指定序列化方式,默认为JSON。
- 如把PetItemDetail设置为存储模型,须在PetItem的petItemDetails字段上使用Field.Relation#store属性将关联关系存储设置为false。不然会同时存储petItemDetails字段和对应的PetItemDetail表记录
Step4 字段序列化方式说明
| 序列化方式 | 说明 | 备注 |
|---|---|---|
| JSON | JSON序列化 | 主要用于模型相关类型字段的序列化,是@Field.serialize默认选项 |
| DOT | 点拼接集合元素 | |
| COMMA | 逗号拼接集合元素 | |
| BIT | 按位与,2次幂数求和 | 非@Field.serialize可选项列表,用于二进制枚举序列化不需要配置,由oinone自动推断 |
二、注册自己的序列化器(举例)
注册自己的序列化器(实现pro.shushi.pamirs.meta.api.core.orm.serialize.Serializer接口), 如oinone的DOT的序列化方式,用type()方法返回值做匹配,serialize和deserialize分别对应序列化和反序列化方法。
package pro.shushi.pamirs.framework.compute.serialize;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import pro.shushi.pamirs.meta.api.core.orm.serialize.Serializer;
import pro.shushi.pamirs.meta.common.constants.CharacterConstants;
import pro.shushi.pamirs.meta.enmu.SerializeEnum;
import pro.shushi.pamirs.meta.util.TypeUtils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 点表达式序列生成处理器实现
*
* @author d@shushi.pro
* @version 1.0.0
* date 2020/3/4 2:48 上午
*/
@SuppressWarnings("rawtypes")
@Slf4j
@Component
public class DotSerializeProcessor implements Serializer<Object, String> {
@Override
public String serialize(String ltype, Object value) {
if (null == value) {
return null;
}
if (List.class.isAssignableFrom(value.getClass())) {
return StringUtils.join((List) value, CharacterConstants.SEPARATOR_DOT);
} else {
return StringUtils.join(Collections.singletonList(value), CharacterConstants.SEPARATOR_DOT);
}
}
@SuppressWarnings("unchecked")
@Override
public Object deserialize(String ltype, String ltypeT, String value, String format) {
if (null == value) {
return null;
}
String[] dots = value.split(CharacterConstants.SEPARATOR_ESCAPE_DOT);
List list = new ArrayList();
for (String dot : dots) {
Object object = TypeUtils.valueOfPrimary(ltypeT, dot, null);
list.add(object);
}
return list;
}
@Override
public String type() {
return SerializeEnum.DOT.value();
}
}字段默认值的反序列化
用@Field.defaultValue注解在字段上配置defaultValue属性时,将根据字段的Ttype类型及字段的Ltype等类型属性,自动进行反序列化。包括但不限于以下几种情况:
- OBJ、STRING、TEXT、HTML——保持不变
- BINARY、INTEGER——转换为整数
- FLOAT、MONEY——转换为浮点数
- DATETIME、DATE、TIME、YEAR——根据Field.Date#format属性决定反序列化日期格式
- BOOLEAN——仅允许null、true、false
- ENUM——使用value进行匹配
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9238.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验